Servlet与多线程与IO操作
1.JVM内存模型相关概念
2.Java多线程并发深入理解
3.Servlet、设计模式、SpringMVC深入理解
4.Java基础遗漏点补充
数据库连接池:JDBC connection pool,频繁的建立、关闭连接,会极大的减低系统的性能,因为对于连接的使用成了系统性能的瓶颈。连接复用。通过建立一个数据库连接池以及一些管理方法,使得一个数据库连接可以得到高效、安全的复用,避免了数据库连接频繁建立、关闭的开销。对于共享资源,有一个很著名的设计模式:资源池。该模式正是为了解决资源频繁分配、释放所造成的问题的。把该模式应用到数据库连接管理领域,就是建立一个数据库连接池,提供一套高效的连接分配、使用策略,最终目标是实现连接的高效、安全的复用。数据库连接池的基本原理是在内部对象池中维护一定数量的数据库连接,并对外暴露数据库连接获取和返回方法。外部使用者可通过getConnection 方法获取连接,使用完毕后再通过releaseConnection 方法将连接返回,注意此时连接并没有关闭,而是由连接池管理器回收,并为下一次使用做好准备。
使用数据库连接池的优势:资源重用<由于数据库连接得到重用,避免了频繁创建、释放连接引起的大量性能开销。在减少系统消耗的基础上,另一方面也增进了系统运行环境的平稳性(减少内存碎片以及数据库临时进程/线程的数量)。>更快的系统响应速度:<数据库连接池在初始化过程中,往往已经创建了若干数据库连接置于池中备用。此时连接的初始化工作均已完成。对于业务请求处理而言,直接利用现有可用连接,避免了数据库连接初始化和释放过程的时间开销,从而缩减了系统整体响应时间。>新的资源分配手段:<对于多应用共享同一数据库的系统而言,可在应用层通过数据库连接的配置,实现数据库连接池技术。某一应用最大可用数据库连接数的限制,避免某一应用独占所有数据库资源。>统一的连接管理,避免数据库连接泄漏:<在较为完备的数据库连接池实现中,可根据预先的连接占用超时设定,强制收回被占用连接。从而避免了常规数据库连接操作中可能出现的资源泄漏。一个最小化的数据库连接池实现.>
数据库的游标:游标实际上是一种能从包括多条数据记录的结果集中每次提取一条记录的机制。游标由结果集和结果集中指向特定记录的游标位置组成。主要用于循环处理结果集,有点儿像for循环。那么为什么使用游标?使用游标有什么作用?在关系型数据库中,我们查询的集合是面向集合的

而游标打破了这一规则,对于游标来说,思维方式是面向行的。而且在性能上,游标吃更多的内存,减少可用的并发,占用带宽。如果用取钱来做比喻,我们取1000元钱。SQL结果集方式是一次取1000元,而采用游标则是10次取,每此取100元。存在即合理,我们使用游标是因为,某些状况无法实现查询的时候,我们使用游标来实现。

游标的生命周期由五部分构成:定义游标、打开游标、使用游标、关闭游标、释放游标。定义游标像是在定义游标变量,有游标类型+游标变量。
//定义游标
DECLARE test
//定义并赋值
DECLARE test=CUST //打开游标
OPEN test //关闭游标
CLOSE test //释放游标
DEALLOCATE test

下面是使用游标的过程,给我们的结论就是尽量使用while,子查询,临时表,函数,表变量等来替代游标。游标性能极差。尽量不要用,用完一定要释放。

数据库应用,在许多软件系统中经常用到,是开发中大型系统不可缺少的辅助。但如果对数据库资源没有很好地管理(如:没有及时回收数据库的游标(ResultSet)、Statement、连接 (Connection)等资源),往往会直接导致系统的稳定。这类不稳定因素,不单单由数据库或者系统本身一方引起,只有系统正式使用后,随着流量、用户的增加,才会逐步显露。在基于Java开发的系统中,JDBC是程序员和数据库打交道的主要途径,提供了完备的数据库操作方法接口。但考虑到规范的适用性,JDBC只提供了最直接的数据库操作规范,对数据库资源管理,如:对物理连接的管理及缓冲,期望第三方应用服务器(Application Server)的提供。
本文,以JDBC规范为基础,介绍相关的数据库连接池机制,并就如果以简单的方式,实现有效地管理数据库资源介绍相关实现技术。
2.在linux下,如何监控和查看JVM的内存。
使用命令jmap,linux下特有的一个命令。用于观察运行时期jvm物理内存的一个占用情况。jmap -heap可以打印出jvm堆内存的使用情况。
补充,linux中命令top。用于显示执行中的程序进程。
linux中命令free,用于显示内存的使用情况。(free比top只占用很少的系统资源)查看free命令输出内容的解释:total:总计物理内存的大小。used:已使用多大。
linux中的命令kill用来终止一个进程。查看当前进程用ps,查看当前当前路径用pwd,文件权限修改chmod,查看帮助文档man,显示文件内容cat,
-Xms 和 -Xmx 分别代表分配JVM的最小内存和最大内存。
-Xms:minimum memory size for pile and heap
-Xmx:maximum memory size for pile and heap
3.Executor框架和Fork/Join框架,简述。
java.util.concurrent.Executors类,用于创建和管理线程。当我们建立ThreadPool和ThreadFactory的时候,用此类。
然后说说Executor框架,Executor框架指jdk中引入的一系列并发库中与executor相关的功能,其中包括线程池、Executor、Executors、ExecutorService、CompletionService、Future、Callable等。在Executor框架中,使用执行器Executor来管理Thread对象,从而简化了并发编程。
Fork/join框架是对原来的Executors更进一步,在原来的基础上增加了并行分治计算中的一种Work-stealing策略,就是指的是。当一个线程正在等待他创建的子线程运行的时候,当前线程如果完成了自己的任务后,就会寻找还没有被运行的任务并且运行他们,这样就是和Executors这个方式最大的区别,更加有效的使用了线程的资源和功能。所以非常推荐使用Fork/Join框架。
4.在Java并发编程中,解决共享资源问题冲突的时候,可以考虑使用锁机制。
对象的锁,所有对象都自动含有单一的锁。JVM负责跟踪对象被加锁的次数。如果一个对象被解锁,其计数变为0。在任务(线程)第一次给对象加锁的时候,计数变为1。 每当这个相同的任务(线程)在此对象上获得锁时,计数会递增。只有首先获得锁的任务(线程)才能继续获取该对象上的多个锁。每当任务离开一个synchronized方法,计数递减,当计数为0的时候,锁被完全释放,此时别的任务就可以使用此资源。
synchronized同步块,第一种,当使用同步块时,如果方法下的同步块都同步到一个对象上的锁,则所有的任务(线程)只能互斥的进入这些同步块。Resource1.java演示了三个线程(包括main线程)试图进入某个类的三个不同的方法的同步块中,虽然这些同步块处在不同的方法中,但由于是同步到同一个对象(当前对象 synchronized (this)),所以对它们的方法依然是互斥的。第二种,同步到多个对象锁,Resource1.java演示了三个线程(包括main线程)试图进入某个类的三个不同的方法的同步块中,这些同步块处在不同的方法中,并且是同步到三个不同的对象(synchronized (this),synchronized (syncObject1),synchronized (syncObject2)),所以对它们的方法中的临界资源访问是独立的。
综上所述,我们知道:1.在java.util.concurrent.locks包下提供了另一种方式实现同步访问,那就是Lock类。既然有了synchronized,为什么还要使用lock呢?如果一个代码块被synchronized修饰了,当一个线程获取了对应的锁,并执行该代码块时,其他线程便只能一直等待,等待获取锁的线程释放锁,而这里获取锁的线程释放锁只会有两种情况:1)获取锁的线程执行完了该代码块,然后线程释放对锁的占有;2)线程执行发生异常,此时JVM会让线程自动释放锁。那么如果这个获取锁的线程由于要等待IO或者其他原因(比如调用sleep方法)被阻塞了,但是又没有释放锁,其他线程便只能干巴巴地等待,试想一下,这多么影响程序执行效率。因此就需要有一种机制可以不让等待的线程一直无期限地等待下去(比如只等待一定的时间或者能够响应中断),通过Lock就可以办到。再举个例子:当有多个线程读写文件时,读操作和写操作会发生冲突现象,写操作和写操作会发生冲突现象,但是读操作和读操作不会发生冲突现象。但是采用synchronized关键字来实现同步的话,就会导致一个问题:如果多个线程都只是进行读操作,所以当一个线程在进行读操作时,其他线程只能等待无法进行读操作。因此就需要一种机制来使得多个线程都只是进行读操作时,线程之间不会发生冲突,通过Lock就可以办到。另外,通过Lock可以知道线程有没有成功获取到锁。这个是synchronized无法办到的。那么也就是说,Lock提供了比synchronized更多的功能。但是要注意以下几点:1)Lock不是Java语言内置的,synchronized是Java语言的关键字,因此是内置特性。Lock是一个类,通过这个类可以实现同步访问;2)Lock 和synchronized有一点非常大的不同,采用 synchronized不需要用户去手动释放锁,当synchronized方法或者synchronized代码块执行完之后,系统会自动让线程释放对锁的占用;而Lock则必须要用户去手动释放锁,如果没有主动释放锁,就有可能导致出现死锁现象。
public void interface Lock{
public void lock(); //获取锁
public void unlock(); //释放锁,发生异常也要由人来手动释放锁,故必须写在finally代码中,防止死锁发生。
}
ReentrantLock类是唯一实现了接口Lock的类,它叫做可重入锁。
ReadWriteLock也是一个接口,在它里面只定义了两个方法:
public void interface ReadWirteLock{
Lock readLock();
Lock writeLock();
}
一个用来获取读锁,一个用来获取写锁。也就是说将文件的读写操作分开,分成2个锁来分配给线程,从而使得多个线程可以同时进行读操作。不过要注意的是,如果有一个线程已经占用了读锁,则此时其他线程如果要申请写锁,则申请写锁的线程会一直等待释放读锁。
http://www.cnblogs.com/dolphin0520/p/3923167.html
插播语:Lock和synchronized有以下几点不同:1)Lock是一个接口,而synchronized是Java中的关键 字,synchronized是内置的语言实现;2)synchronized在发生异常时,会自动释放线程占有的锁,因此不会导致死锁现象发生;而 Lock在发生异常时,如果没有主动通过unLock()去释放锁,则很可能造成死锁现象,因此使用Lock时需要在finally块中释放锁;3)Lock可以让等待锁的线程响应中断,而synchronized却不行,使用synchronized时,等待的线程会一直等待下去,不能够响 应中断;4)通过Lock可以知道有没有成功获取锁,而synchronized却无法办到。5)Lock可以提高多个线程进行读操作的效率。在性能上来说,如果竞争资源不激烈,两者的性能是差不多的,而当竞争资源非常激烈时(即有大量线程同时竞争),此时Lock的性能要远远优于synchronized。所以说,在具体使用时要根据适当情况选择。
什么叫做可重入锁?可重入性表明了锁的分配机制:基于线程的分配,而不是基于方法调用的分配。举个简单的例子,当一个线程执行到某个synchronized 方法时,比如说method1,而在method1中会调用另外一个synchronized方法method2,此时线程不必重新去申请锁,而是可以直接执行方法method2。
什么叫做可中断锁?可中断锁:顾名思义,就是可以相应中断的锁。在Java中,synchronized就不是可中断锁,而Lock是可中断锁。如果某一线程A正在执行锁中的代码,另一线程B正在等待获取该锁,可能由于等待时间过长,线程B不想等待了,想先处理其他事情,我们可以让它中断自己或者在别的线程中中断它,这种就是可中断锁。在前面演示lockInterruptibly()的用法时已经体现了Lock的可中断性。
什么叫做公平锁?公平锁即尽量以请求锁的顺序来获取锁。比如同是有多个线程在等待一个锁,当这个锁被释放时,等待时间最久的线程(最先请求的线程)会获得该所,这种就是公平锁。非公平锁即无法保证锁的获取是按照请求锁的顺序进行的。这样就可能导致某个或者一些线程永远获取不到锁。在Java中,synchronized就是非公平锁,它无法保证等待的线程获取锁的顺序。而对于ReentrantLock和ReentrantReadWriteLock,它默认情况下是非公平锁,但是可以设置为公平锁。
什么叫做读写锁?读写锁将对一个资源(比如文件)的访问分成了2个锁,一个读锁和一个写锁。正因为有了读写锁,才使得多个线程之间的读操作不会发生冲突。ReadWriteLock就是读写锁,它是一个接口,ReentrantReadWriteLock实现了这个接口。可以通过readLock()获取读锁,通过writeLock()获取写锁。上面已经演示过了读写锁的使用方法,在此不再赘述。
基本上所有的并发模式在解决线程安全问题时,都采用“序列化访问临界资源”的方案,即在同一时刻,只能有一个线程访问临界资源,也称作同步互斥访问。
5.关键字volatile解析。
由于使用volatile关键字是与Java的内存模型有关的,所以先了解一下Java内存模型。cpu、高速缓存、内存。在cpu和高速缓存之间非常细粒度的。使用关键字volatile使得细粒度的依然线程安全。
我们知道使用sychronized是用来修饰代码块的,使用volatile则是用来修饰变量的。。当用volatile修饰了变量,线程在每次使用变量的时候,都会读取变量修改后的最新值。分析代码如下:
public class Counter{
public static int count = 0;
public static void inc(){
try{
Thread.sleep(1);
}catch (InterruptException e){
e.printStack();
}
count++;
}
public static void main(String args[]){
for(int i = 0; i < 1000; i++){
new Thread(new Runnable(){
@override
public void run(){
Counter.inc();
}
}).start();
}
System.out.println("运行结果是:Counter.count:"+Counter.count);
}
}
实际上代码的运行结果,每次都不一样。那么我们可能觉得在变量上加上volatile之后,是不是就不会产生线程不安全的问题了,结果不是我们所期望的结果了。
那么我们把代码修改为public volatile static int count = 0;这时候再运行一次,看到结果仍然不是我们所期望的1000,是什么原因呢?分析一下:
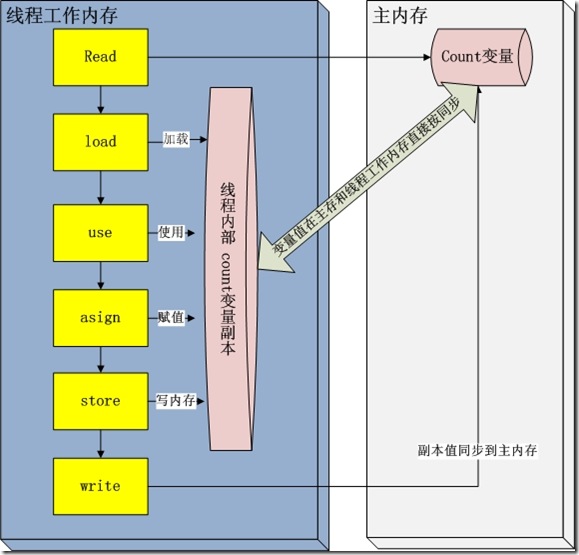
我们看上面这个图。我们知道当JVM运行的时候,其中有一块儿内存区域是虚拟机栈,是线程私有的。用于保存线程运行时的变量信息。当线程访问某一个对象的值的时候,首先通过对象的应用找到对应在堆内存中的变量的值。然后把堆内存变量的具体值load到线程本地内存中,建立一个变量副本,之后线程就不再和对象在堆内存的变量值有任何关系,而是直接修改副本变量的值。当修改完之后的某一个时刻,线程退出之前,自动把线程变量副本的值会写到对象在堆中的变量。这样在堆中的对象的值就产生变化了。
read and load 从堆复制变量到当前工作内存(虚拟机栈)
use and assign 执行代码,改变共享变量值 其中use and assign 可以多次出现
store and write 用工作内存(虚拟机栈)数据刷新堆内存的相关内容
但是这一些操作并不是原子性,也就是 在read load之后,如果主内存count变量发生修改之后,线程工作内存中的值由于已经加载,不会产生对应的变化,所以计算出来的结果会和预期不一样。对于volatile修饰的变量,jvm虚拟机只是保证从主内存加载到线程工作内存的值是最新的。例如假如线程1,线程2 在进行read,load 操作中,发现主内存中count的值都是5,那么都会加载这个最新的值。在线程1堆count进行修改之后,会write到主内存中,主内存中的count变量就会变为6。线程2由于已经进行read,load操作,在进行运算之后,也会更新主内存count的变量值为6。导致两个线程及时用volatile关键字修改之后,还是会存在并发的情况。
(两个进程同时修改x的值,并且同时开始同时完成,则无法保证数据的期望)。volatile具备sychronized的可见性特性,但是不具备原则特性。
******************************************************************************************************************************************************************
说完多线程在说说面试中常常被问到的Servlet。前面说到了Tomcat是容器,Servlet组件,web项目都是提供的基于Servlet接口或者jar包实现的,至于SpringMVC都是小助手,简化我们项目开发的一些催化剂和辅助功能。
第一,Servlet的生命周期:
Servlet 生命周期:Servlet 加载--->实例化--->服务--->销毁。
init():在Servlet的生命周期中,仅执行一次init()方法。它是在服务器装入Servlet时执行的,负责初始化Servlet对象。可以配置服务器,以在启动服务器或客户机首次访问Servlet时装入Servlet。无论有多少客户机访问Servlet,都不会重复执行init()。
service():它是Servlet的核心,负责响应客户的请求。每当一个客户请求一个HttpServlet对象,该对象的Service()方法就要调用,而且传递给这个方法一个“请求”(ServletReque
st)对象和一个“响应”(ServletResponse)对象作为参数。在HttpServlet中已存在Service()方法。默认的服务功能是调用与HTTP请求的方法相应的do功能。
destroy(): 仅执行一次,在服务器端停止且卸载Servlet时执行该方法。当Servlet对象退出生命周期时,负责释放占用的资源。一个Servlet在运行service()方法时可能会产生其他的线程,因此需要确认在调用destroy()方法时,这些线程已经终止或完成。
Tomcat 与 Servlet 是如何工作的:

我们分析一下这个执行步骤:
1.web client(就是浏览器)向Servlet容器(就是Tomcat)发出http请求。
2.Servlet容器接受web client请求。
3.Servlet容器创建一个HttpRequest对象,将web client请求的信息封装到这个对象中。(怪不得通过request.get方法可以获取请求信息)
4.Servlet容器创建一个HttpResponse对象。
5.Servlet容器调用HttpServlet对象的service( )方法, 把HttpRequest对象和HttpResponse对象作为参数传给HttpServlet对象。
6.HttpServlet调用HttpRequest对象的有关方法,获取http请求信息。
7.HttpServlet调用HttpResponse对象的有关方法,生成响应数据。
8.Servlet容器把HttpServlet的响应结果传给Web Client。
第二,说说Servlet的工作原理。
Servlet工作原理,首先简单解释一下Servlet接收和响应客户请求的过程,首先客户发送一个请求,Servlet是调用service()方法对请求进行响应的,通过源代码可见,service()方法中对请求的方式进行了匹配,选择调用doGet,doPost等这些方法,然后再进入对应的方法中调用逻辑层的方法,实现对客户的响应。在Servlet接口和GenericServlet中是没有doGet()、doPost()等等这些方法的,HttpServlet中定义了这些方法,但是都是返回error信息,所以,我们每次定义一个Servlet的时候,都必须实现doGet或doPost等这些方法。其次,每一个自定义的Servlet都必须实现Servlet的接口,Servlet接口中定义了五个方法,其中比较重要的三个方法涉及到Servlet的生命周期,分别是上文提到的init(),service(),destroy()方法。GenericServlet是一个通用的,不特定于任何协议的Servlet,它实现了Servlet接口。而HttpServlet继承于GenericServlet,因此HttpServlet也实现了Servlet接口。所以我们定义Servlet的时候只需要继承HttpServlet即可。Servlet接口和GenericServlet是不特定于任何协议的,而HttpServlet是特定于HTTP协议的类,所以HttpServlet中实现了service()方法,并将请求ServletRequest、ServletResponse 强转为HttpRequest 和 HttpResponse。
第三,说说创建Servlet对象的时机。
<servlet>
<servlet-name>Init</servlet-name>
<servlet-class>org.xl.servlet.InitServlet</servlet-class>
<load-on-startup>1</load-on-startup>
</servlet>
创建Servlet对象的时机:Servlet容器(tomcat)启动时:读取web.xml配置文件中的信息,构造指定的Servlet对象,创建ServletConfig对象,同时将ServletConfig对象作为参数来调用Servlet对象的init方法。在Servlet容器启动后:客户首次向Servlet发出请求,Servlet容器会判断内存中是否存在指定的Servlet对象,如果没有则创建它,然后根据客户的请求创建HttpRequest、HttpResponse对象,从而调用Servlet 对象的service方法。Servlet Servlet容器在启动时自动创建Servlet,这是由在web.xml文件中为Servlet设置的<load-on-startup>属性决定的。从中我们也能看到同一个类型的Servlet对象在Servlet容器中以单例的形式存在。
第四,Servlet是线程安全的么?
先给你答案:Servlet规范中说Servlet不是线程安全的。接下来依次理解什么是线程不安全?Servlet为什么线程不安全?如何解决Servlet中的线程不安全问题?
线程安全的概念,场景:多个线程同时在访问一段代码,或同时操作某个变量。如果每次运行结果和单线程运行的结果是一样的,而且其他变量的值也和预期的是一样的,就是线程安全的。反之,就是线程不安全的。(其实线程安全的机制并不是仅仅是由sychronized修饰,阿里社招犯的错。)
为什么Servlet线程不安全,我们前面看到init()方法只执行一次,Servlet容器中只有一个实例化的对象,它是singleton的,所以会产生多个线程同时访问一个Servlet实例对象。如果我们在唯一的Servlet实例变量中定义了全局变量和静态变量。那么线程不安全是必然的。所以说,Servlet的线程安全完由它的实现来决定的,如果它的内部属性或方法被多个线程改变,它就是线程不安全的。
解决Servlet的线程不安全问题,有以下几种方案,我们先看一个代码实例:
// 有如下的代码:
public class TestServlet extends HttpServlet {
private int count = 0; @Override
protected void service(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
response.getWriter().println("<HTML><BODY>");
response.getWriter().println(this + " ==> ");
response.getWriter().println(Thread.currentThread() + ": <br>");
for(int i=0;i<5;i++){
response.getWriter().println("count = " + count + "<BR>");
try {
Thread.sleep(1000);
count++;
} catch (Exception e) {
e.printStackTrace();
}
}
response.getWriter().println("</BODY></HTML>");
}
} //当同时打开多个浏览器,输入http://localhost:8080/ServletTest/TestServlet时,他们显示的结果不同,这就说明了对于属性count来说,它是线程不安全的,将以上的代码重构,则有
public class TestServlet extends HttpServlet {
private int count = 0;
private String synchronizeStr = "";
@Override
protected void service(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
response.getWriter().println("<HTML><BODY>");
response.getWriter().println(this + " ==> ");
response.getWriter().println(Thread.currentThread() + ": <br>");
synchronized (synchronizeStr){
for(int i=0;i<5;i++){
response.getWriter().println("count = " + count + "<BR>");
try {
Thread.sleep(1000);
count++;
} catch (Exception e) {
e.printStackTrace();
}
}
}
response.getWriter().println("</BODY></HTML>");
}
}
重构之后的代码是安全的。
但是,采用了上面的方法之后,同时有100个浏览器来访问的时候,会造成堵塞的问题,排队会排好长,像上海的浦东12路公交车。改进的方法就是:
没有用synchronized来同步,因为会造成堵塞;而是采用了实现接口SingleThreadModel
public class TestServlet extends HttpServlet implements SingleThreadModel{
private int count = 0;
private String synchronizeStr = "";
@Override
protected void service(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
response.getWriter().println("<HTML><BODY>");
response.getWriter().println(this + " ==> ");
response.getWriter().println(Thread.currentThread() + ": <br>");
for(int i=0;i<5;i++){
response.getWriter().println("count = " + count + "<BR>");
try {
Thread.sleep(1000);
count++;
} catch (Exception e) {
e.printStackTrace();
}
}
response.getWriter().println("</BODY></HTML>");
}
}
该接口指定了系统如何处理对同一个Servlet的调用,如果一个Servlet被这个接口指定,那么这个Servlet接口中的service()方法将不会有两个线程被同时执行,当然也不存在线程安全的问题。
第五,基于以上的理解,我们知道了容器、组件、Servlet,那么他们跟我们的框架SpringMVC又是什么关系呢?
我们知道:JSP+Servlet+javabean是最基本的jsp技术。前台的标签jstl、freemarker等都是为了使jsp页面看起来更简洁、代码更容易维护。
*************************************************************************************************************************************************************************
重点知识:Java中的TreeMap和TreeSet,以及红黑树和AVL树。
AVL树,就是平衡二叉查找树。特点:左右子树高度之差的绝对值最多为1.
红黑树,是一种二叉查找树,它在每个节点上增加一个存储位表示节点的颜色。可以是Red或Black。通过对任何一条从根到叶子节点的路径上的各个节点着色方式的限制,红黑树确保没有一条路径会比其他路径长处两倍。因而是接近平衡的。红黑树上每个结点内含五个域,color,key,left,right,p。如果相应的指针域没有,则设为NIL。每个结点要么是红的,要么是黑的。根结点是黑的。每个叶结点,即空结点(NIL)是黑的。如果一个结点是红的,那么它的俩个儿子都是黑的。对每个结点,从该结点到其子孙结点的所有路径上包含相同数目的黑结点。
多线程中的数据争用问题:
共享变量:如果一个变量在多个线程中的工作内存中都存在副本,那么这个变量就是这几个线程的共享变量。
可见性:一个线程对共享变量值的修改,能够及时的被其他线程看到。
JVM内存模型,规范了Java程序中各种变量的访问规则,只有共享变量才会引起线程的争用。(所有的变量都在主内存中,每个线程都有自己独立的工作内存,里面保存着该线程使用到的变量副本)。
线程对共享变量的所有操作都必须在自己的工作内存中进行,不能直接从主内存中读写;同时不同线程之间无法访问其他线程工作内存中的变量,线程间变量值的传递需要通过主内存来完成。共享变量的值的传递是需要通过主内存这个桥梁来完成的。如果线程一对共享变量值的修改,想要被线程二及时的看到,必须要经过两个步骤:把工作内存一中更新过的共享变量刷新到主内存中,然后,将主内存中最新的共享变量值更新到工作内存二中。
要实现共享变量的可见性,必须保证两点:线程修改后的共享变量值能够及时从工作内存刷新到主内存中。其他线程能够及时的把共享变量的最新值从主内存更新到自己的工作内存中。Java语言层面支持的可见性实现方式有两种,Sychronized和volatile。sychronized是同步,它可以实现互斥锁,它能保证在同一时刻只能有一个线程在执行锁里面的代码。所以sychronized能够保证锁内实现的一个原子性。同时sychronized还有另外一个特性,内存可见性。JDK中对sychronized有这样的规定:线程解锁前,必须把共享变量的最新值刷新到主内存中,线程加锁时,将清空工作内存中的共享变量的值,从而使用共享变量时,将会从主内存中从新读取最新值。(注意:加锁和解锁需要同一把锁!!)这样就保证了线程对共享变量的修改在下次加锁时对其他线程的可见。综上所述,sychronized实现可见性的工作步骤如下:1.首先会获得互斥锁,2.然后清空工作内存,3.然后从主内存拷贝变量的最新副本到工作内存,4.接着执行代码,5.把更改后的共享变量值再刷新到主内存中,6.释放互斥锁。
接下来,我们再看看关键字volatile,它能保证可见性,但是不能保证原子性。接下来分析一下为什么volatile不是原子性。如private int number = 0; number++;很显然,这个number++不是原子操作,因为它分为三个步骤,读取number的值,将number的值加1,写入最新的number的值。那么sychronized{number++};很显然可以保证了原子性。如果采用private volatile int number = 0;它是不能保证原子性的。
Java的IO输入输出流,包括几点:字节流和字符流的使用;编码问题;File类的使用;RandomAccessFile的使用;对象的序列化和反序列化。
Servlet与多线程与IO操作的更多相关文章
- Servlet基础(三) Servlet的多线程同步问题
Servlet基础(三) Servlet的多线程同步问题 Servlet/JSP技术和ASP.PHP等相比,由于其多线程运行而具有很高的执行效率. 由于Servlet/JSP默认是以多线程模式执行的, ...
- python之协程与IO操作
协程 协程,又称微线程,纤程.英文名Coroutine. 协程的概念很早就提出来了,但直到最近几年才在某些语言(如Lua)中得到广泛应用. 子程序,或者称为函数,在所有语言中都是层级调用,比如A调用B ...
- AI学习---数据IO操作&神经网络基础
数据IO操作 TF支持3种文件读取: 1.直接把数据保存到变量中 2.占位符配合feed_dict使用 3. QueueRunner(TF中特有的) 文件读取流程 文件读取流程(多线 ...
- Servlet的多线程和线程安全
线程安全 首先说明一下对线程安全的讨论,哪种情况我们可以称作线程安全?网上对线程安全有很多描述,我比较喜欢<Java并发编程实战>给出的定义,“当多个线程访问某个类时,不管运行时环境采用何 ...
- Linux IO操作——RIO包
1.linux基本I/O接口介绍 ssize_t read(int fd, void *buf, size_t count); ssize_t write(int fd, void *buf, siz ...
- servlet的多线程并发问题
package gz.itcast.e_thread; import java.io.IOException; import javax.servlet.ServletException; impor ...
- 提高生产力:文件和IO操作(ApacheCommonsIO-汉化分享)
复制.移动.删除.比较.监控.文件读写 等文件和IO操作是编程中比较常用的功能. 幸运的是,Apache Commons IO等开源组件已经帮我们实现了. 我们可以不用重复 ...
- 013-java中的IO操作-InputStream/Reader、OutputStream/Writer
一.概述 IO流用来处理设备之间的数据传输,上传文件和下载文件,Java对数据的操作是通过流的方式,Java用于操作流的对象都在IO包中. 流是一组有顺序的,有起点和终点的字节集合,是对数据传输的总称 ...
- Linux网络编程三、 IO操作
当从一个文件描述符进行读写操作时,accept.read.write这些函数会阻塞I/O.在这种会阻塞I/O的操作好处是不会占用cpu宝贵的时间片,但是如果需要对多个描述符操作时,阻塞会使同一时刻只能 ...
随机推荐
- 关于页面查询多数据查询问题(foreach)
最近纠结的一个问题,就是页面综合查询总报错,之前用过传参用list传就没问题,但现在用map总是报错,缓释直接贴图吧,希望对遇到问题的朋友有帮助页面传来参数,之前是 这样写的,直接将拿来的数据封装成一 ...
- ASP.NET MVC TagBuilder使用
ASP.NET MVC在需要进行新建HTML辅助方法时,可以来使用TagBuilder类. TagBuilder类常用方法: 方法名称 说明 AddCssClass() 可在卷标中添加一个新的Clas ...
- 轻松自动化---selenium-webdriver(python) (十)
本节重点 处理下拉框 switch_to_alert() accept() 下拉框是我们最常见的一种页面元素,对于一般的元素,我们只需要一次就定位,但下拉框里的内容需要进行两次定位,先定位到下拉框,再 ...
- Nutch源码阅读进程5---updatedb
看nutch的源码仿佛就是一场谍战片,而构成这精彩绝伦的谍战剧情的就是nutch的每一个从inject->generate->fetch->parse->update的环节,首 ...
- ArcGIS Earth数据小析
ArcGIS Earth,一款轻量级的三维地球应用.因为工作关系下载试用了半天,正好借这个机会简单研究一下ArcGIS Earth的大概思路,特别是地形数据的组成和影像数据的加载,在这总结整理一下.下 ...
- 【Java基础】枚举和注解
在Java1.5版本中,引入了两个类型:枚举类型enum type和注解类型annotation type. Num1:用enum代替int常量 枚举类型enum type是指由一组固定的常量组成合法 ...
- Azure ARM (4) 开始创建ARM Resource Group并创建存储账户
<Windows Azure Platform 系列文章目录> 好了,接下来我们开始创建Azure Resource Group. 1.我们先登录Azure New Portal,地址是: ...
- SQL Server代理(9/12):理解作业和安全
SQL Server代理是所有实时数据库的核心.代理有很多不明显的用法,因此系统的知识,对于开发人员还是DBA都是有用的.这系列文章会通俗介绍它的很多用法. 在这个系列的前一篇文章里,你学习了如何在S ...
- 分享在winform下实现左右布局多窗口界面
在web页面上我们可以通过frameset,iframe嵌套框架很容易实现各种导航+内容的布局界面,而在winform.WPF中实现其实也很容易,我这里就分享一个:在winform下实现左右布局多窗口 ...
- CSS魔法堂:你一定误解过的Normal flow
前言 刚接触CSS时经常听到看到一个词"文档流",那到底什么是"文档流"呢?然后会看到"绝对定位和浮动定位能脱离文档流",从这句可以看到文 ...