cuda基础
一:cuda编程模型
1:主机与设备
主机---CPU 设备/处理器---GPU
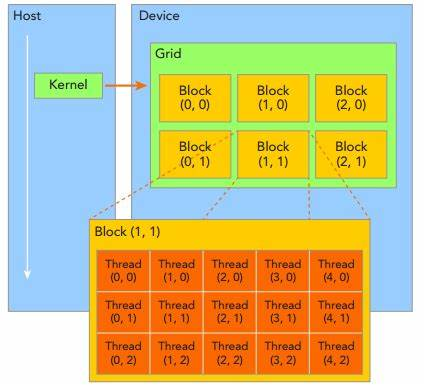
CUDA编程模型如下:
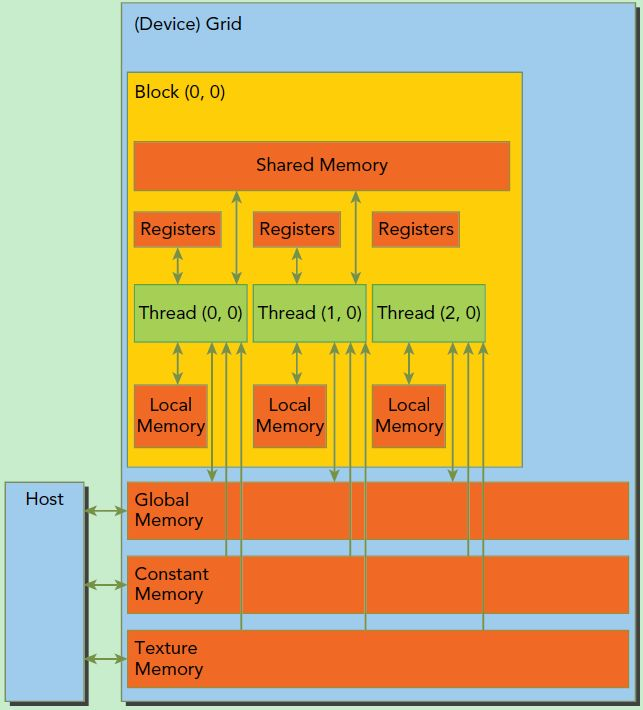
GPU多层存储空间结构如图:
2:Kernel函数的定义与调用
A:运行在GPU上,必须通过__global__函数类型限定符定义且只能在主机端代码中调用;
B:在调用时必须声明内核函数的执行参数----<<<>>>。
C:先为内核函数中用到的变量分配好足够空间再调用kernel函数
D:每个线程都有自己对应的id----由设备端的寄存器提供的内建变量保存,且是只读的。
3:线程结构
1)线程标识
dim3类型(基于uint3定义的矢量类型----由三个unsigned int组成的结构体)的内建变量threadIdx和blockIdx。
2)一维block
线程threadID----threadIdx.x.
3)二维block---(Dx,Dy)
线程threadID----threadIdx.x+threadIdx.y*Dx;
4)三维block---(Dx,Dy,Dz)
线程threadID----threadIdx.x+threadIdx.y*Dx+threadIdx.z*Dx*Dy;
4:硬件映射
1)计算单元
SM---流多处理器 SP---流处理器
A:一个SM包含8个SP,共用一块共享存储器
2)warp
线程束在采用Tesla架构的gpu中:一个线程束由32个线程组成,且其线程只和threadID有关
A:warp才是真正的执行单位
3)执行模型
SIMT---单指令多线程 SIMD---单指令多数据
4)deviceQuery实例
#include <stalib.h>
#include <stdio.h>
#include<string.h>
#include <cutil.h> int main()
{
int deviceCount;
CUDA_SAFE_CALL(cudaGetDeviceCount(&deviceCount));
if( == deviceCount)
{
printf("no deice\n");
}
int dev;
for(dev = ;dev <deviceCount;dev++)
{
cudaDeviceProp deviceProp;
CUDA_SAFE_CALL(cudaGetDeviceProperties(&deviceProp,dev));
print();
}
}
5)cuda程序编写流程
A:主机端
启动CUDA,使用多卡时需加上设备号,或使用cudaSetDevice()设置
为输入数据分配空间
初始化输入数据
为GPU分配显存,用于存放输入数据
将内存中的输入数据拷贝到显存
为GPU分配显存,用于存放输出数据
调用device端的kernel进行计算,将结果写到显存中对应区域
为CPU分配内存,用于存放GPU传回来的输出数据
使用CPU对数据进行其他处理
释放内存和显存空间
退出CUDA
B:设备端
从显存读数据到GPU片内 对数据进行处理 将处理后的数据写回显存
(1)在显存全局内存分配线性空间--cudaMalloc()/cudaFree()
(2)拷贝存储器中的数据 --cudaMemcpy()
拷贝操作类型:cudaMemcpyDeiceToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToDevice
(3)网格定义
<<<Dg,Db,Ns,S>>>
Dg----grid纬度与尺寸 Db---block维度与尺寸 Ns--可分配动态共享内存大小 s--stream_t类型的可选参数
(4)设备端内建变量
gridDim blockIdx blockDim threadIdx warpSize
6)内核实例
A:与shared memory有关
__global__ void
testKernel(float* g_idata,float* g_odata)
{
//分配共享内存 将全局内存的数据写入共享内存 进行计算,将结果写入共享内存 将结果写回全局内存
extern __shared__ float sdata[];//动态分配共享内存空间--__device__ __global__函数中
//动态分配大小是执行参数中的第三个参数。当静态分配时必须指明大小 const unsigned int bid = blockIdx.x;
const unsigned int tid_in_block = threadIdx.x;
const unsigned int tid_in_grid = blockIdx.x*blockDim.x+threadIdx.x;
sdata[tid_in_block] = g_idata[tid_in_grid];
__syncthreads(); sdata[tid_in_block] *= (float)bid; __syncthreads(); g_odata[tid_in_grid] = sdata[tid_in_block];
}
cuda基础的更多相关文章
- CUDA基础介绍
一.GPU简介 1985年8月20日ATi公司成立,同年10月ATi使用ASIC技术开发出了第一款图形芯片和图形卡,1992年4月ATi发布了Mach32图形卡集成了图形加速功能,1998年4月ATi ...
- 【CUDA 基础】6.5 流回调
title: [CUDA 基础]6.5 流回调 categories: - CUDA - Freshman tags: - 流回调 toc: true date: 2018-06-20 21:56:1 ...
- 【CUDA 基础】6.3 重叠内和执行和数据传输
title: [CUDA 基础]6.3 重叠内和执行和数据传输 categories: - CUDA - Freshman tags: - 深度优先 - 广度优先 toc: true date: 20 ...
- 【CUDA 基础】6.1 流和事件概述
title: [CUDA 基础]6.1 流和事件概述 categories: - CUDA - Freshman tags: - 流 - 事件 toc: true date: 2018-06-10 2 ...
- 【CUDA 基础】6.2 并发内核执行
title: [CUDA 基础]6.2 并发内核执行 categories: - CUDA - Freshman tags: - 流 - 事件 - 深度优先 - 广度优先 - 硬件工作队列 - 默认流 ...
- 【CUDA 基础】6.0 流和并发
title: [CUDA 基础]6.0 流和并发 categories: - CUDA - Freshman tags: - 流 - 事件 - 网格级并行 - 同步机制 - NVVP toc: tru ...
- 【CUDA 基础】5.6 线程束洗牌指令
title: [CUDA 基础]5.6 线程束洗牌指令 categories: - CUDA - Freshman tags: - 线程束洗牌指令 toc: true date: 2018-06-06 ...
- 【CUDA 基础】5.4 合并的全局内存访问
title: [CUDA 基础]5.4 合并的全局内存访问 categories: - CUDA - Freshman tags: - 合并 - 转置 toc: true date: 2018-06- ...
- 【CUDA 基础】5.3 减少全局内存访问
title: [CUDA 基础]5.3 减少全局内存访问 categories: - CUDA - Freshman tags: - 共享内存 - 归约 toc: true date: 2018-06 ...
- 【CUDA 基础】5.2 共享内存的数据布局
title: [CUDA 基础]5.2 共享内存的数据布局 categories: - CUDA - Freshman tags: - 行主序 - 列主序 toc: true date: 2018-0 ...
随机推荐
- Python基础语法day_03——列表
day_03 列表是什么 在Python中,用[]来表示列表,并用逗号来分隔其中的元素.下面是一个简单的列表示例: >>> bicycles = ['treak','cannonda ...
- Windows 系统如何安装 Docker
1 docker 是基于 unix 开发的系列工具,所以在 windows 上安装 docker 非常容易出现环境不兼容的问题. 如果 windows 版本是 pro,一般是可以直接安装 docker ...
- webpack使用babel
几个月没用webpack都忘了好多了. webpack构建前端,使用时除了entry/output,就是plugins和module.loaders,还有本地测试的devServer. npm ins ...
- 数据结构----栈stack
栈的概念与数据结构 栈(有时称为“后进先出栈”)是一个元素的有序集合,其中添加移除新元素总发生在同一端.这一端通常称为“顶部”.与顶部对应的端称为“底部”.栈的底部很重要,因为在栈中靠近底部的元素是存 ...
- MYSQL的DOUBLE WRITE双写
期待未来超高速大容量的固态硬盘普及时,只需要CHECKPOINT,而不再需要各种各样的BUFFER,CACHE了 DOUBLE WRITE 在InnoDB将BP中的Dirty Page刷(flush) ...
- .Net数据集导出到Excel样式细节---------------摘自别人的
.Net数据集导出到Excel样式细节 本文的目的是总结一些在做Excel导出功能时需要注意的样式细节.使用环境是Asp.Net,数据集的形式是Html Table,Excel还是识别一些CSS代码的 ...
- poj2914无向图的最小割
http://blog.csdn.net/vsooda/article/details/7397449 //算法理论 http://www.cnblogs.com/ylfdrib/archive/20 ...
- mysql事务控制和锁定语句
MySQL 支持对 MyISAM 和 MEMORY 存储引擎的表进行表级锁定,对 BDB 存储引擎的表进行页级锁定,对 InnoDB 存储引擎的表进行行级锁定.默认情况下,表锁和行锁都是自动获得的,不 ...
- protected和private的区别
1. protected和private在没有继承关系的类A和类B之间其作用都可以视为式一样的--表示私有--每个类中的protected字段/属性都不能被访问到: 2. 当类与类之间存在继承关系时候 ...
- SpringMVC入门总结
一.SpringMVC的好处? 1,基于注解,stuts2虽然也有注解但是比较慢,没人用更多的时候是用xml的形式 2,能与spring其它技术整合比如说webflow等, 3,获取request及s ...