$用python-docx模块读写word文档
工作中会遇到需要读取一个有几百页的word文档并从中整理出一些信息的需求,比如产品的API文档一般是word格式的。几百页的文档,如果手工一个个去处理,几乎是不可能的事情。这时就要找一个库写脚本去实现了,而本文要讲的python-docx库就能满足这个需求。
安装
pip install python-docx
写docx文件
示例代码:
# coding:utf-8
# 写word文档文件
import sys
from docx import Document
from docx.shared import Inches
def main():
reload(sys)
sys.setdefaultencoding('utf-8')
# 创建文档对象
document = Document()
# 设置文档标题,中文要用unicode字符串
document.add_heading(u'我的一个新文档',0)
# 往文档中添加段落
p = document.add_paragraph('This is a paragraph having some ')
p.add_run('bold ').bold = True
p.add_run('and some ')
p.add_run('italic.').italic = True
# 添加一级标题
document.add_heading(u'一级标题, level = 1',level = 1)
document.add_paragraph('Intense quote',style = 'IntenseQuote')
# 添加无序列表
document.add_paragraph('first item in unordered list',style = 'ListBullet')
# 添加有序列表
document.add_paragraph('first item in ordered list',style = 'ListNumber')
document.add_paragraph('second item in ordered list',style = 'ListNumber')
document.add_paragraph('third item in ordered list',style = 'ListNumber')
# 添加图片,并指定宽度
document.add_picture('e:/docs/pic.png',width = Inches(1.25))
# 添加表格: 1行3列
table = document.add_table(rows = 1,cols = 3)
# 获取第一行的单元格列表对象
hdr_cells = table.rows[0].cells
# 为每一个单元格赋值
# 注:值都要为字符串类型
hdr_cells[0].text = 'Name'
hdr_cells[1].text = 'Age'
hdr_cells[2].text = 'Tel'
# 为表格添加一行
new_cells = table.add_row().cells
new_cells[0].text = 'Tom'
new_cells[1].text = '19'
new_cells[2].text = '12345678'
# 添加分页符
document.add_page_break()
# 往新的一页中添加段落
p = document.add_paragraph('This is a paragraph in new page.')
# 保存文档
document.save('e:/docs/demo1.docx')
if __name__ == '__main__':
main()
执行以上代码会在'e:/docs/'路径下产生一个demo1.docx文件,其内容如下:

读docx文件
示例代码:
# coding:utf-8
# 读取已有的word文档
import sys
from docx import Document
def main():
reload(sys)
sys.setdefaultencoding('utf-8')
# 创建文档对象
document = Document('e:/docs/demo2.docx')
# 读取文档中所有的段落列表
ps = document.paragraphs
# 每个段落有两个属性:style和text
ps_detail = [(x.text,x.style.name) for x in ps]
with open('out.tmp','w+') as fout:
fout.write('')
# 读取段落并写入一个文件
with open('out.tmp','a+') as fout:
for p in ps_detail:
fout.write(p[0] + '\t' + p[1] + '\n\n')
# 读取文档中的所有段落的列表
tables = document.tables
# 遍历table,并将所有单元格内容写入文件中
with open('out.tmp','a+') as fout:
for table in tables:
for row in table.rows:
for cell in row.cells:
fout.write(cell.text + '\t')
fout.write('\n')
if __name__ == '__main__':
main()
假如在'e:/docs/'路径下有一个demo2.docx文档,其内如如下:

执行上面脚本后,输出的out.tmp文件的内容如下:
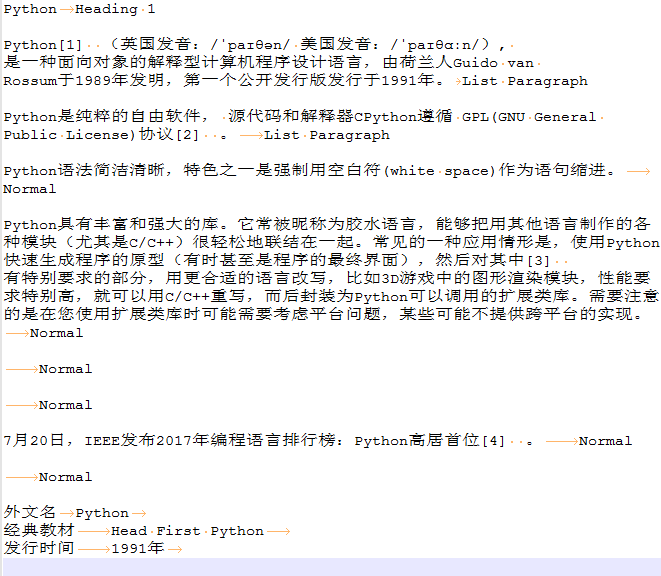
注意事项
- 如果段落中是有超链接的,那么段落对象是读取不出来超链接的文本的,需要把超链接先转换成普通文本,方法:全选word文档的所有内容,按快捷键Ctrl+Shift+F9即可。
遇到的问题
用pyinstaller打包时的一个问题
用pyinstaller工具(用法详见:python打包工具pyinstaller的用法)把使用到python-docx库的脚本打包成exe可执行文件后,双击运行生成的exe文件,报错:
docx.opc.exceptions.PackageNotFoundError: Package not found at 'C:\Users\ADMINI~1.PC-\AppData\Local\Temp\_MEI49~1\docx\templates\default.docx'
经过在stackoverflow上搜索,发现有人遇到过类似的问题(问题链接:cx_freeze and docx - problems when freezing),经过尝试,该问题的第二个回答可以解决这个问题:
I had the same problem and managed to get around it by doing the following. First, I located the default.docx file in the site-packages. Then, I copied it in the same directory as my .py file. I also start the .docx file with Document() which has a docx=... flag, to which I assigned the value: os.path.join(os.getcwd(), 'default.docx') and now it looks like doc = Document(docx=os.path.join(os.getcwd(), 'default.docx')). The final step was to include the file in the freezing process. Et voilà! So far I have no problem.
大概的解决步骤是这样的:
- 找到python-docx包安装路径下的一个名为
default.docx的文件,我是通过everything这个强大的搜索工具全局搜索找到这个文件的,它在我本地所在的路径是:E:\code\env\.env\Lib\site-packages\docx\templates - 把找到的default.docx文件复制到我的py脚本文件所在的目录下。
- 修改脚本中创建Document对象的方式:
从原来的创建方式:
document = Document()
修改为:
import os
document = Document(docx=os.path.join(os.getcwd(), 'default.docx'))
- 再次用pyinstaller工具打包脚本为exe文件
- 把default.docx文件复制到与生成的exe文件相同的路径下,再次运行exe文件,顺利运行通过,没有再出现之前的报错,问题得到解决。
随机推荐
- 【PM面试题】设计一个股价推送工具
这一轮面试时间比较短,问题在短时间内不能很全面展开,因此抓住一些关键点变得尤其重要,这里我记录下当时是怎么想这个问题的. 问题解析 子问题1:推送什么?从问题中看出我们需要推送的是股价,用户可以自定义 ...
- FreeRTOS系列第17篇---FreeRTOS队列
本文介绍队列的基本知识,具体源代码分析见<FreeRTOS高级篇5---FreeRTOS队列分析> 1.FreeRTOS队列 队列是基本的任务间通讯方式.能够在任务与任务间.中断和任务间传 ...
- SurvivalShooter学习笔记(三.敌人移动)
1.敌人和玩家若存活,敌人始终朝着玩家所在位置移动,所以要给玩家物体一个Tag:Player从而找到玩家 2.敌人的自动寻路使用Unity自带的NavMeshAgent寻路组件寻路,要先把场景中不动的 ...
- centos 6.5 安装图形界面【转】
最近想在centos 6.5上安装图形界面,在网上找到了方法.[原文链接] CentOS6相对于CentOS5的安装有了不少的进步,有不少默认的选项可以选择,如: Desktop :基本的桌面系统,包 ...
- PMPBOK 进度管理
项目进度计划提供详尽的计划,说明项目如何以及何时交付项目范围中定义的产品.服务和成功,是一种用于沟通和管理相关方期望的工具,为绩效报告提供了依据. 进度计划方法:关键路径发或敏捷方法.创建项目经度模型 ...
- 【BZOJ4550】小奇的博弈 博弈论
[BZOJ4550]小奇的博弈 Description 这个游戏是在一个1*n的棋盘上进行的,棋盘上有k个棋子,一半是黑色,一半是白色.最左边是白色棋子,最右边是黑色棋子,相邻的棋子颜色不同. 小 ...
- android studio 运行是,app标题栏不显示
解决办法:让所有的活动都继承 AppCompatActivity就行了,如: public class FirstActivity extends AppCompatActivity{ ... }
- 制作简易app个人总结
1.每次修改app.js或者其他路由js文件,都必须重启node app.js,否则修改不起作用!!! 2.<link rel="stylesheet" href=" ...
- Outlook Top of Information Store
Actually I got to thinking this might make a good blog post so I took a closer look - Try this: On t ...
- C# 利用StringBuilder提升字符串拼接性能
一个项目中有数据图表呈现,数据量稍大时显得很慢. 用Stopwatch分段监控了一下,发现耗时最多的函数是SaveToExcel 此函数中遍列所有数据行,通过Replace替换标签生成Excel行,然 ...