沉淀,再出发——在Hadoop集群之上安装hbase
在Hadoop集群之上安装hbase
一、安装准备
首先我们确保在ubuntu16.04上安装了以下的产品,java1.8及其以上,ssh,hadoop集群,其次,我们需要从hbase的官网上下载并安装这个产品。
二、开始安装
这里我介绍两种安装方式,一种是在伪分布式hadoop集群上安装hbase,另一种是在分布式hadoop集群上安装hbase。
2.1、下载hbase
无论是任何安装方式,首先我们需要下载hbase。在官网上点击清华大学的镜像来下载稳定版的hbase。
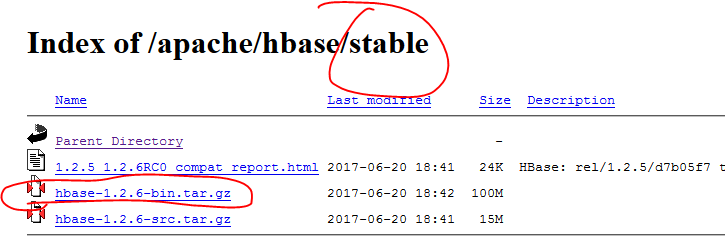
在下载之前,我们要明确自己想要下载的版本,如果没有特殊的要求,我们直接下载稳定版的即可,如果有特殊的版本限制,我们可以选择相应的版本,另外在我们选择版本的时候还要考虑版本的关联性和依赖性,因为hbase是建立在hadoop基础之上的,而hadoop是建立在jdk之上的,因此我们选择版本的时候要参考java和hadoop的版本,具体的参考标准我们可以查看官网。
在官网之中有着明确的支持、不支持、未测试的解释权。
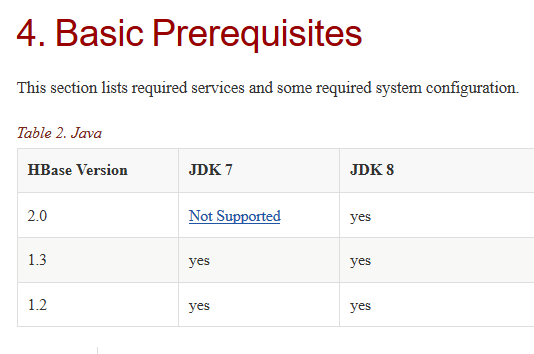
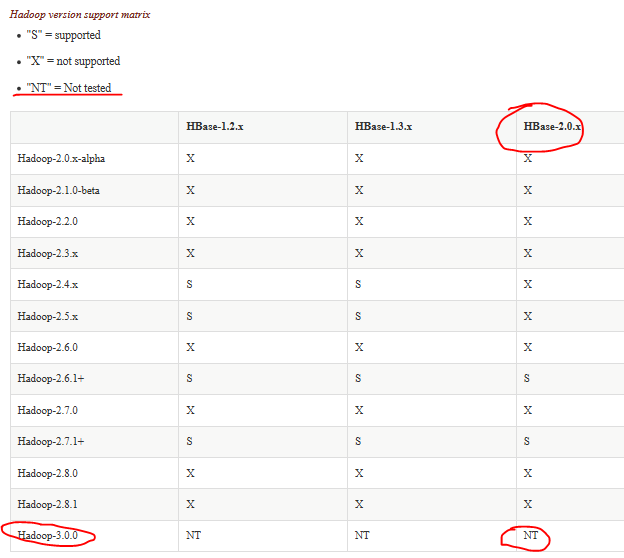
在这里,因为我们之前已经安装了jdk1.8.x和hadoop3.0,从上图看,我们的hadoop版本还不被最新的hbase版本支持,有两种方法,第一种卸载并下载支持的版本,第二种因为是NT,没有被测试,我们冒险安装一下hbase,在这里为了试验,我们选择第二种。
2.2、在伪分布式hadoop集群上安装hbase
我们将下载的安装包解压到我们需要的目录,并且修改该文件夹的权限为相应的用户和用户组,之后我们修改文件夹为最标准的名称,然后修改全局变量,并且对hbase内部的文件进行配置。
cd ~/Downloads
sudo tar -zxvf hbase-1.2.-bin.tar.gz -C ../
cd ../
sudo mv hbase-1.2. hbase
sudo chown -R grid@hadoop hbase
cd ./hbase/conf
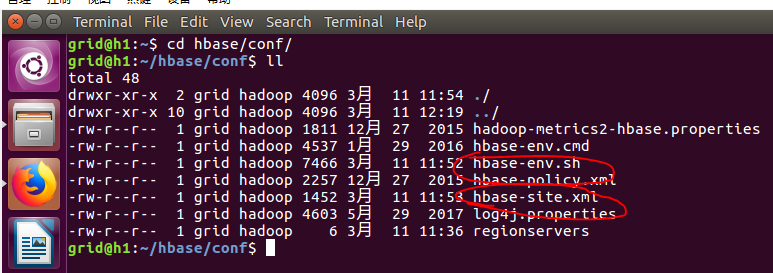
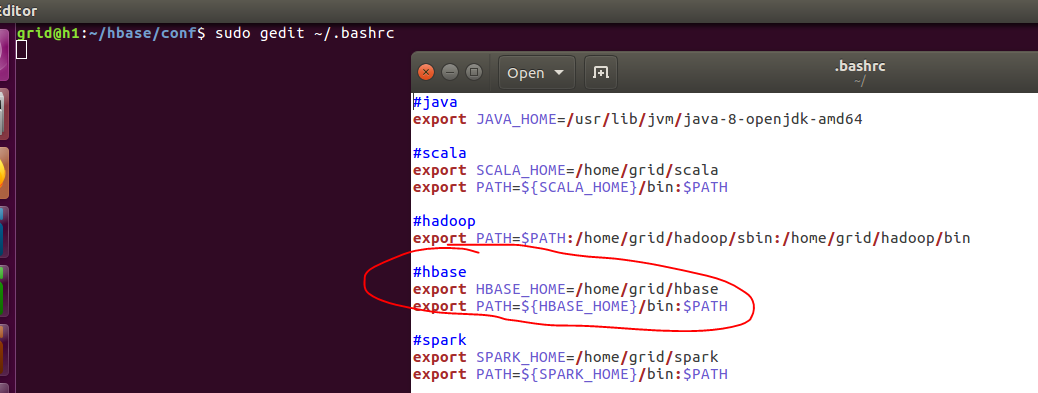
sudo gedit ~/.bashrc
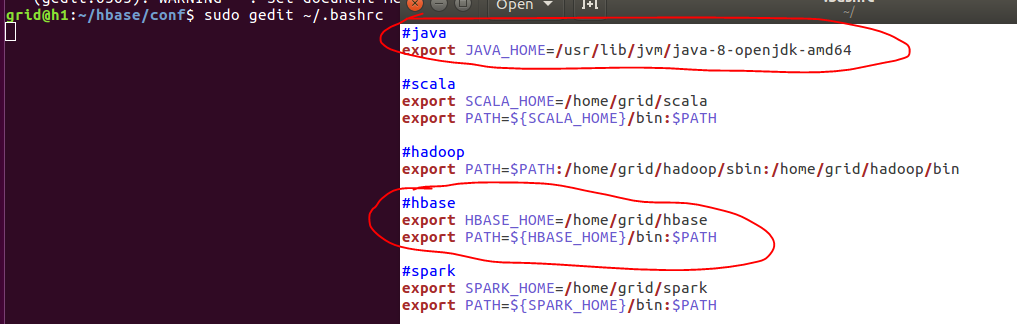
在其中加入hbase的全局参数:
2.2.1、修改hbase-env.sh
sudo gedit hbase-env.sh
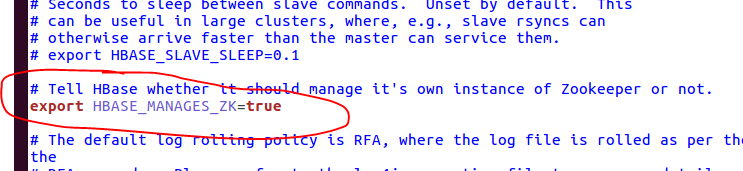
在这里,我们找到这一句话,并且将注释去掉,这样我们就可以使用hbase自带的zookeeper了。有的教程中还将java_home配置了一下,这里我们要明白其中的本质,如果我们在全局变量文件(~/.bashrc)中已经配置过了,在这个地方我们可以不用配置,有的教程还配置了HBASE_CLASSPATH=/home/grid/hadoop中的某一个目录,在我们新的版本之中是不需要的,因此,我们只打开这一句话。
2.2.2、修改hbase-site.xml
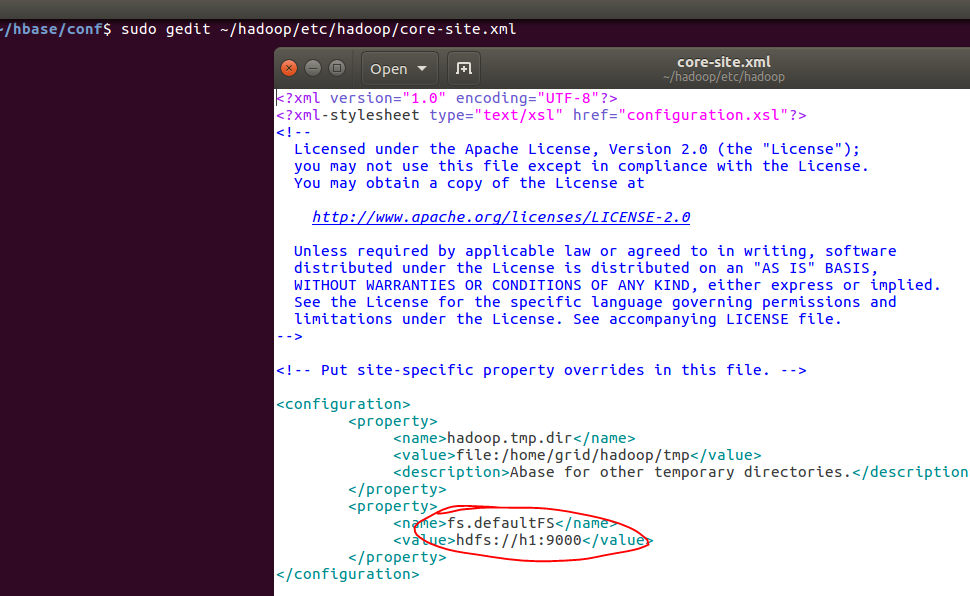
另外我们还需要进行一些细微的配置,首先修改hbase的根目录,这里我们使用hdfs文件系统,将其放到主目录之下,不用真的在hdfs创建这个文件,系统会帮助我们创建,在这里要特别特别的注意,如果使用hdfs,意味着我们需要连接到这个文件系统,因此我们需要使用自己的IP+Port,也就是自己命名的主机(localhost)和Port(在这里我们不能照搬照抄,一定要修改成自己主机上的,具体从hadoop的etc/hadoop/core-site.xml文件中找到),这点非常非常重要,不然就会显示zookeeper不能正常启动,找不到节点等等信息;
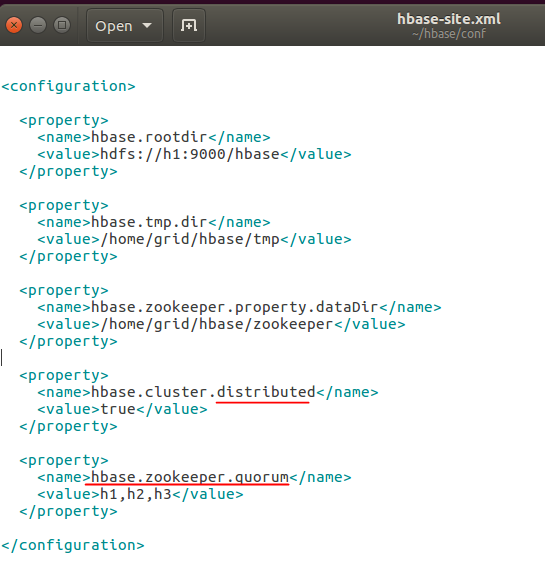
其次,我们修改hbase的临时文件目录,这样可以确保重新加电自检的时候能够正确载入,在断电的时候不会被清除。然后我们修改zookeeper的数据存放路径,一般就在hbase下面创建一个目录存放了,当然我们也不用自己创建,系统会帮我们创建的,最后,我们使得我们的伪分布式生效。至此,我们完成了一些基本的配置,接下来就是运行了。
<property>
<name>hbase.rootdir</name>
<value>hdfs://h1:9000/hbase</value>
</property> <property>
<name>hbase.tmp.dir</name>
<value>/home/grid/hbase/tmp</value>
</property> <property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/grid/hbase/zookeeper</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>

在运行之前我们需要先运行hdfs,也就是start-dfs.sh。之后我们运行hbase,start-hbase.sh。
start-dfs.sh
start-hbase.sh
测试是否安装成功:

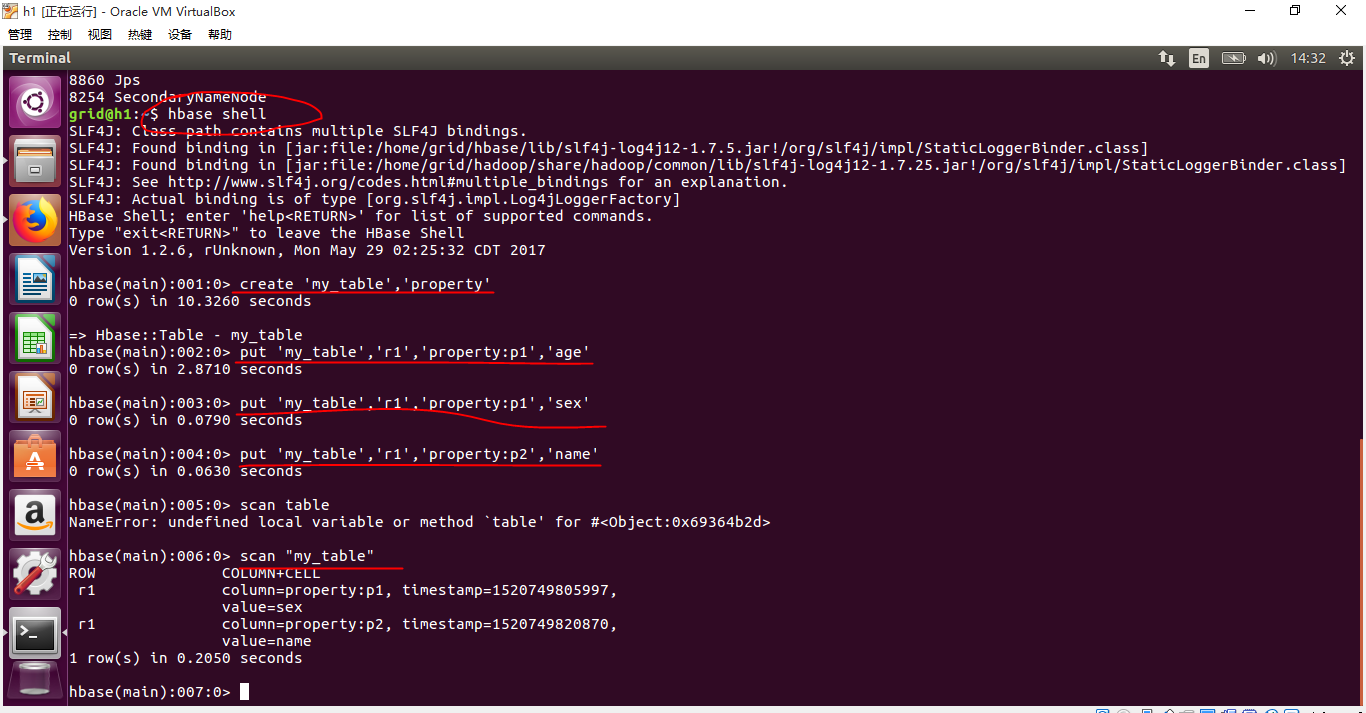
接着我们使用hbase shell为我们创建程序,并工作,如果遇到问题,我们主要从这几个地方查找问题,第一,我们安装的版本是不是完全匹配,第二,我们的配置是不是完全正确,第三我们的hdfs进程和hbase进程是不是完全打开,第四,zookeeper是不是正常打开并且工作,一定要注意端口的设置,在这里我们并不使用yarn,我们只是借助hdfs来存放我们的数据库而已,因为在我们的虚拟机上打开yarn一般资源就会被消耗干净了,所以我们只是用MapReduce就好了。至此我们可以进行CRUD的操作了。
2.3、在hadoop集群上安装hbase
在2.2的基础上我们继续进行配置使得可以实现我们的真正分布式hbase部署。因此请先看2.2的配置。
2.3.1、继续配置hbase-site.xml
增加如下配置,意思为我们让zookeeper为我们投票选举出一个最适合做某个任务的机器,这里我们从这三台机器上投票,一定要记得这个机器的数目一定要为奇数,只有这样我们才能得到最公平的投票。
<property>
<name>hbase.zookeeper.quorum</name>
<value>h1,h2,h3</value>
</property>
我们最终的配置为:
2.3.2、修改regionservers文件
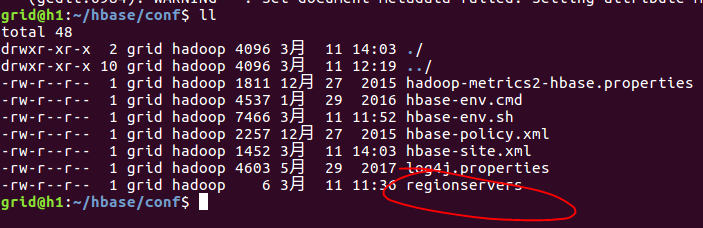
在其中加入h2,h3:

2.3.3、将配置好的文件分发到各个节点
到了这里我们并没有完成所有的任务,还需要分发到其他的物理节点上,我们依旧使用ssh中的secure copy,scp命令来完成,当然我们需要打开三台虚拟机来完成这个操作。
scp -r ~/hbase grid@h2:~/
scp -r ~/hbase grid@h3:~/
之后我们还要进行配置,我想这个配置读者应该能想到,那就是对于h2,h3两台主机,在全局变量之中将hbase的变量注入到其中,实现无目录启动。也就是将如下的内容加入到slaves机器里面。然后我们source一下使得文件修改生效。
2.3.4、运行分布式hbase
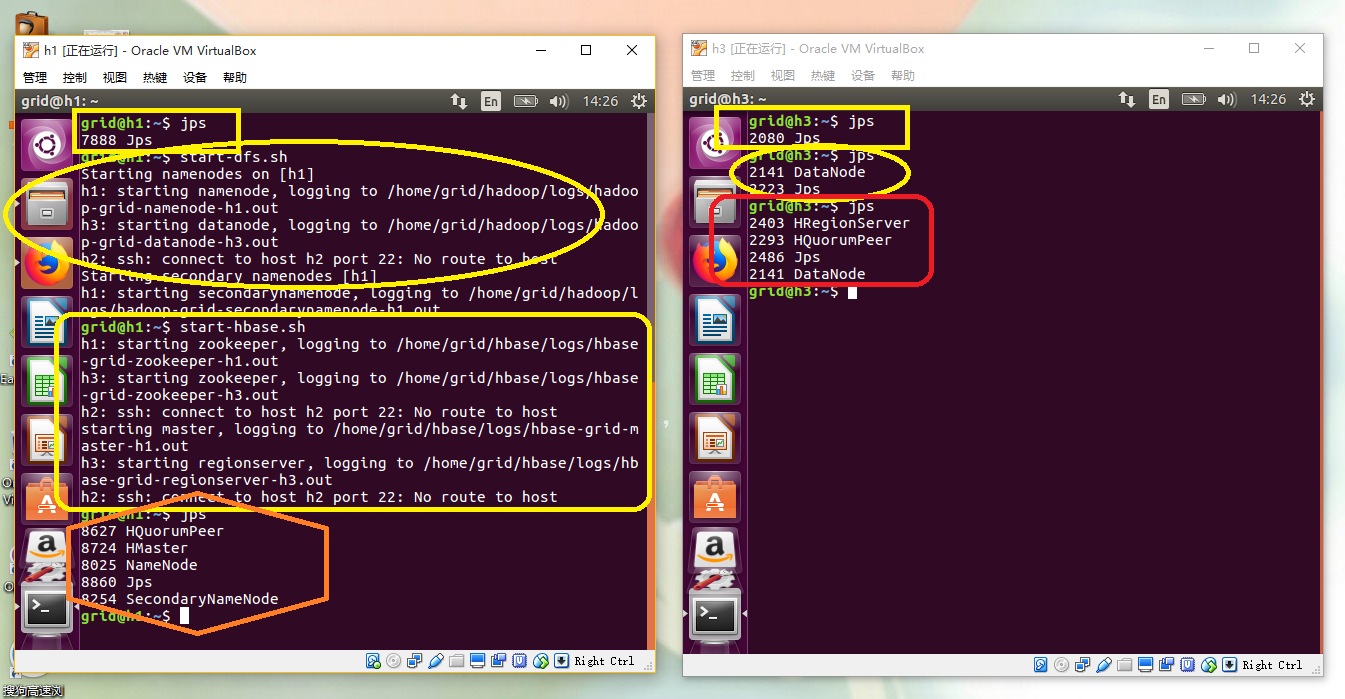
我们打开三台虚拟节点,在h1上面,我们使用start-dfs.sh打开hdfs,之后我们使用start-hbase.sh打开hbase和zookeeper。这里的打开是全面的,就是主从机器都同时做各自的事情了。这里因为性能的限制,我打开了h1和h3来进行测试,主要的内容如下:
开启:
运行:在运行的时候我们还可以通过web查看运行状态:localhost:16010
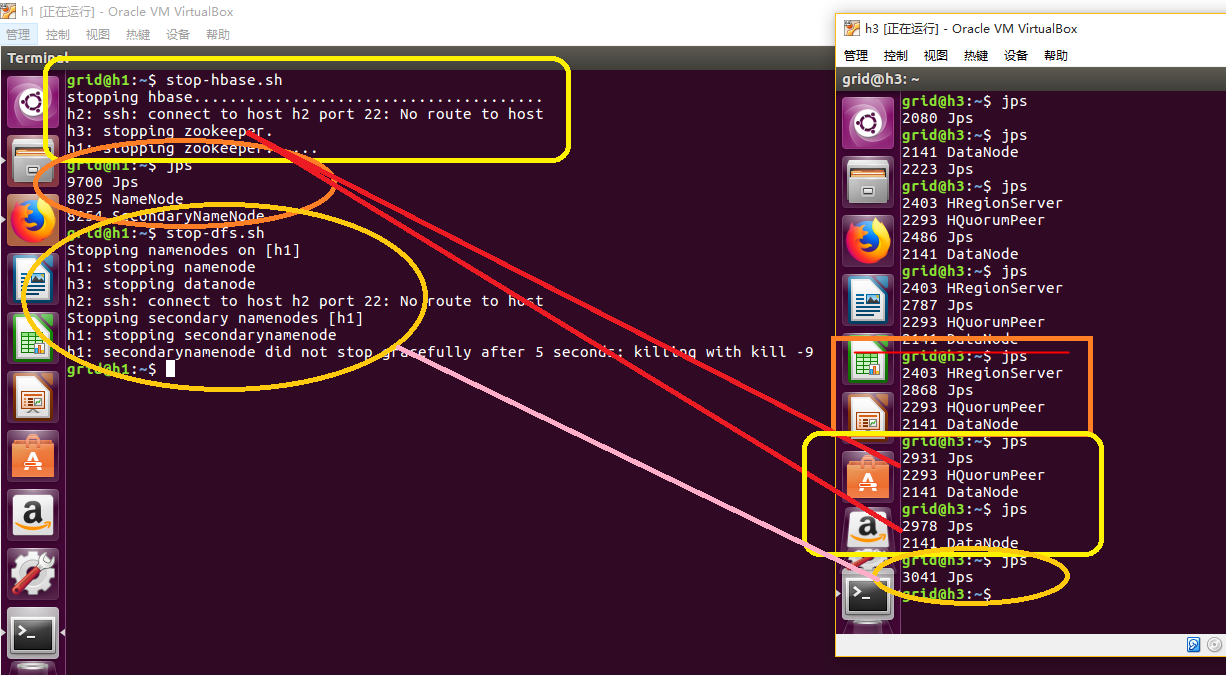
关闭:
至此,我们已经在三个虚拟节点上安装了hdfs、hbase、spark等产品,让我们一起打开这些产品试一下:
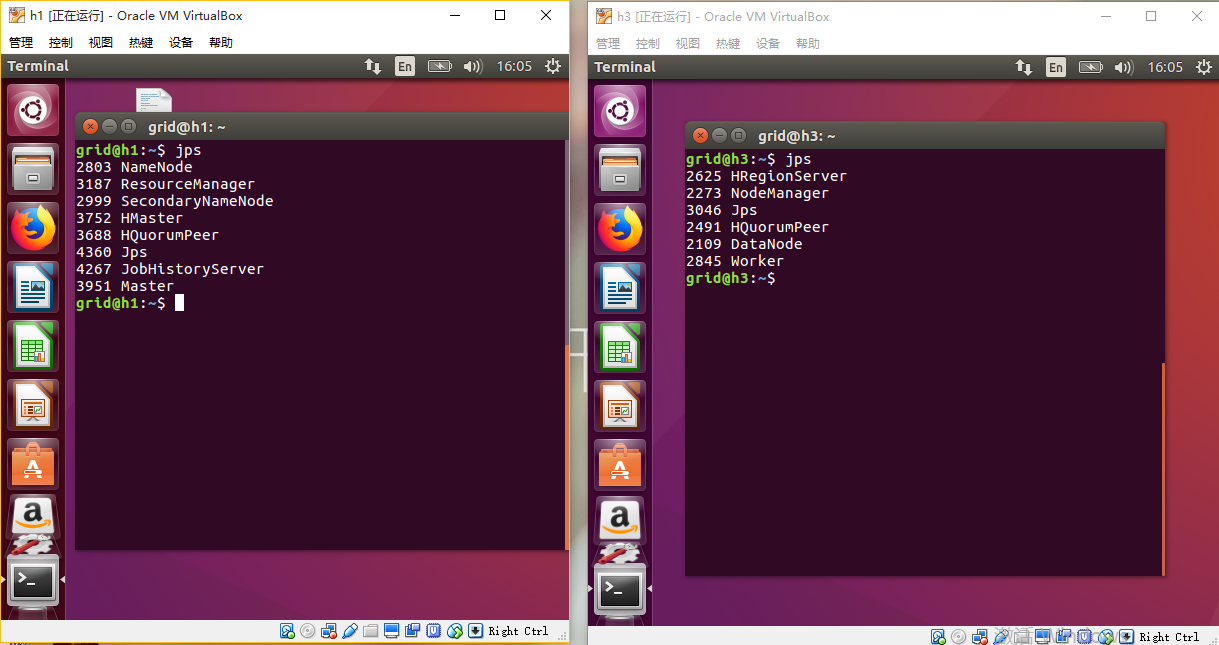
三、总结
安装一次新的产品对我的收获是很大的,在这个过程中,我可以学到很多的新的东西,并且以前认为很简单的东西真正在操作的时候总是出现各种的问题,仔细查找了才发现有的问题是不应该出现的低级错误,因此每一次的总结都是一次进步。
沉淀,再出发——在Hadoop集群之上安装hbase的更多相关文章
- 沉淀,再出发——在Hadoop集群的基础上搭建Spark
在Hadoop集群的基础上搭建Spark 一.环境准备 在搭建Spark环境之前必须搭建Hadoop平台,尽管以前的一些博客上说在单机的环境下使用本地FS不用搭建Hadoop集群,可是在新版spark ...
- Hadoop集群搭建安装过程(三)(图文详解---尽情点击!!!)
Hadoop集群搭建安装过程(三)(图文详解---尽情点击!!!) 一.JDK的安装 安装位置都在同一位置(/usr/tools/jdk1.8.0_73) jdk的安装在克隆三台机器的时候可以提前安装 ...
- Hadoop集群搭建安装过程(二)(图文详解---尽情点击!!!)
Hadoop集群搭建安装过程(二)(配置SSH免密登录)(图文详解---尽情点击!!!) 一.配置ssh无密码访问 ®生成公钥密钥对 1.在每个节点上分别执行: ssh-keygen -t rsa(一 ...
- Ganglia监控Hadoop集群的安装部署[转]
Ganglia监控Hadoop集群的安装部署 一. 安装环境 Ubuntu server 12.04 安装gmetad的机器:192.168.52.105 安装gmond的机 器:192.168.52 ...
- 在Hadoop集群上,搭建HBase集群
(1)下载Hbase包,并解压:这里下载的是0.98.4版本,对应的hadoop-1.2.1集群 (2)覆盖相关的包:在这个版本里,Hbase刚好和Hadoop集群完美配合,不需要进行覆盖. 不过这里 ...
- Apache Hadoop集群离线安装部署(三)——Hbase安装
Apache Hadoop集群离线安装部署(一)——Hadoop(HDFS.YARN.MR)安装:http://www.cnblogs.com/pojishou/p/6366542.html Apac ...
- Apache Hadoop集群离线安装部署(二)——Spark-2.1.0 on Yarn安装
Apache Hadoop集群离线安装部署(一)——Hadoop(HDFS.YARN.MR)安装:http://www.cnblogs.com/pojishou/p/6366542.html Apac ...
- Apache Hadoop集群离线安装部署(一)——Hadoop(HDFS、YARN、MR)安装
虽然我已经装了个Cloudera的CDH集群(教程详见:http://www.cnblogs.com/pojishou/p/6267616.html),但实在太吃内存了,而且给定的组件版本是不可选的, ...
- Hadoop集群环境安装
转载请标明出处: http://blog.csdn.net/zwto1/article/details/45647643: 本文出自:[zhang_way的博客专栏] 工具: 虚拟机virtual ...
随机推荐
- Python多线程&进程
一.线程&进程 对于操作系统来说,一个任务就是一个进程(Process),比如打开一个浏览器就是启动一个浏览器进程,打开一个记事本就启动了一个记事本进程,打开两个记事本就启动了两个记事本进程, ...
- Zookeeper概念学习系列之zab协议
不多说,直接上干货! 上一章讨论了paxos算法,把paxos推到一个很高的位置. Zookeeper概念学习系列之paxos协议 但是,paxos有没有什么问题呢?实际上,paxos还是有其自身的缺 ...
- CountDownLatch同步工具--控制多个线程执行顺序
好像倒计时计数器,调用CountDownLatch对象的countDown方法就将计数器减1,当到达0时,所有等待者就开始执行. java.util.concurrent.CountDownLatch ...
- Golang教程:指针
什么是指针 指针是存储一个变量的内存地址的变量. 在上图中,变量 b 的值是 156,存储在地址为 0x1040a124 的内存中.变量 a 存储了变量 b 的地址.现在可以说 a 指向b. 指针的声 ...
- spring_boot启动报错
配置好pom文件后,在controller加注解,如下: 运行后报错!!! 发现配置加的是多此一举,修改为下边的,运行OK
- javaweb带父标签的自定义标签
1.完整的示例代码:要实现的功能是父标签中有name属性,子标签将父标签的name属性值打印到jsp页面上. 1.1 父类和子类的标签处理器类 testParentTag.java package c ...
- SZU 7
A - Megacity sqrtf是个坑 #include <iostream> #include <string> #include <cstring> #in ...
- 四层协议和Socket编程
<四层协议图> <Soclet编程模型图>
- Java 8 读取文件
以前的Java版本中读取文件非常繁琐,现在比较简单.使用Java8的Files以及Lambda,几句代码就可以搞定. public static String getXml() { StringBuf ...
- html和css入门 (四)
背景样式 背景颜色 属性名 background-color 属性值 合法的颜色的名,比如:red:十六进制值,比如:#ff0000:RGB 值,比如:rgb(255,0,0) 默认值 transpa ...