HashMap(三)之源码分析
通过分析
HashMap来学习源码,那么通过此过程我们要带着这几个问题去一起探索
- 为什么要学习源码
- 怎么去学习
0.1 为什么要学习源码
这个问题,直接给出结论,学习源码肯定是有好处的,比如:
- 学习优秀的编码设计
- 学习一些有用的算法
- 学习一些简单而又实用的方法
- 装逼神器,面试加分
0.2 怎么去学习
这个问题,则仁者见仁智者见智,我这里分享下我的学习心得。并通过HashMap的源码解析来实践检测我的学习方法。
- 先看此代码的实际使用场景
- 主句分析
- 遇到难点的地方,先记下啦,不要影响整体节奏
- 笔记学到的知识点:设计模式、编码风格、算法、有用的方法。
1. 开始分析
要分析源码就要知道,hashmap是怎么定义的,干什么的,
虽然平时都知道new,put,get,remove.那么我们是否曾停下来,看看官方文档,系统的了解它。
这也是中国程序员的通病,严重偏科,理论考试不过关,那在面试官眼里就是基础差! -- 通过一张图来了解下
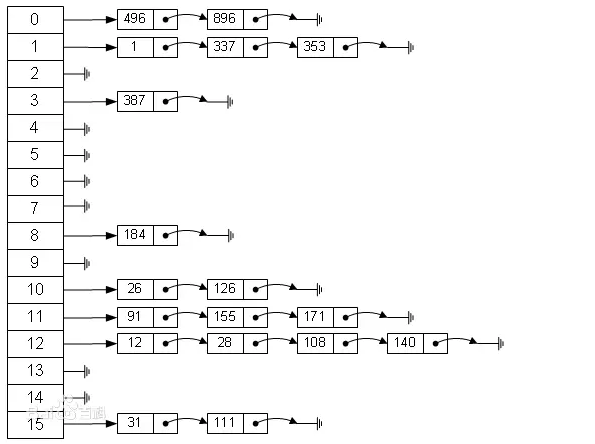
从上图我们可以看到,HashMap由链表+数组组成,他的底层结构是一个数组,而数组的元素是一个单向链表。图中是一个长度为16位的数组,每个数组储存的元素代表的是每一个链表的头结点。
上面我们说了有关Hash算法的事情,通过Key进行Hash的计算,就可以获取Key对应的HashCode。好的Hash算法可以计算出几乎出独一无二的HashCode,如果出现了重复的hashCode,就称作碰撞,就算是MD5这样优秀的算法也会发生碰撞,即两个不同的key也有可能生成相同的MD5。
正常情况下,我们通过hash算法,往HashMap的数组中插入元素。如果发生了碰撞事件,那么意味这数组的一个位置要插入两个或者多个元素,这个时候数组上面挂的链表起作用了,链表会将数组某个节点上多出的元素按照尾插法(jdk1.7及以前为头差法)的方式添加 。
在补充一下,就开始源码分析吧
- HashMap HashMap采用的是数组+链表+红黑树的形式。,它存储的内容是键值对(key-value)映射。
- HashMap 继承于AbstractMap,实现了Map、Cloneable、java.io.Serializable接口。
- HashMap 的实现不是同步的,这意味着它不是线程安全的。它的key、value都可以为null。此外,HashMap中的映射不是有序的
废话说了这么多,先上一段代码
// 1.创建hashmap
Map<String,String> stringMap = new HashMap<>();
//2. 插入值
stringMap.put("key1","vaule1");
// 3. 获取值
String value= stringMap.get("key1");
// 4. 删除key-value
stringMap.remove("key1");
以上就是我们使用HashMap的常用代码,我们就围绕此段的代码来分析。 顺便稍后整理下,我们能学到啥
- 此分析基于JDK1.8
- 需要了解位运算
1.0几个重要的变量
- initialCapacity 初始化容量16
- loadFactor 负载因子 默认0.75
这是在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查询成本(在大多数 HashMap 类的操作中,包括 get 和 put 操作,都反映了这一点)。在设置初始容量时应该考虑到映射中所需的条目数及其加载因子,以便最大限度地减少 rehash 操作次数。如果初始容量大于最大条目数除以加载因子,则不会发生 rehash 操作
- threshold 阈值,用于判断是否需要调整HashMap的容量,怎么获得阈值,
- 1.7 中 threshold = size*loadFactor
- 看一下下面这段代码,这个值的计算算法得到了进一步改进
// 返回的是一个size为 2的n次方的值
// 这是 jdk1.8 中的优化获取阈值
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
- 问题来了,为啥tableSizeFor要得到一个2的n次方
综上 hashmap 有12个成员变量,看详细源码,有分类分析
//默认初始容量为16,这里这个数组的容量必须为2的n次幂。
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
//最大容量为2的30次方
static final int MAXIMUM_CAPACITY = 1 << 30;
//默认加载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//以Node<K,V>为元素的数组,也就是上图HashMap的纵向的长链数组,起长度必须为2的n次幂
transient Node<K,V>[] table;
//已经储存的Node<key,value>的数量,包括数组中的和链表中的
transient int size;
//扩容的临界值,或者所能容纳的key-value对的极限。当size>threshold的时候就会扩容
int threshold;
//加载因子
final float loadFactor;
1.1 创建HashMap
我们看源码,HashMap提供了4个构造方法

public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
这里 我们有没有发现,构造方法并没有new 出一个table来作为一个hashMap,而在jdk1.7是这样的。
//在jdk1.7中,当HashMap创建的时候,table这个数组确实会初始化;但是到了jdk1.8中则没有
public HashMap(int initialCapacity, float loadFactor) {
......
this.loadFactor = loadFactor;
threshold = (int)(capacity * loadFactor);
table = new Entry[capacity]; //注意这里初始化了
init();
}
- JDK1.8 中真正table初始化的地方是在putVal()方法中,即首次向HashMap添加元素时,调用resize()创建并初始化了一个table数组
- 那么接下来分析一下看putVal()方法
1.2 HashMap插入值
put()-->>putVal() 实际上是下面这个方法的调用,来分析一下此方法
- 详见代码分析
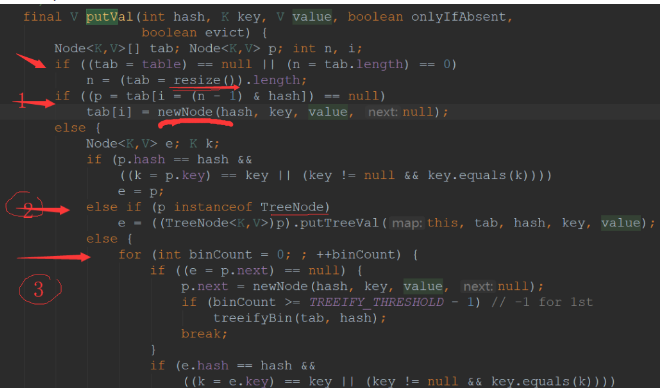
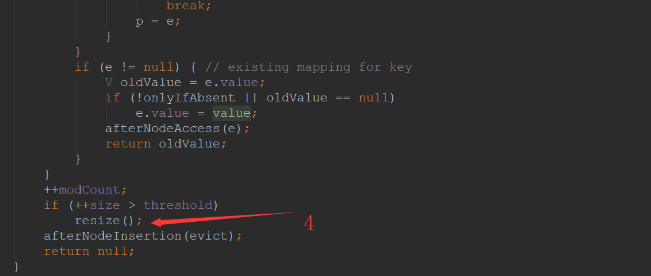
- 如上图,此段代码核心分5个关键地方
1.2.0 第一个箭头的地方
就是上面说的,jdk1.8 初始化table的地方
- table为空,则调用resize()函数创建一个
- 调用resize()创建并初始化了一个table数组。
- 区别与1.7 的初始化table,这里类似于一种 懒加载的思想,可以借鉴下
1.2.1
如果该index位置的Node元素不存在,则直接创建一个新的Node
- 这里创建新的node,首先需要知道hash 怎么来的
//首先将得到key对应的哈希值:h = key.hashCode(),然后通过hashCode()的高16位异或低16位实现的
//主要是从速度、功效、质量来考虑的,这么做可以在数组table的length比较小的时候,也能保证考虑到高低Bit都参与到Hash的计算中,同时不会有太大的开销。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
- 为什么要先高16位异或低16位再取模运算?
- 接着分析怎么获取这个tab当前的index = (n - 1) & hash,n是新创建的table数组的长度,取模运算.得到这个node保存的位置。
- HashMap底层数组的长度总是2的n次方,这是HashMap在速度上的优化。当length总是2的n次方时,hash&(length-1) 运算等价于对length取模,也就是hash % length,但是&比%具有更高的效率。
1.2.2
如果该index位置的Node元素是TreeNode类型即红黑树类型了,则直接按照红黑树的插入方式进行插入
1.2.3
如果该index位置的Node元素是非TreeNode类型则,则按照链表的形式进行插入操作
- 这个要添加的位置上面已经有元素了,也就是发生了碰撞。这个时候就要具体情况分
- 1.key值相同,直接覆盖
- 2.链表已经超过了8位,变成了红黑树
- 3.链表是正常的链表
1.2.4
链表插入操作完成后,判断是否超过阈值TREEIFY_THRESHOLD(默认是8),超过则要么数组扩容要么链表转化成红黑树
- 这里分析一下扩容这个方法
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table; //创建一个oldTab数组用于保存之前的数组
int oldCap = (oldTab == null) ? 0 : oldTab.length; //获取原来数组的长度
int oldThr = threshold; //原来数组扩容的临界值
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) { //如果原来的数组长度大于最大值(2^30)
threshold = Integer.MAX_VALUE; //扩容临界值提高到正无穷
return oldTab; //返回原来的数组,也就是系统已经管不了了,随便你怎么玩吧
}
//else if((新数组newCap)长度乘2) < 最大值(2^30) && (原来的数组长度)>= 初始长度(2^4))
//这个else if 中实际上就是咋判断新数组(此时刚创建还为空)和老数组的长度合法性,同时交代了,
//我们扩容是以2^1为单位扩容的。下面的newThr(新数组的扩容临界值)一样,在原有临界值的基础上扩2^1
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0)
newCap = oldThr; //新数组的初始容量设置为老数组扩容的临界值
else { // 否则 oldThr == 0,零初始阈值表示使用默认值
newCap = DEFAULT_INITIAL_CAPACITY; //新数组初始容量设置为默认值
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); //计算默认容量下的阈值
}
if (newThr == 0) { //如果newThr == 0,说明为上面 else if (oldThr > 0)
//的情况(其他两种情况都对newThr的值做了改变),此时newCap = oldThr;
float ft = (float)newCap * loadFactor; //ft为临时变量,用于判断阈值的合法性
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE); //计算新的阈值
}
threshold = newThr; //改变threshold值为新的阈值
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab; //改变table全局变量为,扩容后的newTable
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) { //遍历数组,将老数组(或者原来的桶)迁移到新的数组(新的桶)中
Node<K,V> e;
if ((e = oldTab[j]) != null) { //新建一个Node<K,V>类对象,用它来遍历整个数组
oldTab[j] = null;
if (e.next == null)
//将e也就是oldTab[j]放入newTab中e.hash & (newCap - 1)的位置,
newTab[e.hash & (newCap - 1)] = e; //这个我们之前讲过,是一个取模操作
else if (e instanceof TreeNode) //如果e已经是一个红黑树的元素,这个我们不展开讲
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // 链表重排,这一段是最难理解的,也是ldk1.8做的一系列优化,我们在下面详细讲解
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) { //关键判断条件,即可将原桶中的数据分成2类
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
//可以知道,如果(e.hash & oldCap) == 0,则 newTab[j] = loHead = e = oldTab[j],即索引位置没变。反之 (e.hash & oldCap) != 0, newTab[j + oldCap] = hiHead = e = oldTab[j],也就是说,此时把原数组[j]位置上的桶移到了新数组[j+原数组长度]的位置上了
。
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
- 扩容涉及到数组迁移问题
- 按照2倍扩容的方式,那么就需要将之前的所有元素全部重新按照2倍桶的长度重新计算所在桶。这里为啥是2倍?也涉及到reHash
- 先,要生成一个新的桶数组,然后要把所有元素都重新Hash落桶一次,几乎等于重新执行了一次所有元素的put。
因为2倍的话,更加容易计算他们所在的桶,并且各自不会相互干扰。如原桶长度是4,现在桶长度是8,那么
桶0中的元素会被分到桶0和桶4中
桶1中的元素会被分到桶1和桶5中
桶2中的元素会被分到桶2和桶6中
桶3中的元素会被分到桶3和桶7中
为啥是这样呢?
桶0中的元素的hash值后2位必然是00,这些hash值可以根据后3位000或者100分成2类数据。他们分别&(8-1)即&111,则后3位为000的在桶0中,后3位为100的必然在桶4中。其他同理,也就是说桶4和桶0重新瓜分了原来桶0中的元素。
如果换成其他倍数,那么瓜分就比较混乱了。
这样在瓜分这些数据的时候,只需要先把这些数据分类,如上述桶0中分成000和100 2类,然后直接构成新的链表,分类完毕后,直接将新的链表挂在对应的桶下即可
- 代码中注释的很详细了,此处分析可以参考下面提供的而参考文章,分析需要依赖于位运算
1.3 HashMap获取值
直接上代码
public V get(Object key) {
// 这里可以看到 get方法其实是拿到一个Node对象后,再取其value
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
所以核心方法应该是 getNode()
1.4 HashMap删除key-value
直接上代码
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
所以核心方法应该是 removeNode()
总结 了解 hash 和扩容,get put 就很好理解了,这里就不展开讨论了
2. 学习总结
- 怎么利用位运算来让代码更加优雅
疑点
- 为什么要先高16位异或低16位再取模运算
3. 参考文章
4. 知识点补充
HashMap(三)之源码分析的更多相关文章
- 并发-HashMap和HashTable源码分析
HashMap和HashTable源码分析 参考: https://blog.csdn.net/luanlouis/article/details/41576373 http://www.cnblog ...
- HashMap原理及源码分析
HashMap 原理及源码分析 1. 存储结构 HashMap 内部是由 Node 类型的数组实现的.Node 包含着键值对,内部有四个字段,从 next 字段我们可以看出,Node 是一个链表.即数 ...
- HashMap:从源码分析到面试题
1 HashMap简介 HashMap是实现map接口的一个重要实现类,在我们无论是日常还是面试,以及工作中都是一个经常用到角色.它的结构如下: 它的底层是用我们的哈希表和红黑树组成的.所以我们在学习 ...
- HashMap与TreeMap源码分析
1. 引言 在红黑树--算法导论(15)中学习了红黑树的原理.本来打算自己来试着实现一下,然而在看了JDK(1.8.0)TreeMap的源码后恍然发现原来它就是利用红黑树实现的(很惭愧学了Ja ...
- JDK1.8 HashMap中put源码分析
一.存储结构 在JDK1.8之前,HashMap采用桶+链表实现,本质就是采用数组+单向链表组合型的数据结构.它之所以有相当快的查询速度主要是因为它是通过计算散列码来决定存储的位置.Hash ...
- EasyUI学习总结(三)——easyloader源码分析(转载)
声明:这一篇文章是转载过来的,转载地址忘记了,原作者如果看到了,希望能够告知一声,我好加上去! easyloader模块是用来加载jquery easyui的js和css文件的,而且它可以分析模块的依 ...
- Nimbus<三>Storm源码分析--Nimbus启动过程
Nimbus server, 首先从启动命令开始, 同样是使用storm命令"storm nimbus”来启动看下源码, 此处和上面client不同, jvmtype="-serv ...
- (三)uboot源码分析
一.九鼎官方uboot和三星原版uboot对比(1)以九鼎官方的uboot为蓝本来学习的,以三星官方的这份为对照.(2)不同版本的uboot或者同一版本不同人移植的uboot,可能目录结构和文件内容都 ...
- 关于JDK1.8 HashMap扩容部分源码分析
今天回顾hashmap源码的时候发现一个很有意思的地方,那就是jdk1.8在hashmap扩容上面的优化. 首先大家可能都知道,1.8比1.7多出了一个红黑树化的操作,当然在扩容的时候也要对红黑树进行 ...
随机推荐
- Redux:data flow
我们使用react,是为了构建可复用的高性能的视图层,学习redux是为了处理视图组件中随应用复杂度提升而变得难以控制的state.说白了,是为了视图. 在了解了action.reducer和stor ...
- JSP中System.out.println()与out.println()区别
1.out.println()输出到客户端. 在out.println()中,out是response的实例,是以response为对象进行流输出的,即将内容输出到客户端. 如果在JSP页面中使用Sy ...
- uefi win10 Ubuntu 18的安装
uefi win10 Ubuntu 18的安装 (Ubuntu折腾的第一天) 安装时的踩坑记录
- 苏浪浪 201771010120 《面向对象程序设计(java)》第9周学习总结
实验九异常.断言与日志 实验时间 2018-10-25 1.实验目的与要求 (1) 掌握java异常处理技术: (2) 了解断言的用法: (3) 了解日志的用途: (4) 掌握程序基础调试技巧: 2. ...
- LightOJ1236
题目大意: 给你一个 n,请你找出共有多少对(i,j)满足 lcm(i,j) = n (i<=j) . 解题思路: 我们利用算术基本定理将 n,i,j 进行分解: n = P1a1 * P2a2 ...
- Maven、Gradle 配置国内镜像源
Maven 全局配置 修改 Maven 默认的全局配置文件: 类 Unix 系统: Mac OS / Linux 默认在 ~/.m2/settings.xml Windows 系统:一般在 Maven ...
- vim的基础命令
:q 退出 :wq 保存并退出 :q! 不保存并退出 :w 保存 :w! 强行保存
- vue 实例化使用模板
var vm = new Vue({ el:"", data:{ }, methods:{ } })
- Linux学习(二):makefile
编译命令: gcc -o exefile src.c (将src.c编译,链接为exefile可执行文件) gcc -o obj.o -c src.c (将src.c编译为obj.o目标文件) mak ...
- [JavaWeb基础] 025.JAVA把word转换成html
用第三方插件POI把word文档转换成HTML,下面直接上代码 package com.babybus.sdteam.wordtopdf; import java.io.BufferedWriter; ...