Python爬取51job实例
用Python爬取51job里面python相关职业、工作地址和薪资。
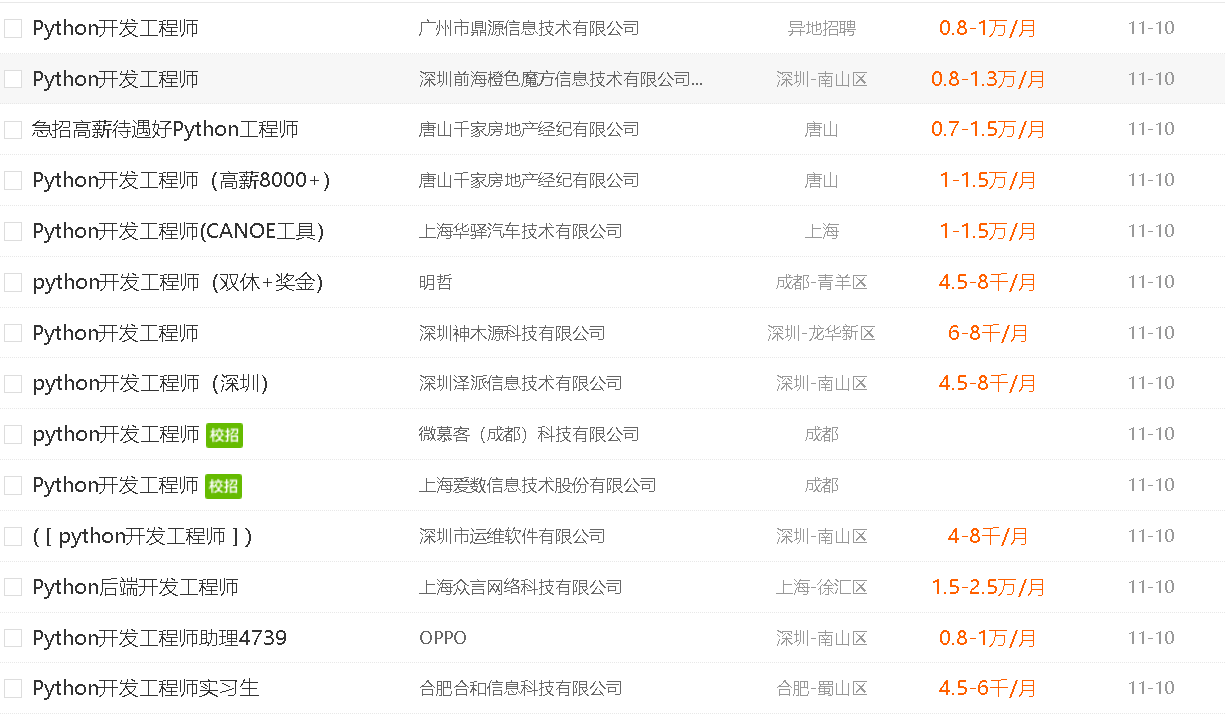
51job上的信息
程序代码
from bs4 import BeautifulSoup
from urllib.request import urlopen
header ={ "Connection": "keep-alive", "Upgrade-Insecure-Requests": "", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36", "Accept":" text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8", "Accept-Encoding": "gzip,deflate", "Accept-Language": "zh-CN,zh;q=0.8"}; html = urlopen("https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=").read().decode('GBK')
soup = BeautifulSoup(html,"html.parser")
titles=soup.select("p[class='t1'] a")#挑选所需信息所在的标签
salaries=soup.select("span[class='t4']")
di=soup.select("span[class='t3']") for i in range(len(titles)):
print("{:30}{:10}{}".format(titles[i].get('title'),di[i+1].get_text(),salaries[i+1].get_text()))
运行结果

Python爬取51job实例的更多相关文章
- Python的scrapy之爬取51job网站的职位
今天老师讲解了Python中的爬虫框架--scrapy,然后带领我们做了一个小爬虫--爬取51job网的职位信息,并且保存到数据库中 用的是Python3.6 pycharm编辑器 爬虫主体: im ...
- 萌新学习Python爬取B站弹幕+R语言分词demo说明
代码地址如下:http://www.demodashi.com/demo/11578.html 一.写在前面 之前在简书首页看到了Python爬虫的介绍,于是就想着爬取B站弹幕并绘制词云,因此有了这样 ...
- python爬取网站数据保存使用的方法
这篇文章主要介绍了使用Python从网上爬取特定属性数据保存的方法,其中解决了编码问题和如何使用正则匹配数据的方法,详情看下文 编码问题因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这 ...
- python 爬取王者荣耀高清壁纸
代码地址如下:http://www.demodashi.com/demo/13104.html 一.前言 打过王者的童鞋一般都会喜欢里边设计出来的英雄吧,特别想把王者荣耀的英雄的高清图片当成电脑桌面 ...
- 用Python爬取网易云音乐热评
用Python爬取网易云音乐热评 本文旨在记录Python爬虫实例:网易云热评下载 由于是从零开始,本文内容借鉴于各种网络资源,如有侵权请告知作者. 要看懂本文,需要具备一点点网络相关知识.不过没有关 ...
- Python 爬取所有51VOA网站的Learn a words文本及mp3音频
Python 爬取所有51VOA网站的Learn a words文本及mp3音频 #!/usr/bin/env python # -*- coding: utf-8 -*- #Python 爬取所有5 ...
- python爬取网站数据
开学前接了一个任务,内容是从网上爬取特定属性的数据.正好之前学了python,练练手. 编码问题 因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这个机会算是彻底搞清楚了. 问题要从文字的编码讲 ...
- python爬取某个网页的图片-如百度贴吧
python爬取某个网页的图片-如百度贴吧 作者:vpoet mail:vpoet_sir@163.com 注:随意copy,不用告诉我 #coding:utf-8 import urllib imp ...
- Python:爬取乌云厂商列表,使用BeautifulSoup解析
在SSS论坛看到有人写的Python爬取乌云厂商,想练一下手,就照着重新写了一遍 原帖:http://bbs.sssie.com/thread-965-1-1.html #coding:utf- im ...
随机推荐
- iOS开发之使用 infer静态代码扫描工具
infer是Facebook 的 Infer 是一个静态分析工具.可以分析 Objective-C, Java 或者 C 代码,报告潜在的问题. 任何人都可以使用 infer 检测应用,可以将严重的 ...
- 【Python】使用socketserver建立一个异步TCP服务器
概述 这篇文章是讲解如何使用socketserver建立一个异步TCP服务器,其中Python版本为3.5.1. socketserver主要的类 socketserver模块中的类主要有以下几个:1 ...
- 基于Aspectj表达式配置的Spring AOP
AOP(Aspect-Oriented Programming, 面向切面编程):是一种新的方法论, 是对传统OOP(Object-Oriented Programming, 面向对象编程)的补充. ...
- Python学习之面向对象进阶
面向对象进阶当然是要谈谈面向对象的三大特性:封装.继承.多态 @property装饰器 python虽然不建议把属性和方法都设为私有的,但是完全暴露给外界也不好,这样,我们给属性赋值的有效性九无法保证 ...
- [HTTP]HTTP/1.1 协议Expect: 100-continue
在追踪请求时发现了这么一个http头 基础知识背景:1)“Expect: 100-continue”的来龙去脉: HTTP/1.1 协议里设计 100 (Continue) HTTP 状态码的的目的是 ...
- web开发中的一些不常见的概念
1.惊群 [活跃]星际争霸小王子 就是当你在车站时,一堆拉客的人一拥而上,想你坐他的车,于是就惊群了.但你只能坐一个车,所以没拉到你的就悻悻而归,于是return false[活跃]星际争霸小王 2 ...
- 微信支付开发h5调用
这两天做微信支付开发.碰到大坑.纠结死我了.好不容做完. 后台java:直接上代码:注意区分前后端的变量大小写... @RequestMapping(value = "/index" ...
- win10中,vscode安装go插件排雷指南
最近学习go,想着使用强大的vscode编写go,在安装go插件过程中,遇到了很多问题.下面记录解决方案. 1)win10环境,安装go,vscode,git 配置GOPATH环境变量,在我的电脑-& ...
- 最长递增子序列-Hdu 1257
最少拦截系统 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total Subm ...
- Steam 游戏 《Sudoku Universe(数独宇宙)》——[数独基本局分析]
日期:2020.02.12 博客期:152 星期三 老师给的任务都做完了,15篇博客也都写好了,剩下的几天居然还要每天写一篇~唉~为难我 PH ,剩下的几天就把 我的数独要义分享一下吧! 1.基本局规 ...