url,解释器,响应器,版本控制,分页
路由控制
-基本路由写法:咱们一直写的
from django.conf.urls import url
from app01 import views
urlpatterns = [
url(r'^books/$', views.BookView.as_view()),
url(r'^books/(?P<pk>\d+)$', views.BookDetailView.as_view()),
]
class BookView(APIView):
def get(self, request):
book_list = models.Book.objects.all()
bs = BookSerializers(book_list, many=True)
return Response(bs.data)
def post(self, request):
# 添加一条数据
print(request.data)
bs=BookSerializers(data=request.data)
if bs.is_valid():
bs.save() # 生成记录
return Response(bs.data)
else:
return Response(bs.errors)
class BookDetailView(APIView):
def get(self,request,pk):
book_obj=models.Book.objects.filter(pk=pk).first()
bs=BookSerializers(book_obj,many=False)
return Response(bs.data)
def put(self,request,pk):
book_obj = models.Book.objects.filter(pk=pk).first()
bs=BookSerializers(data=request.data,instance=book_obj)
if bs.is_valid():
bs.save() # update
return Response(bs.data)
else:
return Response(bs.errors)
def delete(self,request,pk):
models.Book.objects.filter(pk=pk).delete()
return Response("")
-第二种写法(必须继承只要继承了ViewSetMixin):
from app01 import views
urlpatterns = [
url(r'^admin/', admin.site.urls),
获取所有出版社,以及新增数据
url(r'publish/$',views.PublishView.as_view({'get':'list','post':'create'})),
获取单个数据,删除单个数据,更新单个数据
url(r'publish/(?P<pk>\d+)$',views.PublishView.as_view({'get':'retrieve','delete':'destroy','put':'update'}))
]
注意:
1.'get','post','delete','put',''是method提交数据的方法,list,create,retrieve,destroy,update是内部对应的方法,可以在视图类中重写这些方法
2.五个方法,两个路由
from rest_framework .serializers import ModelSerializer
from app01 import models
class PublishSerializers():
class Meta:
model=models.Publish
fields='__all__'
serializer.py
from django.db import models # Create your models here.
class Publish(models.Model):
name=models.CharField(max_length=32)
city = models.CharField(max_length=64)
models.py
from rest_framework.viewsets import ModelViewSet
class PublishView(ModelViewSet):
queryset=models.Publish.objects.all()
serializer_class=PublishSerializers
#源码 class ModelViewSet(mixins.CreateModelMixin,
mixins.RetrieveModelMixin,
mixins.UpdateModelMixin,
mixins.DestroyModelMixin,
mixins.ListModelMixin,
GenericViewSet):
"""
A viewset that provides default `create()`, `retrieve()`, `update()`,
`partial_update()`, `destroy()` and `list()` actions.
"""
pass
1.ModelViewSet中继承了ViewSetMixin所有继承了GenericViewSet,GenericViewSet继承了ViewSetMixin
2.ViewSetMixin中action必须要传值,不然会报错(action也就是传入的字典)
3.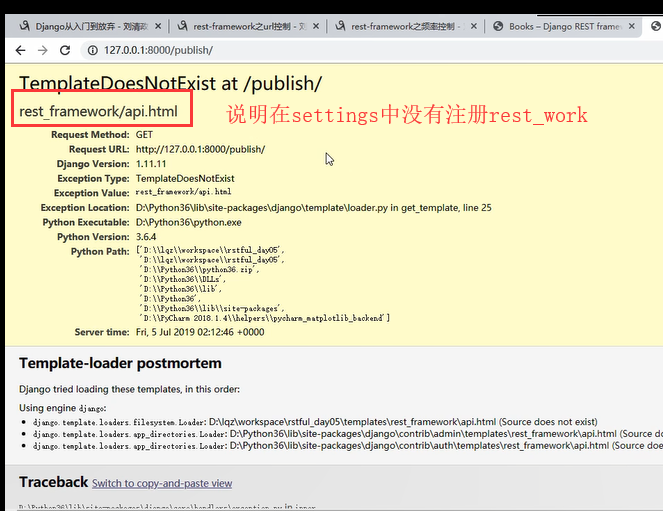
4.有名分组,传入的关键字必须是pk,这个内部固定死的
完美分割线
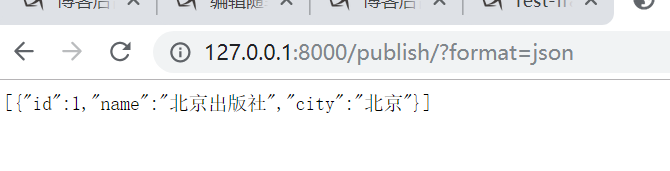
通过format=json获取到json格式的字符串
也有另外一种方式(就是需要配置路由)
url(r'^publish\.(?P<format>\w+)$', views.PublishView.as_view({'get':'list','post':'create'}))
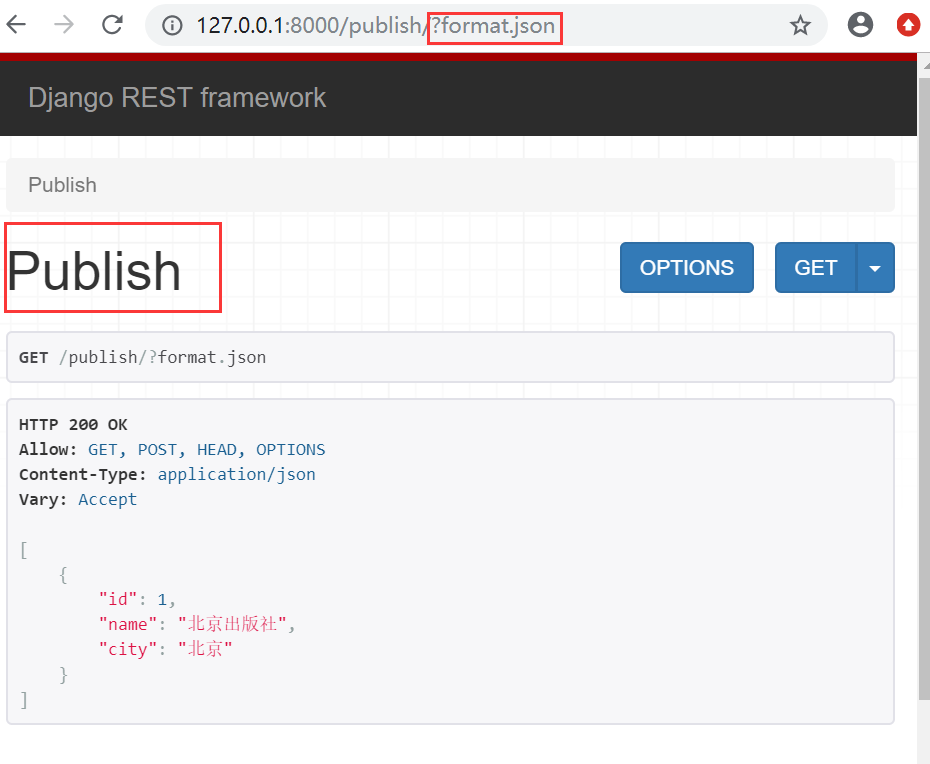
-第三种(自动生成路由,必须继承ModelViewSet):
-SimpleRouter 自动生成两条路由
from django.conf.urls import url,include
from django.contrib import admin
from app01 import views
from rest_framework.routers import SimpleRouter
router = SimpleRouter()
router.register('publish',views.PublishView) urlpatterns = [
url(r'^admin/', admin.site.urls),
# url(r'^publish/$',views.PublishView.as_view({'get':'list','post':'create'})),
# url(r'^publish/(?P<pk>\d+)',views.PublishView.as_view({'get':'retrieve','delete':'destroy','put':'update'})),
url(r'',include(router.urls))
from rest_framework.viewsets import ModelViewSet
class PublishView(ModelViewSet):
queryset=models.Publish.objects.all()
serializer_class=PublishSerializers
-DefaultRouter自动生成四条路由
from django.conf.urls import url,include
from app01 import views
from rest_framework import routers
router=routers.DefaultRouter()
# 两个参数,一个是匹配的路由,一个是视图中写的CBV的类
router.register('publish',views.PublishView)
urlpatterns = [
# http://127.0.0.1:8000/publish/format=json(渲染器通过这个判断,返回渲染的页面)
# url(r'^publish/', views.PublishView.as_view({'get':'list','post':'create'})),
# http://127.0.0.1:8000/publish.json(渲染器通过这个判断,返回渲染的页面)
# url(r'^publish\.(?P<format>\w+)$', views.PublishView.as_view({'get':'list','post':'create'})), # 可以用 以下方式访问
# 1 http://127.0.0.1:8000/publish/
# 2 http://127.0.0.1:8000/publish.json
# 3 http://127.0.0.1:8000/publish/3
# 4 http://127.0.0.1:8000/publish/3.json
url(r'',include(router.urls))
]
from rest_framework.viewsets import ModelViewSet
class PublishView(ModelViewSet):
queryset=models.Publish.objects.all()
serializer_class=PublishSerializers
解析器
-在取某个值之前,先反射看一下有没有,有的话直接返回,如果没有,再去执行获取这个值的方法
一开始request.data去获取值,先看看你之前是否用过,用过直接返回,没用过就去body取出做解析,所以入口是request.data
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework.parsers import JSONParser,FormParser,MultiPartParser
from rest_framework.request import Request
class Test(APIView):
parser_classes = [JSONParser,]
def post(self,request):
print(request.data)
print(type(request.data))
return Response
从Request中找到data
源码
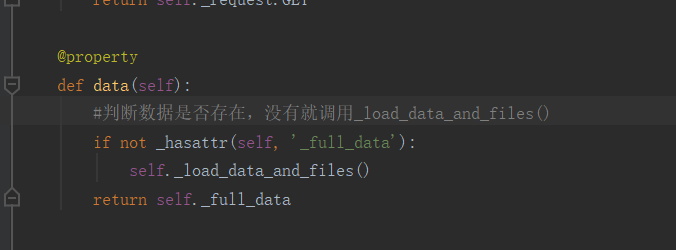
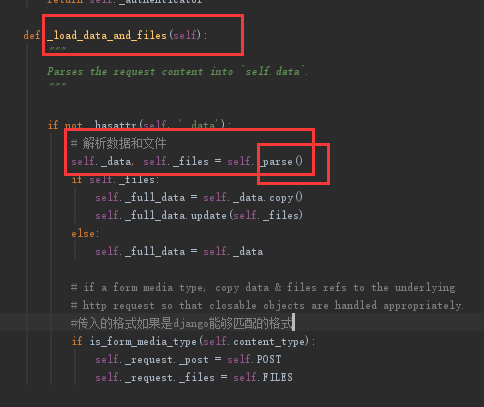
parser就是我在视图类中parser_classes=[JSONParser,]JSONParser类产生的对象
然后调用parser对象方法进行解析(以下是在Requst类中的_parser方法中找到的)

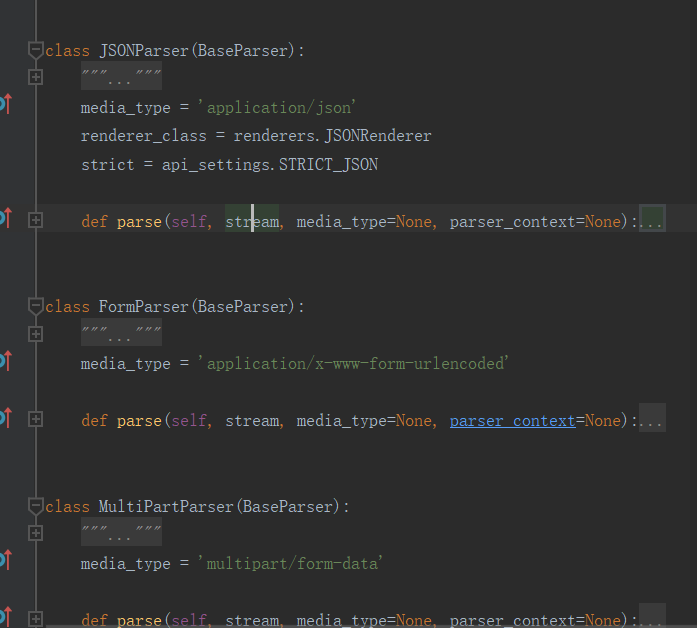
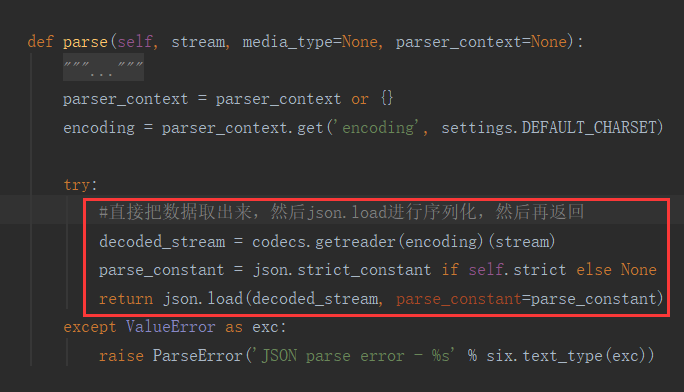
这些类中都有一个parse方法,称之为鸭子类型,
不管返回的是谁的对象,直接调用它们类中的parser方法传入该传的参数就能做解析
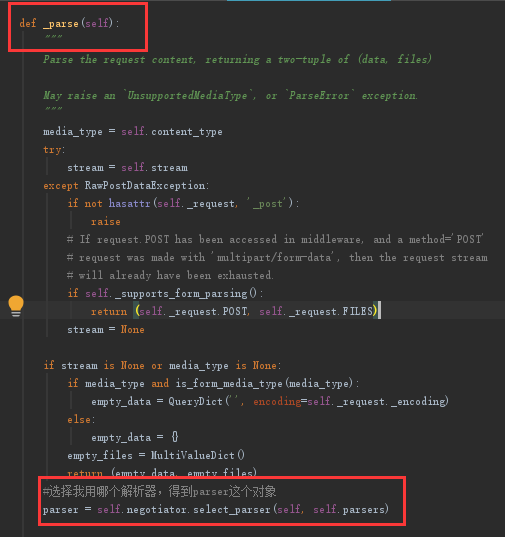
Request类中_parser中的parser = self.negotiator.select_parser(self,self.parsers)中的negotiator是Request初始化对象的时候产生并传入值,而Request是在APIVeiw 的dispatch中初始化对象的
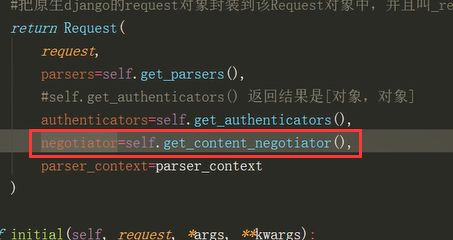
Request类中_parser中的parser = self.negotiator.select_parser(self,self.parsers)中的self.parsers
是Request初始化对象的时候产生并传入值,而Request是在APIVeiw 的dispatch中初始化对象的
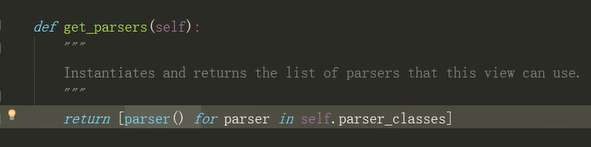
而parsers = self.get_parsers()中的get_parsers,就是传入视图中定义的列表中的类名
然后parser = self.negotiator.select_parser(self,self.parsers)中的self.parsers是所有解析器,然后选择一个返回,根据Request对象request请求编码格式传入
小总结:
-解析器(一般不需要动,项目最开始全局配置一下就可以了)
-作用是控制我的视图类能够解析前端传过来的格式是什么样的
-全局使用:
在setting中配置:
REST_FRAMEWORK = {
"DEFAULT_PARSER_CLASSES":[
'rest_framework.parsers.JSONParser',
] }
-全局使用:
-在视图类中:
parser_classes=[JSONParser,] -源码流程:
-当调用request.data的时候去执行解析方法----》根据传过来的编码方式选择一个解析器对象,调用解析器对象的parser方法完成解析
响应器
-响应器
-from rest_framework.renderers import JSONRenderer,BrowsableAPIRenderer
-不用动,就用全局配置即可
-全局使用:
-在setting中配置
'DEFAULT_RENDERER_CLASSES':[xxx,xxx]
-局部使用:
-在视图类中配置:
renderer_classes = [JSONRenderer, BrowsableAPIRenderer]
版本控制
在restful规范当中,版本号可以放在路径当中,还可以放在请求头当中
直接使用内置,
内置的版本控制类

from rest_framework.versioning import QueryParameterVersioning,AcceptHeaderVersioning,NamespaceVersioning,URLPathVersioning #基于url的get传参方式:QueryParameterVersioning------>如:/users?version=v1
#基于url的正则方式:URLPathVersioning------>/v1/users/
#基于 accept 请求头方式:AcceptHeaderVersioning------>Accept: application/json; version=1.0
#基于主机名方法:HostNameVersioning------>v1.example.com
#基于django路由系统的namespace:NamespaceVersioning------>example.com/v1/users/
局部使用
#在CBV类中加入
versioning_class = URLPathVersioning
四 全局使用
REST_FRAMEWORK = {
'DEFAULT_VERSIONING_CLASS':'rest_framework.versioning.QueryParameterVersioning',
'DEFAULT_VERSION': 'v1', # 默认版本(从request对象里取不到,显示的默认值)
'ALLOWED_VERSIONS': ['v1', 'v2'], # 允许的版本
'VERSION_PARAM': 'version' # URL中获取值的key
}
示例
基于正则的方式:
from django.conf.urls import url, include
from web.views import TestView urlpatterns = [
url(r'^(?P<version>[v1|v2]+)/test/', TestView.as_view(), name='test'),
]
urls.py
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework.versioning import URLPathVersioning class TestView(APIView):
versioning_class = URLPathVersioning def get(self, request, *args, **kwargs):
# 获取版本
print(request.version)
# 获取版本管理的类
print(request.versioning_scheme) # 反向生成URL
reverse_url = request.versioning_scheme.reverse('test', request=request)
print(reverse_url) return Response('GET请求,响应内容')
views.py
# 基于django内置,反向生成url
from django.urls import reverse
url2=reverse(viewname='ttt',kwargs={'version':'v2'})
print(url2)
分页
批量添加(了解)
class PublishView(APIView):
versioning_class = URLPathVersioning
parser_classes = [JSONParser,] def get(self,request,*args,**kwargs):
li = []
for i in range(100):
li.append(models.Publish(name='%s出版社'%i,city='%s城市'%i))
models.Publish.objects.bulk_create(li)
return Response()
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^(?P<version>[v1|v2]+)/test/', views.PublishView.as_view())
]
简单分页(查看第n页,每页显示n条)
# 一 基本使用:url=url=http://127.0.0.1:8000/pager/?page=2&size=3,size无效
from rest_framework.versioning import URLPathVersioning
from rest_framework.pagination import PageNumberPagination,LimitOffsetPagination,CursorPagination
class Page(APIView):def get(self,request,*args,**kwargs): #查询出所有的数据
ret = models.Publish.objects.all()
#实例化产生一个普通分页对象
page=PageNumberPagination()
#ret_page是返回分页之后的数据(列表存放着我一个个数据),已经是分好页了
ret_page = page.paginate_queryset(ret,request,self)
#序列化
pub_ser = serializer.PublishSerializers(ret_page,many=True)
#去settings中配置每页显示多少条
return Response(pub_ser.data)
REST_FRAMEWORK = {
"DEFAULT_PARSER_CLASSES":[
'rest_framework.parsers.JSONParser',
],
'PAGE_SIZE':2 #表示每页显示两条
}
偏移分页(在第n个位置,向后查看n条数据)
# http://127.0.0.1:8000/pager/?offset=4&limit=3
from rest_framework.pagination import LimitOffsetPagination
# 也可以自定制,同简单分页
class Pager(APIView):
def get(self,request,*args,**kwargs):
# 获取所有数据
ret=models.Book.objects.all()
# 创建分页对象
page=LimitOffsetPagination()
# 在数据库中获取分页的数据
page_list=page.paginate_queryset(ret,request,view=self)
# 对分页进行序列化
ser=BookSerializer1(instance=page_list,many=True)
# return page.get_paginated_response(ser.data)
return Response(ser.data)
CursorPagination(加密分页,只能看上一页和下一页,速度快)
思考:不重写类,修改类属性?
from rest_framework.pagination import CursorPagination
# 看源码,是通过sql查询,大于id和小于id
class Pager(APIView):
def get(self,request,*args,**kwargs):
# 获取所有数据
ret=models.Book.objects.all()
# 创建分页对象
page=CursorPagination()
page.ordering='nid'
# 在数据库中获取分页的数据
page_list=page.paginate_queryset(ret,request,view=self)
# 对分页进行序列化
ser=BookSerializer1(instance=page_list,many=True)
# 可以避免页码被猜到
return page.get_paginated_response(ser.data)
小总结:
-分页
1 常规分页
-基本使用:
-page=PageNumberPagination实例化产生对象
-返回值=page.paginate_queryset(ret,request,self):ret是要分页的所有数据,
-再序列化,序列化该返回值
-四个参数
#每页显示多少条
page.page_size=3
#查询指定查询哪一页的key值
page.page_query_param='xxx' #前端控制每页显示多少条的查询key值比如size=9,表示一页显示9条
page.page_size_query_param='size'
#控制每页最大显示多少,size如果传100,最多也是显示10
page.max_page_size=10
2 偏移分页
-基本使用:
-page=LimitOffsetPagination实例化产生对象
-返回值=page.paginate_queryset(ret,request,self):ret是要分页的所有数据,
-再序列化,序列化该返回值 -四个参数:
#从标杆位置往后取几个,默认取3个,我可以指定
page.default_limit=3
#每次取得条数
page.limit_query_param='limit'
#标杆值,现在偏移到哪个位置,如果offset=6 表示当前在第6条位置上,往后取
page.offset_query_param='offset'
#最大取10条
page.max_limit=10
3 cursor游标方式
-基本使用:
-page=CursorPagination实例化产生对象
-返回值=page.paginate_queryset(ret,request,self):ret是要分页的所有数据,
-再序列化,序列化该返回值 -三个参数:
#每页显示的大小
page.page_size=3
#查询的key值
三种编码格式:urlencoded,formdata,json
-urlencoded:在body体中的格式是:name=lqz&age=18&wife=liuyifei
-formdata:在body体中的格式数据部分跟文件部分有区分
-json格式:在body体中就是json格式
page.cursor_query_param='cursor'
# 按什么排序
page.ordering='id'
-注意:get_paginated_response:调用这个方法返回的数据中会有总条数,上一页地址,下一页地址
url,解释器,响应器,版本控制,分页的更多相关文章
- DRF url控制 解析器 响应器 版本控制 分页(常规分页,偏移分页,cursor游标分页)
url控制 第二种写法(只要继承了ViewSetMixin) url(r'^pub/$',views.Pub.as_view({'get':'list','post':'create'})), #获取 ...
- DjangoRestFramework学习三之认证组件、权限组件、频率组件、url注册器、响应器、分页组件
DjangoRestFramework学习三之认证组件.权限组件.频率组件.url注册器.响应器.分页组件 本节目录 一 认证组件 二 权限组件 三 频率组件 四 URL注册器 五 响应器 六 分 ...
- day91 DjangoRestFramework学习三之认证组件、权限组件、频率组件、url注册器、响应器、分页组件
DjangoRestFramework学习三之认证组件.权限组件.频率组件.url注册器.响应器.分页组件 本节目录 一 认证组件 二 权限组件 三 频率组件 四 URL注册器 五 响应器 六 分 ...
- day 89 DjangoRestFramework学习三之认证组件、权限组件、频率组件、url注册器、响应器、分页组件
DjangoRestFramework学习三之认证组件.权限组件.频率组件.url注册器.响应器.分页组件 本节目录 一 认证组件 二 权限组件 三 频率组件 四 URL注册器 五 响应器 六 分 ...
- jnhs 无法提交断点LineBreakpoint hibernate4CURD : -1, 原因是: 找不到 URL 'file:/E:/版本控制/Design-java/hibernate4CURD/' 的源根目录。请验证项目源的设置。
无法提交断点LineBreakpoint hibernate4CURD : -1, 原因是: 找不到 URL 'file:/E:/版本控制/Design-java/hibernate4CURD/' 的 ...
- 20.DjangoRestFramework学习三之认证组件、权限组件、频率组件、url注册器、响应器、分页组件
一 认证组件 1. 局部认证组件 我们知道,我们不管路由怎么写的,对应的视图类怎么写的,都会走到dispatch方法,进行分发, 在咱们看的APIView类中的dispatch方法的源码中,有个sel ...
- 5 解析器、url路由控制、分页、渲染器和版本
1 数据解析器 1 什么是解析器 相当于request 中content-type 对方传什么类型的数据,我接受什么样的数据:怎样解析 无论前面传的是什么数据,都可以解开 例如:django不能解析j ...
- 动态多条件查询分页以及排序(一)--MVC与Entity Framework版url分页版
一.前言 多条件查询分页以及排序 每个系统里都会有这个的代码 做好这块 可以大大提高开发效率 所以博主分享下自己的6个版本的 多条件查询分页以及排序 二.目前状况 不论是ado.net 还是EF ...
- EasyUI DataGrid 使用(分页,url数据获取,data转json)
EasyUI算是比较有名的,搜一下网上的资料也比较多,具体的参数,下载地址我就不写了 平常也不怎么写文章,大部分都是代码,有不能运行的可以直接评论回复 有可能遇到的问题: json数据格式,这个要仔细 ...
随机推荐
- Proto3:C++ API概览
包名 说明 google::protobuf Protocol Buffer运行时库核心组件. google::protobuf::io I/O操作辅助类. google::protobuf::uti ...
- WEB前端工程师简历
一个热爱前端的工程师 关于我 我的作品 ZENRON 关于我 求职意向 作品集 技术掌握 我的经历 联系我 关于我 英语/CET-4 坐标/苏州 状态/求职 我叫Zenron, 现居住苏州, 是一名前 ...
- TF Notes (5), GRU in Tensorflow
小筆記. Tensorflow 裡實作的 GRU 跟 Colah's blog 描述的 GRU 有些不太一樣. 所以做了一下 TF 的 GRU 結構. 圖比較醜, 我盡力了- XD TF 的 GRU ...
- 联想拯救者y7000使用体验
前言 我以前的电脑是在电商平台买的二手电脑,期间觉得软件的运行速度慢,又在网上买了一个128G的固态硬盘安装上.就从大一到大四上学期这么使用了三年半的时间.因为自己需要运行一些吃内存的软件,而我的这个 ...
- 事务Transaction
目录 为什么写这系列的文章 事务概念 ACID 并发事务导致的问题 脏读(Dirty Read) 非重复读(Nonrepeatable Read) 幻读(Phantom Reads) 丢失修改(Los ...
- async/await实现图片的串行、并行加载
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- sql--自链接(推荐人)
表1: 需求:查出推荐人,和被推荐人 1.通过group_concat函数和分组,查出每个id推荐的人有哪些 select group_concat(u_name, u_id) as referce_ ...
- python学习(二)之turtle库绘图
今天是三月七号,也就是女生节,或者女神节.不知道你是不是有自己喜欢的女孩子,在这里你可以用turtle库绘制一朵玫瑰花,送给你喜欢的姑娘.(拉到最后有惊喜哦)但在画这朵玫瑰花之前,先来一个基础的图形, ...
- Rust入坑指南:智能指针
在了解了Rust中的所有权.所有权借用.生命周期这些概念后,相信各位坑友对Rust已经有了比较深刻的认识了,今天又是一个连环坑,我们一起来把智能指针刨出来,一探究竟. 智能指针是Rust中一种特殊的数 ...
- docker 搭建本地私有仓库
1.使用registry镜像创建私有仓库 安装docker后,可以通过官方提供的 registry 镜像来简单搭建一套本地私有仓库环境: docker run -d -p : registry: 这将 ...