技术干货丨卷积神经网络之LeNet-5迁移实践案例
摘要:LeNet-5是Yann LeCun在1998年设计的用于手写数字识别的卷积神经网络,当年美国大多数银行就是用它来识别支票上面的手写数字的,它是早期卷积神经网络中最有代表性的实验系统之一。可以说,LeNet-5就相当于编程语言入门中的“Hello world!”。
华为的昇腾训练芯片一直是大家所期待的,目前已经开始提供公测,如何在昇腾训练芯片上运行一个训练任务,这是目前很多人都在采坑过程中,所以我写了一篇指导文章,附带上所有相关源代码。注意,本文并没有包含环境的安装,请查看另外相关文档。
环境约束:昇腾910目前仅配套TensorFlow 1.15版本。
基础镜像上传之后,我们需要启动镜像命令,以下命令挂载了8块卡(单机所有卡):
docker run -it --net=host --device=/dev/davinci0 --device=/dev/davinci1 --device=/dev/davinci2 --device=/dev/davinci3 --device=/dev/davinci4 --device=/dev/davinci5 --device=/dev/davinci6 --device=/dev/davinci7 --device=/dev/davinci_manager --device=/dev/devmm_svm --device=/dev/hisi_hdc -v /var/log/npu/slog/container/docker:/var/log/npu/slog -v /var/log/npu/conf/slog/slog.conf:/var/log/npu/conf/slog/slog.conf -v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ -v /usr/local/Ascend/driver/tools/:/usr/local/Ascend/driver/tools/ -v /data/:/data/ -v /home/code:/home/local/code -v ~/context:/cache ubuntu_18.04-docker.arm64v8:v2 /bin/bash
设置环境变量并启动手写字训练网络:
#!/bin/bash
export LD_LIBRARY_PATH=/usr/local/lib/:/usr/local/HiAI/runtime/lib64
export PATH=/usr/local/HiAI/runtime/ccec_compiler/bin:$PATH
export CUSTOM_OP_LIB_PATH=/usr/local/HiAI/runtime/ops/framework/built-in/tensorflow
export DDK_VERSION_PATH=/usr/local/HiAI/runtime/ddk_info
export WHICH_OP=GEOP
export NEW_GE_FE_ID=
export GE_AICPU_FLAG=
export OPTION_EXEC_EXTERN_PLUGIN_PATH=/usr/local/HiAI/runtime/lib64/plugin/opskernel/libfe.so:/usr/local/HiAI/runtime/lib64/plugin/opskernel/libaicpu_plugin.so:/usr/local/HiAI/runtime/lib64/plugin/opskernel/libge_local_engine.so:/usr/local/H
iAI/runtime/lib64/plugin/opskernel/librts_engine.so:/usr/local/HiAI/runtime/lib64/libhccl.so export OP_PROTOLIB_PATH=/usr/local/HiAI/runtime/ops/built-in/ export DEVICE_ID=
export PRINT_MODEL=
#export DUMP_GE_GRAPH= #export DISABLE_REUSE_MEMORY=
#export DUMP_OP=
#export SLOG_PRINT_TO_STDOUT= export RANK_ID=
export RANK_SIZE=
export JOB_ID=
export OPTION_PROTO_LIB_PATH=/usr/local/HiAI/runtime/ops/op_proto/built-in/
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/Ascend/fwkacllib/lib64/:/usr/local/Ascend/driver/lib64/common/:/usr/local/Ascend/driver/lib64/driver/:/usr/local/Ascend/add-ons/
export PYTHONPATH=$PYTHONPATH:/usr/local/Ascend/opp/op_impl/built-in/ai_core/tbe
export PATH=$PATH:/usr/local/Ascend/fwkacllib/ccec_compiler/bin
export ASCEND_HOME=/usr/local/Ascend
export ASCEND_OPP_PATH=/usr/local/Ascend/opp
export SOC_VERSION=Ascend910 rm -f *.pbtxt
rm -f *.txt
rm -r /var/log/npu/slog/*.log
rm -rf train_url/* python3 mnist_train.py
以下训练案例中我使用的lecun大师的LeNet-5网络,先简单介绍LeNet-5网络:
LeNet5诞生于1994年,是最早的卷积神经网络之一,并且推动了深度学习领域的发展。自从1988年开始,在多年的研究和许多次成功的迭代后,这项由Yann LeCun完成的开拓性成果被命名为LeNet5。
LeNet-5包含七层,不包括输入,每一层都包含可训练参数(权重),当时使用的输入数据是32*32像素的图像。下面逐层介绍LeNet-5的结构,并且,卷积层将用Cx表示,子采样层则被标记为Sx,完全连接层被标记为Fx,其中x是层索引。
层C1是具有六个5*5的卷积核的卷积层(convolution),特征映射的大小为28*28,这样可以防止输入图像的信息掉出卷积核边界。C1包含156个可训练参数和122304个连接。
层S2是输出6个大小为14*14的特征图的子采样层(subsampling/pooling)。每个特征地图中的每个单元连接到C1中的对应特征地图中的2*2个邻域。S2中单位的四个输入相加,然后乘以可训练系数(权重),然后加到可训练偏差(bias)。结果通过S形函数传递。由于2*2个感受域不重叠,因此S2中的特征图只有C1中的特征图的一半行数和列数。S2层有12个可训练参数和5880个连接。
层C3是具有16个5-5的卷积核的卷积层。前六个C3特征图的输入是S2中的三个特征图的每个连续子集,接下来的六个特征图的输入则来自四个连续子集的输入,接下来的三个特征图的输入来自不连续的四个子集。最后,最后一个特征图的输入来自S2所有特征图。C3层有1516个可训练参数和156 000个连接。
层S4是与S2类似,大小为2*2,输出为16个5*5的特征图。S4层有32个可训练参数和2000个连接。
层C5是具有120个大小为5*5的卷积核的卷积层。每个单元连接到S4的所有16个特征图上的5*5邻域。这里,因为S4的特征图大小也是5*5,所以C5的输出大小是1*1。因此S4和C5之间是完全连接的。C5被标记为卷积层,而不是完全连接的层,是因为如果LeNet-5输入变得更大而其结构保持不变,则其输出大小会大于1*1,即不是完全连接的层了。C5层有48120个可训练连接。
F6层完全连接到C5,输出84张特征图。它有10164个可训练参数。这里84与输出层的设计有关。
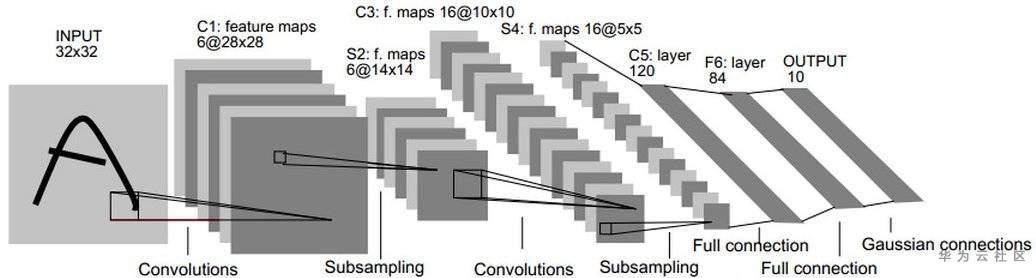
LeNet的设计较为简单,因此其处理复杂数据的能力有限;此外,在近年来的研究中许多学者已经发现全连接层的计算代价过大,而使用全部由卷积层组成的神经网络。
LeNet-5网络训练脚本是mnist_train.py,具体代码:
import os
import numpy as np
import tensorflow as tf
import time
from tensorflow.examples.tutorials.mnist import input_data import mnist_inference from npu_bridge.estimator import npu_ops #导入NPU算子库
from tensorflow.core.protobuf.rewriter_config_pb2 import RewriterConfig #重写tensorFlow里的配置,针对NPU的配置 batch_size =
learning_rate = 0.1
training_step = model_save_path = "./model/"
model_name = "model.ckpt" def train(mnist):
x = tf.placeholder(tf.float32, [batch_size, mnist_inference.image_size, mnist_inference.image_size, mnist_inference.num_channels], name = 'x-input')
y_ = tf.placeholder(tf.float32, [batch_size, mnist_inference.num_labels], name = "y-input") regularizer = tf.contrib.layers.l2_regularizer(0.001)
y = mnist_inference.inference(x, train = True, regularizer = regularizer) #推理过程
global_step = tf.Variable(, trainable=False)
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits = y, labels = tf.argmax(y_, )) #损失函数
cross_entropy_mean = tf.reduce_mean(cross_entropy)
loss = cross_entropy_mean + tf.add_n(tf.get_collection("loss")) train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step = global_step) #优化器调用 saver = tf.train.Saver() #启动训练 #以下代码是NPU所必须的代码,开始配置参数
config = tf.ConfigProto(
allow_soft_placement = True,
log_device_placement = False)
custom_op = config.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = "NpuOptimizer"
custom_op.parameter_map["use_off_line"].b = True
#custom_op.parameter_map["profiling_mode"].b = True
#custom_op.parameter_map["profiling_options"].s = tf.compat.as_bytes("task_trace:training_trace")
config.graph_options.rewrite_options.remapping = RewriterConfig.OFF
#配置参数结束 writer = tf.summary.FileWriter("./log_dir", tf.get_default_graph())
writer.close() #参数初始化
with tf.Session(config = config) as sess:
tf.global_variables_initializer().run() start_time = time.time() for i in range(training_step):
xs, ys = mnist.train.next_batch(batch_size)
reshaped_xs = np.reshape(xs, (batch_size, mnist_inference.image_size, mnist_inference.image_size, mnist_inference.num_channels))
_, loss_value, step = sess.run([train_step, loss, global_step], feed_dict={x:reshaped_xs, y_:ys}) #每训练10个epoch打印损失函数输出日志
if i % == :
print("****************************++++++++++++++++++++++++++++++++*************************************\n" * )
print("After %d training steps, loss on training batch is %g, total time in this 1000 steps is %s." % (step, loss_value, time.time() - start_time))
#saver.save(sess, os.path.join(model_save_path, model_name), global_step = global_step)
print("****************************++++++++++++++++++++++++++++++++*************************************\n" * )
start_time = time.time()
def main():
mnist = input_data.read_data_sets('MNIST_DATA/', one_hot= True)
train(mnist) if __name__ == "__main__":
main()
本文主要讲述了经典卷积神经网络之LeNet-5网络模型和迁移至昇腾D910的实现,希望大家快来动手操作一下试试看!
技术干货丨卷积神经网络之LeNet-5迁移实践案例的更多相关文章
- 经典卷积神经网络(LeNet、AlexNet、VGG、GoogleNet、ResNet)的实现(MXNet版本)
卷积神经网络(Convolutional Neural Network, CNN)是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现. 其中 文章 详解卷 ...
- 卷积神经网络之LeNet
开局一张图,内容全靠编. 上图引用自 [卷积神经网络-进化史]从LeNet到AlexNet. 目前常用的卷积神经网络 深度学习现在是百花齐放,各种网络结构层出不穷,计划梳理下各个常用的卷积神经网络结构 ...
- TensorFlow 实战卷积神经网络之 LeNet
欢迎大家关注我们的网站和系列教程:http://www.tensorflownews.com/,学习更多的机器学习.深度学习的知识! LeNet 项目简介 1994 年深度学习三巨头之一的 Yan L ...
- 技术干货丨如何在VIPKID中构建MQ服务
小结: 1. https://mp.weixin.qq.com/s/FQ-DKvQZSP061kqG_qeRjA 文 |李伟 VIPKID数据中间件架构师 交流微信 | datapipeline201 ...
- 技术干货丨通过wrap malloc定位C/C++的内存泄漏问题
摘要:用C/C++开发的程序执行效率很高,但却经常受到内存泄漏的困扰.本文提供一种通过wrap malloc查找memory leak的思路. 用C/C++开发的程序执行效率很高,但却经常受到内存泄漏 ...
- [DeeplearningAI笔记]卷积神经网络2.9-2.10迁移学习与数据增强
4.2深度卷积网络 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.9迁移学习 迁移学习的基础知识已经介绍过,本篇博文将介绍提高的部分. 提高迁移学习的速度 可以将迁移学习模型冻结的部分看 ...
- 技术应用丨DWS 空间释放(vacuum full) 最佳实践
摘要:本文主要介绍如何进行正常的VACUUM FULL 维护,及时释放磁盘存储. 1.背景 目前根据某项目情况,其DWS的磁盘IO性能低.库内数据量大.对象多.数据膨胀严重.若毫无目的性的进行空间释放 ...
- 五大经典卷积神经网络介绍:LeNet / AlexNet / GoogLeNet / VGGNet/ ResNet
欢迎大家关注我们的网站和系列教程:http://www.tensorflownews.com/,学习更多的机器学习.深度学习的知识! LeNet / AlexNet / GoogLeNet / VGG ...
- Python机器学习笔记:卷积神经网络最终笔记
这已经是我的第四篇博客学习卷积神经网络了.之前的文章分别是: 1,Keras深度学习之卷积神经网络(CNN),这是开始学习Keras,了解到CNN,其实不懂的还是有点多,当然第一次笔记主要是给自己心中 ...
随机推荐
- DNS域传输漏洞利用总结
操作基本的步骤是: 1) 输入nslookup命令进入交互式shell 2) Server 命令参数设定查询将要使用的DNS服务器 3) Ls命令列出某个域中的所有域名 4) Exit命令退出程序 攻 ...
- Rocket - debug - TLDebugModuleInner - HALTSUM
https://mp.weixin.qq.com/s/elOGjaVCWc48gs9c_cTqww 简单介绍TLDebugModuleInner中HALTSUM寄存器的实现. 1. numHalted ...
- PowerPC-Link Command File解析
https://mp.weixin.qq.com/s/CATWma2mv5IPYGtKZLuGDA 以Code Warrior 11生成的flash版本(FLASH.lcf)为例 一. 参考资 ...
- SpringMVC(一)概述、解析器与注解
个人博客网:https://wushaopei.github.io/ (你想要这里多有) 一.SpringMVC的概述 1.概述 Spring MVC框架是一个开源的Java平台,为开发强大的基 ...
- Java实现 蓝桥杯VIP 算法训练 接水问题
题目描述 有n个人在一个水龙头前排队接水,假如每个人接水的时间为Ti,请编程找出这n个人排队的一种顺序,使得n个人的平均等待时间最小. 输入输出格式 输入格式: 输入文件共两行,第一行为n:第二行分别 ...
- java实现串逐位和(C++)
给定一个由数字组成的字符串,我们希望得到它的各个数位的和. 比如:"368" 的诸位和是:17 这本来很容易,但为了充分发挥计算机多核的优势,小明设计了如下的方案: int f(c ...
- java实现第七届蓝桥杯反幻方
反幻方 题目描述 我国古籍很早就记载着 2 9 4 7 5 3 6 1 8 这是一个三阶幻方.每行每列以及对角线上的数字相加都相等. 下面考虑一个相反的问题. 可不可以用 1~9 的数字填入九宫格. ...
- java实现第八届蓝桥杯数位和
数位和 题目描述 数学家高斯很小的时候就天分过人.一次老师指定的算数题目是:1+2+-+100. 高斯立即做出答案:5050! 这次你的任务是类似的.但并非是把一个个的数字加起来,而是对该数字的每一个 ...
- JS变量小总
变量分类:1.栈内存(stack)和堆内存(heap)2.基本类型和引用类型 #栈内存(stack) 一般为静态分配内存,其分配的内存系统自动释放. #堆内存(heap) 一般为动态分配内存,其分配的 ...
- 如何监控 Linux 服务器状态?
Linux 服务器我们天天打交道,特别是 Linux 工程师更是如此.为了保证服务器的安全与性能,我们经常需要监控服务器的一些状态,以保证工作能顺利开展. 本文介绍的几个命令,不仅仅适用于服务器监控, ...