Hadoop(九):Shuffle组件
重温MR整体流程
工作流程
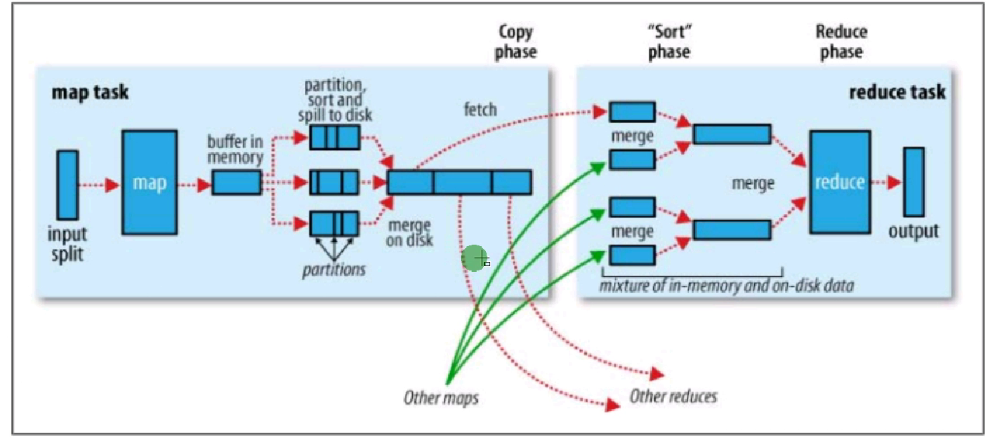
开始执行输入(InputFormat),先对文件进行分片,然后读取数据输入到Map中。
Mapper读取输入内容,解析成键值对,1行内容解析成1个键值对,每个键值对调用一次map方法。
每个键值对执行map重写的方法,把输入的键值对转换成新的键值对。
多个Mapper的输出,按照不同的分区,通过网络复制到不同的Reducer节点。
Map shuffle阶段。
Reduce shuffle阶段
对多个Mapper的输出进行合并、排序,执行重写的reduce方法,再次输出新的键值对。
把最后的结果保存到文件中。
定义
Shuffle阶段就是指Map输出到Reduce输入的过程,可以区分为Map shuffle阶段和Reduce shuffle阶段。
shuffle机制的主要功能作用是将数据进行排序、分组、分区。
由于shuffle是reduce task节点通过http拉取map task的执行结果,这个过程就会有网络开销和磁盘IO开销,因此我们要降低网络开销、减少磁盘IO对其他task的影响、获取完整的结果数据。
Map shuffle阶段
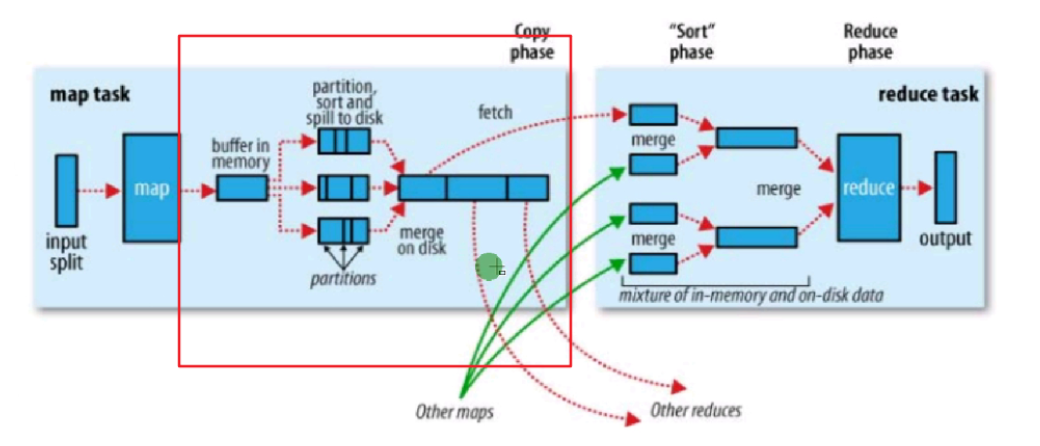
Map shuffle主要功能是将map方法输出的<key,value>键值对最终输出到map task节点的本地文件系统(而不是HFDS文件系统)的一个文件(而不是多个文件!)中,让reduce task获取。
主要步骤:
write to memory buffer(写出到内存缓存)
write to disk file(写出到磁盘文件)
combin(组合器,可控制))
partition(分区,可控制)
sort(排序,可控制))
write to disk file(写出到磁盘文件)
merge disk file(合并磁盘文件)
1.write to memory buffer(写出到内存缓存)
第一步就是将数据添加到memory buffer中,该memory buffer是一个环形的内存缓存区,当写入容量达到80%(默认)的时候,会触发溢出操作
触发溢出操作的时候会将已经写入的缓存区(80%)锁住,同时map task允许往剩下的缓存区中写入数据。也就是说当触发溢出操作的时候,不会阻塞map task的继续写出操作
Map端内存中有个环形的内存缓存结构体,该结构体的内存大小由参数mapreduce.task.io.sort.mb控制,默认大小为100MB。
其中控制阀值的是参数mapreduce.map.sort.spill.percent,默认值0.8
2. write to disk file(写出到磁盘文件)
在触发溢出操作的时候,会同时触发<key,value>键值对的combiner、partitioner以及sort三种操作(MapOutputBuffer类)。
操作后会在磁盘中生成(Spill)一个磁盘文件(每次溢出就会有一个文件,文件是进行合并后的,排序好的,按照reduce分区好的数据文件)。
当执行完Spill操作后,磁盘中会多一个数据文件,同时会将环形内存缓存写出数据部分进行清空操作,允许map task往这部分填写数据。
可能会触发多次combiner操作。
reduce分区:1个reduce任务就要做一个reduce分区。
3.merge disk file(合并磁盘文件)
当map task执行完成后,会执行溢出文件归并操作,通过combiner、partitioner以及sort操作,最终将多个溢出文件以及内存中没有溢出的数据写出到一个本地磁盘文件中。
同时保存一个reducer节点到文件内容的偏移量的一个索引文件。比如reduce1取1-10,2取11-20...
只所以不采用一个reducer对应一个文件的方式,是因为如果一个大的集群有很多个reducer task节点,那么最终每个map task执行完成后,都会产生多个本地文件,不好维护。
当map task节点完成数据写出操作后(最终产生一个磁盘文件后),map task正式完成,同时通知ApplicationMaster服务,完成map task。
并告诉application master服务,最终数据保存文件地址信息。
当完成的map task数量达到百分之五的时候,会启动reducer task任务。控制参数为mapreduce.job.reduce.slowstart.completedmaps,默认值0.05。
Reduce shuffle阶段
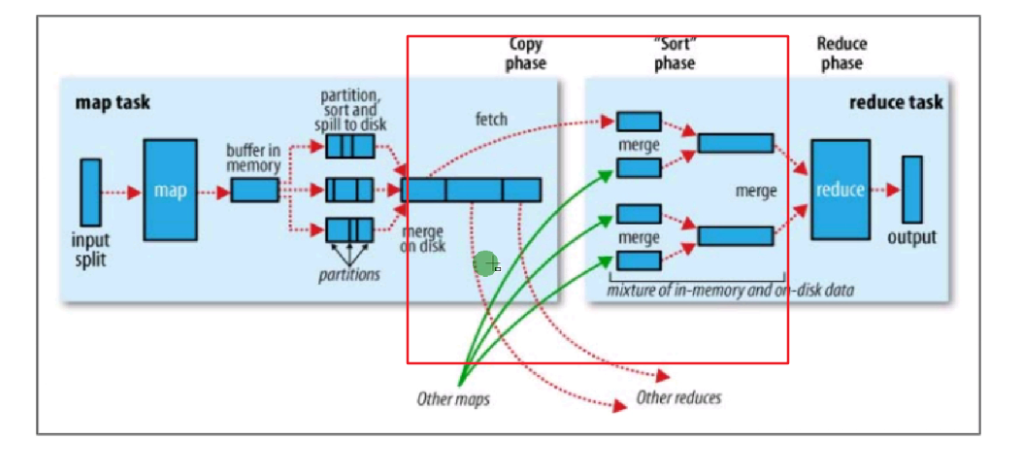
Reduce端的shuffle主要功能是将该reduce task节点需要处理的所有map端输出数据拉取过来,然后通过排序和合并操作,形成输入到reduce方法的<key,Iterator<value>>的键值对形式的数据。
Reduce端的shuffle操作指定类和Mapper不同,Mapper不能自定义,但是Reduce可以由参数指定:
默认为Shuffle.class类。可以通过参数mapreduce.job.reduce.shuffle.consumer.plugin.class指定
主要步骤:
copy
spill & merge & sort
group(分组,可控制)
1.copy
根据已经完成的map信息生成Fetcher线程组。
启动好Fetcher线程后,就开始从远程map task节点通过HttpURLConnection获取流来读取数据,并将数据先写到内存中。
内存不够(75%)的时候再溢出到磁盘中,内存大小是reduce task当前堆大小。
Fetcher线程组的数量由参数mapreduce.reduce.shuffle.parallelcopies控制,默认为5个。
内存大小不受用户参数控制,只所以选择使用当前堆大小作为内存大小,是因为此时reduce task不会进行任何任何其他操作(而Map还要计算),不需要额外的内存空间。
2. spill & merge & sort
和map端的溢出类似,reduce端在进行copy的时候由于内存不够,会进行溢出操作,在这个过程中会触发sort和merge操作,最终会产生一个磁盘文件(可能存在于内存中)。
reduce端的merge操作有三种方式:
内存到内存
内存到磁盘
磁盘到磁盘
默认情况下第一种方式是没有开启的,当内存容量不够的时候,会启动第二种方式,然后一直处于运行状态,直到map端数据全部拉取完成,最后会启动第三种方式进行归并操作。
3.group
group就是Reduce阶段输入的value是迭代器的原因,就是在这里实现的。
当reduce进行完merge操作后,会有一个数据文件存放到本地磁盘系统中或者内存中,为下一步reduce方法的执行提供数据。
每次获取数据的时候,会判断下一个key是否和当前key一样,通过group comparable来进行比较
如果一致,认为属于同一组key,那么在同一组中进行处理
否则直接结束当前组的处理,新起一个组来进行reduce方法的调用。
Shuffle 可控制的插件
Partition:用来完成Map节点数据的中间结果向Reduce节点的分区处理,也就是当Reduce节点为多个的时候(>1),决定数据是输出到那个节点。
Combine:用来减少Map过程输出的中间结果键值对的数量,降低网络开销。
Sorting:主要用来根据key来进行排序,并将结果按照sorting定义的顺序写出到磁盘文件或内存中。
Grouping:主要用来在Reduce节点处理数据的时候,将"相同"的key认为是同一组数据,一起进行处理操作
Partition
默认为HashPartitioner类,根据key的hashcode值进行分区操作。
自定义Partitioner要求:
实现org.apache.hadoop.mapreduce.Partitioner类
实现方法getPartition,返回当前key/value所属的分区号,分区号从0开始。
通过调用job.setPartitionerClass(CustomPartitioner.class)方法来进行设置。
示例
自定义类key数据类型,含用户id和访问时间time,根据id属性决定分区的Partitioner。
package com.rzp.pojo;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
//作为key,要实现WritableComparable
public class CustomerValue implements WritableComparable<CustomerValue> {
private String id;
private long time;
public int compareTo(CustomerValue o) {
int tmp = this.id.compareTo(o.id);
if (tmp!=0){return tmp;}
tmp = Long.compare(this.time,o.time);
return tmp;
}
public void write(DataOutput out) throws IOException {
out.writeUTF(this.id);
out.writeLong(this.time);
}
public void readFields(DataInput in) throws IOException {
this.id = in.readUTF();
this.time = in.readLong();
}
//省略后续get/set/构造器
重写Partitioner
使用一个简单的做法,就是调用Hadoop自带的HashPartitioner方法来实现按照ID分区
package com.rzp.pojo;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
//自定义分区类
public class CustomerPartitioner extends Partitioner<CustomerValue,Object> {
private Partitioner<String,Object> proxy = new HashPartitioner<String,Object> (); //numPartitions一般Hadoop会直接输入ReducerTask的数量
@Override
public int getPartition(CustomerValue key, Object o, int numPartitions) {
return this.proxy.getPartition(key.getId(),o,numPartitions);
}
}
这是HashPatitioner的方法
HashPatitioner其实是根据key值的HashCode进行分区
因为String类型相同的字符串的HashCode相同的特性,我们输入id值作为String传入即可。
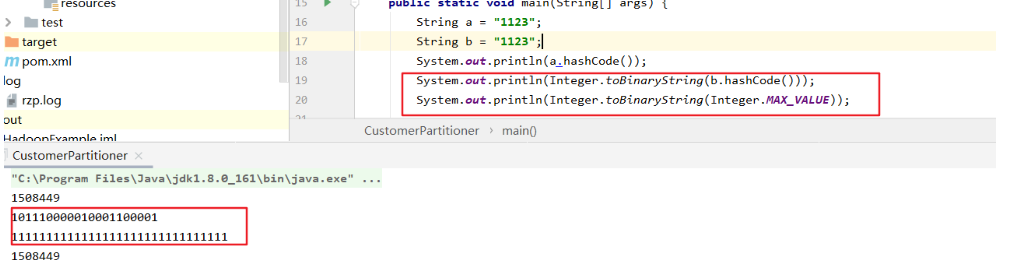
/** Use {@link Object#hashCode()} to partition. */
public int getPartition(K key, V value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
方法中的&是位运算符,其实就是返回了key.hashCode
Combiner
默认为空,不进行任何合并操作。
Combiner其实就是在MapShuffle阶段,先进行部分数据的合并,减少要传输的数据,从而降低带宽的压力。
Combiner适合Map输出中的value是可以进行合并操作的场景,要求combiner的输入和输出的key/value键值对是一样的(combiner的输入是map的输出)。
自定义Combiner要求:
实现org.apache.hadoop.mapreduce.Reducer类
实现方法reduce。
通过调用job.setCombinerClass(CustomCombiner.class)方法来进行设置。
Combiner是由MR框架根据内存容量大小进行控制决定是否执行,而且执行次数不定,所以在编写Combiner的时候有一个要求:不管执行多少次Combiner操作,不影响最终运算结果(mr输出结果)。
示例
给计算WordCount的MR作业添加Combiner,然后查看Combiner是否执行。
package com.rzp.utils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.log4j.Logger;
import java.io.IOException;
//输入输出的键值对一摸一样
public class WordCountCombiner extends Reducer<Text, LongWritable,Text, LongWritable> {
private static final Logger logger = Logger.getLogger(WordCountCombiner.class);
private LongWritable count = new LongWritable();
@Override
protected void setup(Context context) throws IOException, InterruptedException {
super.setup(context);
logger.debug("调用combiner");
}
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
logger.debug("执行combiner"+key); //先进行一部分的合并累加操作
int sum = 0;
for (LongWritable value :values){
sum += value.get();
}
this.count.set(sum);
context.write(key,this.count);
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
super.cleanup(context);
logger.debug("完成combiner的调用");
}
}
Runner
在outputvalue后面增加
//设置combainer
job.setCombinerClass(WordCountCombiner.class);
Sorting & Grouping
Sorting 默认采用key的compareTo方法来进行排序定义,一般我们的做法也是重写compareTo的方法进行实现,而不是重写Hadoop的接口。
Grouping 默认采用Sorting采用的排序定义方法来进行分组操作。
自定义要求:
实现org.apache.hadoop.io.RawComparator接口,但是由于内部方法比较难实现,一般都是实现org.apache.hadoop.io.WritableComparator,并实现hashCode和equals方法。
通过调用job.setGroupingComparatorClass(CustomGrouping.class)设置。
备注
如果实现org.apache.hadoop.io.RawComparator接口,就要实现这个方法,按数组比较,就不是很好实现。
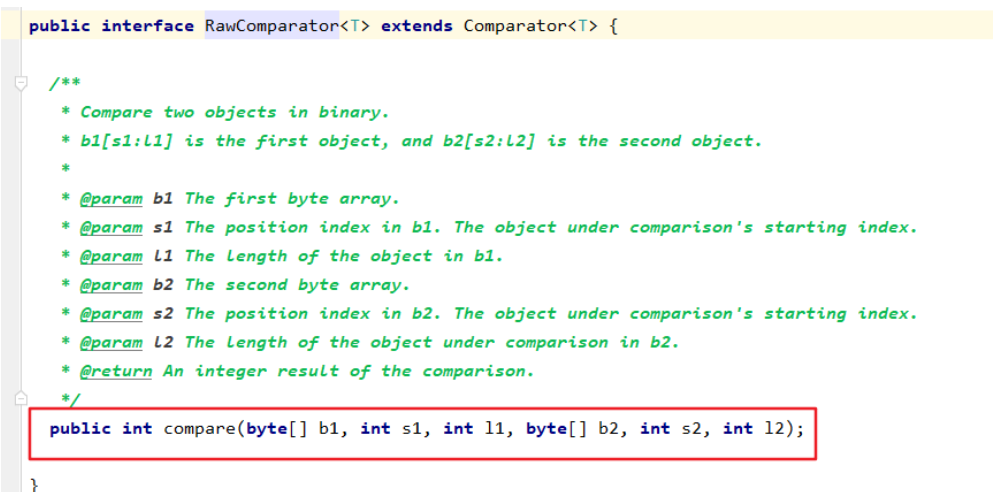
而org.apache.hadoop.io.WritableComparator本身就实现了这个方法,所以我们一般实现这个。
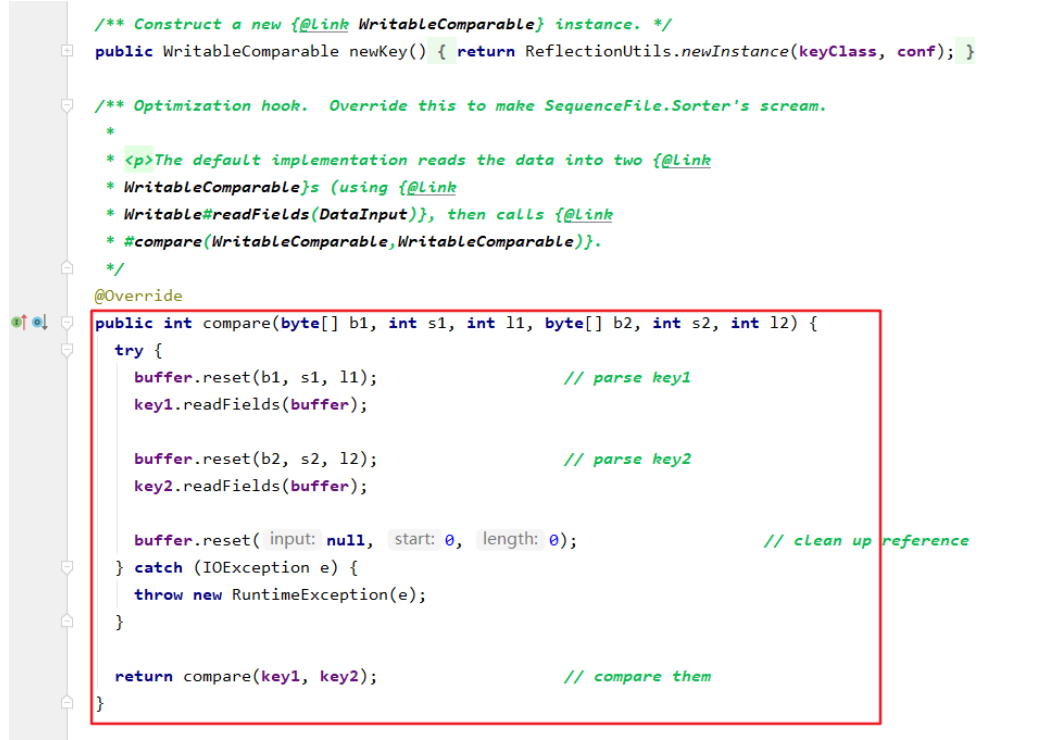
示例
自定义类key数据类型,含用户id和访问时间time,根据id属性决定分组Grouping。
package com.rzp.pojo;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class CustomGrouping extends WritableComparator {
public CustomGrouping(){
//调用父类构造器,对父类要使用的key值赋值
//第一个参数是该grouping进行分组对应的key类
//第二个参数写true,表示直接创建对象
super(CustomerValue.class,true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
CustomerValue cv1 = (CustomerValue)a;
CustomerValue cv2 = (CustomerValue)b;
return cv1.getId().compareTo(cv2.getId());
}
}
二次排序
MR框架默认情况下只会map的输出key进行排序,从小到大排序,而没有对value进行排序操作,但是有些情况下,我们的最终结果需要按照value中的某些字段进行排序输出。这个时候,默认的MR执行流程就无法帮助我们完成任务。
此时就需要我们自定义分区、排序、分组等组件,使用二次排序,将value中需要进行排序的字段作为一个key中的一些属性进行排序,但是在分区分组的时候又要求不考虑这些额外的属性。
即:二次排序就是指不仅仅对key进行排序,而且对value也进行排序操作。实现方式就是排序使用key+value的方式,但是分区和分组只考虑key的方式进行。
案例:
我们需要把输入的文件,按照uid分组,按uid排序,每个uid后面显示url,按t1排序。

思路
按照uid和t1进行排序我们只需要把uid和t1作为Mapper OutputKey,重写compare方法就可以了。
要分组显示我们要使用grouping。
但是如果有多个Reducer Task任务,就可能会造成同一组去了不同的Task,导致结果不符合要求。
因此我们还要加上Patitioner。
实现:
如果我们只对key值排序:
Mapper OutputValue
package com.rzp.sorttwice;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
//
public class SortOutputKey implements WritableComparable<SortOutputKey> {
private String uid;
private String time;
public int compareTo(SortOutputKey o) {
//主要用于排序,先把需要group的字段排序,然后再进行其他字段排序
//拿this比较o,那么得到结果是从小到大
int tmp = this.uid.compareTo(o.uid);
if (tmp!=0){
return tmp;
}
//tmp = this.time.compareTo(o.time); //time从小到大
tmp = o.time.compareTo(this.time);
return tmp;
}
public void write(DataOutput out) throws IOException {
out.writeUTF(this.uid);
out.writeUTF(this.time);
}
public void readFields(DataInput in) throws IOException {
this.uid = in.readUTF();
this.time = in.readUTF();
}
public String getUid() {
return uid;
}
public void setUid(String uid) {
this.uid = uid;
}
public String getTime() {
return time;
}
public void setTime(String time) {
this.time = time;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
SortOutputKey that = (SortOutputKey) o;
if (uid != null ? !uid.equals(that.uid) : that.uid != null) return false;
return time != null ? time.equals(that.time) : that.time == null;
}
@Override
public int hashCode() {
int result = uid != null ? uid.hashCode() : 0;
result = 31 * result + (time != null ? time.hashCode() : 0);
return result;
}
@Override
public String toString() {
return "SortOutputKey{" +
"uid='" + uid + '\'' +
", time='" + time + '\'' +
'}';
}
}
Mapper
package com.rzp.sorttwice;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class SortMapper extends Mapper<Object, Text,SortOutputKey,Text> {
private SortOutputKey outputKey = new SortOutputKey();
private Text outPutValue = new Text();
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] splits = line.split(",");
if (splits!=null&&splits.length==3){
String uid = splits[0];
String time = splits[1];
String url = splits[2];
if (uid!=null&&time!=null && url!=null){
this.outputKey.setUid(uid);
this.outputKey.setTime(time);
this.outPutValue.set(url);
context.write(this.outputKey,this.outPutValue);
}
}
}
}
Reducer
package com.rzp.sorttwice;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
//在二次排序的实现中,进入reduce方法的key/value键值对是随时更新的,会将同一组key一起进行处理
public class SortReducer extends Reducer<SortOutputKey, Text,Text,Text> {
private Text outputKey = new Text();
private Text outputvalue = new Text();
private int i = 0;
@Override
protected void reduce(SortOutputKey key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
StringBuffer sb = new StringBuffer();
for (Text value : values) {
System.out.println(i+":"+key);
sb.append(value.toString()).append(",");
}
this.outputKey.set(key.getUid());
this.outputvalue.set(sb.substring(0,sb.length()-1));
i++;
context.write(outputKey,outputvalue);
}
}
Runner
package com.rzp.sorttwice;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class SortRunner implements Tool {
private Configuration conf = null;
public int run(String[] args) throws Exception {
Configuration conf = this.getConf();
Job job = Job.getInstance(conf,"sorting");
job.setJarByClass(SortRunner.class);
job.setMapperClass(SortMapper.class);
job.setMapOutputKeyClass(SortOutputKey.class);
job.setMapOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job,new Path("D:\\Hoptest\\sort\\in\\data.txt"));
job.setReducerClass(SortReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileOutputFormat.setOutputPath(job,new Path("D:\\Hoptest\\sort\\out"));
return job.waitForCompletion(true)?0:-1;
}
public void setConf(Configuration conf) {
conf.set("mapreduce.framework.name","local");
this.conf=conf;
}
public Configuration getConf() {
return this.conf;
}
public static void main(String[] args) throws Exception {
ToolRunner.run(new SortRunner(),args);
}
}
这是我们使用第一次接触排序的知识,对key值重写compare方法进行排序,得到结果是
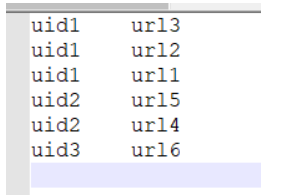
查看输出,可以看出其实排序已经好了,先按uid排序,再按time排序

如果我们加上group的重写
package com.rzp.sorttwice;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class SortGrouping extends WritableComparator {
public SortGrouping(){
super(SortOutputKey.class,true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
SortOutputKey k1 = (SortOutputKey) a;
SortOutputKey k2 = (SortOutputKey) b;
return k1.getUid().compareTo(k2.getUid());
}
}
设置grouping.classi
//grouping
job.setGroupingComparatorClass(SortGrouping.class);
再次输出

似乎可以了,但是如果我们把Reduce的任务设置为2
job.setNumReduceTasks(2);
再次输出,可以看到同一个uid的分去了不同Reducer Task里面去了,还是没达到分组的效果(前面的数字是分组的组号)

因此我们还要重写分区的逻辑
partitioner
package com.rzp.sorttwice;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
public class SortPartitioner extends Partitioner<SortOutputKey,Object> {
private Partitioner<Object,Object> proxy = new HashPartitioner<Object, Object>();
@Override
public int getPartition(SortOutputKey key, Object value, int numPartitions) {
return this.proxy.getPartition(key.getUid(),value,numPartitions);
}
}
Runner
//一般在二次排序中,分区和分组的字段要一样
//partitioner
job.setPartitionerClass(SortPartitioner.class);
//grouping
job.setGroupingComparatorClass(SortGrouping.class);
输出结果:
这样才能完成需求

Hadoop(九):Shuffle组件的更多相关文章
- Bootstrap入门(十九)组件13:页头与缩略图
Bootstrap入门(十九)组件13:页头与缩略 1.页头 2.默认的缩略图 3.自定义缩略图 页头组件能够为 h1 标签增加适当的空间,并且与页面的其他部分形成一定的分隔.它支持 h1 标签内内嵌 ...
- Bootstrap入门(九)组件3:按钮组
Bootstrap入门(九)组件3:按钮组 先引入本地的CSS文件和JS文件(注:1.bootstrap是需要jQuery支持的.2.需要在<body>当中添加) <link h ...
- 【串线篇】SpringMVC九大组件
SpringMVC中的Servlet一共有三个层次,分别是HttpServletBean.FrameworkServlet和 DispatcherServlet. HttpServletBean直接继 ...
- Spring核心原理分析之MVC九大组件(1)
本文节选自<Spring 5核心原理> 1 什么是Spring MVC Spring MVC 是 Spring 提供的一个基于 MVC 设计模式的轻量级 Web 开发框架,本质上相当于 S ...
- 【Hadoop】ZooKeeper组件
目录 一.配置时间同步 二.部署zookeeper(master节点) 1.使用xftp上传软件包至~ 2.解压安装包 3.创建 data 和 logs 文件夹 4.写入该节点的标识编号 5.修改配置 ...
- hadoop伪分布式组件安装
一.版本建议 Centos V7.5 Java V1.8 Hadoop V2.7.6 Hive V2.3.3 Mysql V5.7 Spark V2.3 Scala V2.12.6 Flume V1. ...
- Hadoop :map+shuffle+reduce和YARN笔记分享
今天做了一个hadoop分享,总结下来,包括mapreduce,及shuffle深度讲解,还有YARN框架的详细说明等. v\:* {behavior:url(#default#VML);} o\:* ...
- Hadoop及其相关组件简介
一.大数据介绍 1.大数据指的是所涉及的数据量规模巨大到无法通过人工,在合理时间内达到截取.管理.处理.并整理成为人类所能解读的形式的信息. 2.大数据,可帮助我们能察觉商业趋势.判断研究质量.避免疾 ...
- 零碎记录Hadoop平台各组件使用
>20161011 :数据导入研究 0.sqoop报warning,需要安装accumulo: 1.下载Microsoft sql server jdbc, 使用ie下载,将42版j ...
随机推荐
- Simulink仿真入门到精通(十二) Publish发布M文件
12.1 M文件的注释 使用%进行注释. 连续多行注释Ctrl+R,取消注释Ctrl+T. 12.2 Cell模式 在MATLAB脚本文件中使用连续两个注释符,开启一个新的Cell块,%%后空一格追加 ...
- 【猫狗数据集】使用top1和top5准确率衡量模型
数据集下载地址: 链接:https://pan.baidu.com/s/1l1AnBgkAAEhh0vI5_loWKw提取码:2xq4 创建数据集:https://www.cnblogs.com/xi ...
- 如何安装vue-devtool调试工具
1.从git上下载工具压缩包,github下载地址:https://github.com/vuejs/vue-devtools: 2.打开cmd,切换到下载的文件目录下:npm install---- ...
- macOS Catalina 升级软件问题
最近升级macOS Catalina系统,升级失败时多尝试几次就可以执行成功了,在使用过程中发现以下问题,大家谨慎升级!!! 存在软件启动不兼容,不存在已软件激活失效问题. 有道词典不兼容,启动异常 ...
- go例子(一) 使用go语言实现linux内核中的list_head
package list 代码 package list import ( "fmt" ) // 数据接口 type ElemType interface{} // 节点 type ...
- 群辉DS418play体验+经验分享
群辉DS418play体验+经验分享 群辉DS418play体验+经验分享 购买初衷 近期百度网盘到期,我又需要重复下载很多资源(游戏.电影.毛片),下载没速度&下完没空间怎么办? ...
- vuepress-theme-reco + Github Actions 构建静态博客,部署到第三方服务器
最新博客链接 Github链接 查看此文档前应先了解,vuepress基本操作 参考官方文档进行配置: vuepress-theme-reco VuePress SamKirkland / FTP-D ...
- 3D游戏中各种空间变换到底是怎么回事
每一个游戏可以呈现炫丽效果的背后,需要进行一系列的复杂计算,同时也伴随着各种各样的顶点空间变换.渲染游戏的过程可以理解成是把一个个顶点经过层层处理最终转化到屏幕上的过程,本文就旨在说明,顶点是经过了哪 ...
- Elasticsearch 之聚合分析入门
本文主要介绍 Elasticsearch 的聚合功能,介绍什么是 Bucket 和 Metric 聚合,以及如何实现嵌套的聚合. 首先来看下聚合(Aggregation): 什么是 Aggregati ...
- 免注册公众号的三种微信推送消息服务的C#代码实现
有时候我们需要监控一些网络上的变化,但是每次去刷新网页却又很麻烦,而且大部分刷新的时候网页并没有更新.那么有没有一个工具,可以监控网页变化,并将变化的结果推送到手机微信上呢? 这里有很多应用场景,比如 ...