spark job, stage ,task介绍。
1. spark 如何执行程序?
首先看下spark 的部署图:
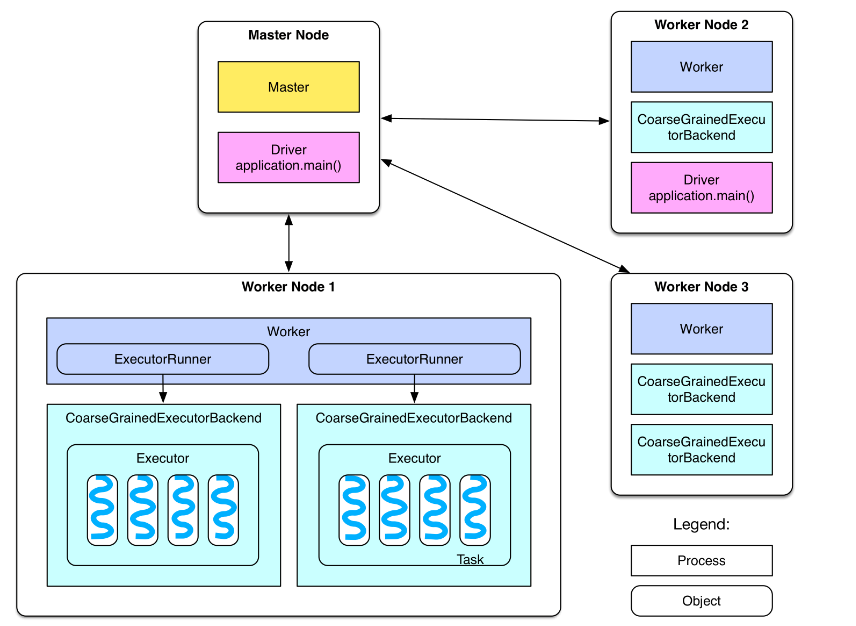
节点类型有:
1. master 节点: 常驻master进程,负责管理全部worker节点。
2. worker 节点: 常驻worker进程,负责管理executor 并与master节点通信。
dirvier:官方解释为: The process running the main() function of the application and creating the SparkContext。即理解为用户自己编写的应用程序
Executor:执行器:
在每个WorkerNode上为某应用启动的一个进程,该进程负责运行任务,并且负责将数据存在内存或者磁盘上,每个任务都有各自独立的Executor。
Executor是一个执行Task的容器。它的主要职责是:
1、初始化程序要执行的上下文SparkEnv,解决应用程序需要运行时的jar包的依赖,加载类。
2、同时还有一个ExecutorBackend向cluster manager汇报当前的任务状态,这一方面有点类似hadoop的tasktracker和task。
总结:Executor是一个应用程序运行的监控和执行容器。Executor的数目可以在submit时,由 --num-executors (on yarn)指定.
Job:
包含很多task的并行计算,可以认为是Spark RDD 里面的action,每个action的计算会生成一个job。
用户提交的Job会提交给DAGScheduler,Job会被分解成Stage和Task。
Stage:
一个Job会被拆分为多组Task,每组任务被称为一个Stage就像Map Stage, Reduce Stage。
Stage的划分在RDD的论文中有详细的介绍,简单的说是以shuffle和result这两种类型来划分。在Spark中有两类task,一类是shuffleMapTask,一类是resultTask,第一类task的输出是shuffle所需数据,第二类task的输出是result,stage的划分也以此为依据,shuffle之前的所有变换是一个stage,shuffle之后的操作是另一个stage。比如 rdd.parallize(1 to 10).foreach(println) 这个操作没有shuffle,直接就输出了,那么只有它的task是resultTask,stage也只有一个;如果是rdd.map(x => (x, 1)).reduceByKey(_ + _).foreach(println), 这个job因为有reduce,所以有一个shuffle过程,那么reduceByKey之前的是一个stage,执行shuffleMapTask,输出shuffle所需的数据,reduceByKey到最后是一个stage,直接就输出结果了。如果job中有多次shuffle,那么每个shuffle之前都是一个stage。
Task
即 stage 下的一个任务执行单元,一般来说,一个 rdd 有多少个 partition,就会有多少个 task,因为每一个 task 只是处理一个 partition 上的数据.
每个executor执行的task的数目, 可以由submit时,--num-executors(on yarn) 来指定。
spark job, stage ,task介绍。的更多相关文章
- 【Spark】Stage生成和Stage源代码浅析
引入 上一篇文章<DAGScheduler源代码浅析>中,介绍了handleJobSubmitted函数,它作为生成finalStage的重要函数存在.这一篇文章中,我将就DAGSched ...
- spark教程(13)-shuffle介绍
shuffle 简介 shuffle 描述了数据从 map task 输出到 reduce task 输入的过程,shuffle 是连接 map 和 reduce 的桥梁: shuffle 性能的高低 ...
- 【原】Spark中Stage的提交源码解读
版权声明:本文为原创文章,未经允许不得转载. 复习内容: Spark中Job如何划分为Stage http://www.cnblogs.com/yourarebest/p/5342424.html 1 ...
- spark 笔记 9: Task/TaskContext
DAGScheduler最终创建了task set,并提交给了taskScheduler.那先得看看task是怎么定义和执行的. Task是execution执行的一个单元. Task: execut ...
- Spark分区数、task数目、core数目、worker节点数目、executor数目梳理
Spark分区数.task数目.core数目.worker节点数目.executor数目梳理 spark隐式创建由操作组成的逻辑上的有向无环图.驱动器执行时,它会把这个逻辑图转换为物理执行计划,然后将 ...
- Spark 的 Shuffle过程介绍`
Spark的Shuffle过程介绍 Shuffle Writer Spark丰富了任务类型,有些任务之间数据流转不需要通过Shuffle,但是有些任务之间还是需要通过Shuffle来传递数据,比如wi ...
- Spark的Shuffle过程介绍
Spark的Shuffle过程介绍 Shuffle Writer Spark丰富了任务类型,有些任务之间数据流转不需要通过Shuffle,但是有些任务之间还是需要通过Shuffle来传递数据,比如wi ...
- spark 划分stage Wide vs Narrow Dependencies 窄依赖 宽依赖 解析 作业 job stage 阶段 RDD有向无环图拆分 任务 Task 网络传输和计算开销 任务集 taskset
每个job被划分为多个stage.划分stage的一个主要依据是当前计算因子的输入是否是确定的,如果是则将其分在同一个stage,从而避免多个stage之间的消息传递开销. http://spark. ...
- spark 笔记 15: ShuffleManager,shuffle map两端的stage/task的桥梁
无论是Hadoop还是spark,shuffle操作都是决定其性能的重要因素.在不能减少shuffle的情况下,使用一个好的shuffle管理器也是优化性能的重要手段. ShuffleManager的 ...
随机推荐
- PSP(11.9~11.16)
14号 类别c 内容c 开始时间s 结束e 中断I 净时间T 看书 设计模式 15:20 17:10 25m 85m 看书 构建执法 19:00 20:10 0m 70m 15号 类别c 内容c 开始 ...
- java httpclient cookie
BasicCookieStore cookieStore = new BasicCookieStore();BasicClientCookie cookie = new BasicClientCook ...
- pod install后无反应
参考这篇文章 http://akinliu.github.io/2014/05/03/cocoapods-specs-/
- LR12.53—第7课:分析场景
第7课:分析场景 在前面的课程中,您学习如何设计,控制和执行方案运行.一旦您已加载您的服务器,你要分析的运行,并确定需要被淘汰,以提高系统性能的问题. 在图表和报告中有关方案的性能您的分析会议上提出的 ...
- iOS开发阶段技能总结
这是一篇自己平时纪录的笔记... 1.基本的数据结构常识:链表,队列,栈 2.基本的算法:排序,动态规划等常用算法 3.基本的概念,cocoa,各种自带的view的使用. 4.xcode自带的测试:O ...
- String类常用方法
1.String类的特点,字符串一旦被初始化就不会被改变. 2.String对象定义的两种方式 ①String s = "affdf";这种定义方式是在字符串常量池中创建一个Str ...
- background-size拉伸背景图片
在制作页面中常需要对背景图片在容器中进行平铺,可用background-size属性对背景编辑:拉伸,压缩等~ background-size:contain; 将背景扩展到整个容器大小. 较为实用的 ...
- 登陆判读,并跳转到指定页面(window.location.href='http://localhost/index.html')
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 functio ...
- Android 5.0属性
//水波纹效果//v 指定控件 x屏幕的 x轴 y轴 endRadio 起始位置 水波半径Animator circularReveal = ViewAnimationUtils.createCirc ...
- Datasnap Image
delphi用,不能与java.c#互相识别. procedure TServerMethods.UpdateDoc(ItemID : integer; doc : TStream); delphi用 ...