Hadoop之MapReduce分布式计算
简单介绍一下项目背景——很简单,作死去接下老师的活,然后一干就是半个月,一直忙着从零基础到使用Hadoop中的MapReduce来解决一个实际问题,也就是用来计算一个数据量较大的二度朋友关系。
那么首先是我的上一篇博文:Hadoop之初体验
上一篇博文是将所有的准备前的环境搭建起来了,接下来就HDFS的一些基本的命令操作,那么这些命令如果是想要使用Hadoop的话,那么你就应当熟练的使用(类似于Linux中的命令,那么使用时稍微参考一下,时间不长就能够熟悉)
下边开始介绍MapReduce。
为了介绍MapReduce,我在这里提出来三个问题
问题一:如何统计一个字符串中出现的所有的小写字母出现的次数?
问题二:如何统计一个文件中所有单词出现的次数?
问题三:如何统计多个文件中所有单词出现的一个次数?
好的面对问题一我设计了一个c语言的程序代码,同时将其运行结果展示出来
#include <iostream>
#include <stdlib.h>
#include <string>
#include <string.h> #define MAX_LENGH 100
using namespace std;
char str[MAX_LENGH];
int count[];
int main()
{
for(int i = ;i < MAX_LENGH;i++){ str[i] = (char)('a' + rand()%);
cout<<str[i];
}
str[MAX_LENGH] = '\n';
cout<<str<<endl<<"下面开始匹配"<<endl;
///将结果初始化
for(int i = ;i < ;i++)count[i] = ;
for(int i = ;str[i]!='\n';i++){
count[str[i] - 'a']++;
}
cout<<"Every char and it's time(s):"<<endl;
for(int i = ;i < ;i++){
cout<<(char)('a'+i)<<" : "<<count[i]<<endl;
}
return ;
}
phqghumeaylnlfdxfircvscxggbwkfnqduxwfnfozvsrtkjprepggxrpnrvystmwcysyycqpevikeffm
znimkkasvwsrenzkycxfphqghumeaylnlfdxfircvscxggbwkfnqduxwfnfozvsrtkjprepggxrpnrvy
stmwcysyycqpevikeffmznimkkasvwsrenzkycxf 下面开始匹配
Every char and it's time(s):
a :
b :
c :
d :
e :
f :
g :
h :
i :
j :
k :
l :
m :
n :
o :
p :
q :
r :
s :
t :
u :
v :
w :
x :
y :
z : Process returned (0x0) execution time : 0.149 s
Press any key to continue.
可以看到,代码的一个关键之处就将ascii对应的小写字母和数组的下标进行了一个简单的映射,最后使得统计起来极为方便,只要通过数组下标来访问就可以成功了。
关键代码:
for(int i = 0;str[i]!='\n';i++){ count[str[i] - 'a']++; } cout<<"Every char and it's time(s):"<<endl; for(int i = 0;i < 26;i++){ cout<<(char)('a'+i)<<" : "<<count[i]<<endl; }
好的,我们接着处理问题二:
如何统计一个文件中的所有单词的一个数量。
如何统计呢?我们就会设想,能不能像上一个问题的处理方式一样,也直接使用下标的方式来访问,然后每次对应一个就加一?显然不行,在我们的语法中没有这种形式???有的,在C++中或者在Java中,我们可以使用一个map容器,其中有一个键值对,也就是说来保存一个key和一个value的键值对,最后如同上一题一样将问题处理好
第三问:如何面对同一个问题,我们对多个文件进行处理呢?
在这里我就不提出一个很好的答案了,因为我自己也不知道。我只能给大家一些馊主意,比如说,多次运行上一个程序,一个个的访问文件,将文件中的所有的单词都统计完。或者呢,将所有的文件拼成一个文件,最后再对这个文件进行访问。
好的问题提出来了,然后也给解决了,那么现在就来提出我们一个MapReduce的背景
大计算量,然后短时间计算出结果,同时可以处理一些复杂的问题。
下边我将会从概念,实现步骤和简单的实例对其进行介绍
概念
不想说太多,网上随便找找就有非常多的案例
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。 当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
那么这里我要推荐两个东西,第一个是相对比较生活化的介绍MapReduce,也就是《给老婆讲讲什么是MapReduce》,好像挺火的一篇博问,随便百度一下就能找到
然后第二个就是谷歌,为啥提谷歌呢,毕竟是MapReduce的爸爸吧,谷歌的三篇论文中有一个就是专门讲解MapReduce的
好的,我来说一下实现步骤
这里我上传一些图片供大家参考
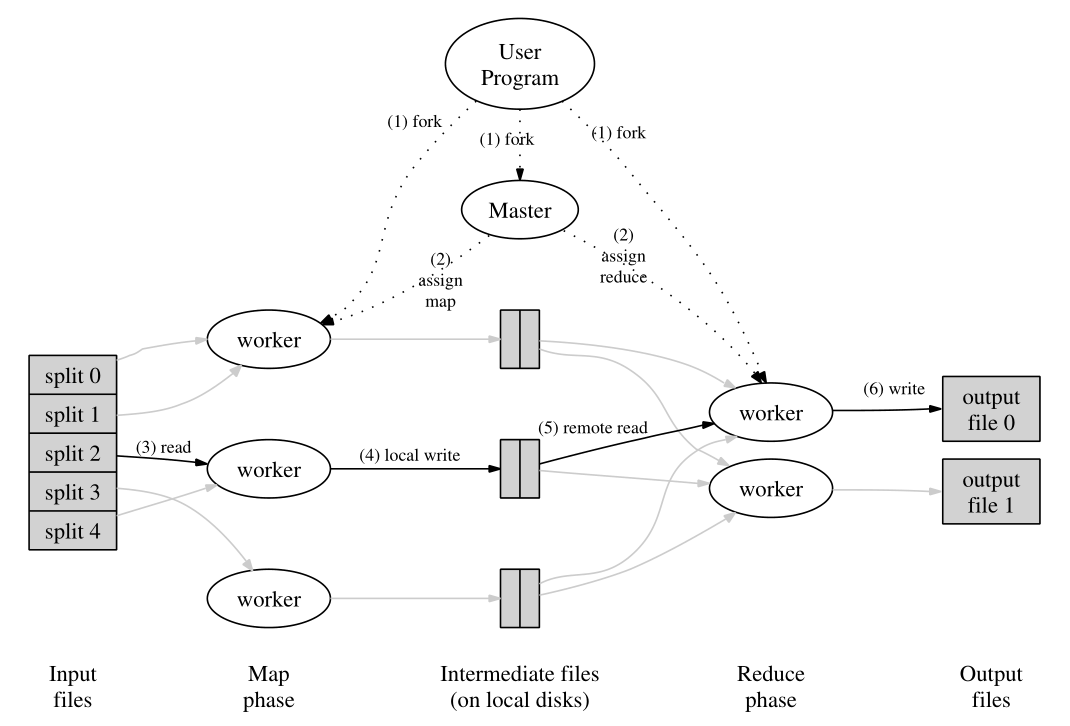
这张图片要注意的就是一个控制的命令流,还有一个就是数据流,两个流的一个流向

这张图片是MapReduce的一个简单案例,wordcount的实现原理
第一步:程序将数据拆分成splits,由于测试用的数据较小,所以每个文件就是一个split,并将文件拆分成<key,value>键值对,这里的key是包括回车在内的字符数的偏移量,value的值为一行文字。 第二步:将分割好的<key,value>键值对交由map()方法进行处理,生成新的键值对<'',1>(其中的''表示的是一个单词) 第三步:得到map()方法输出的<world,1>对,Mapper会将他们按照key值进行排序,并执行Combine过程,将key值相同的value值进行相加,得到Mapper的最终结果 第四步:Reduce先对从Mapper接收的数据进行排序,再交由用户自定义的reduce方法按照相同的键值把数形成累加,新成新的键值对


Shuffle过程优化
Map端的shuffle优化
Reduce端的shuffle优化
任务执行
推测执行
任务jvm重用
跳过坏的记录
任务执行的信息
故障处理
任务失败(分为map或reduce任务失败及子进程jvm突然退出)
TaskTracker失败
JobTracker失败
任务失败重试的处理方法
作业调度
先进先出调度器
能力调度器
公平调度器
MapReduce编程接口
MapReducer编程开发
好的,最后介绍一个具体的数据操作
第一步是我们的wordcount
那么首先我们是使用在Hadoop中的一个默认的一个example中的jar包进行wordcount实验

[root@master wordcount_in]# cat *
hello
world
hello hadoop
hello nice to meet you
my name is zhangjie
以上步骤均为准备输入数据文件
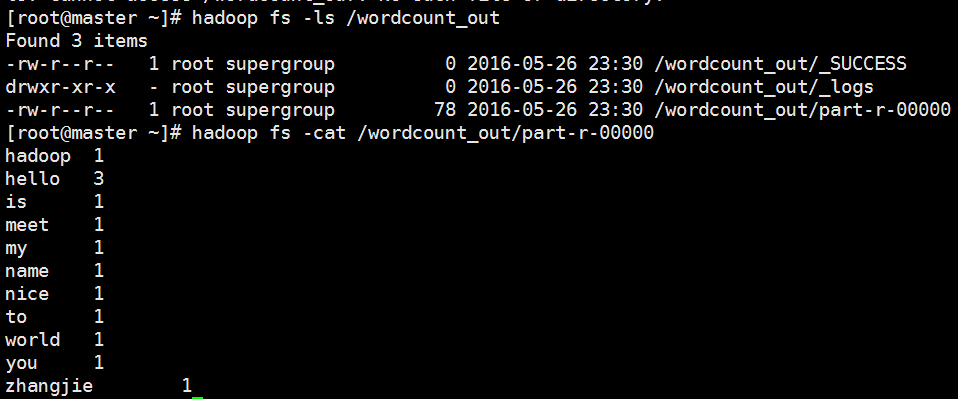

好的,今天先写到这里,后期有时间我将简单为大家介绍一下我那个二度人脉的统计项目
Hadoop之MapReduce分布式计算的更多相关文章
- 【hadoop】MapReduce分布式计算框架原理
PS:实操部分就省略了哈,准备最近好好看下理论这块,其实我是比较懒得哈!!! <?>MapReduce的概述 MapReduce是一种计算模型,进行大数据量的离线计算.MapReduce实 ...
- hadoop的mapReduce和Spark的shuffle过程的详解与对比及优化
https://blog.csdn.net/u010697988/article/details/70173104 大数据的分布式计算框架目前使用的最多的就是hadoop的mapReduce和Spar ...
- Hadoop 新 MapReduce 框架 Yarn 详解
Hadoop 新 MapReduce 框架 Yarn 详解: http://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-yarn/ Ap ...
- 用PHP编写Hadoop的MapReduce程序
用PHP编写Hadoop的MapReduce程序 Hadoop流 虽然Hadoop是用Java写的,但是Hadoop提供了Hadoop流,Hadoop流提供一个API, 允许用户使用任何语言编 ...
- Hadoop之MapReduce程序应用三
摘要:MapReduce程序进行数据去重. 关键词:MapReduce 数据去重 数据源:人工构造日志数据集log-file1.txt和log-file2.txt. log-file1.txt内容 ...
- 从Hadoop骨架MapReduce在海量数据处理模式(包括淘宝技术架构)
从hadoop框架与MapReduce模式中谈海量数据处理 前言 几周前,当我最初听到,以致后来初次接触Hadoop与MapReduce这两个东西,我便稍显兴奋,认为它们非常是神奇.而神奇的东西常能勾 ...
- 对于Hadoop的MapReduce编程makefile
根据近期需要hadoop的MapReduce程序集成到一个大的应用C/C++书面框架.在需求make当自己主动MapReduce编译和打包的应用. 在这里,一个简单的WordCount1一个例子详细的 ...
- Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码
Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本文主要是记录一写我在学习MapReduce时的一些 ...
- Hadoop基础-MapReduce的常用文件格式介绍
Hadoop基础-MapReduce的常用文件格式介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.MR文件格式-SequenceFile 1>.生成SequenceF ...
随机推荐
- IOS使用 Visual Format Language 定义水平和垂直约束
定义限制条件来改变一个 UI 组件在其父视图的水平和垂直方向布局的方法. 可以使用方程式里 H:方向符号代表水平方向的边距,使用 V:方向符号代表垂直方向的边 距. 转载请注明,本文转自:http:/ ...
- Dotliquid使用Json模板变量
Dotliquid是不错的Template Engine,为了更方便使用,扩展了一下,使它支持json数据的替换,引用了Newtonsoft.Json.Linq /// <summary> ...
- js中的AMD规范
回首萧瑟,残月挂角,孤草弄影. 看了一下上一篇随笔的日期,距离上一篇日志又过去了许久.在这段时间中,我尽全力去拯救那间便利店,可惜到最后依然失败,这一次是所有的出路全部没有了,我也做了所有的努力.闲下 ...
- jQuery获取动态生成的元素
需求描述:页面上可以动态添加数据,比如table,点击按钮可以动态添加行.又或页面 加载时table数据是通过ajax从后台获取的.而这时我们想要获取其中的某个值,又该如何获取呢? 如果是要通过某个事 ...
- 冒泡动画按钮的简单实现(使用CSS3)
冒泡动画按钮的简单实现(使用CSS3) 原始的参考文章是 http://tutorialzine.com/2010/10/css3-animated-bubble-buttons/ ,基本原理是利用了 ...
- java中的volatile关键字
java中的volatile关键字 一个变量被声明为volatile类型,表示这个变量可能随时被其他线程改变,所以不能把它cache到线程内存(如寄存器)中. 一般情况下volatile不能代替syn ...
- T-SQL 临时表、表变量、UNION
T-SQL 临时表.表变量.UNION 这次看一下临时表,表变量和Union命令方面是否可以被优化呢? 阅读导航 一.临时表和表变量 二.本次的另一个重头戏UNION 命令 一.临时表和表变量 很多数 ...
- KingPaper初探 wamp下本地虚拟主机的搭建
在本地我们进行网站或系统开发时,因为我们本地的地址以localhost为主机名的 我们上传到服务器会有很多东西要修改 为了避免这些不必要的修改,我们可以在本地搭建虚拟主机 一下是在wamp下搭建虚拟 ...
- Introduction to OOC Programming Language
Introduction to OOC Programming Language 文/akisann @ cnblogs.com / zhaihj @ github.com 本文同时发布在github ...
- C#彻底解决Web Browser 跨域读取Iframes内容
C#彻底解决Web Browser 跨域读取Iframes内容 用C# winform的控件web browser 读取网页内容,分析一下数据,做一些采集工作. 如果是同一个域名下面还是好办的,基本上 ...