k邻近算法理解及代码实现
github:代码实现
本文算法均使用python3实现
1 KNN
KNN(k-nearest neighbor, k近邻法),故名思议,是根据最近的 $ k $ 个邻居来判断未知点属于哪个类别。《统计学习方法》中对其定义为:
给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的 $ k $ 个实例,这 $ k $ 个实例的多数属于某个类,就把该输入实例分为这个类。
我们对该定义进行直观地分析,已知实例点为如下图中带有颜色的点,不同颜色代表不同类别,未知点为绿色点,要想知道未知点属于哪个类别,则需要找到未知点最近的 $ k $ 个邻居。
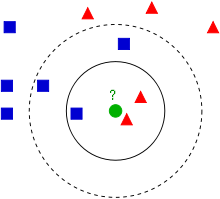
当 $ k=3 $ 时,结果见第一个圆环内,此时红色实例点为2个,蓝色实例点为1个,因此将未知点判定为红色类别。
当 $ k=5 $ 时,结果见第二个圆环内,此时红色实例点为2个,蓝色实例点为3个,因此将未知点判定为蓝色类别。
此时想必大家对KNN算法的思想有了初步的理解。接下来我们将根据定义,来探讨KNN算法的相关细节以及具体的实现。
1.1 KNN算法要点:
回顾一下刚刚的定义,“给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最近邻的的 $ k $ 个实例,这 $ k $ 个实例的多数属于某个类,就把该输入实例分为这个类”
由定义我们可以找到KNN算法的三个要点:
- 距离度量
- $ k $ 值的选择
- 分类决策规则
(1)距离的度量
特征空间中我们通常使用两个实例点的距离来衡量两个实例点的相似程度。对于KNN模型,其特征空间一般是 $ n $ 维实数向量空间 $ R^n $ ,即对于每一个实例点 $ x_i=(x_i^{(1)},x_i^{(2)},...,x_i^{(n)}) $ 都有 $ n $ 维,一般使用的距离是欧氏距离:\[ d=\sqrt{\sum_{l=1}^n {(x_i^{(l)}-x_j^{(l)})^2}} \]
当然也可以使用其它距离公式进行度量。
(2)$ k $ 值的选择
$ k $ 值的选择会对KNN的结果产生很大的影响,正如上面所示,当 $ k=3 $ 时与 $ k=5 $时,对未知点的类别判定是不同的。 $ k $ 值的减小意味着整体模型变得复杂,会产生过拟合;但 $ k $ 值过大,模型过于简单,也并不可取。
在应用中, $ k $ 值一般取较小的值,通常采用交叉验证法来选取最优的 $ k $ 值。
(3)分类决策选择
在得到离未知点最近的 $ k $ 个点之后,如何判定未知点属于哪个类?通常采用多数表决法,即对最近的 $ k $ 个点中每个类别及个数进行统计,个数最多的那个类别即为未知点的类别。(该方法存在一定缺陷,我们将在后面内容进行讲述)
1.2 KNN算法步骤:
输入:训练数据集:\[ T=\{ (x_1,y_1),(x_2,y_2),...,(x_N,y_N) \} \]
其中,$ x_i \in R^N $ 为实例的特征向量,$ y_i \in {c_1,c_2,...,c_k} $ 为实例的类别, $ i=1,2,..,N $ ;
输出:实例 $ x $ 所属的类别 $ y $
(1)根据给定的距离度量,在训练集 $ T $ 中找出与 $ x $ 最近邻的 $ k $ 个点,涵盖这 $ k $ 个点的 $ x $ 的邻域记作 $ N_k(x) $
(2)在 $ N_k(x) $ 中根据分类决策规则(如多数表决)决定 $ x $ 的类别 $ y $ :\[ y={arg max}_{c_g}{\sum_{x_i \in N_k(x)}I(y_i=c_g)}, i=1,2,..,N; g=1,2,..,k \]
上式中,$ I $ 为指示函数,即当 $ y_i=c_g $ 时 $ I $ 为1,否则 $ I $ 为0
1.3 KNN算法分析
适用数据范围:数值型和标称型
优点:精度高、对异常值不敏感、无数据输入假定
缺点:
(1)计算复杂度高:由于对于每一次未知实例的输入,都需要将其与已知训练实例依次进行距离的计算,再找出 $ top-k $ 最后进行类别的判断。在进行距离计算时相当于线性扫描,当训练集很大时,计算将非常耗时。
(2)空间复杂度高:由于KNN算法必须保存全部数据集,如果训练数据集很大,必须使用大量的存储空间。
(3)当训练样本不平衡时(见下图),按照KNN中的多数表决法,在 $ k $ 个最近点中,明显蓝色点个数较多,因此会被判定为蓝色点对应的类别。但据观察可知未知点的类别可能更接近于红色实例部分。也就是说KNN中的多数表决法只考虑了样本数量的多少,而忽略了距离的远近。因此,我们可以采用均值或者权值的方法来改进。(均值:$ k $ 近邻中某一类别所有实例点距未知点的平均距离作为判决标准,选择距离最短的作为结果。权值:和该样本距离小的邻居权值大,和该样本距离大的权值相对较小)
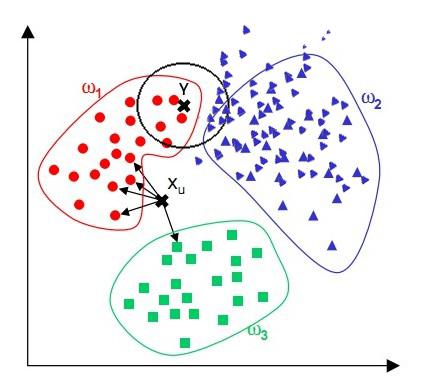
为了提高KNN算法的效率,可以考虑使用特殊的结构存储训练数据,以减少计算距离的次数,下面将介绍其中一种方法---kd树(kd tree)
2 Kd树
我们将该部分分为两部分进行讲解:(1)构造kd树(2)搜索kd树。前者是对训练数据集使用特殊结构进行存储,后者是对实例使用kd数结构进行搜索找到其类别。(该方法类似于搜索二叉树,在下面讲述中可将其与搜索二叉树对比着理解会比较容易接受)
2.1 构造kd树
kd树是一种对 $ k $ 维空间中的实例点进行存储以便对其进行快速检索的树形数据结构。kd树是二叉树,表示对 $ k $ 维空间的一个划分(partition)。构造kd树相当于不断地用垂直于坐标轴的超平面将 $ k $ 维空间进行切分,构成一系列的 $ k $ 维矩形区域。kd树的每个节点对应于一个 $ k $ 维超矩形区域。
本文讲述的切分方法是按照中位数(基于经验风险最小化)进行切分,也可使用其它方法进行切分,例如按照某维上的数据分散程度进行划分,该方法将使用方差作为划分标准。
下面将按照个人理解,对二维空间的划分以及kd树进行讲解:
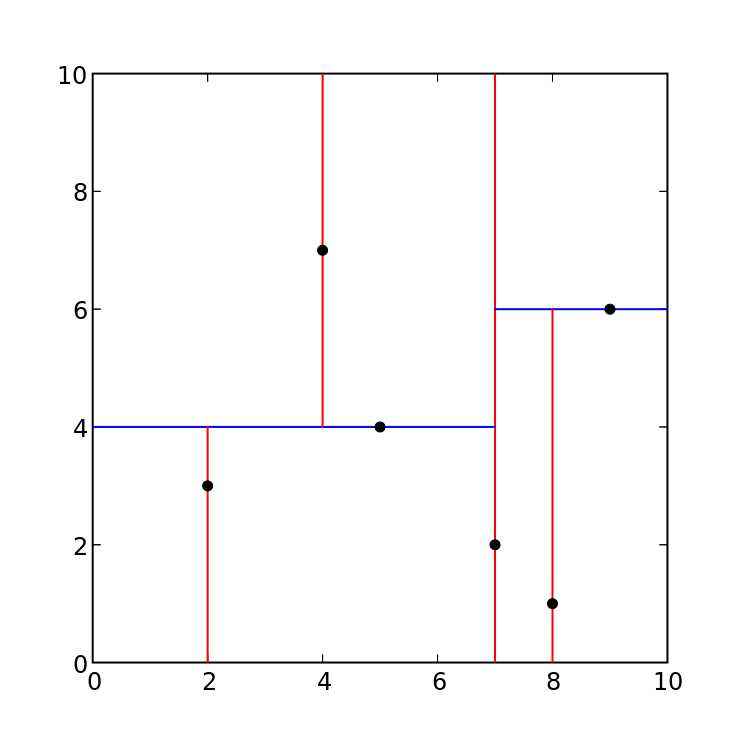
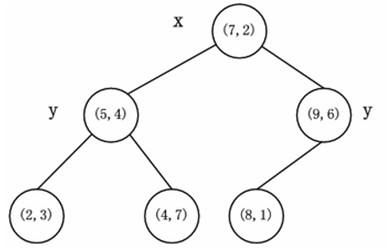
给定一个二维空间的数据集:\[ T=\{ (2,3),(5,4),(9,6),(4,7),(8,1),(7,2) \} \]
根节点对应包含数据集 $ T $ 的矩形,首先选择 $ x^{(1)} $ 维,按照 $ x^{(1)} $ 维对数据集进行排序: $ { (2,3),(4,7),(5,4),(7,2),(8,1),(9,6) } $ ,对于 $ x^{(1)} $ 维,其中位数为:7(按照排好序的数据集,其中位数的所在位置对应下标的中位数,即可使用 $ median = dataset[len(dataset)//2] $ 来确定),选择 $ (7,2) $ 作为根节点,接着按照 $ x^{(1)} $ 维进行划分,将小于7的划分到根节点的左子树中,大于7的划分到根节点的右子树中(该过程类似搜索二叉树)。
此时对于左右子树,需要选取相同的维进行划分(此处选取 $ x^{(2)} $ 维)。左子树:对于节点 $ { (2,3),(4,7),(5,4) } $ ,按照 $ x^{(2)} $ 维进行排序 $ { (2,3),(5,4),(4,7) } $ ,选择中位数 $ (5,4) $ 作为子树根节点,同理将小于4的放到 $ (5,4) $ 节点的左子树中,大于4的放到 $ (5,4) $ 节点的右子树中。对于根节点 $ (7,2) $ 的右子树,对节点 $ { (8,1),(9,6) } $ 进行排序,并选择中位数6,由于 $ 1 < 6 $ ,将 $ (8,1) $ 作为 $ (9,6) $ 的左孩子。到此,kd树构造完成。(对于kd树的每一层,都是对相同维进行划分,而每一次划分都相当于一次构造一次搜索二叉树)
如下图是一个二维空间的划分:
其对应的kd树为:
起初对于二维空间的划分图,我也是想了很久才理解,在此处以图的方式,给大家讲一下我的理解:
结合二维空间划分图与kd树二叉图,可以将下图中垂直绿色线看做是根节点,整个图的左半部分为根节点的左子树空间,右半部分为根节点的右子树空间:
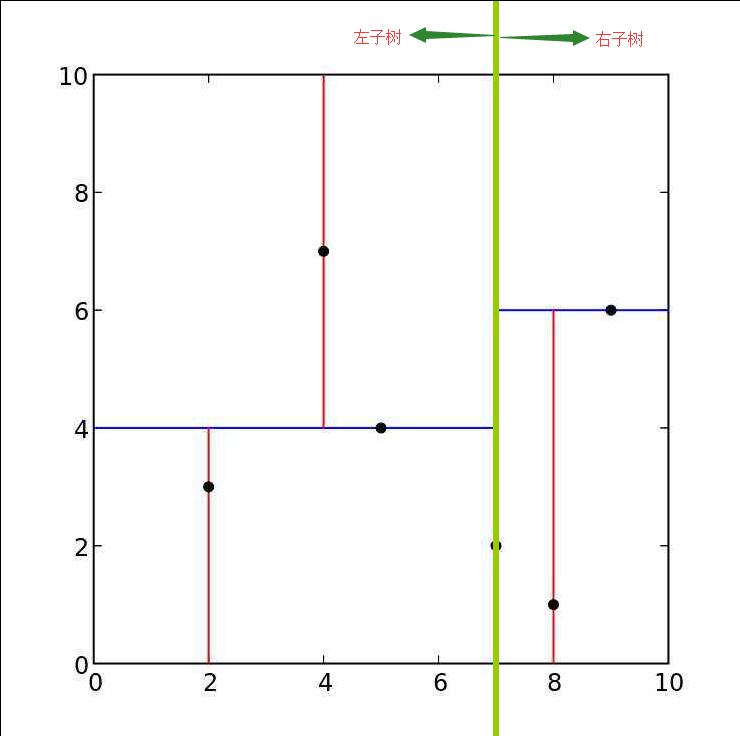
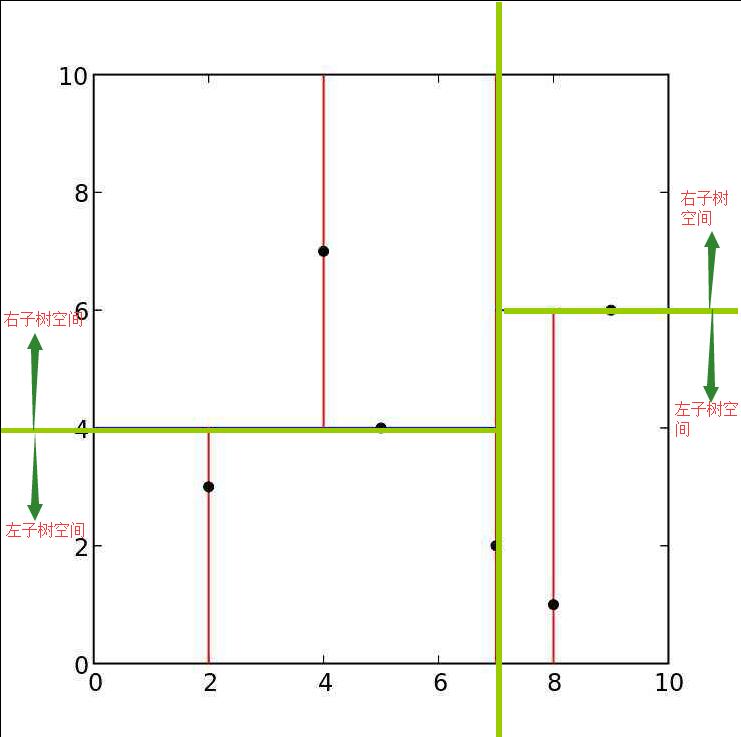
接着我们来看根节点的左右子树。左半部分的绿色横线可以看做左子树的根节点,下面部分在 $ x^{(2)} $ 维上比根节点小,因此看做是该根节点的左子树空间,上面部分是该根节点的右子树空间。同理整个图的右半部分,中间绿色横线看作是右子树根节点,下面部分是相对于该根节点的左子树空间,上面部分是相对于该根节点的右子树空间。
构造平衡kd树算法步骤:
输入:$ k $ 维空间数据集:\[ T=\{ x_1,x_2,...,x_N \} \] ,
其中 $ x_i=(x_i^{(1)},x_i^{(2)},...,x_i^{(k)}), i=1,2,...,N $
输出:kd树
(1)开始:构造根结点,根结点对应于包含T的 $ k $ 维空间的超矩形区域。选择 $ x^{(1)} $ 为坐标轴,以 $ T $ 中所有实例的 $ x^{(1)} $ 坐标的中位数为切分点,将根结点对应的超矩形区域切分为两个子区域。切分由通过切分点并与坐标轴 $ x^{(1)} $ 垂直的超平面实现。由根结点生成深度为1的左、右子结点:左子结点对应坐标 $ x^{(1)} $ 小于切分点的子区域,右子结点对应于坐标 $ x^{(1)} $ 大于切分点的子区域。将落在切分超平面上的实例点保存在根结点。
(2)重复。对深度为 $ j $ 的结点,选择 $ x^{(l)} $ 为切分的坐标轴, $ l=j%k+1 $,以该结点的区域中所有实例的 $ x^{(l)} $ 坐标的中位数为切分点,将该结点对应的超矩形区域切分为两个子区域。切分由通过切分点并与坐标轴 $ x^{(l)} $ 垂直的超平面实现。由该结点生成深度为 $ j+1 $ 的左、右子结点:左子结点对应坐标 $ x^{(l)} $ 小于切分点的子区域,右子结点对应坐标 $ x^{(l)} $ 大于切分点的子区域。将落在切分超平面上的实例点保存在该结点。
2.2 搜索kd树
利用kd树可以省去对大部分数据点的搜索,从而减少搜索的计算量。下面以搜索最近邻点为例加以叙述:给定一个目标点,搜索其最近邻,首先找到包含目标点的叶节点;然后从该叶结点出发,依次回退到父结点;不断查找与目标点最近邻的结点,当确定不可能存在更近的结点时终止。这样搜索就被限制在空间的局部区域上,效率大为提高。
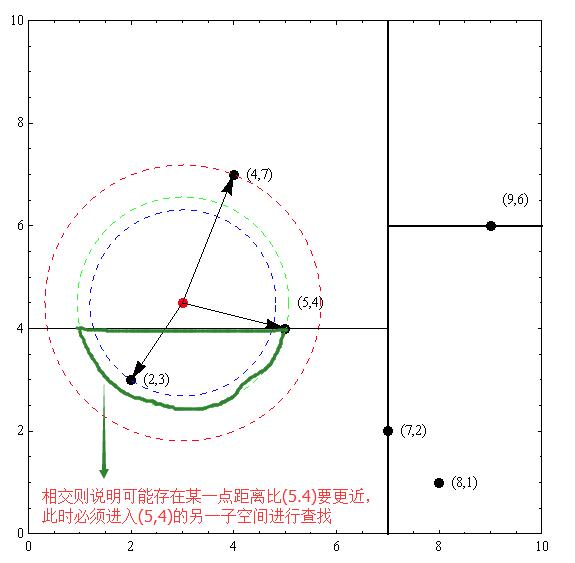
从空间划分来看:以先前构建好的kd树为例,查找目标点 $ (3,4.5) $ 的最近邻点。同样先进行二叉查找,先从 $ (7,2) $ 查找到 $ (5,4) $ 节点,在进行查找时是由 $ y = 4 $ 为分割超平面的,由于查找点为 $ y $ 值为4.5,因此进入右子空间查找到 $ (4,7) $ ,形成搜索路径:$ (7,2) \rightarrow (5,4) \rightarrow (4,7) $,取 $ (4,7) $ 为当前最近邻点。以目标查找点为圆心,目标查找点到当前最近点的距离2.69为半径确定一个红色的圆。然后回溯到 $ (5,4) $ ,计算其与查找点之间的距离为2.06,则该结点比当前最近点距目标点更近,以 $ (5,4) $ 为当前最近点。用同样的方法再次确定一个绿色的圆,可见该圆和 $ y = 4 $ 超平面相交(相交即可认为可能存在某一个点在相交区域内,而相交区域内的所有点的距离都比 $ (5.4) $ 点的距离要短,因此只要判断相交,就需要进入另一个子空间进行查找),所以需要进入 $ (5,4) $ 结点的另一个子空间进行查找。$ (2,3) $ 结点与目标点距离为1.8,比当前最近点要更近,所以最近邻点更新为 $ ( 2,3) $ ,最近距离更新为1.8,同样可以确定一个蓝色的圆。接着根据规则回退到根结点 $ (7,2) $ ,蓝色圆与 $ x=7 $ 的超平面不相交,因此不用进入 $ (7,2) $ 的右子空间进行查找。至此,搜索路径回溯完,返回最近邻点 $ (2,3) $,最近距离1.8。
用kd树的最近邻搜索算法:
输入: 已构造的kd树;目标点 $ x $ ;
输出: $ x $ 的最近邻。
(1) 在kd树中找出包含目标点 $ x $ 的叶结点:从根结点出发,递归的向下访问kd树。若目标点当前维的坐标值小于切分点的坐标值,则移动到左子结点,否则移动到右子结点。直到子结点为叶结点为止;
(2) 以此叶结点为“当前最近点”;
(3) 递归的向上回退,在每个结点进行以下操作:
(a) 如果该结点保存的实例点比当前最近点距目标点更近,则以该实例点为“当前最近点”;
(b) 当前最近点一定存在于该结点一个子结点对应的区域。检查该子结点的父结点的另一个子结点对应的区域是否有更近的点。具体的,检查另一个子结点对应的区域是否与以目标点为球心、以目标点与“当前最近点”间的距离为半径的超球体相交。如果相交,可能在另一个子结点对应的区域内存在距离目标更近的点,移动到另一个子结点。接着,递归的进行最近邻搜索。如果不相交,向上回退。
(4) 当回退到根结点时,搜索结束。最后的“当前最近点”即为x的最近邻点。
2.3 kd树算法分析
如果实例点是随机分布的,kd树搜索的平均计算复杂度是 $ O(\log N) $ ,$ N $ 为训练实例数,kd树更适用与训练实例数远大于空间维数的$ k $ 近邻搜索,当空间维数接近训练实例数时,它的效率将迅速下降,几乎接近线性扫描。
引用及参考:
[1] https://www.cnblogs.com/21207-iHome/p/6084670.html
[2]《统计学习方法》李航著
[3]《机器学习实战》Peter Harrington著
写在最后:本文参考以上资料进行整合与总结,属于原创,文章中可能出现理解不当的地方,若有所见解或异议可在下方评论,谢谢!
若需转载请注明:http://www.cnblogs.com/lliuye/p/8981586.html
k邻近算法理解及代码实现的更多相关文章
- 机器学习算法及代码实现–K邻近算法
机器学习算法及代码实现–K邻近算法 1.K邻近算法 将标注好类别的训练样本映射到X(选取的特征数)维的坐标系之中,同样将测试样本映射到X维的坐标系之中,选取距离该测试样本欧氏距离(两点间距离公式)最近 ...
- Python实现kNN(k邻近算法)
Python实现kNN(k邻近算法) 运行环境 Pyhton3 numpy科学计算模块 计算过程 st=>start: 开始 op1=>operation: 读入数据 op2=>op ...
- k邻近算法(KNN)实例
一 k近邻算法原理 k近邻算法是一种基本分类和回归方法. 原理:K近邻算法,即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例,这K个实例的多数属于某个类,就把该输入实 ...
- 《机器学习实战》学习笔记一K邻近算法
一. K邻近算法思想:存在一个样本数据集合,称为训练样本集,并且每个数据都存在标签,即我们知道样本集中每一数据(这里的数据是一组数据,可以是n维向量)与所属分类的对应关系.输入没有标签的新数据后,将 ...
- 监督学习——K邻近算法及数字识别实践
1. KNN 算法 K-近邻(k-Nearest Neighbor,KNN)是分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一.该方法的思路是:如果一个样本在特征空间中的k个最相似( ...
- <机器学习实战>读书笔记--k邻近算法KNN
k邻近算法的伪代码: 对未知类别属性的数据集中的每个点一次执行以下操作: (1)计算已知类别数据集中的点与当前点之间的距离: (2)按照距离递增次序排列 (3)选取与当前点距离最小的k个点 (4)确定 ...
- [机器学习实战] k邻近算法
1. k邻近算法原理: 存在一个样本数据集,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系.输入没有标签的新数据后,将新数据的每个特征与样本集中数据对 ...
- kaggle赛题Digit Recognizer:利用TensorFlow搭建神经网络(附上K邻近算法模型预测)
一.前言 kaggle上有传统的手写数字识别mnist的赛题,通过分类算法,将图片数据进行识别.mnist数据集里面,包含了42000张手写数字0到9的图片,每张图片为28*28=784的像素,所以整 ...
- kmeans算法理解及代码实现
github:kmeans代码实现1.kmeans代码实现2(包含二分k-means) 本文算法均使用python3实现 1 聚类算法 对于"监督学习"(supervised ...
随机推荐
- mongodb副本集的docker化安装
1. 定义 一般只要生产环境就需要考虑冗余设计,保证在某一台服务器由于某种原因宕机后服务还可以正常运行. mongo副本集是一组服务器,其中有一个主服务器(primary),用于处理客户端请求:还有多 ...
- 在我的职业生涯中,没有一种技能比 SQL 更有用!
作者 | Craig Kerstiens 译者 | 阿拉丁 创业公司 CitusData(CitusData 是一家将 PostgreSQL 商业化的初创企业,也是 PostgreSQL 社区领导者, ...
- 我的名字叫hadoop
第一回 新入环境 我的名字是hadoop,我一出生我的爸爸雅虎就给我取了这样一个名字:hadoop,我也不知道为什么叫这个名字,刚出生没多久,雅虎爸爸就把我领进一个黑暗的屋子里面,屋里堆满了黑色的 ...
- Milking Order
Milking Order 题意:给出m个描述状态,其中包含若干个边的关系,问最多能取x (x<=m)个状态,使得形成的图没有环.就是说取x个状态,用状态中的关系建边,其中不能有环. 题解:最大 ...
- 北京Uber优步司机奖励政策(2月25日)
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...
- LeetCode: 56. Merge Intervals(Medium)
1. 原题链接 https://leetcode.com/problems/merge-intervals/description/ 2. 题目要求 给定一个Interval对象集合,然后对重叠的区域 ...
- cakephp中find('list')的使用
运用一.快速实现下拉菜单 控制器中,使用find('list')返回的是键值对的数组,键名是array的第一个参数id,键值就是第二个参数content. public function list_s ...
- unity3d 角色头顶信息3D&2D遮挡解决方案(一)
先上效果图,只凭文字描述,脑补应该有些困难- - 如图:有三个角色(我们暂且从左到右叫它们A.B.C),一个2D UI(中间动作选择的框框),一个cube(右边的方块) cube挡住了角色C的头顶信息 ...
- 初识c++模板元编程
模板元编程(Template metaprogramming,简称TMP)是编译器内执行的程序,编译器读入template,编译输出的结果再与其他源码一起经过普通编译过程生成目标文件.通俗来说,普通运 ...
- 「日常训练」 Longest Run on a Snowboard (UVA-10285)
题意 其实就是一条二维的LIS,但是还是做的一愣一愣的,多努力. 考虑$dp[i][j]$为从(i,j)出发的二维LIS的最大值,那么$dp[i][j]=max\{dp[i−di[k]][j−dj[k ...