Category、load、initialize 源码讲解
今天深圳天气有暴风雨,没有事情干,趁着周末和平常晚上写一篇关于Category知识的梳理!可能针对平常只会知道些category基本结论知道的人有些帮助,写这篇博客会按照下面的目录结合实例以及Category的源码进行一一讲解!!!
- Category的实现原理?
- Category中有load方法吗?load方法是什么时候调用的?
- load、initialize方法的区别是什么?它们在Category中的调用的顺序?以及出现继承时调用过程发生怎样的变化?
- Category能否添加成员变量?如果可以,如何给Category添加成员变量?
一、Category的实现原理
1. 前沿Category讲解-所有知识在这
在Xcode中使用Category,可以在里面添加方法以及遵守相应的协议。下面以实例讲解,首先创建ZXYPerson类,类中有对象方法run方法,创建两个分类ZXYPerson+Test和ZXYPerson+Eat,方法分别为test和eat方法。,结构代码如下:
运行代码执行结果如下:

上面person是实例对象,所以run实例方法是放在ZXYPerson的实例对象方法中,而对于ZXYPerson(Test)和ZXYPerson(Eat)中的test和eat方法放在哪里了呢?
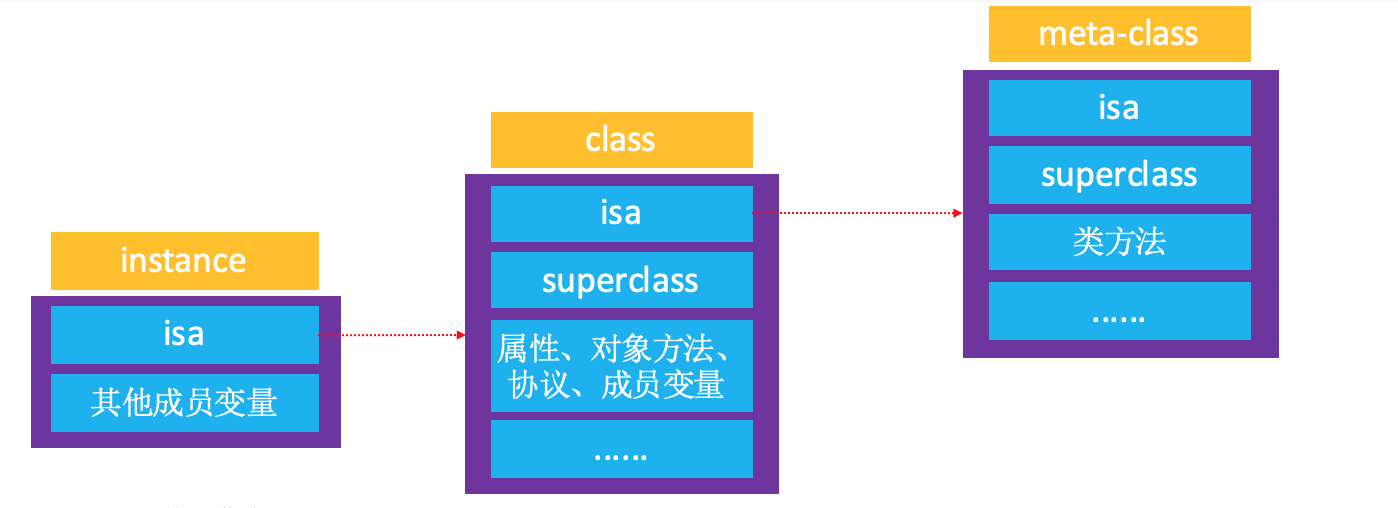
拓展: isa指针方法
- instance的isa指向class
当调用对象方法时,通过instance的isa找到class,最后找到对象方法的实现进行调用
- class的isa指向meta-class
当调用类方法时,通过class的isa找到meta-class,最后找到类方法的实现进行调用
答:Category的方法并不是在编译的时候将方法加入到ZXYPerson的实例对象中的,而是在运行时通过Runtime运行时机制将分类的方法合并到到实例对象中的!
将ZXYPerson+Eat.m clang编译成.cpp文件,查看编译之后的代码(xcrun -sdk iphonesimulator clang -rewrite-objc ZXYPerson+Eat.m)
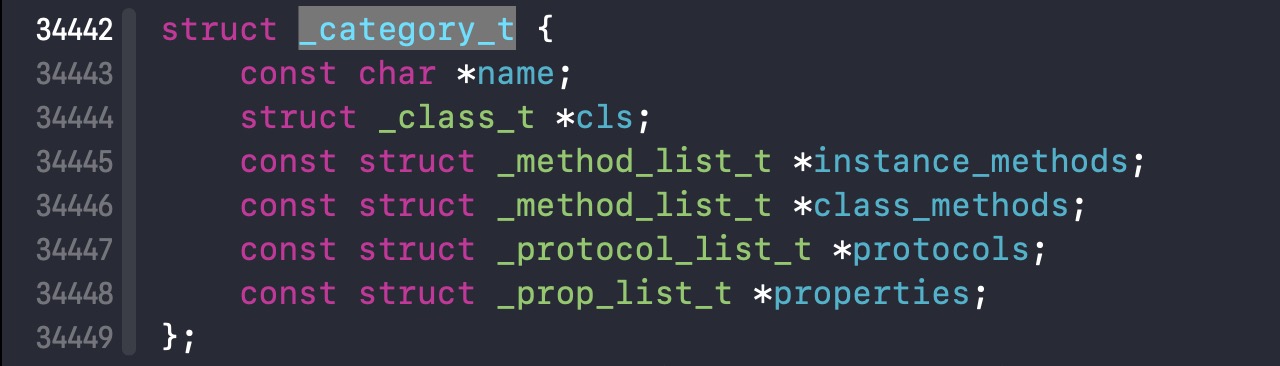
查看一下协议Category的结构体如下:
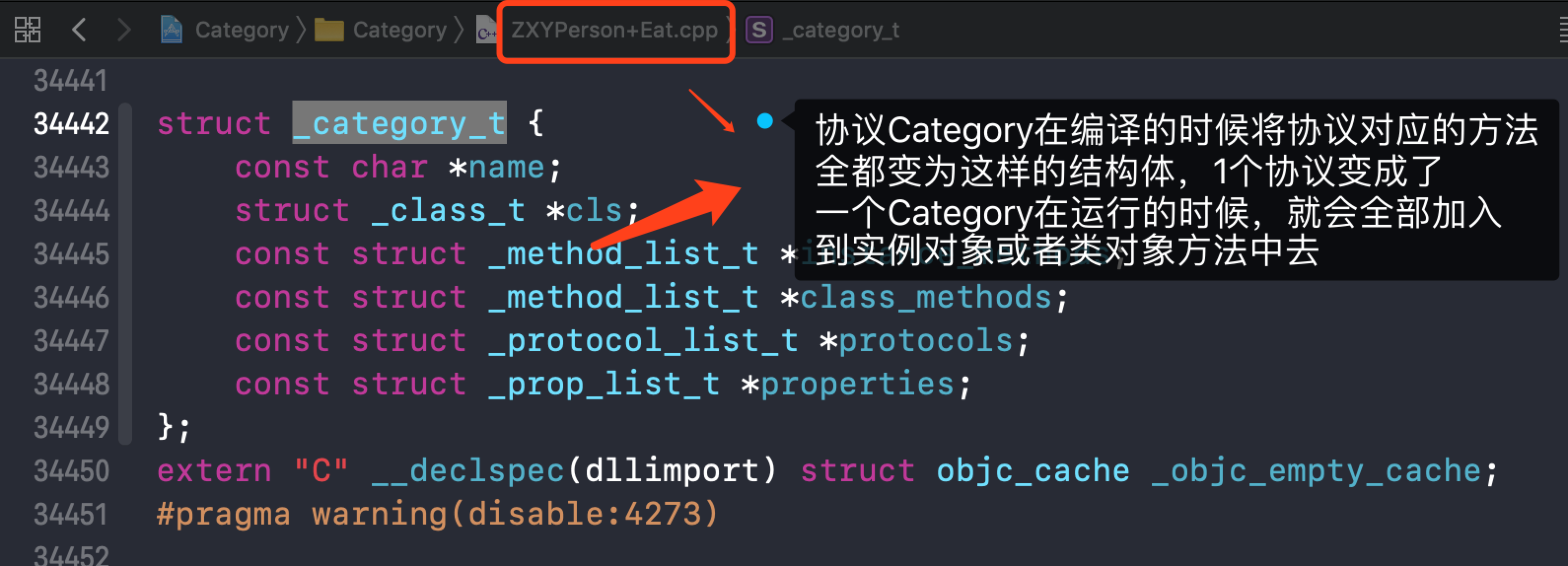
上面协议ZXYPerson+Test以及ZXYPerson+Eat经过编译会编译成两个_category_t结构体,在运行时会把它加入到ZXYPerson的实例对象中(也有可能是类对象中,或者元类对象)
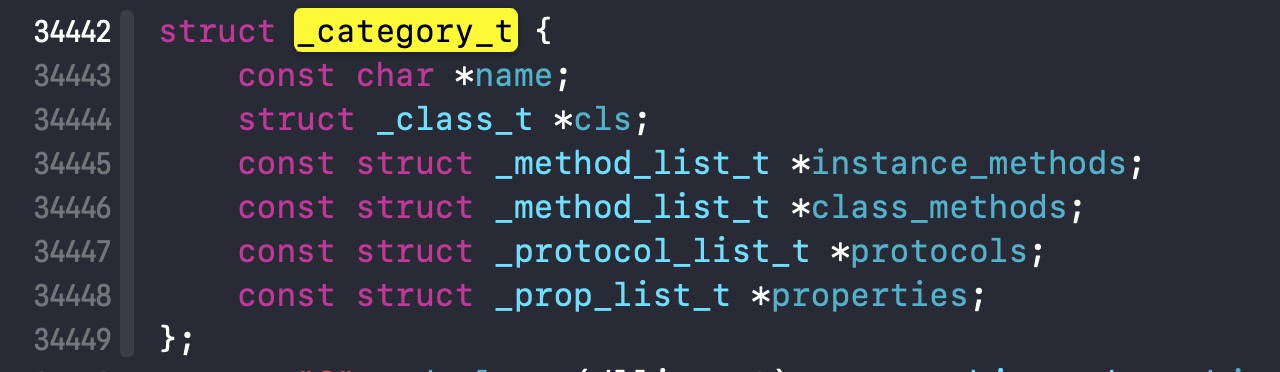
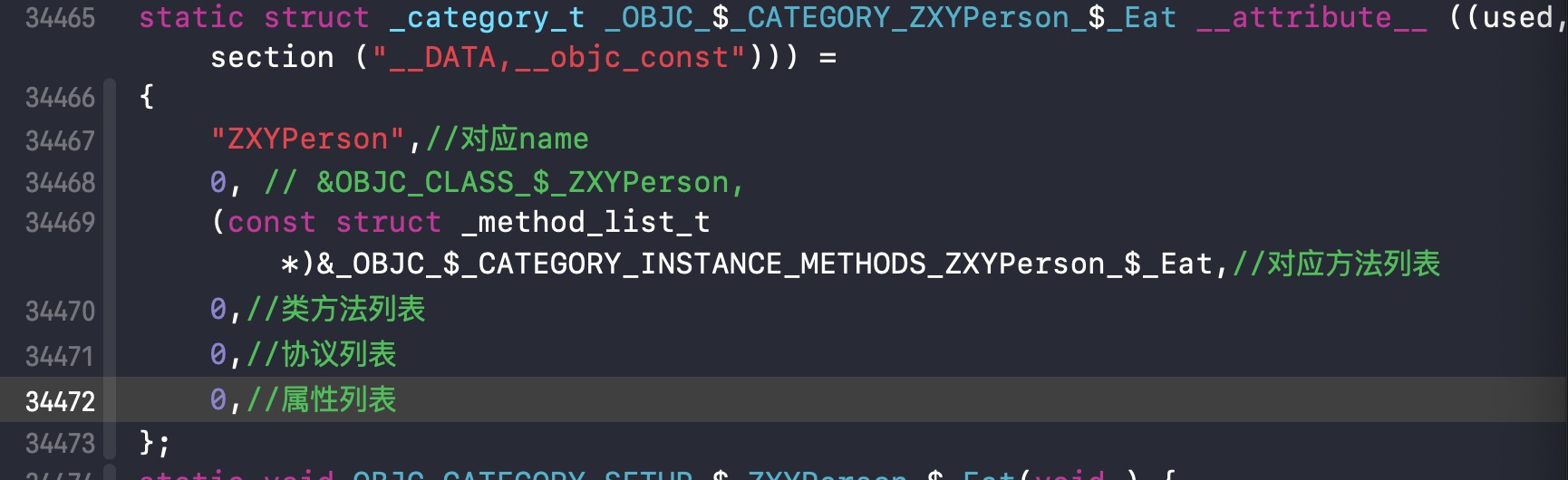
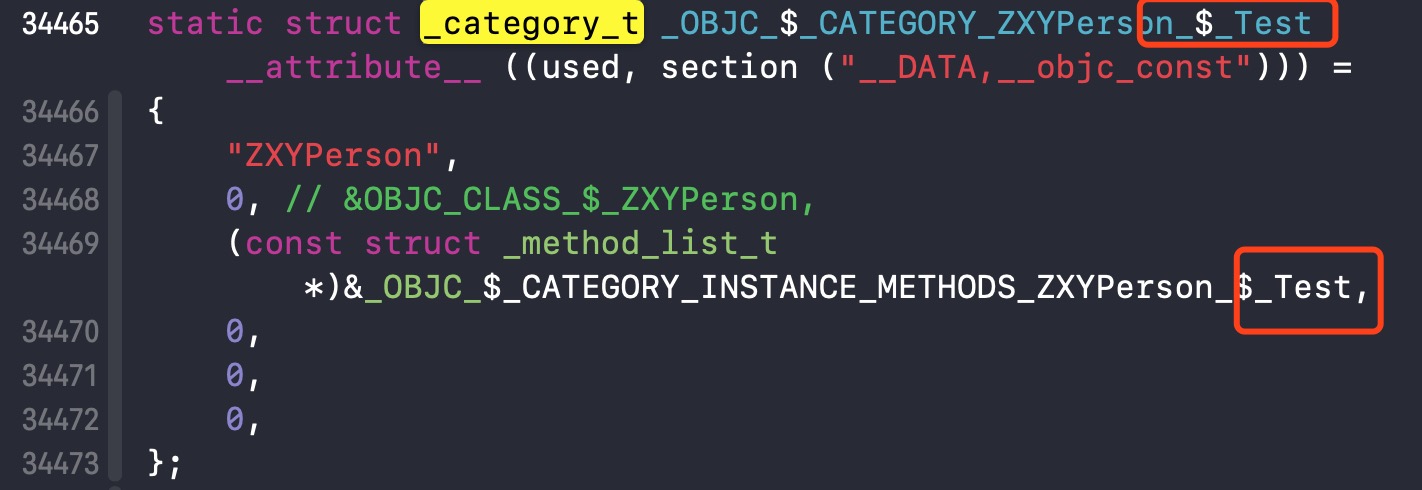
如果换成ZXYPerson+Test协议变为.cpp文件,_category_t这个结构体不会发生改变,但是后面的传参会发生改变如下:
2. 源码讲解
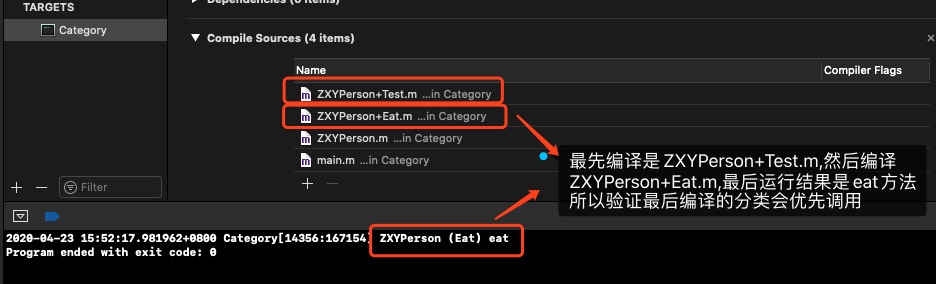
下面来验证一下为什么Category的优先级高于主类?原理是什么?
2.1 结论
上面的run方法到底会调用哪一个呢,这个编译顺序有关,最后参与编译的分类会优先调用
抽出上面的main.m代码,ZXYPerson、ZXYPerson+Eat以及ZXYPerson+Test都具有run方法(看上面收起来的代码)
#import <Foundation/Foundation.h>
#import "ZXYPerson.h"
#import "ZXYPerson+Eat.h"
#import "ZXYPerson+Test.h" int main(int argc, const char * argv[]) {
@autoreleasepool {
ZXYPerson *person = [[ZXYPerson alloc]init];
[person run];
}
return 0;
}
看下编译顺序和运行结果
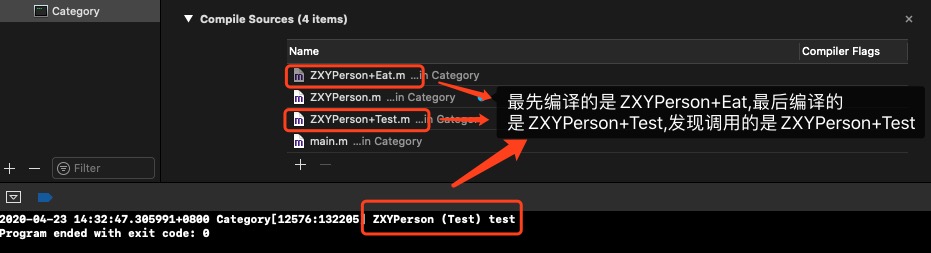
如果将编译顺序改变下
2.2 原因
查看的OC的源码是objc4-723版本 查看Category的加载处理过程,过程可以为以下步骤:
- objc-os.m
- _objc_init
- map_images
- map_images_nolock
2. objc-runtime-new.mm
- _read_images(images是镜像,逆向开发博客有)
- remethodizeClass
- attachCategories
- attachLists
- realloc、memmove、memcpy
直接看Category加载逻辑,搜索attachCategories,找到对应的实现

下面针对attachCategories的实现开始讲解,大家认认真真看下代码
static void
attachCategories(Class cls, category_list *cats, bool flush_caches)
{
// cls: [ZXYPerson class]
// cats - category: 代表[ZXYPerson+Eat,ZXYPerson+Test] if (!cats) return;
if (PrintReplacedMethods) printReplacements(cls, cats); bool isMeta = cls->isMetaClass(); /**方法列表 **mlists 二维数组
*[
* [method_t,method_t],
* [method_t,method_t]
* ]
*/
method_list_t **mlists = (method_list_t **)
malloc(cats->count * sizeof(*mlists)); /**属性列表 **proplists 二维数组
*[
* [property_t,property_t],
* [property_t,property_t]
* ]
*/
property_list_t **proplists = (property_list_t **)
malloc(cats->count * sizeof(*proplists)); /**协议列表 **protolists 二维数组
*[
* [protol_t,protol_t],
* [protol_t,protol_t]
* ]
*/
protocol_list_t **protolists = (protocol_list_t **)
malloc(cats->count * sizeof(*protolists)); // Count backwards through cats to get newest categories first
int mcount = ;
int propcount = ;
int protocount = ;
int i = cats->count;
bool fromBundle = NO;
while (i--) {//最后面编译的分类会优先调用,i--,首先取最后一个分类 auto& entry = cats->list[i];
//将category里面的方法列表组都加入到一个数组中
method_list_t *mlist = entry.cat->methodsForMeta(isMeta);
if (mlist) {
mlists[mcount++] = mlist;
fromBundle |= entry.hi->isBundle();
}
//将category里面的属性列表组都加入到一个数组中
property_list_t *proplist =
entry.cat->propertiesForMeta(isMeta, entry.hi);
if (proplist) {
proplists[propcount++] = proplist;
}
//将category里面的协议列表组都加入到一个数组中
protocol_list_t *protolist = entry.cat->protocols;
if (protolist) {
protolists[protocount++] = protolist;
}
} //得到类里面的数据
auto rw = cls->data(); prepareMethodLists(cls, mlists, mcount, NO, fromBundle);
// 将所有分类的对象方法,附加到类(对象)对象的方法列表中
rw->methods.attachLists(mlists, mcount);
free(mlists);
if (flush_caches && mcount > ) flushCaches(cls); // 将所有分类的属性,附加到类(对象)对象的属性列表中
rw->properties.attachLists(proplists, propcount);
free(proplists); //将所有分类的协议,附加到类(对象)对象的协议列表中
rw->protocols.attachLists(protolists, protocount);
free(protolists);
}
对于方法attachCategories的参数cls:在本次例子中代表的是[ZXYPerson class]; cats代表的是分类列表[ZXYPerson+Eat,ZXYPerson+Test]
然后紧接着分配了三个数组空间,三个二维数组mlists,proplists以及protolists分别放着方法、属性和协议列表,然后看一个附加加载过程的原理attachLists()方法
/**方法列表 **mlists 二维数组
*[
* [method_t,method_t],协议ZXYPerson+Test的方法test
* [method_t,method_t] 协议ZXYPerson+Eat的方法Eat
* ]
* addedCount = 2
*/
void attachLists(List* const * addedLists, uint32_t addedCount) {
if (addedCount == ) return; if (hasArray()) {
// many lists -> many lists
uint32_t oldCount = array()->count;
//因为ZXYPerson有一个方法run,所以oldCount为1 ,addCount两个分类共有两个方法,所以newCount = 3
uint32_t newCount = oldCount + addedCount; //通过realloc方法重新分配内存,并分配newCount的空间大小
setArray((array_t *)realloc(array(), array_t::byteSize(newCount)));
array()->count = newCount; //array()->lists:返回原来的方法列表
//void *memmove(void *__dst, const void *__src, size_t __len);将src的array()->lists移到array()->lists + addedCount,因为addedCount = 2,相当于将array()->lists向后移动2位
memmove(array()->lists + addedCount, array()->lists,
oldCount * sizeof(array()->lists[])); //addedLists:所有分类的方法列表
//void *memcpy(void *__dst, const void *__src, size_t __n); 将src的addedLists拷贝到dst的array()->lists(原来方法的列表)
//相当于分类的方法列表拷贝到了原来的方法列表位置,而原来的方法列表位于前面
memcpy(array()->lists, addedLists,
addedCount * sizeof(array()->lists[]));
}
else if (!list && addedCount == ) {
// 0 lists -> 1 list
list = addedLists[];
}
else {
// 1 list -> many lists
List* oldList = list;
uint32_t oldCount = oldList ? : ;
uint32_t newCount = oldCount + addedCount;
setArray((array_t *)malloc(array_t::byteSize(newCount)));
array()->count = newCount;
if (oldList) array()->lists[addedCount] = oldList;
memcpy(array()->lists, addedLists,
addedCount * sizeof(array()->lists[]));
}
}
上面源码对应方法内容也做了比较详细的解释,大家可以细细体会看下!下面memcpy(拷贝)和memmove(移动)函数

现在就来回答第一个问题:Category的实现原理?
1. 通过Runtime加载某个类的所有Category数据
2. 把所有Category的方法、属性、协议数据,合并到一个大数组中,后面参与编译的Category数据,会放在数组的前面
3. 将合并后的分类数据(方法、属性、协议)插入到类原来数据的前面
写到上面了,大家可能有人有疑问,那Category和Objective-C 的class Extension有什么关系区别嘛?
- Objective-C 的class Extension 是在编译的时候,它的数据已经包含在类信息中
- Category在运行时才会将数据合并到类信息中
二、Category中有load方法嘛?load方法什么时候调用?
创建ZXYPerson以及ZXYPerson的分类ZXYPerson+Test和ZXYPerson+Eat,在代码中加入load代码,下面是源代码
#import <Foundation/Foundation.h>
int main(int argc, const char * argv[]) {
@autoreleasepool {
}
return ;
}
#import <Foundation/Foundation.h>
NS_ASSUME_NONNULL_BEGIN
@interface ZXYPerson : NSObject
@end
NS_ASSUME_NONNULL_END
#import "ZXYPerson.h"
@implementation ZXYPerson
+(void)load {
NSLog(@"ZXYPerson的load方法");
}
@end
#import <Foundation/Foundation.h>
#import "ZXYPerson.h"
NS_ASSUME_NONNULL_BEGIN
@interface ZXYPerson (Test)
@end
#import "ZXYPerson+Test.h"
#import <Foundation/Foundation.h>
@implementation ZXYPerson (Test)
+(void)load {
NSLog(@"ZXYPerson (Test)的load方法");
}
@end
#import <Foundation/Foundation.h>
#import "ZXYPerson.h"
NS_ASSUME_NONNULL_BEGIN
@interface ZXYPerson (Eat)
@end
NS_ASSUME_NONNULL_END
#import "ZXYPerson+Eat.h"
@implementation ZXYPerson (Eat)
+(void)load {
NSLog(@"ZXYPerson (Test)的load方法");
}
@end

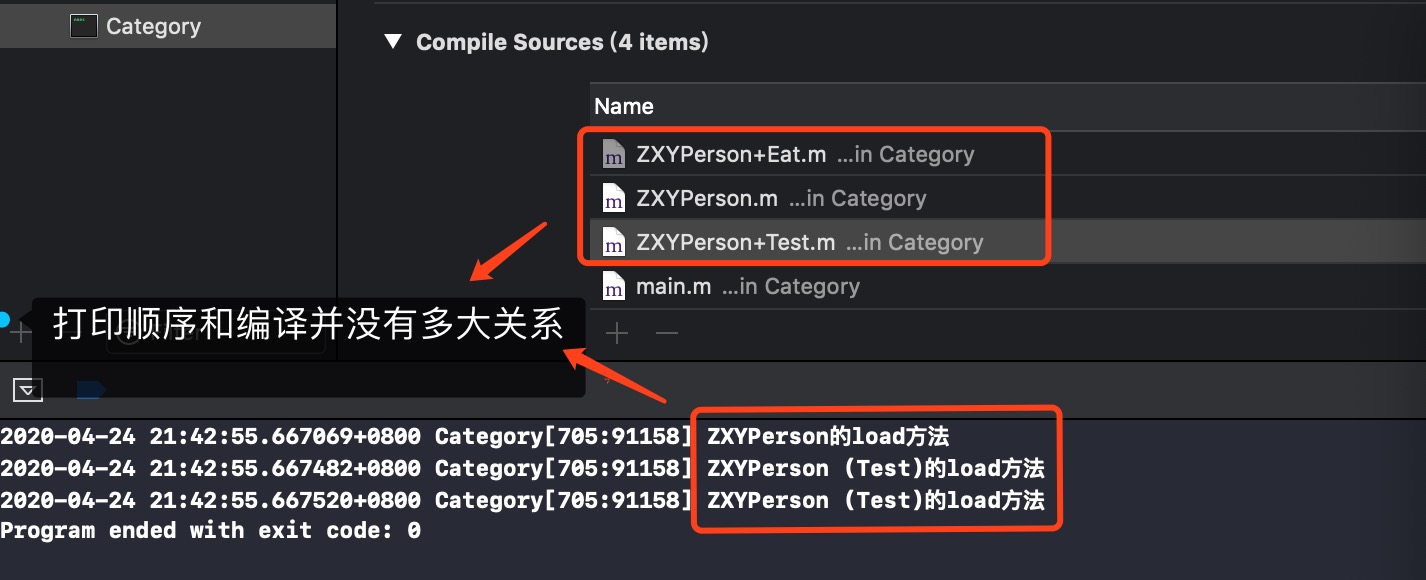
刚刚代码的编译顺序如下:
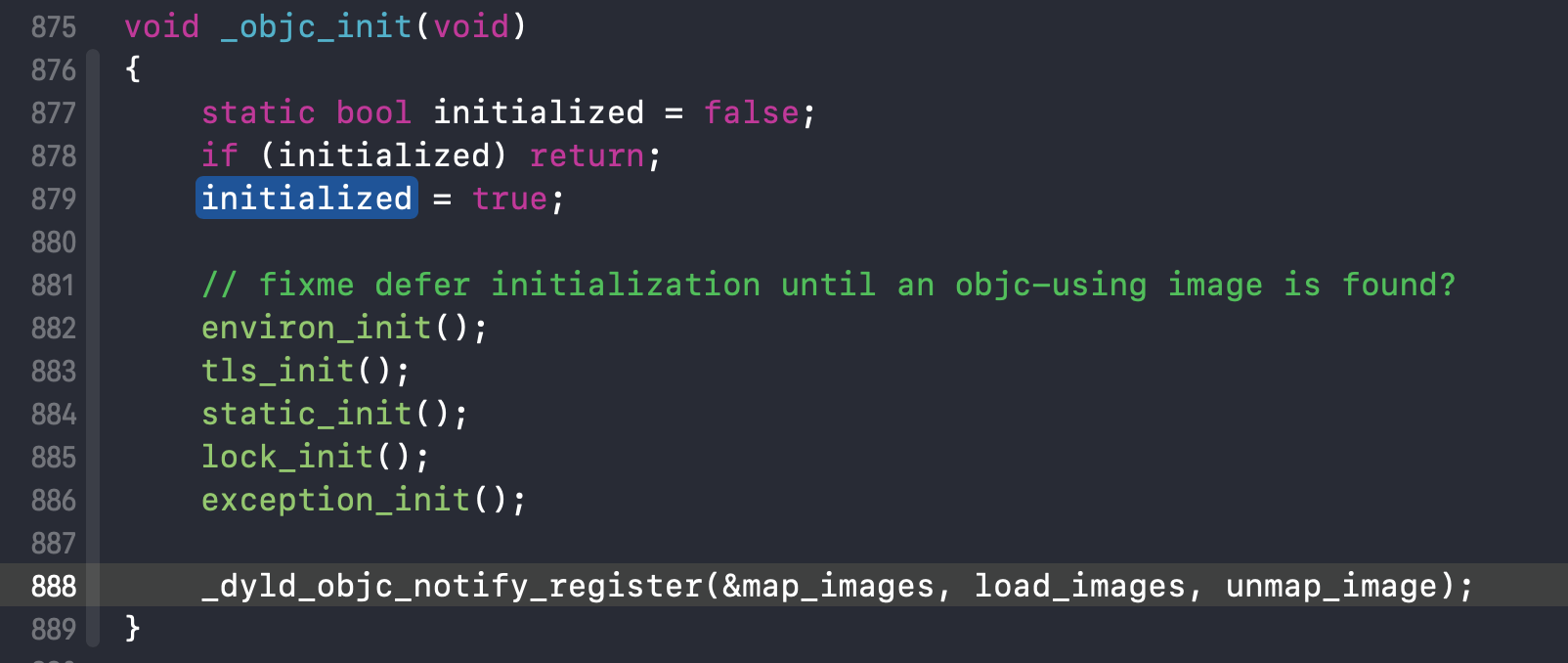
下面通过源码分析一下load的调用顺序! objc4源码解读过程:objc-os.mm
1. _objc_init,点击load_images
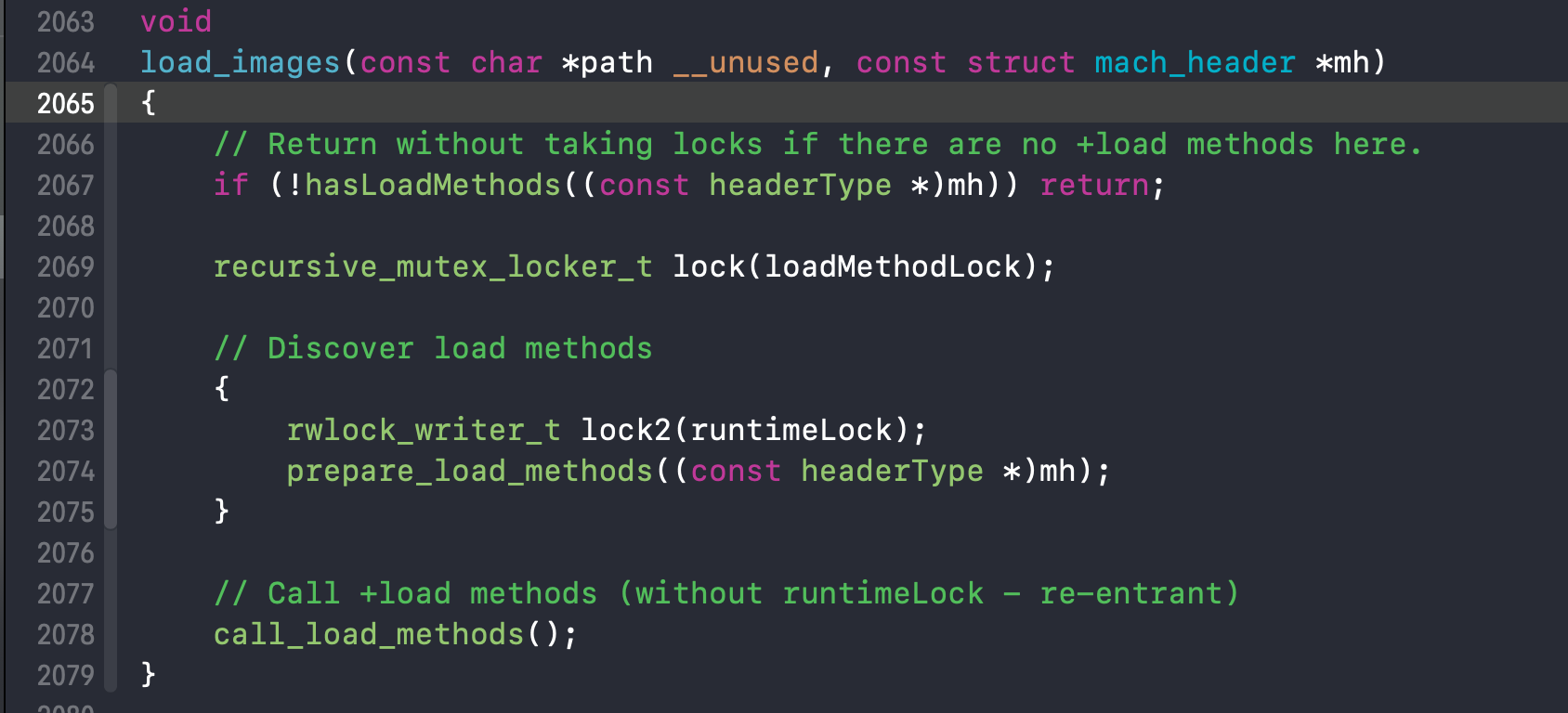
2. 进入load_images,看到prepare_load_methods和call_load_methods,首先看call_load_methods
3. 查看call_load_methods
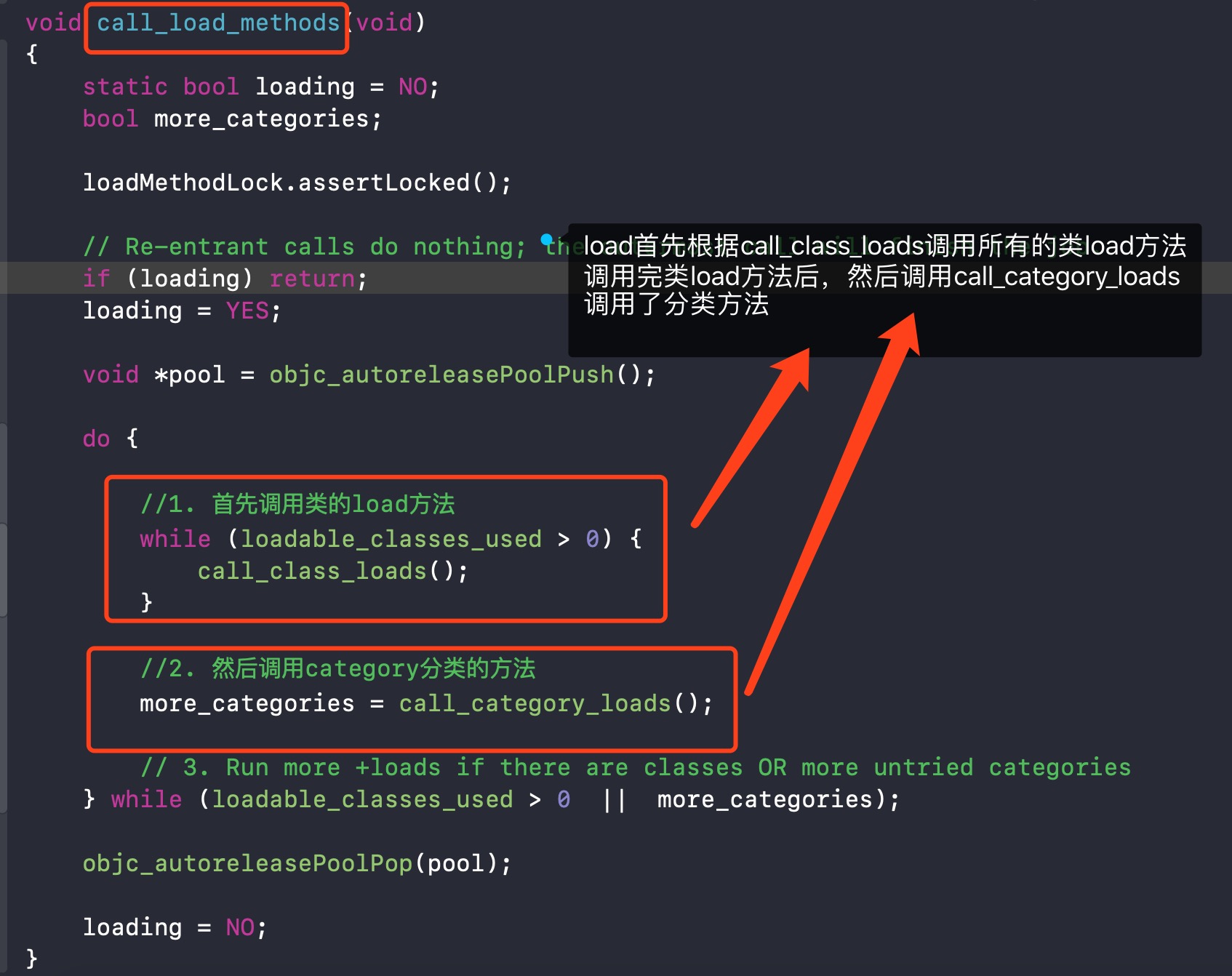
上面就验证了一个观点:先调用类的+load,然后再调用分类的+load
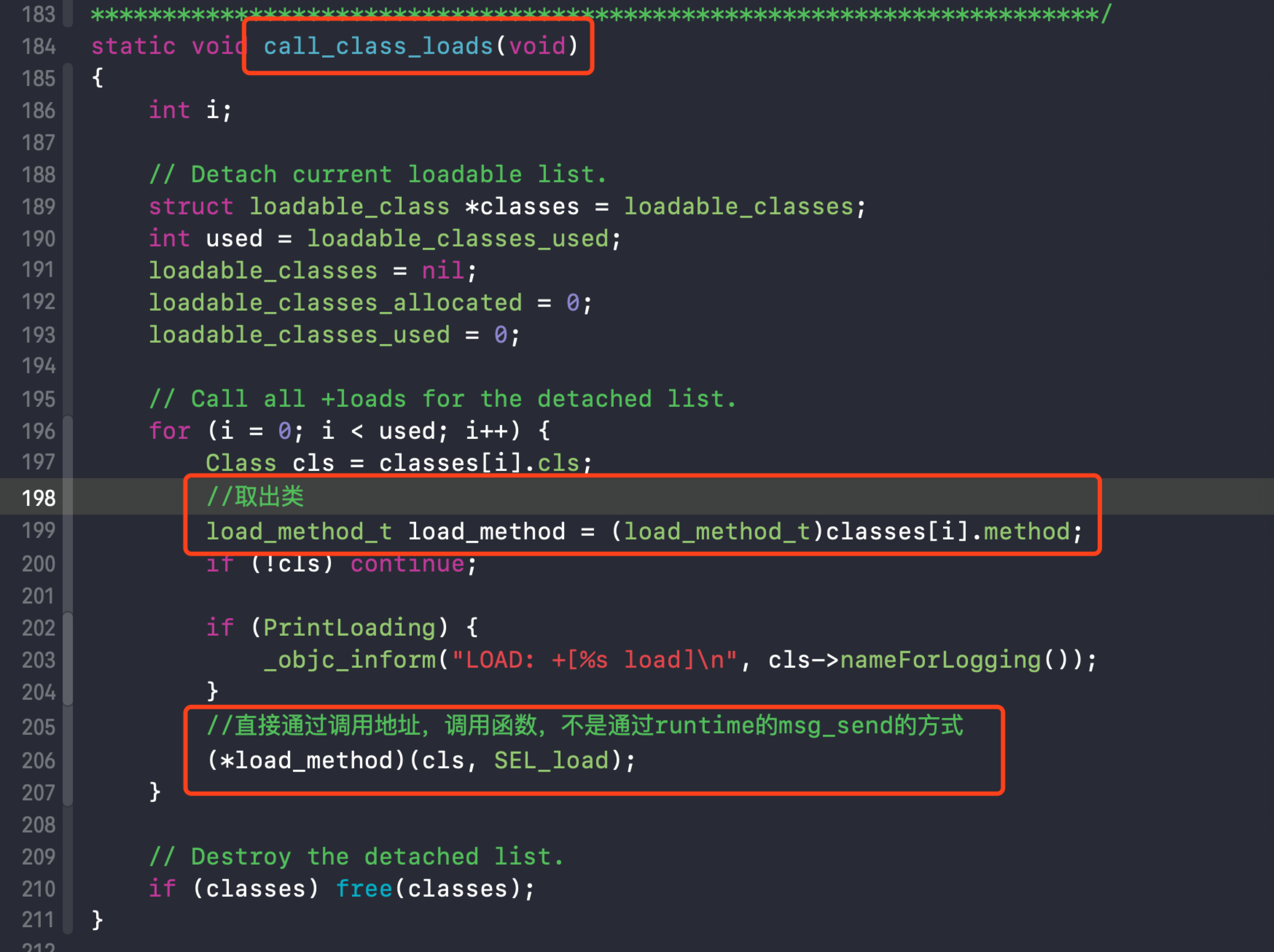
紧接着分别查看call_class_loads方法和call_category_loads方法
4. call_class_loads 加载类的load方法
假如项目中有100个类, 到底先调用哪一个类呢?
回到上面2中的load_images中,发现调用call_classes_loads之前也做了调用prepare_load_methods,再次进入了prepare_load_method中,看看有没有做一些准备工作:
5. prepare_load_method的实现
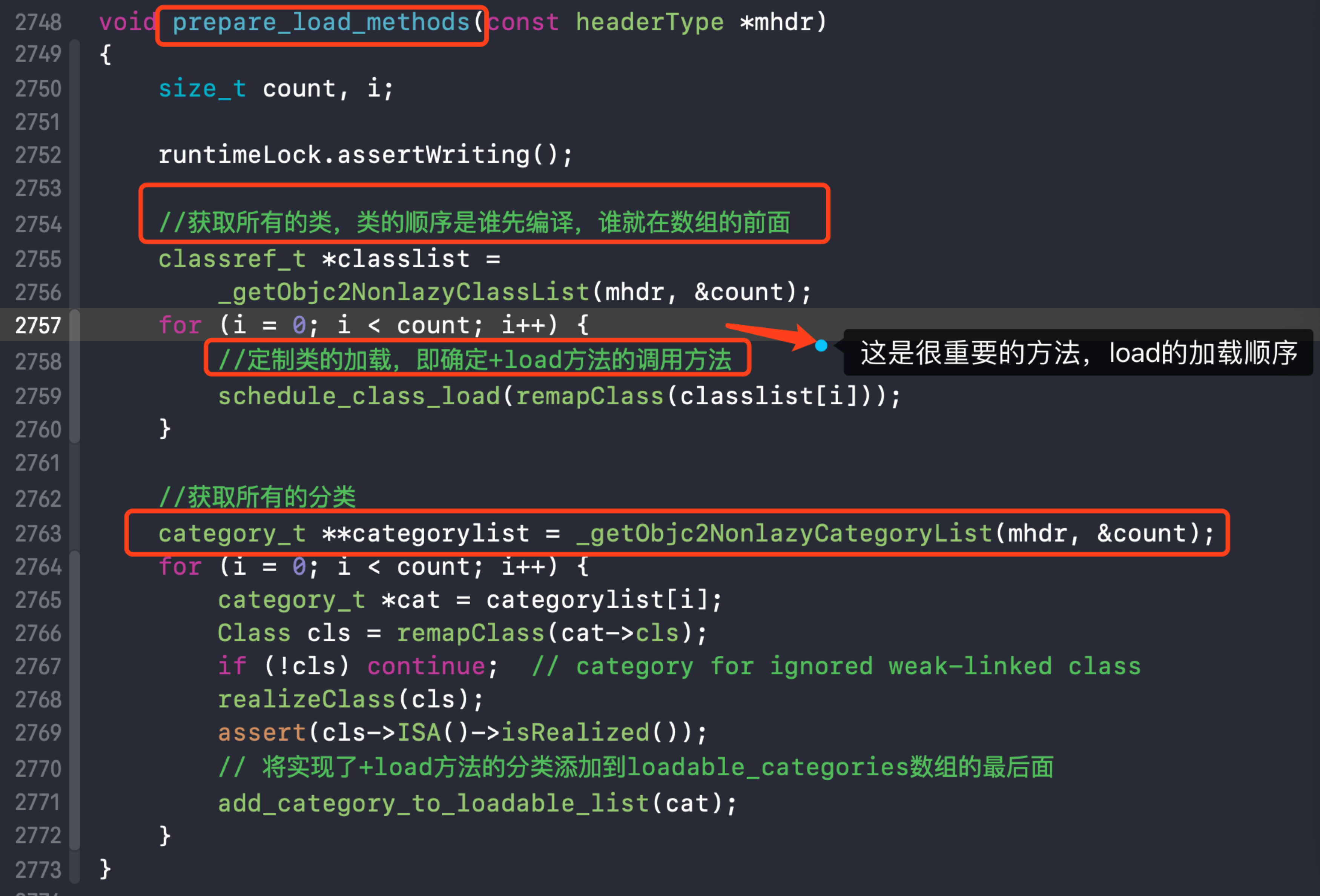
prepare_load_method 实现分为以下步骤:
- 获取所有类,调用schedule_class_load
- 关于classlist和categorylist两个数组顺序是根据类、分类被编译的顺序放到了对应的数组中去
6. 类load的调用顺序
确定类load的调用顺序,依赖于schedule_class_load,它的实现如下:
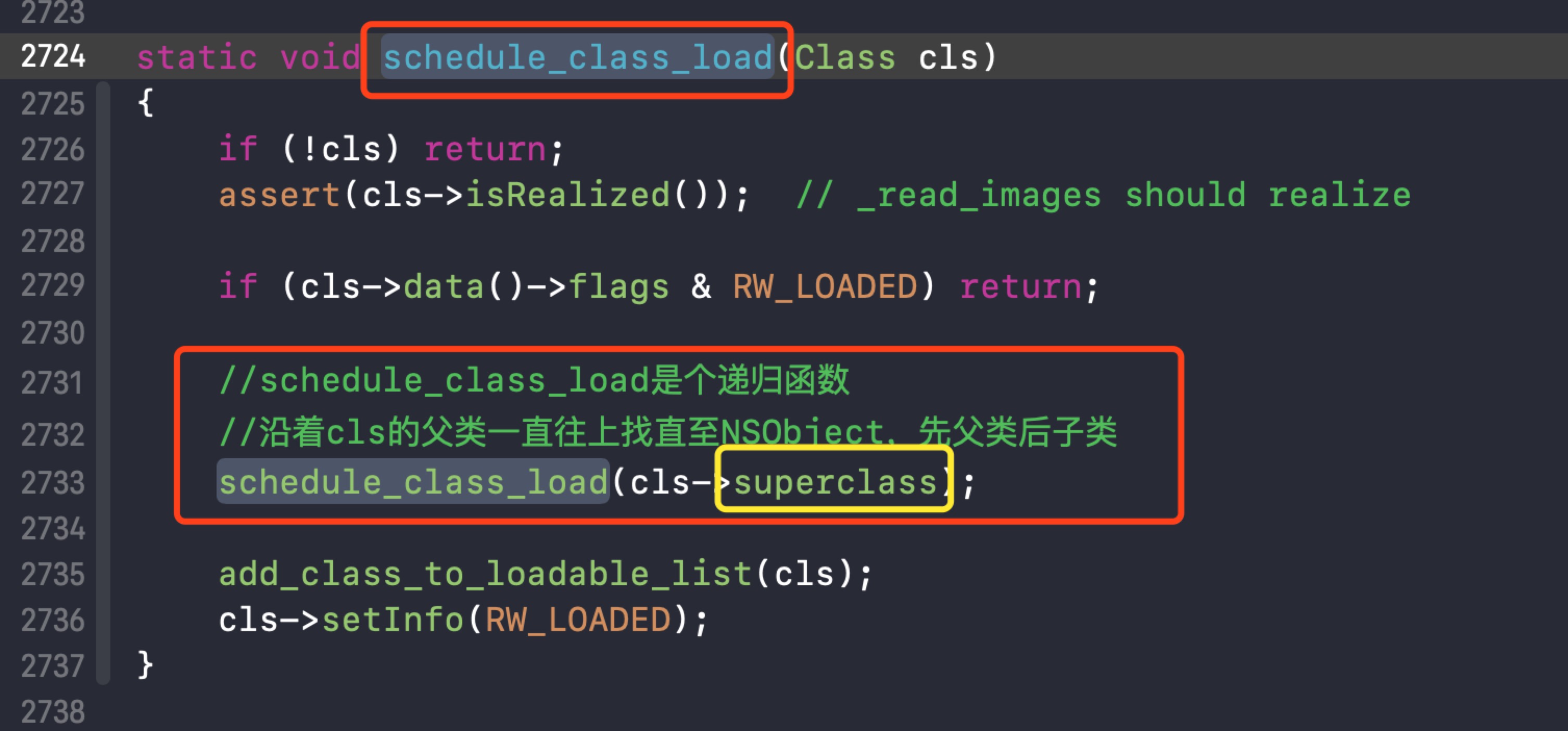
上面源码表明首先调用父类,然后子类!
对于重写了+load的类,load方法调用顺序是先编译的类的父类>先编译的类>后编译类的父类>后编译的类
总结:load调用顺序(+load)方法是根据方法地址直接调用,并不是经过objc_msgSend函数调用
1. 先调用类的+load
- 按照编译先后顺序调用(先编译先调用)
- 调用子类的+load之前会先调用父类的+load
2. 再调用分类的+load方法
- 按照编译先后顺序调用(先编译先调用)
三、initialize讲解
+initialize的方法在类第一次接受消息时会被调用
1. 例子
首先给ZXYStudent类和Person类覆盖+initialize,主要代码如下
//ZXYPerson
+ (void)initialize{ NSLog(@"Person + initialize");
} //ZXYPerson +Test
+ (void)initialize{ NSLog(@"Person (Test1) + initialize");
} //ZXYPerson+Eat
+ (void)initialize{ NSLog(@"Person (Eat) + initialize");
} //ZXYStudent
+ (void)initialize{ NSLog(@"Student + initialize");
} //ZXYStudent (Test)
+ (void)initialize{ NSLog(@"Student (Test) + initialize");
} //ZXYStudent (Eat)
+ (void)initialize{ NSLog(@"Student (Eat) + initialize");
}
此时运行程序,并没有发现打印,说明运行没有调用initialize
假如给ZXYPerson类发送消息,如下,打印出ZXYPerson+Test的initialize方法
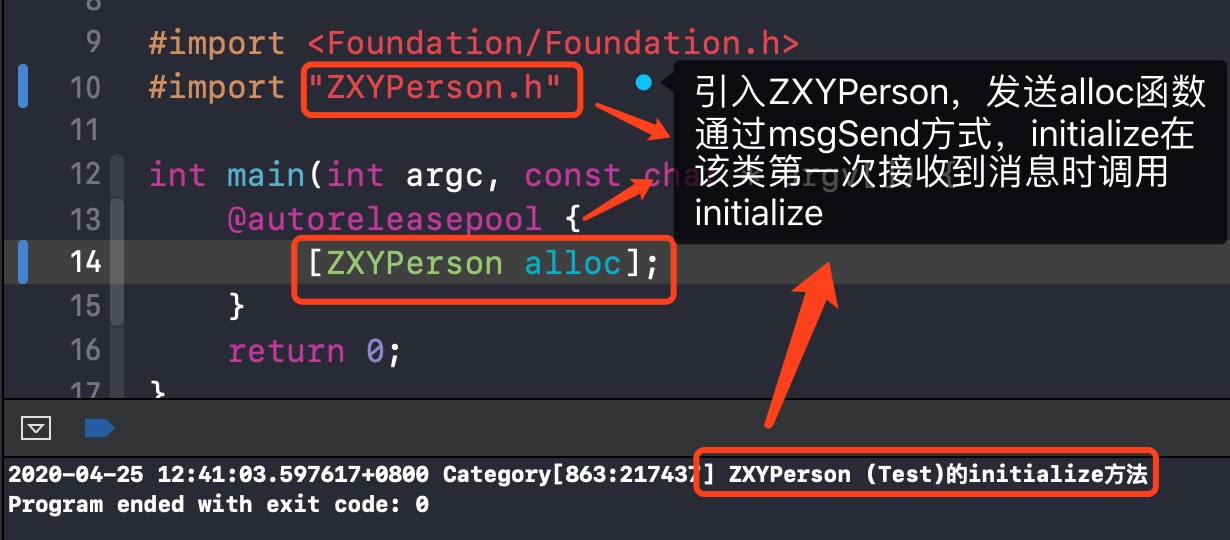
因为initialize是走runtime那套,通过msgSend()方式,所以先打印出ZXYPerson的分类方法,至于先打印出哪一个分类的initialize,看编译顺序(先编译后执行)

当使用ZXYPerson的子类ZXYStudent发送消息
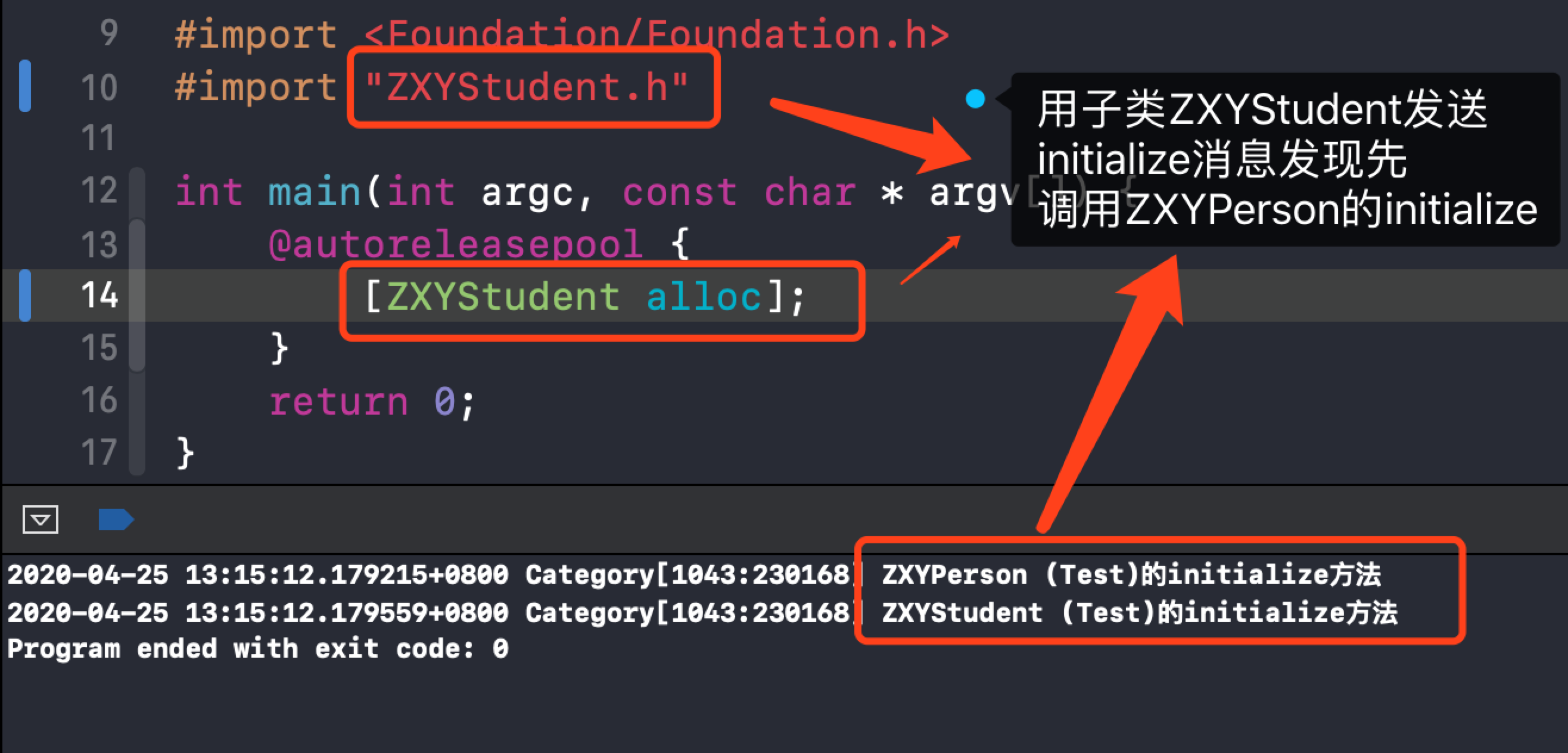
发现先调用ZXYPerson的分类,然后再调用子类的分类!也可以多写几行[ZXYStudent alloc],发现还是一样的打印,说明initialize仅仅在该类第一次收到消息才会调用,下面通过查看源码讲解其调用顺序!
2. 源码讲解
使用objc4查看initialize的源码解读过程主要在 objc-runtime-new.mm中
- class_getInstanceMethod
- lookUpImpOrNil
- lookUpImpOrForward
- _class_initialize
- callInitialize
- objc_msgSend(cls, SEL initialize)
1). 上面[ZXYStudent alloc]相当于objc_msgSend([ZXYStudent class], @selector(alloc))

2). 然后进行点击红色内容
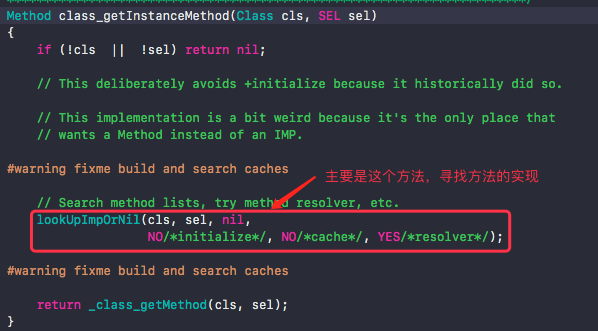
3). 点进去,然后继续寻找lookUpImpOrForward,源码主要内容
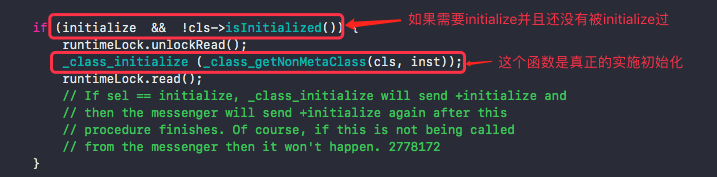
这样的源代码说明了每个类的+initialize方法只会调用一次
4). _class_initialize源代码如下
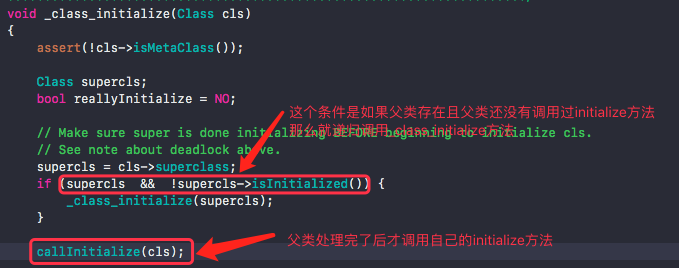
上面的源代码说明首先调用父类的+initialize,然后再调用子类的+initialize,就像上面先调用ZXYPerson的+initialize,然后再调用ZXYStudent的+initialize
5). 最后查看callInitialize
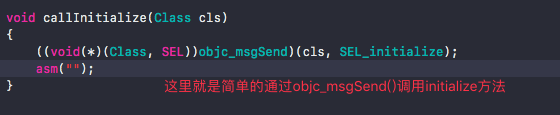
说明+initialize方法是通过msgSend()的方式进行调用
3. 总结
initialize调用顺序
首先调用父类的+initialize方法,然后再调用子类的+initialize
(先初始化父类,然后初始化子类,每个类只会被初始化1次)
通过上面总结下+initialize和+load区别
1. 调用方式
- load是根据函数地址直接调用
- initialize是通过objc_msgSend()调用
2. 调用时刻
- load是runtime加载类、分类的时候调用(只会被调用1次)
- initialize是类第一次接收到消息的时候调用,每一个类只会initialize一次(父类的initialize可能会调用多次-子类和分类都没有实现+initialize可能存在)
3. 调用顺序
load方法
- load方法先调用类的load(先编译的类优先调用load,调用子类的load之前,会优先调用父类)
- 然后调用分类的load,先编译的分类,会优先调用load方法
initialize
- 先初始化父类
- 再初始化子类
四. category能添加成员变量(实例变量)嘛?
默认情况下: 不能
因为类的内存布局在编译时候就已经确定了,Category是在运行时才加载的,无法更改早已确定的内存布局。
由于分类底层结构的限制,不能添加成员变量到分类中,但是可以通过关联(Associate)方式进行间接实现!
上面就是Category、load和initialize的讲解,希望对大家有所帮助!!!如果觉得写得还不错,给个赞吧!!!
Category、load、initialize 源码讲解的更多相关文章
- Qt5.5.0使用mysql编写小软件源码讲解---顾客信息登记表
Qt5.5.0使用mysql编写小软件源码讲解---顾客信息登记表 一个个人觉得比较简单小巧的软件. 下面就如何编写如何发布打包来介绍一下吧! 先下载mysql的库文件链接:http://files. ...
- 源码讲解 node+mongodb 建站攻略(一期)第二节
源码讲解 node+mongodb 建站攻略(一期)第二节 上一节,我们完成了模拟数据,这次我们来玩儿真正的数据库,mongodb. 代码http://www.imlwj.com/download/n ...
- Netty源码解读(二)-服务端源码讲解
简单Echo案例 注释版代码地址:netty 代码是netty的源码,我添加了自己理解的中文注释. 了解了Netty的线程模型和组件之后,我们先看看如何写一个简单的Echo案例,后续的源码讲解都基于此 ...
- 【源码讲解】Spring事务是如何应用到你的业务场景中的?
初衷 日常开发中经常用到@Transaction注解,那你知道它是怎么应用到你的业务代码中的吗?本篇文章将从以下两个方面阐述Spring事务实现原理: 解析并加载事务配置:本质上是解析xml文件将标签 ...
- laravel5源码讲解整理
来源:http://yuez.me/laravel-yuan-ma-jie-du/?utm_source=tuicool&utm_medium=referral 目录 入口文件 index.p ...
- jdk1.8 HashMap源码讲解
1. 开篇名义 jdk1.8中hashMap发生了一些改变,在之前的版本中hsahMap的组成是数组+链表的形式体现,而在1.8中则改为数组+链表+红黑树的形式实现,通过下面两张图来对比一下二者的不同 ...
- 深入Redis内部-Redis 源码讲解(转)
Redis作为 NoSQL 数据库的杰出代表,一直广受关注,其轻量级的敏捷架构,向来有存储中的瑞士军刀之称.下面推荐的一篇文章,从源码的角度讲解了Redis 的整个工作流程,是了解 Redis 流程的 ...
- Servlet基础(一) Servlet简介 关键API介绍及结合源码讲解
Servlet基础(一) Servlet基础和关键的API介绍 Servlet简介 Java Servlet是和平台无关的服务器端组件,它运行在Servlet容器中. Servlet容器负责Servl ...
- ESA2GJK1DH1K基础篇: STM32+GPRS(AT指令版)实现MQTT源码讲解(支持Air202,SIM800)
前言 注: 本程序发送心跳包,发送温湿度,返回控制数据这三个发送是单独的,有可能凑到一起发. 由于本身程序就是复杂性的程序,所以这节程序没有使用中断发送,没有使用环形队列发送,为了避免多条消息可能凑到 ...
随机推荐
- 粒子群优化算法(PSO)之基于离散化的特征选择(FS)(一)
欢迎大家关注我们的网站和系列教程:http://www.tensorflownews.com/,学习更多的机器学习.深度学习的知识! 作者:Geppetto 在机器学习中,离散化(Discretiza ...
- 百道Python面试题实现,搞定Python编程就靠它
对于一般的机器学习求职者而言,最基础的就是掌握 Python 编程技巧,随后才是相关算法或知识点的掌握.在这篇文章中,我们将介绍一个 Python 练习题项目,它从算法练习题到机试实战题提供了众多问题 ...
- 本地缓存Ehcache
1,什么是Ehcache Ehcache是纯java的开源缓存框架,具有快速.精干等特点,是Hibernate中默认的CacheProvider.它主要面向通用缓存.Java EE和轻量级容器, ...
- [noip2016]蚯蚓<单调队列+模拟>
题目链接:https://vijos.org/p/2007 题目链接:https://www.luogu.org/problem/show?pid=2827#sub 说实话当两个网站给出AC后,我很感 ...
- Hadoop入门之hdfs
大数据技术开篇之Hadoop入门[hdfs] 学习都是从了解到熟悉的过程,而学习一项新的技术的时候都是从这个技术是什么?可以干什么?怎么用?如何优化?这几点开始.今天这篇文章分为两个部分.一. ...
- Blazor入门笔记(6)-组件间通信
1.环境 VS2019 16.5.1.NET Core SDK 3.1.200Blazor WebAssembly Templates 3.2.0-preview2.20160.5 2.简介 在使用B ...
- 《Three.js 入门指南》3.1.1 - 基本几何形状 -圆柱体(CylinderGeometry)
3.1 基本几何形状 圆柱体(CylinderGeometry) 构造函数: THREE.CylinderGeometry(radiusTop, radiusBottom, height, radiu ...
- js中常见的数据加密与解密的方法
加密在我们前端的开发中也是经常遇见的.本文只把我们常用的加密方法进行总结.不去纠结加密的具体实现方式(密码学,太庞大了). 常见的加密方式 常见的加密算法基本分为这几类, 线性散列算法(签名算法)MD ...
- 原生js弹力球
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- HDU1158:Employment Planning(暴力DP)
Employment Planning Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Othe ...