Spark SQL 用户自定义函数UDF、用户自定义聚合函数UDAF 教程(Java踩坑教学版)
在Spark中,也支持Hive中的自定义函数。自定义函数大致可以分为三种:
- UDF(User-Defined-Function),即最基本的自定义函数,类似to_char,to_date等
- UDAF(User- Defined Aggregation Funcation),用户自定义聚合函数,类似在group by之后使用的sum,avg等
- UDTF(User-Defined Table-Generating Functions),用户自定义生成函数,有点像stream里面的flatMap
本篇就手把手教你如何编写UDF和UDAF
先来个简单的UDF
场景:
我们有这样一个文本文件:
1^^d
2^b^d
3^c^d
4^^d
在读取数据的时候,第二列的数据如果为空,需要显示'null',不为空就直接输出它的值。定义完成后,就可以直接在SparkSQL中使用了。
代码为:
package test;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.DataFrame;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.SQLContext;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
import java.util.ArrayList;
import java.util.List;
/**
* Created by xinghailong on 2017/2/23.
*/
public class test3 {
public static void main(String[] args) {
//创建spark的运行环境
SparkConf sparkConf = new SparkConf();
sparkConf.setMaster("local[2]");
sparkConf.setAppName("test-udf");
JavaSparkContext sc = new JavaSparkContext(sparkConf);
SQLContext sqlContext = new SQLContext(sc);
//注册自定义方法
sqlContext.udf().register("isNull", (String field,String defaultValue)->field==null?defaultValue:field, DataTypes.StringType);
//读取文件
JavaRDD<String> lines = sc.textFile( "C:\\test-udf.txt" );
JavaRDD<Row> rows = lines.map(line-> RowFactory.create(line.split("\\^")));
List<StructField> structFields = new ArrayList<StructField>();
structFields.add(DataTypes.createStructField( "a", DataTypes.StringType, true ));
structFields.add(DataTypes.createStructField( "b", DataTypes.StringType, true ));
structFields.add(DataTypes.createStructField( "c", DataTypes.StringType, true ));
StructType structType = DataTypes.createStructType( structFields );
DataFrame test = sqlContext.createDataFrame( rows, structType);
test.registerTempTable("test");
sqlContext.sql("SELECT con_join(c,b) FROM test GROUP BY a").show();
sc.stop();
}
}
输出内容为:
+---+----+---+
| a| _c1| c|
+---+----+---+
| 1|null| d|
| 2| b| d|
| 3| c| d|
| 4|null| d|
+---+----+---+
其中比较关键的就是这句:
sqlContext.udf().register("isNull", (String field,String defaultValue)->field==null?defaultValue:field, DataTypes.StringType);
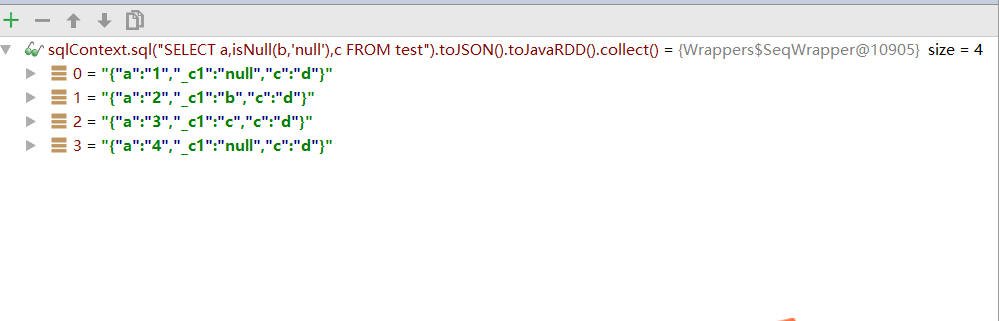
这里我直接用的java8的语法写的,如果是java8之前的版本,需要使用Function2创建匿名函数。
再来个自定义的UDAF—求平均数
先来个最简单的UDAF,求平均数。类似这种的操作有很多,比如最大值,最小值,累加,拼接等等,都可以采用相同的思路来做。
首先是需要定义UDAF函数
package test;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.expressions.MutableAggregationBuffer;
import org.apache.spark.sql.expressions.UserDefinedAggregateFunction;
import org.apache.spark.sql.types.DataType;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
import java.util.ArrayList;
import java.util.List;
/**
* Created by xinghailong on 2017/2/23.
*/
public class MyAvg extends UserDefinedAggregateFunction {
@Override
public StructType inputSchema() {
List<StructField> structFields = new ArrayList<>();
structFields.add(DataTypes.createStructField( "field1", DataTypes.StringType, true ));
return DataTypes.createStructType( structFields );
}
@Override
public StructType bufferSchema() {
List<StructField> structFields = new ArrayList<>();
structFields.add(DataTypes.createStructField( "field1", DataTypes.IntegerType, true ));
structFields.add(DataTypes.createStructField( "field2", DataTypes.IntegerType, true ));
return DataTypes.createStructType( structFields );
}
@Override
public DataType dataType() {
return DataTypes.IntegerType;
}
@Override
public boolean deterministic() {
return false;
}
@Override
public void initialize(MutableAggregationBuffer buffer) {
buffer.update(0,0);
buffer.update(1,0);
}
@Override
public void update(MutableAggregationBuffer buffer, Row input) {
buffer.update(0,buffer.getInt(0)+1);
buffer.update(1,buffer.getInt(1)+Integer.valueOf(input.getString(0)));
}
@Override
public void merge(MutableAggregationBuffer buffer1, Row buffer2) {
buffer1.update(0,buffer1.getInt(0)+buffer2.getInt(0));
buffer1.update(1,buffer1.getInt(1)+buffer2.getInt(1));
}
@Override
public Object evaluate(Row buffer) {
return buffer.getInt(1)/buffer.getInt(0);
}
}
使用的时候,需要先注册,然后在spark sql里面就可以直接使用了:
package test;
import com.tgou.standford.misdw.udf.MyAvg;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.DataFrame;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.SQLContext;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
import java.util.ArrayList;
import java.util.List;
/**
* Created by xinghailong on 2017/2/23.
*/
public class test4 {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf();
sparkConf.setMaster("local[2]");
sparkConf.setAppName("test");
JavaSparkContext sc = new JavaSparkContext(sparkConf);
SQLContext sqlContext = new SQLContext(sc);
sqlContext.udf().register("my_avg",new MyAvg());
JavaRDD<String> lines = sc.textFile( "C:\\test4.txt" );
JavaRDD<Row> rows = lines.map(line-> RowFactory.create(line.split("\\^")));
List<StructField> structFields = new ArrayList<StructField>();
structFields.add(DataTypes.createStructField( "a", DataTypes.StringType, true ));
structFields.add(DataTypes.createStructField( "b", DataTypes.StringType, true ));
StructType structType = DataTypes.createStructType( structFields );
DataFrame test = sqlContext.createDataFrame( rows, structType);
test.registerTempTable("test");
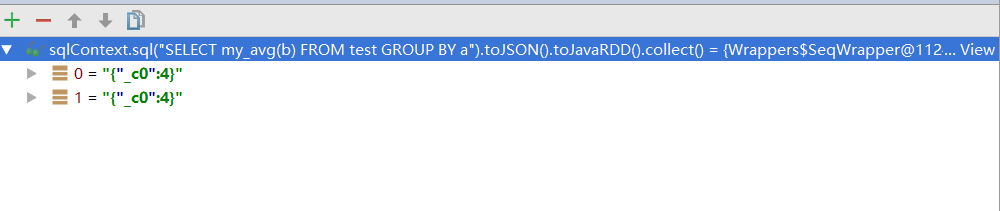
sqlContext.sql("SELECT my_avg(b) FROM test GROUP BY a").show();
sc.stop();
}
}
计算的文本内容为:
a^3
a^6
b^2
b^4
b^6
再来个无所不能的UDAF
真正的业务场景里面,总会有千奇百怪的需求,比如:
- 想要按照某个字段分组,取其中的一个最大值
- 想要按照某个字段分组,对分组内容的数据按照特定字段统计累加
- 想要按照某个字段分组,针对特定的条件,拼接字符串
再比如一个场景,需要按照某个字段分组,然后分组内的数据,又需要按照某一列进行去重,最后再计算值
- 1 按照某个字段分组
- 2 分组校验条件
- 3 然后处理字段
如果不用UDAF,你要是写spark可能需要这样做:
rdd.groupBy(r->r.xxx)
.map(t2->{
HashSet<String> set = new HashSet<>();
for(Object p : t2._2){
if(p.getBs() > 0 ){
map.put(xx,yyy)
}
}
return StringUtils.join(set.toArray(),",");
});
上面是一段伪码,不保证正常运行哈。
这样写,其实也能应付需求了,但是代码显得略有点丑陋。还是不如SparkSQL看的清晰明了...
所以我们再尝试用SparkSql中的UDAF来一版!
首先需要创建UDAF类
import org.apache.commons.lang.StringUtils;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.expressions.MutableAggregationBuffer;
import org.apache.spark.sql.expressions.UserDefinedAggregateFunction;
import org.apache.spark.sql.types.*;
import java.util.*;
/**
*
* Created by xinghailong on 2017/2/23.
*/
public class ConditionJoinUDAF extends UserDefinedAggregateFunction {
@Override
public StructType inputSchema() {
List<StructField> structFields = new ArrayList<>();
structFields.add(DataTypes.createStructField( "field1", DataTypes.IntegerType, true ));
structFields.add(DataTypes.createStructField( "field2", DataTypes.StringType, true ));
return DataTypes.createStructType( structFields );
}
@Override
public StructType bufferSchema() {
List<StructField> structFields = new ArrayList<>();
structFields.add(DataTypes.createStructField( "field", DataTypes.StringType, true ));
return DataTypes.createStructType( structFields );
}
@Override
public DataType dataType() {
return DataTypes.StringType;
}
@Override
public boolean deterministic() {//是否强制每次执行的结果相同
return false;
}
@Override
public void initialize(MutableAggregationBuffer buffer) {//初始化
buffer.update(0,"");
}
@Override
public void update(MutableAggregationBuffer buffer, Row input) {//相同的executor间的数据合并
Integer bs = input.getInt(0);
String field = buffer.getString(0);
String in = input.getString(1);
if(bs > 0 && !"".equals(in) && !field.contains(in)){
field += ","+in;
}
buffer.update(0,field);
}
@Override
public void merge(MutableAggregationBuffer buffer1, Row buffer2) {//不同excutor间的数据合并
String field1 = buffer1.getString(0);
String field2 = buffer2.getString(0);
if(!"".equals(field2)){
field1 += ","+field2;
}
buffer1.update(0,field1);
}
@Override
public Object evaluate(Row buffer) {//根据Buffer计算结果
return StringUtils.join(Arrays.stream(buffer.getString(0).split(",")).filter(line->!line.equals("")).toArray(),",");
}
}
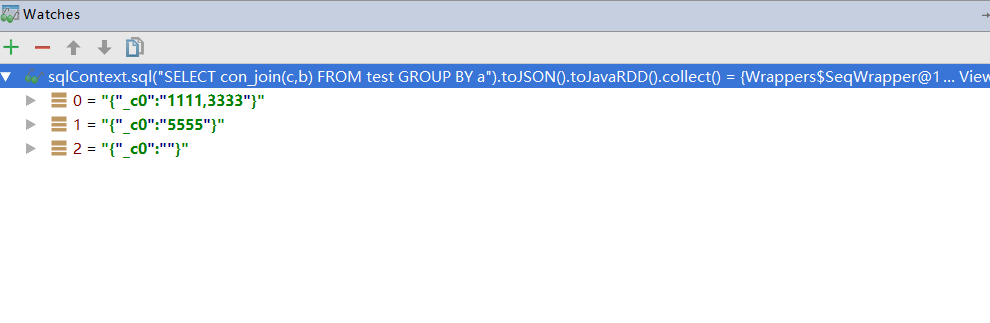
拿一个例子坐下实验:
a^1111^2
a^1111^2
a^1111^2
a^1111^2
a^1111^2
a^2222^0
a^3333^1
b^4444^0
b^5555^3
c^6666^0
按照第一列进行分组,不同的第三列值,进行拼接。
package test;
import test.ConditionJoinUDAF;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.DataFrame;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.SQLContext;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
import java.util.ArrayList;
import java.util.List;
/**
* Created by xinghailong on 2017/2/23.
*/
public class test2 {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf();
sparkConf.setMaster("local[2]");
sparkConf.setAppName("test");
JavaSparkContext sc = new JavaSparkContext(sparkConf);
SQLContext sqlContext = new SQLContext(sc);
sqlContext.udf().register("con_join",new ConditionJoinUDAF());
JavaRDD<String> lines = sc.textFile( "C:\\test2.txt" );
JavaRDD<Row> rows = lines.map(line-> RowFactory.create(line.split("\\^")));
List<StructField> structFields = new ArrayList<StructField>();
structFields.add(DataTypes.createStructField( "a", DataTypes.StringType, true ));
structFields.add(DataTypes.createStructField( "b", DataTypes.StringType, true ));
structFields.add(DataTypes.createStructField( "c", DataTypes.StringType, true ));
StructType structType = DataTypes.createStructType( structFields );
DataFrame test = sqlContext.createDataFrame( rows, structType);
test.registerTempTable("test");
sqlContext.sql("SELECT con_join(c,b) FROM test GROUP BY a").show();
sc.stop();
}
}
这样SQL简洁明了,就能表达意思了。
参考
- Spark Multiple Input/Output User Defined Aggregate Function (UDAF) using Java
- 李震的UDAF·scala版本
- Spark Sql官方文档
- Scala菜鸟教程
- spark1.5 自定义聚合函数UDAF
Spark SQL 用户自定义函数UDF、用户自定义聚合函数UDAF 教程(Java踩坑教学版)的更多相关文章
- Flask聚合函数(基本聚合函数、分组聚合函数、去重聚合函数))
Flask聚合函数 1.基本聚合函数(sun/count/max/min/avg) 使用聚合函数先导入:from sqlalchemy import func 使用方法: sun():func.sum ...
- Spark SQL概念学习系列之用户自定义函数
不多说,直接上干货! 用户自定义函数 注册udf 我们可以使用Spark 支持的编程语言编写好函数,然后通过Spark SQL 内建的方法传递进来,非常便捷地注册我们自己的UDF 在Scala 和Py ...
- Spark(十三)SparkSQL的自定义函数UDF与开窗函数
一 自定义函数UDF 在Spark中,也支持Hive中的自定义函数.自定义函数大致可以分为三种: UDF(User-Defined-Function),即最基本的自定义函数,类似to_char,to_ ...
- SQL语句汇总(三)——聚合函数、分组、子查询及组合查询
聚合函数: SQL中提供的聚合函数可以用来统计.求和.求最值等等. 分类: –COUNT:统计行数量 –SUM:获取单个列的合计值 –AVG:计算某个列的平均值 –MAX:计算列的最大值 –MIN:计 ...
- SQL SERVER 2005允许自定义聚合函数-表中字符串分组连接
不多说了,说明后面是完整的代码,用来将字符串型的字段的各行的值拼成一个大字符串,也就是通常所说的Concat 例如有如下表dict ID NAME CATEGORY 1 RED COLOR ...
- SQL SERVER 2005允许自定义聚合函数
不多说了,说明后面是完整的代码,用来将字符串型的字段的各行的值拼成一个大字符串,也就是通常所说的Concat 例如有如下表dict ID NAME CATEGORY 1 RED COLOR ...
- SQL Server温故系列(4):SQL 查询之集合运算 & 聚合函数
1.集合运算 1.1.并集运算 UNION 1.2.差集运算 EXCEPT 1.3.交集运算 INTERSECT 1.4.集合运算小结 2.聚合函数 2.1.求行数函数 COUNT 2.2.求和函数 ...
- 【2017-03-12】SQL Sever 子查询、聚合函数
一.子查询 子查询:把一条查询语句,当做值来使用子句的查询结果必须是一列子句可以返回多行数据,但必须是一列 子句返回的值为一个值的时候: 例如: 我只知道c026这个编号,我要查询比这个车价格低的全部 ...
- sql sever模糊查询和聚合函数
使用is null 的时候 要确保 查询的列 可以为空! null: 01.标识 空值 02.不是0,也不是空串"" 03.只能出现在定义 允许为null的字段 04.只 ...
随机推荐
- JAVA文件的两种读取方法和三种写入方法
在使用java对文件进行读写操作时,有多种方法可以使用,但不同的方法有不同的性能. 此文对常用的读写方法进行了整理,以备不时之需. 1.文件的读取 主要介绍两种常用的读取方法.按行读取和按字符块读取. ...
- OS X EI Capitan 10.11 & xcode 7.0 beta(7A120f) -- cocoapods安装失败
1.sudo gem install cocoapods: ERROR:While executing gem ... (Errno:EPERM) Operation not permitted - ...
- Spark中的键值对操作
1.PairRDD介绍 Spark为包含键值对类型的RDD提供了一些专有的操作.这些RDD被称为PairRDD.PairRDD提供了并行操作各个键或跨节点重新进行数据分组的操作接口.例如,Pa ...
- ubuntu系统中crontab的使用介绍
1.创建crontab任务 用户hancool
- 读jQuery之二十(Deferred对象)
Deferred对象是由$.Deferred构造的,$.Deferred被实现为简单工厂模式. 它用来解决JS中的异步编程,它遵循 Common Promise/A 规范.实现此规范的还有 when. ...
- ora-04031
诊断并解决ORA-04031 错误 当我们在共享池中试图分配大片的连续内存失败的时候,Oracle首先清除池中当前没使用的所有对象,使空闲内存块合并.如果仍然没有足够大单个的大块内存满足请求,就会产生 ...
- Java线程:线程安全类和Callable与Future(有返回值的线程)
一.线程安全类 当一个类已经很好的同步以保护它的数据时,这个类就称为线程安全的.当一个集合是安全的,有两个线程在操作同一个集合对象,当第一个线程查询集合非空后,删除集合中所有元素的时候,第二个线程也来 ...
- C# 从字符串向 datetime 转换时失败
更改电脑的日期类型即可,把短日期和长日期修改下面的样子即可:
- android 快捷技巧
快捷方式 <!--[if !supportLists]-->0. Ctrl + 1 (快速修复) <!--[if !supportLists]-->1. Ctrl + D (删 ...
- spring mvc rest 方式
handler中编写方式: @RequestMapping("/{userName}/ajaxUser3.do") @ResponseBody public UserInfo aj ...