Twitter-Snowflake,64位自增ID算法详解
Twitter-Snowflake算法产生的背景相当简单,为了满足Twitter每秒上万条消息的请求,每条消息都必须分配一条唯一的id,这些id还需要一些大致的顺序(方便客户端排序),并且在分布式系统中不同机器产生的id必须不同。
snowflake把时间戳,工作机器id,序列号组合在一起。
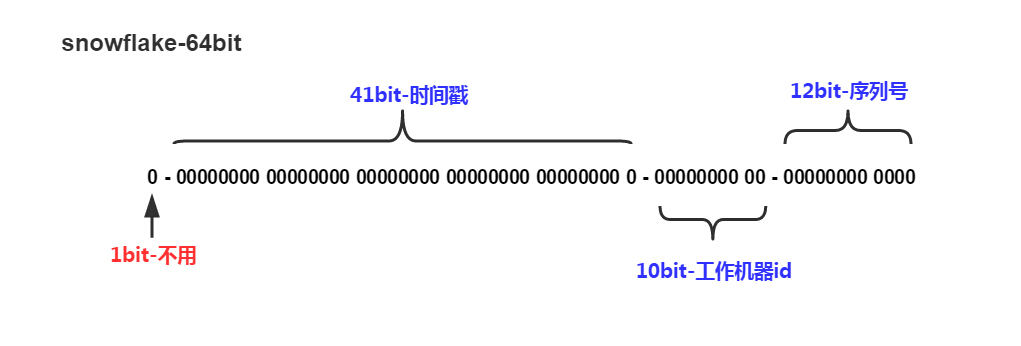
除了最高位bit标记为不可用以外,其余三组bit占位均可浮动,看具体的业务需求而定。以下关于此算法的可行性研究
Console.WriteLine("41bit的时间戳可以支持该算法使用年限:{0}", (1L << ) / (3600L * * * 1000.0));
Console.WriteLine("10bit的工作机器id数量:{0}", (1L << ) - );
Console.WriteLine("12bit序列id数量:{0}", (1L << ) - );
运行结果:
41bit的时间戳可以支持该算法使用年限:69.7305700010147
10bit的工作机器id数量:
12bit序列id数量:
默认情况下41bit的时间戳(从当前开始计算)可以支持该算法使用近70年,10bit的工作机器id可以支持1023台机器,序列号支持1毫秒产生4095个自增序列id。那么理论上,一个应用1秒钟可以产生409万条自增ID,此算法可持续使用近70年。完全能满足我们日常开发项目的需求。
工作机器id严格意义上来说这个bit段的使用可以是进程级,机器级的话你可以使用MAC地址来唯一标示工作机器,工作进程级可以使用IP+Path来区分工作进程。如果工作机器比较少,可以使用配置文件来设置这个id是一个不错的选择,如果机器过多配置文件的维护是一个灾难性的事情。这个工作机器id的bit段也可以进一步拆分,比如用前5个bit标记workerid,后5个bit标记datacenterid,具体代码如下:
class Snowflake
{ //工作机器id的bit段拆分为前5个bit标记workerid,后5个bit标记datacenterid
const int WorkerIdBits = ;
const int DatacenterIdBits = ;
//序列号bit数
const int SequenceBits = ;
//最大编号限制
const long MaxWorkerId = -1L ^ (-1L << WorkerIdBits);
const long MaxDatacenterId = -1L ^ (-1L << DatacenterIdBits);
private const long SequenceMask = -1L ^ (-1L << SequenceBits);
//位左运算移动量
public const int WorkerIdShift = SequenceBits;
public const int DatacenterIdShift = SequenceBits + WorkerIdBits;
public const int TimestampLeftShift = SequenceBits + WorkerIdBits + DatacenterIdBits; //序列号记录
private long _sequence = 0L;
//时间戳记录
private long _lastTimestamp = -1L; public long WorkerId { get; protected set; }
public long DatacenterId { get; protected set; } public Snowflake(long workerId, long datacenterId, long sequence = 0L)
{
WorkerId = workerId;
DatacenterId = datacenterId;
_sequence = sequence; // sanity check for workerId
if (workerId > MaxWorkerId || workerId < )
{
throw new ArgumentException( String.Format("worker Id can't be greater than {0} or less than 0", MaxWorkerId) );
} if (datacenterId > MaxDatacenterId || datacenterId < )
{
throw new ArgumentException( String.Format("datacenter Id can't be greater than {0} or less than 0", MaxDatacenterId));
} }
/// <summary>
/// 格林时间戳
/// </summary>
/// <returns></returns>
public long TimeGen()
{
DateTime Jan1st1970 = new DateTime(, , , , , , DateTimeKind.Utc);//
return (long)(DateTime.UtcNow - Jan1st1970).TotalMilliseconds;
} readonly object _lock = new Object(); public virtual long NextId()
{
lock (_lock)
{
var timestamp = TimeGen(); if (timestamp < _lastTimestamp)
{
throw new InvalidSystemClock(String.Format(
"发现最新时间戳少{0}毫秒的异常", _lastTimestamp - timestamp));
} if (_lastTimestamp == timestamp)
{
_sequence = (_sequence + ) & SequenceMask;
if (_sequence == )
{
//序列号超过限制,重新取时间戳
timestamp = TilNextMillis(_lastTimestamp);
}
}
else
{
_sequence = ;
} _lastTimestamp = timestamp;
//snowflake算法
var id = (timestamp << TimestampLeftShift) |
(DatacenterId << DatacenterIdShift) |
(WorkerId << WorkerIdShift) | _sequence; return id;
}
}
/// <summary>
/// 重新取时间戳
/// </summary>
protected virtual long TilNextMillis(long lastTimestamp)
{
var timestamp = TimeGen();
while (timestamp <= lastTimestamp)
{
//新的时间戳要大于旧的时间戳,才算作有效时间戳
timestamp = TimeGen();
}
return timestamp;
}
}
Twitter-Snowflake,64位自增ID算法详解的更多相关文章
- 【转】Twitter-Snowflake,64位自增ID算法详解
Twitter-Snowflake算法产生的背景相当简单,为了满足Twitter每秒上万条消息的请求,每条消息都必须分配一条唯一的id,这些id还需要一些大致的顺序(方便客户端排序),并且在分布式系统 ...
- windows 64位下,React-Native环境搭建详解 (Android)
React-Native环境搭建需要: 1.安装Java JDK 2.安装Android Studio 3.安装node.js 4.安装git 5.安装Python 2.x (注意目前不支持Pytho ...
- DonkeyID---php扩展-64位自增ID生成器
##原理 参考Twitter-Snowflake 算法,扩展了其中的细节.具体组成如下图: 如图所示,64bits 咱们分成了4个部分. 毫秒级的时间戳,有42个bit.能够使用139年,从1970年 ...
- Twitter-Snowflake:自增ID算法
简介 Twitter 早期用 MySQL 存储数据,随着用户的增长,单一的 MySQL 实例没法承受海量的数据,后来团队就研究如何产生完美的自增ID,以满足两个基本的要求: 每秒能生成几十万条 ID ...
- Twitter分布式自增ID算法snowflake原理解析
以JAVA为例 Twitter分布式自增ID算法snowflake,生成的是Long类型的id,一个Long类型占8个字节,每个字节占8比特,也就是说一个Long类型占64个比特(0和1). 那么一个 ...
- Twitter分布式自增ID算法snowflake原理解析(Long类型)
Twitter分布式自增ID算法snowflake,生成的是Long类型的id,一个Long类型占8个字节,每个字节占8比特,也就是说一个Long类型占64个比特(0和1). 那么一个Long类型的6 ...
- 详解Twitter开源分布式自增ID算法snowflake(附演算验证过程)
详解Twitter开源分布式自增ID算法snowflake,附演算验证过程 2017年01月22日 14:44:40 url: http://blog.csdn.net/li396864285/art ...
- 分布式自增ID算法-Snowflake详解
1.Snowflake简介 互联网快速发展的今天,分布式应用系统已经见怪不怪,在分布式系统中,我们需要各种各样的ID,既然是ID那么必然是要保证全局唯一,除此之外,不同当业务还需要不同的特性,比如像并 ...
- 安全体系(三)——SHA1算法详解
本文主要讲述使用SHA1算法计算信息摘要的过程. 安全体系(零)—— 加解密算法.消息摘要.消息认证技术.数字签名与公钥证书 安全体系(一)—— DES算法详解 安全体系(二)——RSA算法详解 为保 ...
随机推荐
- linux下JDK1.7安装
http://mnt.conf.blog.163.com/blog/static/115668258201210793915876/ 一.软件下载1.下载JDK(下面分别是32位系统和64位系统下的版 ...
- ion-header-bar
ion-header-bar 指令声明一个标题栏元素,标题栏总是位于屏幕顶部 它有两个同级的可选属性 align-title:设置标题文字的对齐方式.允许值:left|right|center no- ...
- Oracle 数据库SQL性能查看
作为一个开发/测试人员,或多或少都得和数据库打交道,而对数据库的操作归根到底都是SQL语句,所有操作到最后都是操作数据,那么对sql性能的掌控又成了我们工作中一件非常重要的工作.下面简单介绍下一些查看 ...
- Android深度探索HAL与驱动开发 第二章 搭建Android开发环境
通常以应用移植和系统移植的为Andorid系统移植的主要部分.同时为了适应不同平台硬件设备,对源代码进行相应的修改.除了要移植相适应的CPU架构,最重要是移植Linux驱动. 但是由于一些特别的原因, ...
- sql server 更新视图的sp
create procedure RefreshAllViewas begin declare @ViewName varchar(250) declare #views cursor for sel ...
- epoll 反应堆
epoll反应堆模型 ================================ 下面代码实现的思想:epoll反应堆模型:( libevent 网络编程开源库 核心思想) . 普通多路IO转接 ...
- eclipse中的窗口切换快捷键
Ctrl+Shift+F6 很简单,如果以后改用IDEA的话就没用了,但这个窗口切换确实很复杂,看起来也操作比较快.
- 如何搭建 node,react 开发环境
项目相关内容:Sublime + Node + React --注意:在 windows 操作系统中,如果把 node 安装在系统盘(一般是C盘),会导致 node 没有操作文件的权限的问题,如无法新 ...
- Controller
http://www.cnblogs.com/artech/archive/2012/08/15/action-result-03.html
- 转载:scala中:: , +:, :+, :::, ++的区别
原文链接:https://segmentfault.com/a/1190000005083578 初学Scala的人都会被Seq的各种操作符所confuse.下面简单列举一下各个Seq操作符的区别. ...