深度学习应用系列(三)| autokeras使用入门
我们在构建自己的神经网络模型时,往往会基于预编译模型上进行迁移学习。但不同的训练数据、不同的场景下,各个模型表现不一,需要投入大量的精力进行调参,耗费相当多的时间才能得到自己满意的模型。
而谷歌近期推出了AutoML,可以帮助人们在给定数据下自动找寻最优网络模型,可谓让不是专业的人也可以轻松构建合适自己的网络模型,但唯一的问题是太贵了,每小时收费20美元啦。
幸好开源界也推出了autokeras,让我们一众屌丝也可以享受这免费的待遇,其官网是 https://autokeras.com/ 。
官网的文档和样例目前不是很详细,我研究了一番,写篇简单的入门贴,供大家参考。
一、 准备数据
先下载训练和测试数据集,下载地址为 http://pan.baidu.com/s/1nuqlTnN,总共500张图片,其中100张为测试数据,400张为训练数据,图片分为'bus', 'dinosaur', 'flower', 'horse', 'elephant'五类,分别以以3,4,5,6,7开头进行按类区分
按照autokers的要求,我们需要做一个csv文件,记录图片与所属标签的映射关系,可以用如下代码生成:
import os
import csv TRAIN_IMG_DIR = '/home/yourname/Documents/tensorflow/images/500pics2/train'
TRAIN_CSV_DIR = '/home/yourname/Documents/tensorflow/images/500pics2/train_labels.csv'
TEST_IMG_DIR = '/home/yourname/Documents/tensorflow/images/500pics2/test'
TEST_CSV_DIR = '/home/yourname/Documents/tensorflow/images/500pics2/test_labels.csv' def mkcsv(img_dir, csv_dir):
list = []
list.append(['File Name','Label'])
for file_name in os.listdir(img_dir):
if file_name[0] == '3': #bus
item = [file_name, 0]
elif file_name[0] == '4': #dinosaur
item = [file_name, 1]
elif file_name[0] == '5': #elephant
item = [file_name, 2]
elif file_name[0] == '6': #flower
item = [file_name, 3]
else:
item = [file_name, 4] #horse
list.append(item) print(list)
f = open(csv_dir, 'w', newline='')
writer = csv.writer(f)
writer.writerows(list) mkcsv(TRAIN_IMG_DIR, TRAIN_CSV_DIR)
mkcsv(TEST_IMG_DIR, TEST_CSV_DIR)
最后生成的csv文件的格式是这样:
File Name,Label
473.jpg,1
675.jpg,3
556.jpg,2
584.jpg,2
339.jpg,0
二、 格式化图片
训练和测试图片的大小不一,需要统一转换成相同的格式才能被autokeras处理,可用如下代码处理:
from tensorflow.keras.preprocessing import image
import os TEST_IMG_DIR_INPUT = "/home/yourname/Documents/tensorflow/images/500pics2/test_origin"
TEST_IMG_DIR_OUTPUT = "/home/yourname/Documents/tensorflow/images/500pics2/test"
TRAIN_IMG_DIR_INPUT = "/home/yourname/Documents/tensorflow/images/500pics2/train_origin"
TRAIN_IMG_DIR_OUTPUT = "/home/yourname/Documents/tensorflow/images/500pics2/train"
IMAGE_SIZE = 28 def format_img(input_dir, output_dir):
for file_name in os.listdir(input_dir):
path_name = os.path.join(input_dir, file_name)
img = image.load_img(path_name, target_size=(IMAGE_SIZE, IMAGE_SIZE))
path_name = os.path.join(output_dir, file_name)
img.save(path_name) format_img(TEST_IMG_DIR_INPUT, TEST_IMG_DIR_OUTPUT)
format_img(TRAIN_IMG_DIR_INPUT, TRAIN_IMG_DIR_OUTPUT)
本例中我们把图片大小统一转换成(28, 28)的格式,为什么是这个值呢?我最初尝试设置成224*224,但发现后来运行autokeras时,抛出了"RuntimeError: CUDA error: out of memory"的错误,autokeras是基于pyTorch,我觉得pyTorch对于内存的利用上需要优化下,同样的数据集我在基于tensorflow的keras上是不会报内存不足的。不过也许你的内存足够大的话,可以忽略我的建议。
三、 训练
首先我们需要安装autokeras:pip3 install autokeras
其次需要安装graphviz: apt install graphviz,目的是为了最后能画出我们生成的模型
以下是训练代码:
from autokeras.image.image_supervised import load_image_dataset, ImageClassifier
from keras.models import load_model
from keras.utils import plot_model
from keras.preprocessing.image import load_img, img_to_array
import numpy as np TRAIN_CSV_DIR = '/home/yourname/Documents/tensorflow/images/500pics2/train_labels.csv'
TRAIN_IMG_DIR = '/home/yourname/Documents/tensorflow/images/500pics2/train'
TEST_CSV_DIR = '/home/yourname/Documents/tensorflow/images/500pics2/test_labels.csv'
TEST_IMG_DIR = '/home/yourname/Documents/tensorflow/images/500pics2/test' PREDICT_IMG_PATH = '/home/yourname/Documents/tensorflow/images/500pics2/test/719.jpg' MODEL_DIR = '/home/yourname/Documents/tensorflow/images/500pics2/model/my_model.h5'
MODEL_PNG = '/home/yourname/Documents/tensorflow/images/500pics2/model/model.png'
IMAGE_SIZE = 28 if __name__ == '__main__':
# 获取本地图片,转换成numpy格式
train_data, train_labels = load_image_dataset(csv_file_path=TRAIN_CSV_DIR, images_path=TRAIN_IMG_DIR)
test_data, test_labels = load_image_dataset(csv_file_path=TEST_CSV_DIR, images_path=TEST_IMG_DIR) # 数据进行格式转换
train_data = train_data.astype('float32') / 255
test_data = test_data.astype('float32') / 255
print("train data shape:", train_data.shape) # 使用图片识别器
clf = ImageClassifier(verbose=True)
# 给其训练数据和标签,训练的最长时间可以设定,假设为1分钟,autokers会不断找寻最优的网络模型
clf.fit(train_data, train_labels, time_limit=1 * 60)
# 找到最优模型后,再最后进行一次训练和验证
clf.final_fit(train_data, train_labels, test_data, test_labels, retrain=True)
# 给出评估结果
y = clf.evaluate(test_data, test_labels)
print("evaluate:", y) # 给一个图片试试预测是否准确
img = load_img(PREDICT_IMG_PATH)
x = img_to_array(img)
x = x.astype('float32') / 255
x = np.reshape(x, (1, IMAGE_SIZE, IMAGE_SIZE, 3))
print("x shape:", x.shape) # 最后的结果是一个numpy数组,里面是预测值4,意味着是马,说明预测准确
y = clf.predict(x)
print("predict:", y) # 导出我们生成的模型
clf.export_keras_model(MODEL_DIR)
# 加载模型
model = load_model(MODEL_DIR)
# 将模型导出成可视化图片
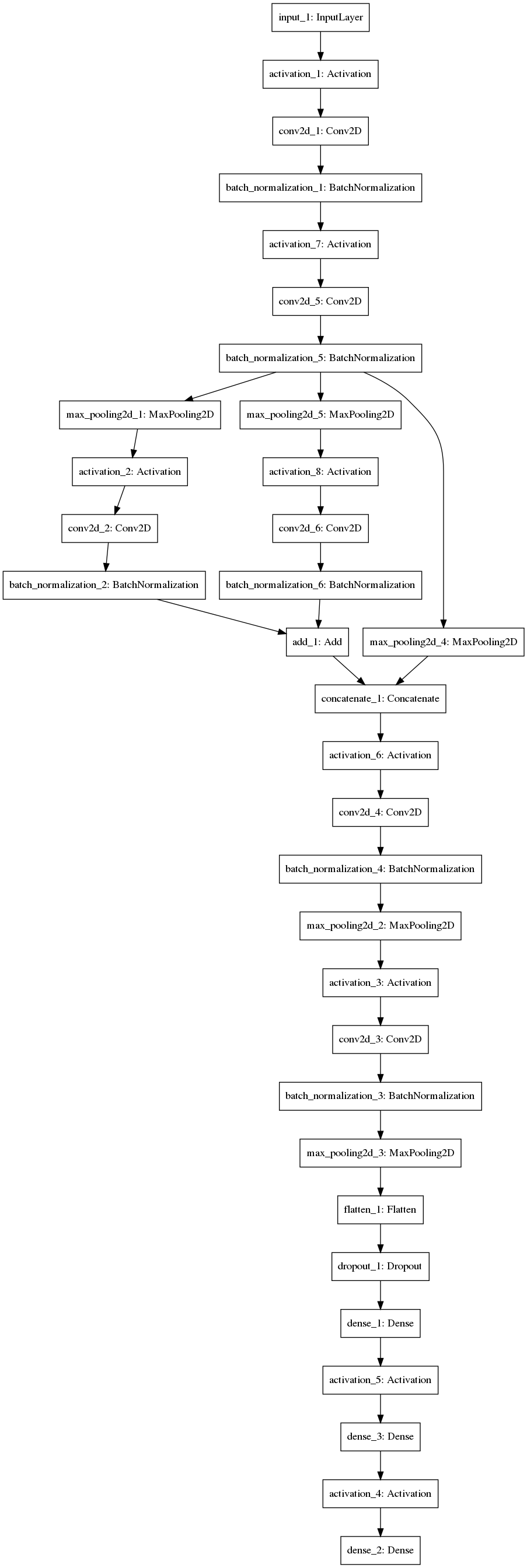
plot_model(model, to_file=MODEL_PNG)
最后给出生成的模型样子,也许这个模型比不上你手工调参得来的模型高效,但这已经是autokeras给出的最优解了,而且我们不需要劳神劳力的去调参了。
人生苦短,我用autokers!
深度学习应用系列(三)| autokeras使用入门的更多相关文章
- 深度学习实践系列(2)- 搭建notMNIST的深度神经网络
如果你希望系统性的了解神经网络,请参考零基础入门深度学习系列,下面我会粗略的介绍一下本文中实现神经网络需要了解的知识. 什么是深度神经网络? 神经网络包含三层:输入层(X).隐藏层和输出层:f(x) ...
- 深度学习实践系列(3)- 使用Keras搭建notMNIST的神经网络
前期回顾: 深度学习实践系列(1)- 从零搭建notMNIST逻辑回归模型 深度学习实践系列(2)- 搭建notMNIST的深度神经网络 在第二篇系列中,我们使用了TensorFlow搭建了第一个深度 ...
- 深度学习基础系列(九)| Dropout VS Batch Normalization? 是时候放弃Dropout了
Dropout是过去几年非常流行的正则化技术,可有效防止过拟合的发生.但从深度学习的发展趋势看,Batch Normalizaton(简称BN)正在逐步取代Dropout技术,特别是在卷积层.本文将首 ...
- 深度学习基础系列(五)| 深入理解交叉熵函数及其在tensorflow和keras中的实现
在统计学中,损失函数是一种衡量损失和错误(这种损失与“错误地”估计有关,如费用或者设备的损失)程度的函数.假设某样本的实际输出为a,而预计的输出为y,则y与a之间存在偏差,深度学习的目的即是通过不断地 ...
- UFLDL深度学习笔记 (三)无监督特征学习
UFLDL深度学习笔记 (三)无监督特征学习 1. 主题思路 "UFLDL 无监督特征学习"本节全称为自我学习与无监督特征学习,和前一节softmax回归很类似,所以本篇笔记会比较 ...
- [深度学习] Pytorch(三)—— 多/单GPU、CPU,训练保存、加载模型参数问题
[深度学习] Pytorch(三)-- 多/单GPU.CPU,训练保存.加载预测模型问题 上一篇实践学习中,遇到了在多/单个GPU.GPU与CPU的不同环境下训练保存.加载使用使用模型的问题,如果保存 ...
- 《神经网络和深度学习》系列文章三:sigmoid神经元
出处: Michael Nielsen的<Neural Network and Deep Leraning>,点击末尾“阅读原文”即可查看英文原文. 本节译者:哈工大SCIR硕士生 徐伟 ...
- 【深度学习与TensorFlow 2.0】入门篇
注:因为毕业论文需要用到相关知识,借着 TF 2.0 发布的时机,重新捡起深度学习.在此,也推荐一下优达学城与 TensorFlow 合作发布的TF 2.0入门课程,下面的例子就来自该课程. 原文发布 ...
- 深度学习应用系列(一)| 在Ubuntu 18.04安装tensorflow 1.10 GPU版本
tensorflow目前已经升级至r1.10版本.在之前的深度学习中,我是在MAC的虚拟机上跑CPU版本的tensorflow程序,当数据量变大后,tensorflow跑的非常慢,在内存不足情况下,又 ...
- 使用Keras进行深度学习:(一)Keras 入门
欢迎大家关注我们的网站和系列教程:http://www.tensorflownews.com/,学习更多的机器学习.深度学习的知识! Keras是Python中以CNTK.Tensorflow或者Th ...
随机推荐
- UVA 1213 Sum of Different Primes
https://vjudge.net/problem/UVA-1213 dp[i][j][k] 前i个质数里选j个和为k的方案数 枚举第i个选不选转移 #include<cstdio> # ...
- [洛谷P4774] [NOI2018]屠龙勇士
洛谷题目链接:[NOI2018]屠龙勇士 因为markdown复制过来有点炸格式,所以看题目请戳上面. 题解: 因为杀死一条龙的条件是在攻击\(x\)次,龙恢复\(y\)次血量\((y\in N^{* ...
- dump_stack 实现分析【转】
转自:http://kernel.meizu.com/2017/03/18-40-19-dump_stack.html 1 简介 说起 dump_stack() ,相信从事 Linux 内核或者驱动相 ...
- 安全测试===burpsuit指南
网址: https://www.gitbook.com/book/t0data/burpsuite/details 引子 刚接触web安全的时候,非常想找到一款集成型的渗透测试工具,找来找去,最终选择 ...
- python基础===抽象
懒惰即美德 斐波那契数列: >>> fibs = [0,1] >>> for i in range(8): fibs.append(fibs[-2]+fibs[-1 ...
- mips64高精度时钟引起ktime_get时间不准,导致饿狗故障原因分析【转】
转自:http://blog.csdn.net/chenyu105/article/details/7720162 重点关注关中断的情况.临时做了一个版本,在CPU 0上监控所有非0 CPU的时钟中断 ...
- FreeRADIUS + MySQL 安装配置笔记
FreeRADIUS + MySQL 安装配置笔记 https://www.2cto.com/net/201110/106597.html
- perl操作MongoDB
perl操作MongoDB http://blog.csdn.net/jophyyao/article/details/8223190 Mongodb 的C语言操作 http://blog.csdn. ...
- Makefile 跟着走快点
引言 - 从"HelloWorld"开始 Makefile 是Linux C 程序开发最重要的基本功. 代表着整个项目编译和最终生成过程.本文重点是带大家了解真实项目中那些简易的 ...
- 通过file中的字段查询MySQL内容
# -*- coding: utf-8 -*- import MySQLdb with open(r"./user.txt", "r") as f: f.rea ...