爬虫入门【10】Pyspider框架简介及安装说明
Pyspider是python中的一个很流行的爬虫框架系统,它具有的特点如下:
1、可以在Python环境下写脚本
2、具有WebUI,脚本编辑器,并且有项目管理和任务监视器以及结果查看。
3、支持多种数据库
4、支持定义任务优先级,自动重试链接。。。
5、分布式架构
等等优点。
pyspider的设计基础是:以python脚本驱动的抓取环模型爬虫。
教程: http://docs.pyspider.org/en/latest/tutorial/
文档: http://docs.pyspider.org/
发布版本: https://github.com/binux/pyspider/releases
入门范例
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = {
}
@every(minutes=24 * 60)
def on_start(self):
self.crawl('http://scrapy.org/', callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a[href^="http"]').items():
self.crawl(each.attr.href, callback=self.detail_page)
def detail_page(self, response):
return {
"url": response.url,
"title": response.doc('title').text(),
}
【插入图片,Pyspider界面】
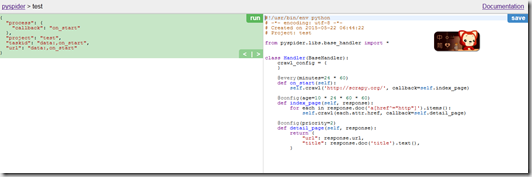
代码简单介绍
def on_start(self):
这是脚本的入口节点,当我们点击run的时候,程序会自动调用这个函数。
self.crawl(url, callback=self.index_page):
这时最重要的API,将会添加新任务,大部分选项使用crawl的参数来指定。
def index_page(self, response):
这个方法得到一个response对象,然后通过PyQuery的doc命令来解析。
def detail_page(self, response):
返回一个dict对象作为结果。这个结果可以保存到数据库中。
我们还可以在脚本中自定义函数或者对象。
【插入图片,运行界面】
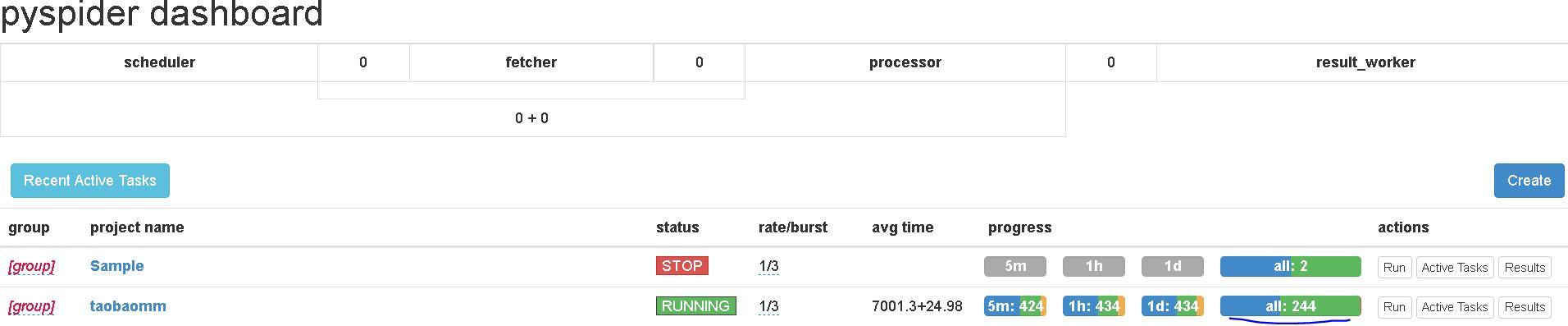
安装
推荐使用Pycharm,在Project Interpreter里面添加pyspider,目前最新的版本是0.3.9.
或者使用pip命令安装。
今天来不及把整个项目内容讲完了,明天继续。
爬虫入门【10】Pyspider框架简介及安装说明的更多相关文章
- 爬虫基础(五)-----scrapy框架简介
---------------------------------------------------摆脱穷人思维 <五> :拓展自己的视野,适当做一些眼前''无用''的事情,防止进入只关 ...
- 爬虫开发7.scrapy框架简介和基础应用
scrapy框架简介和基础应用阅读量: 1432 scrapy 今日概要 scrapy框架介绍 环境安装 基础使用 今日详情 一.什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数 ...
- 10.scrapy框架简介和基础应用
今日概要 scrapy框架介绍 环境安装 基础使用 今日详情 一.什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被 ...
- python爬虫入门(六) Scrapy框架之原理介绍
Scrapy框架 Scrapy简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬 ...
- 爬虫入门之Scrapy 框架基础功能(九)
Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非 ...
- python爬虫入门10分钟爬取一个网站
一.基础入门 1.1什么是爬虫 爬虫(spider,又网络爬虫),是指向网站/网络发起请求,获取资源后分析并提取有用数据的程序. 从技术层面来说就是 通过程序模拟浏览器请求站点的行为,把站点返回的HT ...
- 人工智能 tensorflow框架-->简介及安装01
简介:Tensorflow是google于2015年11月开源的第二代机器学习框架. Tensorflow名字理解:图形边中流动的数据叫张量(Tensor),因此叫Tensorflow 既 张量流动 ...
- 爬虫入门之Scrapy框架实战(新浪百科豆瓣)(十二)
一 新浪新闻爬取 1 爬取新浪新闻(全站爬取) 项目搭建与开启 scrapy startproject sina cd sina scrapy genspider mysina http://roll ...
- 爬虫入门之Scrapy框架基础框架结构及腾讯爬取(十)
Scrapy终端是一个交互终端,我们可以在未启动spider的情况下尝试及调试代码,也可以用来测试XPath或CSS表达式,查看他们的工作方式,方便我们爬取的网页中提取的数据. 如果安装了 IPyth ...
随机推荐
- Android USB转串口通信开发基本流程
好久没有写文章了,年前公司新开了一个项目,是和usb转串口通信相关的,需求是用安卓平板通过usb转接后与好几个外设进行通信.一直忙到近期,才慢慢闲下来,趁着这个周末不忙.记录下usb转串口通信开发的基 ...
- javascript 反调试 监听用户打开了Chrome devtool
let div = document.createElement('div'); let loop = setInterval(() => { console.log(div); ...
- 在Visual Studio 2013顯示SCSS詳細錯誤訊息
在WebEssentials套件加持之下,Visual Studio 2013可以直接編修SCSS,每次存檔自動編譯出css.min.css及.map,非常方便.但初心者如我,寫錯語法在所難免,一旦造 ...
- atitit.恒朋无纸化彩票系统数据接入通信协议
atitit.恒朋无纸化彩票系统数据接入通信协议 深圳市恒朋科技开发有限公司 Shenzhen Helper Science & Technology Co., Ltd. 恒朋无纸化彩票系统数 ...
- TextView中超链接拦截
TextView中的超链接点击时,其实是通过Intent方式的,因此会调用Activity中的startActivity(Intent intent)方法,所以可在此方法中做些简单的拦截操作 例如拦截 ...
- 选择如何的系统更能适合App软件开发人员?
手机这个词早已经同吃喝玩乐一样.成为了人们生活中的必备元素. 尤其是iPhone一炮走红之后,不但手机世界发生了巨大变化,整个科技产业似乎都格局性的改变.直至今日,手机市场的竞争更是日趋白炽化,这就给 ...
- socket failed:EACCES(Permission denied)
1. 权限问题 安卓端写的TCP协议软件报错原因是建立的套接字没有限权对外连接. 在AndroidManifest.xml中,加上这一句话,取得权限. <uses-permission andr ...
- python-hanoi
#!/usr/bin/env python #-*- coding:utf-8 -*- ############################ #File Name: hanoi.py #Autho ...
- JS高程3:DOM-DOM操作技术
动态脚本 加载外部脚本 方式一,直接写代码: var script = document.createElement("script"); script.type = " ...
- 李洪强iOS开发之iOS社区收集
李洪强iOS开发之iOS社区收集 项目 简述 github 全球最大的代码仓库,无论是iOS开发还是Android开发没有人不知道这个网站,它也是一个社区,你可以去follow(关注)某些人或公司. ...