使用 Solr 构建企业级搜索服务器
最近因项目需要一个全文搜索引擎服务, 在考察了Lucene及Solr后,我们选择了Solr. 本文简要记录了基于Solr搭建一个企业搜索服务器的过程.网上的资料太多千篇一律,也可能版本不同,总之在参照的时候并不顺利,因此在通过官网的介绍并逐步实践的基础上,我们整理了这个文档,希望能帮助到有类似需求的大家.
- Solr 介绍
- Solr 是一个基于Lucene技术的企业级搜索应用服务器, 运行在JVM环境中, 对外以类似webservice http模式提供接口.可简单的通过配置的形式实现一个企业级的搜索服务.
- 安装与部署
- JDK环境配置
安装配置jdk, 并设置 JAVA_HOME 环境变量,
ps: 楼主最开始使用的是1.8的版本, 也挺正常, 但后面因为在尝试导入sqlserver 2014数据库数据的时候,可能是楼主下载的mssql-jdbc.jar 包比较新的原因, 总是出现类似版本过低的提示, 便直接升级到了最新的jdk11版本. - 下载Solr包及配置运行环境
- 去Solr官网下载程序包 ,楼主下载了最新的7.5版本 http://www.apache.org/dyn/closer.lua/lucene/solr/7.5.0
- Solr 本身内置了Severlet, 故可直接运行, 当然如果不习惯,也可以将其挂在类似 tomcat 等其他Serverlet 容器下运行.
- 将下载的Solr 包解压到合适位置后, 在其bin路径下, 执行 solr start后, 如出现下面的提示则表示环境正常了.

此时便可通过浏览器访问 http://localhost:8983, 一切正常的话便可预见类似下面的管理中心界面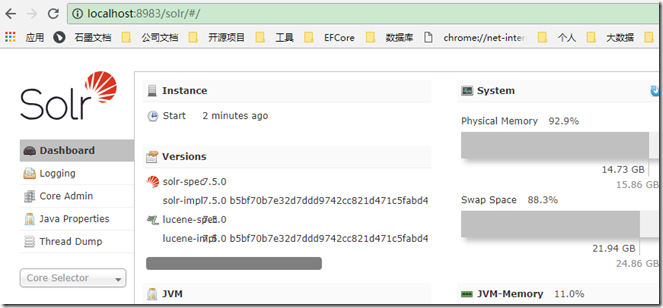
若出现错误, 通常可能为jdk环境没有配置正常,可通过提示对应处理. - 创建索引库 Core
- 在 server\solr 目录下,新建文件夹,本文以创建一个用于搜索物料产品的索引库为例. 姑且取名为 icvip 为例, 并默认配置[ server\solr\configsets\_default\conf ] 复制到此路径下.
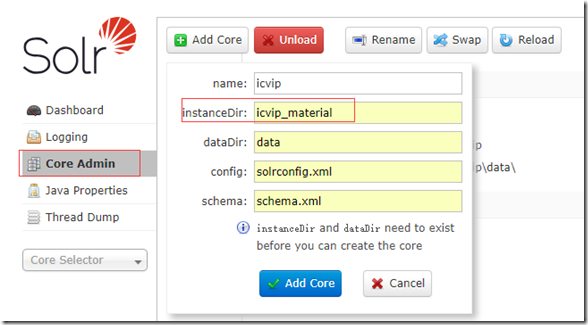
- 在管理中心界面中,选择左侧的 Core Admin 菜单,创建一个新的 Core. 本处将name设置为icvip,instanceDir 设置为icvip, 注意下面的提示:instanceDir 和 DataDir 一定要在此步骤之前存在,这也是我们为何要在界面创建之前先做第一步的原因.参考截图如下
- 正常添加后, 我们便可以对这个索引库做操作了,如导入数据,分词器,上传文档,查询测试....参见如下截图中的左边菜单

- 中文分词器ik-analyzer
为了更好的支持中文分词,我们此处引入ik分词器. - 可通过maven仓库下载最新的ik分词器的jar包. https://search.maven.org/search?q=com.github.magese, 并将其放在server\solr-webapp\webapp\WEB-INF\lib 目录下.
- 修改server\solr\icvip\conf\managed-schema配置,添加一个fieldType启用ik分词器.
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
- 重启Solr服务,并尝试在 Analysis 中选择 text_ik 测试是否生效,如下所示

- 从数据库导入数据源
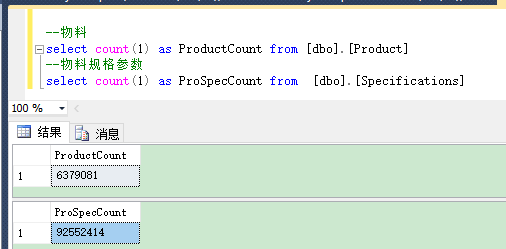
- 有了以上的配置后, 我们的搜索库已经准备好了,接下来就该往其添加索引数据了.当然你可以添加其支持的各种数据格式, 如documents菜单下的Document Type所列.本处介绍另外一种形式的数据源,即直接从数据库导入数据.在正式导入之前,我们先简单介绍一下导入数据的内容,本文以一个物料及其规格参数列表为例, 其关系为 1物料:n规格参数 , 数据量大概为 物料表 638 万条, 参数规格表 9255万条, 数据库文件约为15G左右.
- 前文已说, Solr 是基于java平台下的产物, 需要下载对应的驱动来支持数据库连接,其中 sqlserver 可通过 https://docs.microsoft.com/zh-cn/sql/connect/jdbc/download-microsoft-jdbc-driver-for-sql-server?view=sql-server-2017 下载对应的jar包,mysql 对应下载地址为 https://www.mysql.com/products/connector/ .
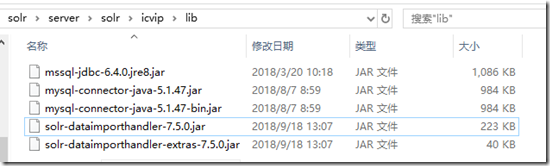
- 在Core目录下,新建 lib 文件夹,将solr-dataimporthandler 和 数据库连接驱动 jar包拷贝到此目录.
- 添加Dataimport 支持, server\solr\icvip\conf\solrconfig.xml 添加 requestHandler , 注意如果有其他的 name=”/dataimport” 节点,请将其移除.,其中的 <str name=”config”>节点即为导入数据源的配置文件
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler> - 在当前目录下新建 data-config.xml文件, 如下所示
<?xml version="1.0" encoding="UTF-8"?>
<dataConfig>
<!--mysql数据源-->
<!--<dataSource type="JdbcDataSource"
driver="com.mysql.jdbc.Driver"
url="jdbc:mysql://localhost:3306/icvip_material?characterEncoding=utf8&useSSL=false"
user="root"
password="123456"/> -->
<!--sqlserver 数据源-->
<dataSource type="JdbcDataSource"
driver="com.microsoft.sqlserver.jdbc.SQLServerDriver"
url="jdbc:sqlserver://localhost:1433;DatabaseName=icvip_material"
user="sa"
password="123456"/> <document name="Products"> <!--产品实体-->
<entity name="Product" dataSource="dataSource" pk="ProductId"
query="SELECT * FROM Product">
<field column="ProductId" name="ProductId" />
<field column="CategoryId" name="CategoryId" />
<field column="PN" name="PN" />
<field column="Brand" name="Brand" />
<field column="Describe" name="Describe" />
<field column="ImageBigUrl" name="ImageBigUrl" />
<field column="ImageSmallUrl" name="ImageSmallUrl" />
<field column="DataSheetURL" name="DataSheetURL" />
<field column="Series" name="Series" />
<field column="ProductFamily" name="ProductFamily" />
<field column="CategoryName" name="CategoryName" />
<field column="PageUrl" name="PageUrl" /> <!--产品规格实体,关系为1产品:n产品规格-->
<entity name="Product_Spec" pk="SpecificationsId"
query="SELECT [Key],[Value] FROM specifications WHERE ProductId='${Product.ProductId}'">
<field column="Key" name="ProSpecKey" />
<field column="Value" name="ProSpecValue" />
</entity>
</entity>
</document>
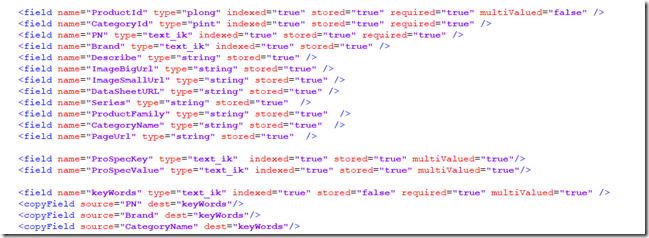
</dataConfig> - 配置server\solr\icvip\conf\managed-schema,以确认使用的分词规则
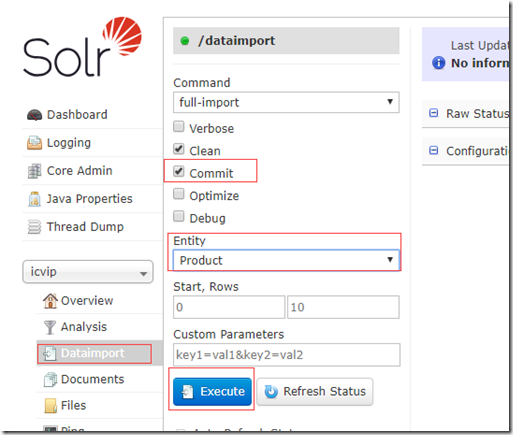
至于配置的含义,可参考https://wiki.apache.org/solr/DataImportHandler - 导入数据,切换到Dataimport 菜单, 选中实体导入. 接下来就是漫长的等待过程....
- 常用查询参数介绍, 重点需要关注 q/ fq/ hl/start/rows 几个参数. 可使用Query菜单进行测试.

后记: 经过以上步骤后,我们的Solr应用就基本结束. 不过因Solr作为一个企业级的搜索产品,功能原不止于此,文中并没有涵盖完全Solr的操作, 如关于增量索引设置问题,各位如果有需要可以在此基础上继续深入研究,附上Solr官网介绍的详细地址.https://wiki.apache.org/solr/
使用 Solr 构建企业级搜索服务器的更多相关文章
- Spring Data Solr教程(翻译) 开源的搜索服务器
Solr是一个使用开源的搜索服务器,它采用Lucene Core的索引和搜索功能构建,它可以用于几乎所有的编程语言实现可扩展的搜索引擎. Solr的虽然有很多优点,建立开发环境是不是其中之一.此博客条 ...
- Lucene/Solr企业级搜索学习资源
Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口.用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引:也可以通过Http GSol ...
- 使用Elasticsearch 与 NEST 库 构建 .NET 企业级搜索
使用Elasticsearch 与 NEST 库 构建 .NET 企业级搜索 2015-03-26 dotNET跨平台 最近几年出现的云计算为组织和用户带来了福音.组织对客户的了解达到前所未有的透彻, ...
- java 框架-企业级搜索 Solr
https://blog.csdn.net/cs_hnu_scw/article/details/79388080 一:Solr简介 Solr是一个独立的企业级搜索应用服务器,它对外提供类 ...
- Apache Solr采用Java开发、基于Lucene的全文搜索服务器
http://docs.spring.io/spring-data/solr/ 首先介绍一下solr: Apache Solr (读音: SOLer) 是一个开源.高性能.采用Java开发.基于Luc ...
- 架构师成长之路6.6 DNS服务器搭建(构建企业级DNS)
点击返回架构师成长之路 架构师成长之路6.6 DNS服务器搭建(构建企业级DNS) 采用LVS-DR模式负载均衡,多IDC,多套DNS集群,通过master-slave技术保证dns配置的一致性. 1 ...
- SOLR搭建企业搜索平台
一. SOLR搭建企业搜索平台 运行环境: 运行容器:Tomcat6.0.20 Solr版本:apache-solr-1.4.0 分词器:mmseg4j-1.6.2 词库:sogou-dic ...
- Hadoop专业解决方案-第12章 为Hadoop应用构建企业级的安全解决方案
一.前言: 非常感谢Hadoop专业解决方案群:313702010,兄弟们的大力支持,在此说一声辛苦了,春节期间,项目进度有所延迟,不过元宵节以后大家已经步入正轨, 目前第12章 为Hadoop应用构 ...
- Python 和 Elasticsearch 构建简易搜索
Python 和 Elasticsearch 构建简易搜索 作者:白宁超 2019年5月24日17:22:41 导读:件开发最大的麻烦事之一就是环境配置,操作系统设置,各种库和组件的安装.只有它们都正 ...
随机推荐
- sql:日期操作注意的,如果以字符串转日期时的函数,因为数据量大,会出问题
---1.以日期字符操作转换日期 如果是VIP1生日不对,可以以上传的数据日期为生日 begin declare @NowBirthday datetime, @birthday datetime,@ ...
- jQuery ajax调接口时跨域
解决方法提炼 一.jsonp方法 在前端ajax配置jsonp参数,在后台配置jsonp设置,具体方法自行百度 二. 参考同源策略 把前端静态页面放在tomcat内webapp下,和后台文件同目录, ...
- ERROR:Tried to register widget id ==basemapGalleryDiv but that id is already registered解决办法
在ArcGIS Server开发中,遇到DIV已经被注册的情况,不能对原DIV内容进行更新.这里需要调用Dojo的destroyRecursive()方法,逐个销毁该Widget下的子元素及其后代元素 ...
- Android MediaPlayer播放音乐并实现进度条
提前工作,往sd卡里放音乐文件 1.布局文件main.xml <?xml version="1.0" encoding="utf-8"?> < ...
- margin的auto的理解 top,left[,bottom,right] position
auto auto 总是试图充满父元素 margin有四个值: All the margin properties can have the following values: auto - the ...
- HTML 5篇(持续更新)
1.sessionStorage .localStorage 和 cookie 之间的区别 (一)共同点:都是保存在浏览器端,且同源的. (二)区别:cookie数据始终在同源的http请求中携带(即 ...
- SpringMVC学习(三)——基于注解配置的springMVC项目
可运行的附件地址:http://files.cnblogs.com/files/douJiangYouTiao888/springWithAnnotation.zip 项目说明: 作者环境:maven ...
- Session和Cookie详解(1)
面试常问的有关session和cookie的问题: 1.session在分布式环境下怎么解决 2.集群下如何保证session踩中 3.cookie的大小 4.服务器怎么识别一个用户的 5.sessi ...
- Linq批量建表
public JsonResult CreateTable() { db = new RZBDbContext(); var query = (from c in db.Clients select ...
- 【Leetcode】【Medium】Repeated DNA Sequences
All DNA is composed of a series of nucleotides abbreviated as A, C, G, and T, for example: "ACG ...