Machine Learning Yearning - Andrew NG
链接(1~12章):
https://gallery.mailchimp.com/dc3a7ef4d750c0abfc19202a3/files/Machine_Learning_Yearning_V0.5_01.pdf
链接(第13章):
https://gallery.mailchimp.com/dc3a7ef4d750c0abfc19202a3/files/Machine_Learning_Yearning_V0.5_02.pdf
链接(第14章):
https://gallery.mailchimp.com/dc3a7ef4d750c0abfc19202a3/files/Machine_Learning_Yearning_V0.5_03.pdf
本文有转载:http://blog.csdn.net/u014380165/article/details/73611858
MLY--1. Why Machine Learning Strategy
这一章主要是抛砖引玉,指出在你的深度学习模型遇到问题的时候,你需要选择合适的方法解决,那么一般都有哪些方法呢?作者列举了以下几个:
1、获取更多的数据。
2、增加训练样本的多样性。
3、增加迭代次数。
4、试试更深、更宽的网络,比如增加层数,卷积核个数,参数等等。
5、试试更小的网络。
6、加正则项,比如L2正则项。
7、改变你的网络结构,比如激活方式,卷积核个数等。
个人感悟:增加训练样本的多样性可以这么理解:假如你要做猫狗分类,那么不同种类、不同姿势、睡觉的吃饭的等等的猫,各种各样都来一些,对提升你的算法效果是有帮助的。是否要增加迭代次数可以根据你的loss情况进行判断,当你的loss还没趋于平稳的时候,而且模型不太过拟合时,可以增加迭代次数。经验而言需要把你的全部数据跑几十遍才能达到不错的效果。更深的网络可以通过增加层数达到,比如像ResNet-152,当然原本简单增加层数的时候会遇到梯度衰减严重难以训练的情况,所以有了ResNet网络来解决这个问题。更宽的网络主要是通过增加某些层的卷积核的个数,一个卷积核相当于提取了一种特征,卷积核越多,特征越丰富,当然也增加了计算量。正则项一般是在过拟合的时候使用,简单讲就是限制权值的大小,L2是将权值的平方和加入到目标函数中,最后会使得权值趋于平滑,还有一种正则项是L1,可以使得权值趋于稀疏,即许多项为0。改变网络结构一般是比较细的调整,比如激活从ReLU改为pReLU,某层卷积核的大小的改变等等,一般小改的效果不会太明显。
MLY--2. How to use this book to help your team
MLY--3. Prerequisites and Notation
这一章也没什么重要内容,就是说如果你对机器学习不是很了解,可以看看这个链接:http://ml-class.org
MLY--4. Scale drives machine learning progress
其实深度学习(或者叫神经网络)在几十年前就有了,但是为什么现在才开始这么火?作者提到两个主要因素:
1、足够的数据
2、足够的计算能力
虽然现在数据有很多,但是传统的机器学习算法,比如逻辑回归,随着数据量的增加,其效果会遇到明显的瓶颈,此时如果采用不同深度的神经网络来训练,效果基本随着网络深度的增加而增加。如下图:

为什么会这样?因为在小数据上,可以人工构造特征,一般而言在小数据集上构造的特征还是十分有效的,但是随着数据集的增加,人工构造特征会愈加困难。
MLY--5. Your development and test sets
一般而言,在开展深度学习项目的时候,都会将数据分成三部分:训练集,验证集,测试集。你的模型在训练集上训练,然后用验证集来验证其效果,根据验证集的结果进行模型优化。作者强调你的测试集一定要和真实的数据有相同分布。
个人感悟:有些人可能觉得直接分成训练集和测试集就行了,为什么还要加一个验证集。其实应该这么理解,验证集也是一个测试集,用来测试你的模型的泛化能力。而测试集一般是指线上的环境。一般而言我们拿到数据,可以分成训练集和验证集,要随机分,这样训练集和验证集才能有相似的分布,然后就在这两个数据集上不断训练和优化我们的模型。最后将模型应用到实际场景中,这实际场景其实就是我们的测试集,因为实际场景中数据一般会比我们之前收集的数据更多样,所以模型表现不如线下验证集是正常的,因为你一开始拿到的数据不可能十全十美,这时需要将这些数据再加到我们的训练集和验证集中,再训练和优化,直到迭代到下一个版本。如此不断重复。总之记住:训练集,验证集,测试集要尽可能具有相同分布。
MLY--6. Your dev and test sets should come from the same distribution
跟第五章类似,强调验证集和测试集要有相同的分布,否则你可能在验证集上训练出一个非常好的模型,但是在测试集上表现非常差。
MLY--7. How large do the dev/test sets need to be?
这一章主要讲验证集和测试集需要多大比较合适?如果你的验证集只要100个样本,那么你的准确率提高的最小单位是1%,而不可能是0.1%,除非你的验证集增加到1000个样本。测试集样本也需要大到能足够表达你的模型效果才行,但是一般也不建议太大。
个人感悟:我觉得对于验证集和测试集的划分没有硬性规定,一般我将数据集分成训练:验证=9:1。
MLY--8. Establish a single-number evalution metric for your team to optimize
主要是讲模型的评价标准。最好能用一个评价标准(比如准确率)来判断模型优劣,而不是用多个标准(比如precision和recall)。主要是因为多个标准不好比较算法的效果。比如这个图:

其实如果要兼顾precision和recall,可以采用F1 score。
MLY--9. Optimizing and satisficing metrics
在权衡算法效果和速度的时候,除了可以用类似Accuracy-0.5*RunningTime的方式来比较,还可以采用其他方式,比如:假如可以接受的运行时间是100ms,那么就在这个限制条件下寻找准确率最高的算法。当然,如果你有多个限制条件,比如模型大小,运行时间,算法效果等,那可以在挨个满足条件的前提下找到最好的。还有一个例子是false positive rate和false negative rate,比如你希望在false positive rate为0的前提下降低你的false negative rate。
MLY--10. Having a dev set and metric speeds up iterations
当你拿到一个问题的时候,你要思考这个问题要用什么样的方式解决,然后把这个方式用代码表达出来,最后根据实验结果去思考之前的解决方式是否还有改进的地方,不断迭代。作者给出的这个图非常形象

MLY--11. When to change dev/test sets and metrics
作者提到在开始一个项目的时候,最好在一周内就能定义出验证集和测试集以及评价标准,而不是花太长的时间去制定和思考。后期当你发现你之前定义的验证集和测试集存在缺陷的时候,就应该尽快修改。这里有三个需要注意的点,如果你有这三种情况,那么就需要修改你的验证集了。
1、实际的数据分布和你验证集的数据分布不同。
2、在验证集上过拟合了。
3、你的评价标准和模型的优化方向不一致。比如你的一个图像分类算法,模型A的准确率比模型B的准确要高,但是有时候模型A容易漏判一些特殊图像,这是不能容忍的,而模型B不会,因此准确讲模型B的效果要比模型A要好。怎么改进呢?可以通过对漏判一些特殊图像做惩罚,而不仅仅用准确率来表征模型优劣。
MLY--12. Takeaways: Setting up development and test sets
1、你的验证集和测试集要尽可能从你实际应用场景的数据中获取。验证集和测试集不一定要跟你的训练数据有相同分布。(这点我认为最好还是训练集和验证集有相似的分布,如果训练数据和验证数据分布太大,你可能训练多次都难以得到好的效果,)
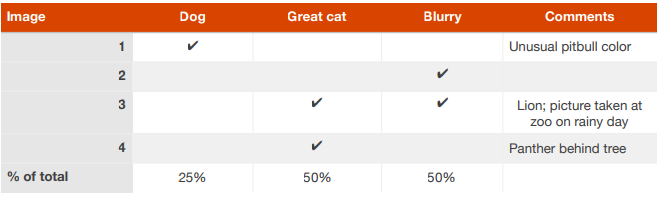
MLY--14. Evaluating multiple ideas in parallel during error analysis
将错误分类的图像在一张表格里面列出了,并comments可能的原因,然后分析原因,改进算法及预处理或者便签问题。可以通过分析挑选出各个优化类别的优先训练,各个击破来提高模型效果;
表格格式可以参考如下:
Machine Learning Yearning - Andrew NG的更多相关文章
- 学习笔记之Machine Learning by Andrew Ng | Stanford University | Coursera
Machine Learning by Andrew Ng | Stanford University | Coursera https://www.coursera.org/learn/machin ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 10) Large Scale Machine Learning & Application Example
本栏目来源于Andrew NG老师讲解的Machine Learning课程,主要介绍大规模机器学习以及其应用.包括随机梯度下降法.维批量梯度下降法.梯度下降法的收敛.在线学习.map reduce以 ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 8) Clustering & Dimensionality Reduction
本周主要介绍了聚类算法和特征降维方法,聚类算法包括K-means的相关概念.优化目标.聚类中心等内容:特征降维包括降维的缘由.算法描述.压缩重建等内容.coursera上面Andrew NG的Mach ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 7) Support Vector Machines
本栏目内容来源于Andrew NG老师讲解的SVM部分,包括SVM的优化目标.最大判定边界.核函数.SVM使用方法.多分类问题等,Machine learning课程地址为:https://www.c ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 9) Anomaly Detection&Recommender Systems
这部分内容来源于Andrew NG老师讲解的 machine learning课程,包括异常检测算法以及推荐系统设计.异常检测是一个非监督学习算法,用于发现系统中的异常数据.推荐系统在生活中也是随处可 ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 4) Neural Networks Representation
Andrew NG的Machine learning课程地址为:https://www.coursera.org/course/ml 神经网络一直被认为是比较难懂的问题,NG将神经网络部分的课程分为了 ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 1) Linear Regression
Andrew NG的Machine learning课程地址为:https://www.coursera.org/course/ml 在Linear Regression部分出现了一些新的名词,这些名 ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 3) Logistic Regression & Regularization
coursera上面Andrew NG的Machine learning课程地址为:https://www.coursera.org/course/ml 我曾经使用Logistic Regressio ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 1) Introduction
最近学习了coursera上面Andrew NG的Machine learning课程,课程地址为:https://www.coursera.org/course/ml 在Introduction部分 ...
随机推荐
- ZK框架笔记3、窗体组件
<window title="My First window" border="normal" width="200px" closa ...
- Wireshark-配合tcpdump对Android(安卓)手机抓包
环境:Windows, 安装真机(可以获取Root权限), adb, Wireshark, tcpdump 原理: 使用 tcpdump 进行抓包, 然后用 Wireshark 进行分析 1.获取手机 ...
- android 屏幕适配原则
屏幕大小 1.不同的layout Android手 机屏幕大小不一,有480x320,640x360,800x480.怎样才能让App自动适应不同的屏幕呢? 其实很简单,只需要在res目录下创建不同的 ...
- config.sql
# mysql服务器注释支持# #到该行结束# -- 到该行结束 # /* 行中间或多个行 */ drop database if exists db_warehouse;create databas ...
- python之版本管理
linux 环境下怎样对不同的python环境进行 方便的切换呢?update-alternatives工具能够非常方便的帮我们完成这个任务.而windows环境下可通过anaconda来完成. 1. ...
- hdu 4771 Stealing Harry Potter's Precious (2013亚洲区杭州现场赛)(搜索 bfs + dfs) 带权值的路径
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=4771 题目意思:'@' 表示的是起点,'#' 表示的是障碍物不能通过,'.' 表示的是路能通过的: ...
- 前端_basic
web: 分三部分:1.HTML:2.CSS:3.JavaScript. 1.HTML:用来构建网页的结构和内容: 2.CSS:用来给网页化妆,美化网页: 3.JavaScript:用来让网页呈现动态 ...
- ExtFormReturn,ext
package cn.edu.hbcf.common.vo; public class ExtFormReturn { /** * 是否成功 */ private boolean success; / ...
- cocos2dx触摸
两种方法其实都一样,CCLayer也是继承CCTouchDelegate. 1.继承CCTouchDelegate 添加触摸代理 CCTouchDispatcher* pDispatcher = CC ...
- hadoop单节点配置
首先按照官网的单机去配置,如果官网不行的话可以参考一下配置,这个是配置成功过的.但是不一定每次都成功 http://hadoop.apache.org/docs/r2.6.5/ centos 6.7 ...