python大数据挖掘系列之淘宝商城数据预处理实战
数据清洗:
所谓的数据清洗,就是把一些异常的、缺失的数据处理掉,处理掉不一定是说删除,而是说通过某些方法将这个值补充上去,数据清洗目的在于为了让我们数据的可靠,因为脏数据会对数据分析产生影响。
拿到数据后,我们进行数据清洗分为两方面:
- 缺失值发现:可以查找
- 异常值发现:画图分析
- 缺失值:在下载数据、搜集数据的时候刚好就缺失。可以通过查找的方法去发现。
- 异常值:不一定就是异常,可能就是客观存在,但是这个值对于总的数据来说是一个就比较特殊点。可以通过画散点图发现。
这两方面的处理方法如下:
- 缺失值处理:均值/中位数插补、固定值、临近插补、回归分析、插值法(拉格朗日插值,牛顿插值)
- 异常值处理:视为缺失,平均值修正,不处理。
方法解释:
- 均值/中位数插补:在缺失位置插入一个总数据的均值或者中位数。
- 固定值::在缺失位置插入一个固定值
- 临近插补:看这个缺失位置附近的值是什么,就把附近的某一个值插到缺失位置,这类应用场景应用于物以类聚的场景
- 回归分析:等日后用上的时候在研究。
- 插值法:此算法复杂,暂未研究,等日后用上的时候在研究。
- 视为缺失:可以看成缺失值,然后通过缺失值来处理。
- 平均值修正:通过平均值来替代这个值
- 不处理:不处理这个值
开始分析:
表结构介绍:
淘宝商品表结构如下:
- title:商品名称
- link:商品URL
- price:商品价钱
- comment:商品评论数量
mysql> desc taob;
+---------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+-------------+------+-----+---------+-------+
| title | varchar(50) | YES | | NULL | |
| link | varchar(60) | NO | PRI | NULL | |
| price | int(30) | YES | | NULL | |
| comment | int(30) | YES | | NULL | |
+---------+-------------+------+-----+---------+-------+对于上面四个字段,比较好处理的就是价钱和评论数,比如价钱是0(没有采集到的数据),可以通过刚才平均值或者中位数来填充,对于异常值,比如某个评论10W+,那么也可以采用平均值修正。
Python环境介绍:
依赖于pymysql,numpy,pandas,matplotlib,请自己先安装。可以参考我上篇博文:http://www.cnblogs.com/liaojiafa/p/6239262.html
拿代码说话:
- 获取数据
conn = pymysql.connect(host='192.168.56.4',user='root',passwd='123456',db='csdn',charset='utf8')
sql='select * from taob'
data = pandas.read_sql(sql,conn)
print(data.head(1))
#数据样例如下,和mysql字段相匹配的:
0 买2袋减2元 印尼进口菲那菲娜虾味木薯片油炸大龙虾片零食品400g
link price comment
0 https://item.taobao.com/item.htm?id=44350560220 50 2577 可以看看数据的中位数和均值:
print(data.describe())
price comment
count 9616.00000 9616.000000
mean 64.49324 562.239601 # 均值
std 176.10901 6078.909643
min 0.00000 0.000000
25% 20.00000 16.000000
50% 36.00000 58.000000 # 中位数
75% 66.00000 205.000000
max 7940.00000 454037.000000- 对price列的数据清洗
- 缺失值的处理:
我们先了解下这样的判断方法:
a={1:'a',2:'b'}
print([a[1]=='a'])上述代码打印结果必然是True,小括号([])相当于if判断了,返回的值为布尔值。
下面对price为0的值(也就是缺失值)进行处理。
data['price'][(data['price']==0)]=None # 对price的缺失值统统赋值为None,方便下面处理
data['price'][(data['price']==0)]=64 # 也可以这样写,直接把price的缺失值设置为price的平均数64.那么下面的for循环设置price的缺失值就不需要写。对上面这段代码拆分来看:
- (data['price']==0) 判断data['price']列中哪行price的值等于0,等于的返回True,不等于返回False
- data['price'][(data['price']==0)] 这语句就是一下子把所有price=0的给取出来了 ,然后哪行的price等于0就 赋值为None
for i in data.columns: # 遍历data的每列
for j in range(len(data)): # 遍历data的每一行了。
if data[i].isnull()[j]: # i在这是一维(列),data[i]等于把这一列的值取出来了,j在这里是二维(行),i相当于XY轴的X轴,j相当于XY轴的Y轴,data[i].isnull是判断整列的某一个值是nan那么就返回True,data[i].isnull[j]是逐行逐行的判断是否为nan了,是的话返回True从而进行下面代码块的处理。
data[i][j]=64 # 缺失值设置为均值- 异常值处理:
1.找到异常值:通过画散点图(横轴:价格,纵轴:评论数)
我们这里的话要选取评论数,价钱。通常的方法就是说通过遍历每一行的数据,取每一行中的price值,但是呢这个方法效率低下。
对此我们可以采用转置方法,把price列转置为一行,这样就能够快速取到这价钱的数据,还有评论数。
下面请看代码:
dataT=data.T # 转置下数据
prices = dataT.values[2] # 取第3行数据
comments = dataT.values[3] # 取第4行数据
pylab.plot(prices,comments,'o') # 画散点图
pylab.xlabel('prices')
pylab.ylabel('comments')
pylab.title(" The Good's price and comments")
pylab.show()处理异常数据,我这里定义的异常数据就是评论数超过20W,价格大于2000,请看代码:
line = len(data.values) # 取行数
col = len(data.values[0]) # 取列数
davalues = data.values #取data的所有值
for i in range(0,line): # 遍历行数
for j in range(0,col): #遍历列数
if davalues[i][3]>200000: #判断评论数
#print('comments==i,j',i,j,davalues[i][j])
davalues[i][j] = 562 # 评论数取平均值
if davalues[i][2]>2000:
davalues[i][j] = 64 # 价钱取平均值
prices2=davalues.T[2]
comments2=davalues.T[3]
pylab.plot(prices2,comments2,'or')
pylab.xlabel('prices')
pylab.ylabel('comments')
pylab.title(" The Good's price and comments")
pylab.show()此时,我们看图:
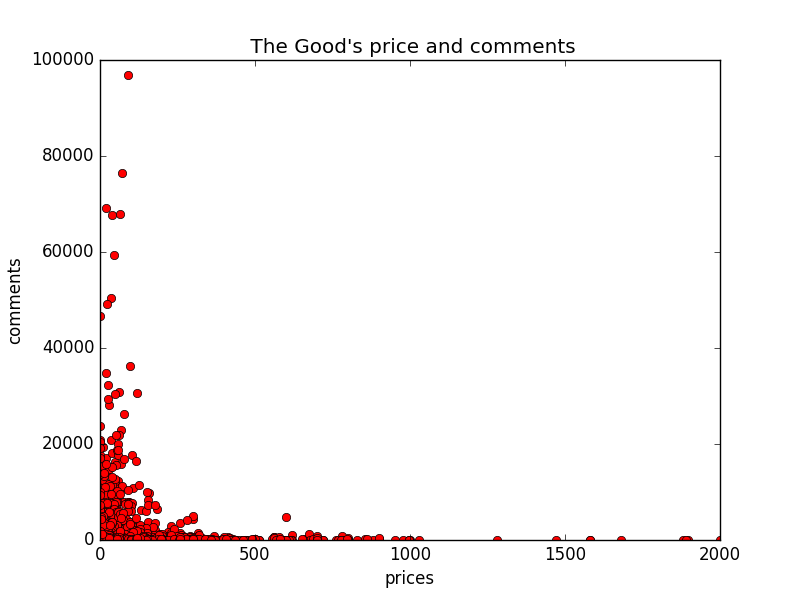
显然我们已经对评论数超过20W,价格大于2000的数据处理了,但是呢上图显示的还是不够漂亮,因为异常点与正常点的差距太大了,导致正常点与正常点之间的间隔非常小,小到黏在一块了,所以我们还需要在处理下,把评论数超过2000,价格大于300的处理掉,这样的话,正常点就能够很好的展现在图上,代码如下:
line = len(data.values) # 取行数
col = len(data.values[0]) # 取列数
davalues = data.values #取data的所有值
for i in range(0,line): # 遍历行数
for j in range(0,col): #遍历列数
if davalues[i][3]>2000: #判断评论数,===主要修改这行
#print('comments==i,j',i,j,davalues[i][j])
davalues[i][j] = 562 # 评论数取平均值
if davalues[i][2]>300: # ====主要修改这行
davalues[i][j] = 64 # 价钱取平均值
prices2=davalues.T[2]
comments2=davalues.T[3]
pylab.plot(prices2,comments2,'or')
pylab.xlabel('prices')
pylab.ylabel('comments')
pylab.title(" The Good's price and comments")
pylab.show()full example:
import pymysql
import numpy
import pandas
from matplotlib import pylab
#缺失值处理
#======
data['price'][(data['price']==0)]=64 # 对price的缺失值统统赋值为平均数
# 异常值处理:
# 1.找到异常值:通过画散点图(横轴:价格,纵轴:评论数)
# 我们这里的话要选取评论数,价钱。通常的方法就是说通过遍历每一行的数据,取每一行中的price值,但是呢这个方法效率低下,
# 对此我们可以采用转置方法,把price列转置为一行,这样就能够快速取到这价钱的数据,还有评论数
# 处理异常数据,我这里定义的异常数据就是评论数超过20W,价格大于2000
conn = pymysql.connect(host='192.168.56.4',user='root',passwd='123456',db='csdn',charset='utf8')
sql='select * from taob'
data = pandas.read_sql(sql,conn)
line = len(data.values) # 取行数
col = len(data.values[0]) # 取列数
davalues = data.values #取data的所有值
for i in range(0,line): # 遍历行数
for j in range(0,col): #遍历列数
if davalues[i][3]>2000: #判断评论数
#print('comments==i,j',i,j,davalues[i][j])
davalues[i][j] = 562 # 评论数取平均值
if davalues[i][2]>300:
davalues[i][j] = 64 # 价钱取平均值
prices2=davalues.T[2]
comments2=davalues.T[3]
pylab.plot(prices2,comments2,'or')
pylab.xlabel('prices')
pylab.ylabel('comments')
pylab.title(" The Good's price and comments")
pylab.show()生成的图如下: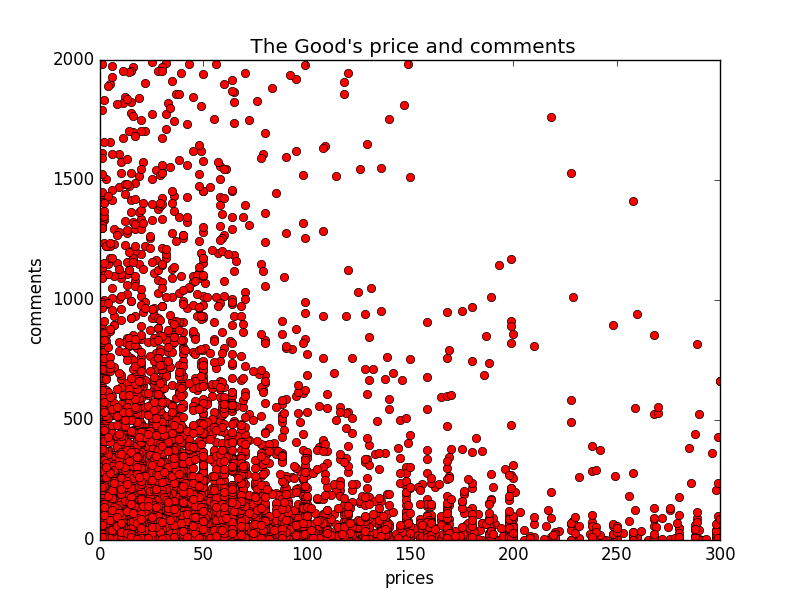
这张图就很直观的看出,价钱和评论数的关系了,价钱在100以内的,评论数也比较多,价钱越高,评论数相对来说越少。
数据集成与数据离散化
数据集成:不同来源的数据集合在一起,需要注意格式保持一致。
for example:
我这里有2个表数据,淘宝与京东的,淘宝的表就如上面所述的一样,标题,url,价钱,评论,那么京东的下标为2的列也必须是价钱,只有数据格式保持一致,才能分析。数据离散化:处理连续数据较好的方法。离散化就是指数据不集中,分散了。
for example:
一个班的考试成绩就是从0-100分之间,这个数据是在100以内连续的,那么我们对这个数据分析的时候就可以这么做,把连续的数据或者近似连续的数据整合在一个点附近,比如0-60分为及格,60-80为良好.....
商品数据分布分析实战
我们在这里要分析商品数据的分布,看评论数与价钱的在哪个数量段的分布最多。
首先我们需要计算出价钱和评论的最值,其次在计算最值之间的极差,最后计算组距(极差/组数,组数自己根据情况定义)。下面请看代码:
# 数据分布:
# 1 求最值
# 2 计算极差
# 3 组距: 极差/组数
da2=davalues.T
# print('=======')
# print(data['price'])
pricemax = da2[2].max()
pricemin = da2[2].min()
commentmax = da2[3].max()
commentmin = da2[3].min()
# 极差
pricerg = pricemax - pricemin
commentrg = commentmax -commentmin
# 组距
pricedst = pricerg/10
commentdst = pricerg/10
# 绘制直方图
# numpy.arrange(最小值,最大值,组距)
# 价钱直方图
pricesty = numpy.arange(pricemin,pricemax,pricedst)
pylab.hist(da2[2],pricesty)
pylab.show()
# 评论直方图
commentty = numpy.arange(commentmin,commentmax,commentdst)
pylab.hist(da2[3],pricesty)
pylab.show()评论直方图如下: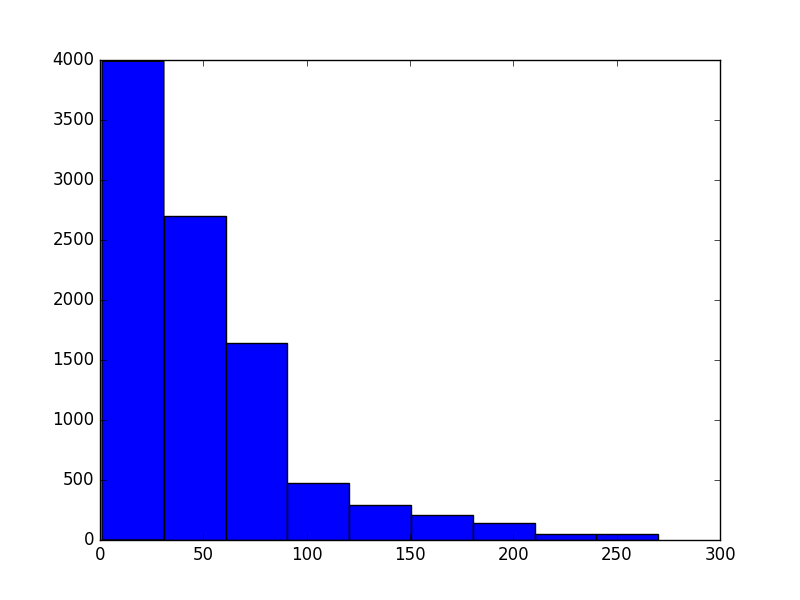
结论:
从上图中我们可以看出,评论数最多的集中在100元以内的商品,评论数也间接的说明了购买数,因为购买后才能够评论。
所以可以根据这个来直方图来给商品定价。
价钱直方图如下: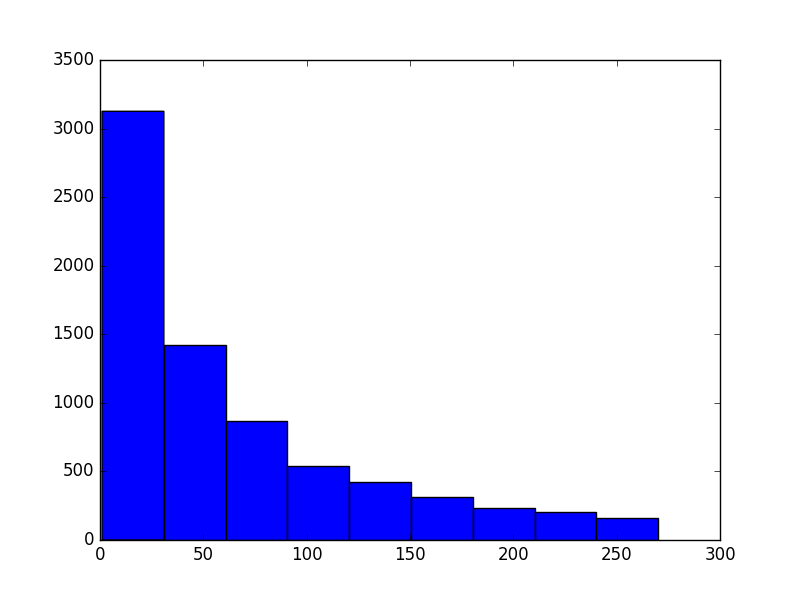
结论:
从上图中我们可以看出,商品价钱最多的集中在50元以内的商品
code full example:
#!/usr/bin/env python
# __author__:Leo
import pymysql
import numpy
import pandas
from matplotlib import pylab
conn = pymysql.connect(host='192.168.56.4',user='root',passwd='123456',db='csdn',charset='utf8')
sql='select * from taob'
data = pandas.read_sql(sql,conn)
# 缺失值处理
data['price'][(data['price']==0)]=64 # 对price的缺失值统统赋值为price的平均数
# 异常值处理:
# 1.找到异常值:通过画散点图(横轴:价格,纵轴:评论数)
# 我们这里的话要选取评论数,价钱。通常的方法就是说通过遍历每一行的数据,取每一行中的price值,但是呢这个方法效率低下,
# 对此我们可以采用转置方法,把price列转置为一行,这样就能够快速取到这价钱的数据,还有评论数
line = len(data.values) # 取行数
col = len(data.values[0]) # 取列数
davalues = data.values #取data的所有值
for i in range(0,line): # 遍历行数
for j in range(0,col): #遍历列数
if davalues[i][3]>2000: #判断评论数
#print('comments==i,j',i,j,davalues[i][j])
davalues[i][j] = 562 # 评论数取平均值
if davalues[i][2]>300:
davalues[i][j] = 64 # 价钱取平均值
prices2=davalues.T[2]
comments2=davalues.T[3]
pylab.plot(prices2,comments2,'or')
pylab.xlabel('prices')
pylab.ylabel('comments')
pylab.title(" The Good's price and comments")
pylab.show()
# 数据分布:
# 1 求最值
# 2 计算极差
# 3 组距: 极差/组数
da2=davalues.T
# print('=======')
# print(data['price'])
pricemax = da2[2].max()
pricemin = da2[2].min()
commentmax = da2[3].max()
commentmin = da2[3].min()
# 极差
pricerg = pricemax - pricemin
commentrg = commentmax -commentmin
# 组距
pricedst = pricerg/10
commentdst = pricerg/10
# 绘制直方图
# numpy.arrange(最小值,最大值,组距)
# 价钱直方图
pricesty = numpy.arange(pricemin,pricemax,pricedst)
pylab.hist(da2[2],pricesty)
pylab.show()
# 评论直方图
commentty = numpy.arange(commentmin,commentmax,commentdst)
pylab.hist(da2[3],pricesty)
pylab.show()python大数据挖掘系列之淘宝商城数据预处理实战的更多相关文章
- 2 python大数据挖掘系列之淘宝商城数据预处理实战
preface 在上一章节我们聊了python大数据分析的基本模块,下面就说说2个项目吧,第一个是进行淘宝商品数据的挖掘,第二个是进行文本相似度匹配.好了,废话不多说,赶紧上车. 淘宝商品数据挖掘 数 ...
- 1 python大数据挖掘系列之基础知识入门
preface Python在大数据行业非常火爆近两年,as a pythonic,所以也得涉足下大数据分析,下面就聊聊它们. Python数据分析与挖掘技术概述 所谓数据分析,即对已知的数据进行分析 ...
- python大数据挖掘系列之基础知识入门
preface Python在大数据行业非常火爆近两年,as a pythonic,所以也得涉足下大数据分析,下面就聊聊它们. Python数据分析与挖掘技术概述 所谓数据分析,即对已知的数据进行分析 ...
- Python实例之抓取淘宝商品数据(json型数据)并保存为TXT
本实例实现了抓取淘宝网中以‘python’为关键字的搜索结果,经详细查看数据存储于html文档中的js脚本中,数据类型为JSON 具体实现代码如下: import requests import re ...
- 使用jQuery仿淘宝商城多格焦点图滚动切换效果
1.效果及功能说明 图片滚动切换特效,高仿2012淘宝商城首页多格子焦点图切换,鼠标滑过焦点图片各个格子区域聚光灯效果展示 2.实现原理 在显示div的下面有一个按钮条在鼠标触及到按钮的时候会改变那妞 ...
- Python爬虫,抓取淘宝商品评论内容!
作为一个资深吃货,网购各种零食是很频繁的,但是能否在浩瀚的商品库中找到合适的东西,就只能参考评论了!今天给大家分享用python做个抓取淘宝商品评论的小爬虫! 思路 我们就拿"德州扒鸡&qu ...
- python大数据挖掘和分析的套路
大数据的4V特点: Volume(大量):数据巨大. Velocity(高速):数据产生快,每一天每一秒全球人产生的数据足够庞大且数据处理也逐渐变快. Variety(多样):数据格式多样化,如音频数 ...
- 服饰行业淘宝商城店铺首页设计报告-转载自http://bbs.paidai.com/topic/88363
店铺的设计 和 美工是2个完全不同的工作. 很多中小卖家,往往会模糊他们之间的差别. 好比要建造一座金茂大厦,先要有建筑设计师设计图纸,明确好建造的楼层数,具体框架结构,所用材料等等. 然后建筑施工队 ...
- jQuery制作淘宝商城商品列表多条件查询功能
一.介绍 这几天做网站的时候,突然用到这个功能,找了好久也没有找到.看到"希伟素材网"有这么一个JS,效果很不错,也正是我一直以来想要的结果.附图如下: 二:使用教程 1 ...
随机推荐
- netbeans调试配置
apache端口8050,xdebug端口9000 1.把项目放到apache的htdocs下(一定要放在htdocs上,要么调试的时候xdebug会一直卡在“等待连接中”) 2.把php_xdebu ...
- CodeChef LEMOVIE
题意:给你n个数字(下标不同数值相同的数字应当被认为是不同的数字),有n!种排列方式.每种排列方式的价值定义为:第一次出现时比前面的所有数字都大的数值个数. 比如1,2,2,3这个排列中,1,2,3这 ...
- Python 文件对象和方法
Python文件对象和方法 1.打开和关闭文件 Python提供了必要的函数和方法进行默认情况下的文件基本操作,我们可以用file对象做大部分文件操作. open()方法 我们必须先用Python内置 ...
- BZOJ4289 PA2012Tax(最短路)
一个暴力的做法是把边看成点,之间的边权为两边的较大权值,最短路即可.但这样显然会被菊花图之类的卡掉. 考虑优化建图.将边拆成两个有向边,同样化边为点.原图中同一条边在新图中的两个点之间连边权为原边权的 ...
- Linux相关——手写测试程序
由于本人太弱,,,不会lemon,,,也不会在ubuntu下安装lemon,所以我选择手写测试程序emmmm 首先要写这个东西我们要先知道对拍怎么写. ; i <= ; i++) { syste ...
- [HNOI2008]GT考试 矩阵优化DP
---题面--- 题解: 一开始看觉得很难,理解了之后其实还挺容易的. 首先我们考虑朴素DP: 令f[i][j]表示长串到了第i项, 与不吉利数字(模式串)匹配到了第j项的方案. 显然ans = f[ ...
- BZOJ5011 & 洛谷4065 & LOJ2275:[JXOI2017]颜色——题解
https://www.lydsy.com/JudgeOnline/problem.php?id=5011 https://www.luogu.org/problemnew/show/P4065 ht ...
- BZOJ3223:文艺平衡树——超详细题解
http://www.lydsy.com/JudgeOnline/problem.php?id=3223 题面复制于洛谷. 题目背景 这是一道经典的Splay模板题——文艺平衡树. 题目描述 您需要写 ...
- Apache 403 错误解决方法-让别人可以访问你的服务器(转)
有一次做好了一个效果放在自己电脑的服务器上,让同学查看(同处于校园网中),却不知apache一直显示403 错误,对方没有权限访问,我知道这应该是配置文件httpd.conf中的问题,网上搜了一下其他 ...
- Codeforces Round #311 (Div. 2)B. Pasha and Tea二分
B. Pasha and Tea time limit per test 1 second memory limit per test 256 megabytes input standard inp ...