海康威视研究院ImageNet2016竞赛经验分享
原文链接:https://zhuanlan.zhihu.com/p/23249000
目录

场景分类
数据增强
- 第一,对颜色的数据增强,包括色彩的饱和度、亮度和对比度等方面,主要从Facebook的代码里改过来的。
- 第二,PCA Jittering,最早是由Alex在他2012年赢得ImageNet竞赛的那篇NIPS中提出来的. 我们首先按照RGB三个颜色通道计算了均值和标准差,对网络的输入数据进行规范化,随后我们在整个训练集上计算了协方差矩阵,进行特征分解,得到特征向量和特征值,用来做PCA Jittering。
- 第三,在图像进行裁剪和缩放的时候,我们采用了随机的图像差值方式。
- 第四, Crop Sampling,就是怎么从原始图像中进行缩放裁剪获得网络的输入。


如下图所示,对比原始的尺度和长宽比增强变换,我们方法的优点在于,我们根据目标物体出现在不同位置的概率信息,去选择不同的Crop区域,送进模型训练。通过引入这种有监督的信息,我们可以利用正确的信息来更好地训练模型,以提升识别准确率。 (+0.5~0.7)

样本平衡
场景数据集有800万样本,365个类别,各个类别的样本数非常不平衡,有很多类别的样本数达到了4万,也有很多类别的样本数还不到5000。这么大量的样本和非常不均匀的类别分布,给模型训练带来了难题。
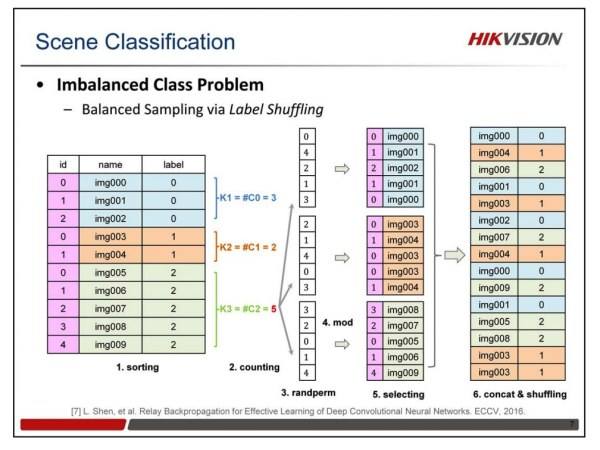
Label Shuffling平衡策略
- 首先对原始的图像列表,按照标签顺序进行排序;
- 然后计算每个类别的样本数量,并得到样本最多的那个类别的样本数。
- 根据这个最多的样本数,对每类随机都产生一个随机排列的列表;
- 然后用每个类别的列表中的数对各自类别的样本数求余,得到一个索引值,从该类的图像中提取图像,生成该类的图像随机列表;
- 然后把所有类别的随机列表连在一起,做个Random Shuffling,得到最后的图像列表,用这个列表进行训练。
Label Smoothing策略

性能提升技巧
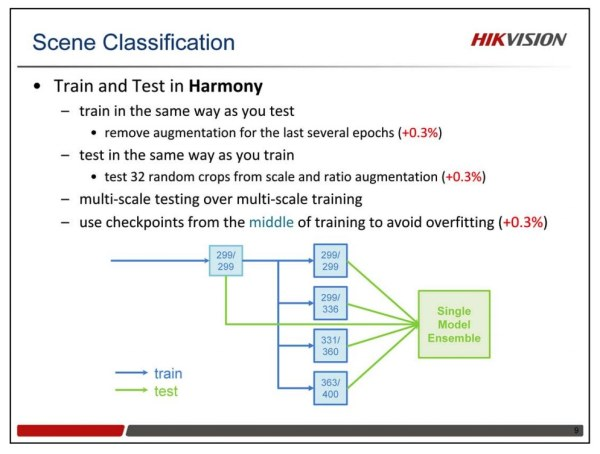
对于模型结构,没什么特别的改进,我们主要使用了Inception v3和Inception ResNet v2,以及他们加深加宽的版本。还用到了Wide ResNet 。

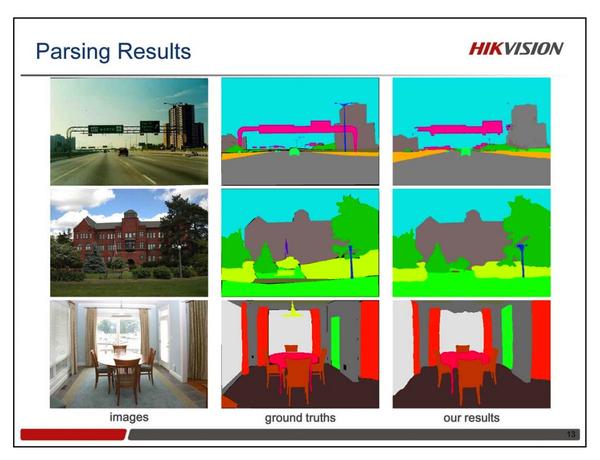
场景解析
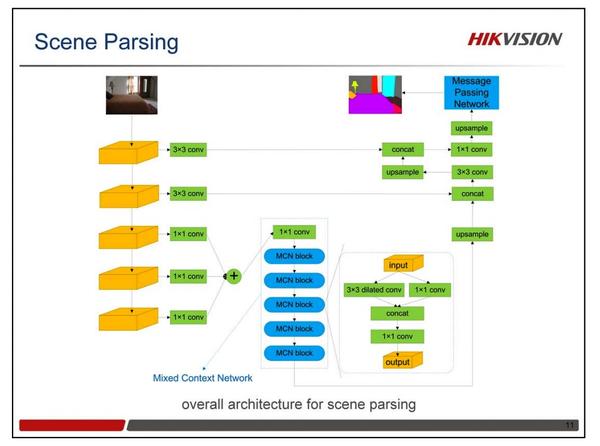
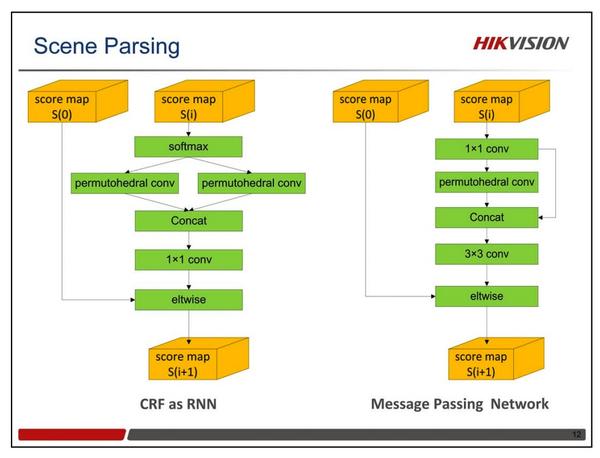
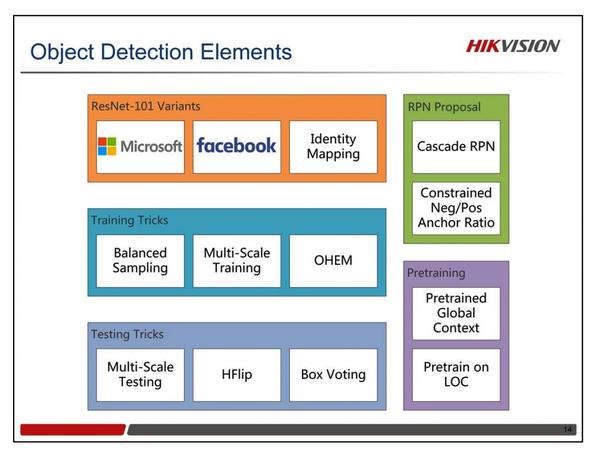
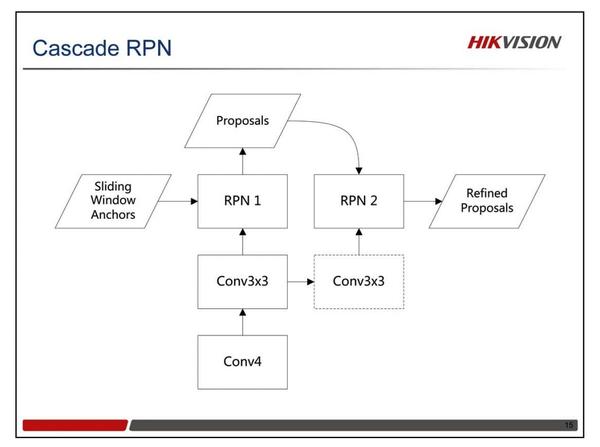
物体检测与定位





海康威视研究院ImageNet2016竞赛经验分享的更多相关文章
- 分享一个学习的网站:每天会有大量AI相关的干货(论文分享,行业动态,相关竞赛经验分享等)http://www.deepsmart.ai/
网址:http://www.deepsmart.ai/ 微信公众号如下:
- 【干货】Kaggle 数据挖掘比赛经验分享(mark 专业的数据建模过程)
简介 Kaggle 于 2010 年创立,专注数据科学,机器学习竞赛的举办,是全球最大的数据科学社区和数据竞赛平台.笔者从 2013 年开始,陆续参加了多场 Kaggle上面举办的比赛,相继获得了 C ...
- Kaggle 数据挖掘比赛经验分享(转)
原作者:陈成龙 简介 Kaggle 于 2010 年创立,专注数据科学,机器学习竞赛的举办,是全球最大的数据科学社区和数据竞赛平台.笔者从 2013 年开始,陆续参加了多场 Kaggle上面举办的比 ...
- Kaggle 数据挖掘比赛经验分享
文章发布于公号[数智物语] (ID:decision_engine),关注公号不错过每一篇干货. 来源 | 腾讯广告算法大赛 作者 | 陈成龙 Kaggle 于 2010 年创立,专注数据科学,机器学 ...
- 【原创经验分享】WCF之消息队列
最近都在鼓捣这个WCF,因为看到说WCF比WebService功能要强大许多,另外也看了一些公司的招聘信息,貌似一些中.高级的程序员招聘,都有提及到WCF这一块,所以,自己也关心关心一下,虽然目前工作 ...
- 【原创经验分享】JQuery(Ajax)调用WCF服务
最近在学习这个WCF,由于刚开始学 不久,发现网上的一些WCF教程都比较简单,感觉功能跟WebService没什么特别大的区别,但是看网上的介绍,就说WCF比WebService牛逼多少多少,反正我刚 ...
- (转)CMOS Sensor的调试经验分享
CMOS Sensor的调试经验分享 我这里要介绍的就是CMOS摄像头的一些调试经验. 首先,要认识CMOS摄像头的结构.我们通常拿到的是集成封装好的模组,一般由三个部分组成:镜头.感应器和图像信号处 ...
- 关于启用 HTTPS 的一些经验分享(二)
转载: 关于启用 HTTPS 的一些经验分享(二) 几天前,一位朋友问我:都说推荐用 Qualys SSL Labs 这个工具测试 SSL 安全性,为什么有些安全实力很强的大厂家评分也很低?我认为这个 ...
- 关于启用 HTTPS 的一些经验分享(一)
转载: 关于启用 HTTPS 的一些经验分享(一) 随着国内网络环境的持续恶化,各种篡改和劫持层出不穷,越来越多的网站选择了全站 HTTPS.就在今天,免费提供证书服务的 Let's Encrypt ...
随机推荐
- linux shell--算术运算
求和: 方法一.使用命令替换法: #!/bin/bash read -p 'input number a...' numA read -p 'input number b...' numB #这里有两 ...
- 提取肤色信息原理及操作——opencv
网上也有很多的资料,讲述怎么提取肤色的,大致有5种方法.这几种方法转载http://blog.csdn.net/augusdi/article/details/8865275 第一种:RGB colo ...
- JS如何设置计算几天前的时间?
计算多少天前的具体时间.比如今天是9月5日,那7天前正常就是8月29了. 之前曾经直接用时间进行加减,吃了大亏,后来脑残到直接写了一个很复杂的计算闰年,闰月,30.31.28的月份 现在分享一下. f ...
- C#基础:异步调用 【转】
首先来看一个简单的例子: 小明在烧水,等水烧开以后,将开水灌入热水瓶,然后开始整理家务 小文在烧水,在烧水的过程中整理家务,等水烧开以后,放下手中的家务活,将开水灌入热水瓶,然后继续整理家务 这也是日 ...
- 一点用JS写控制权限的心得
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" ...
- C# AES,AesManaged使用学习
加密 static byte[] EncryptBytes_Aes(byte[] plainText, byte[] Key, byte[] IV) { // Check arguments. ) t ...
- Asp.Net长文件名下载的问题和解决办法
在Asp.Net中写了一个附件上传和下载的程序,附件上传到数据库中,然后将附件的GUID保存起来,我们可以根据GUID来找到数据库中的附件,一般附件下载的代码是: <!--<br /> ...
- 动态获取UIWebView的真正高度
场景 在 App 中使用UIWebView加载网页, 与原生的 UI 显示在一起,一般情况下,webView 的 内容一页是肯定不够的,换句话说,webView 的高度是不定的,那如果原生的 UI是一 ...
- NOPI使用手册
目录 1. 认识NPOI 2. 使用NPOI生成xls文件 2.1 创建基本内容 2.1.1 创建Workbook和Sheet 2.1.2 创建DocumentSummaryInformation和S ...
- 关于OpenXml SpreadSheet列宽根据内容的Auto-suitability
因为之前接到的一个需求,让excel的宽度自动适应.所以最近一直在看Excel相关内容,从结构到.net的两个类库OpenXml和Office.Interop.Excel,再到一些具体的使 ...