Django模型层ORM学习笔记
一. 铺垫
1. 连接Django自带数据库sqlite3
之前提到过Django自带一个叫做sqlite3的小型数据库,当我们做本地测试时,可以直接在sqlite3上测试。不过该数据库是小型的,在有些细节可能体验不大好,比如用ORM用双下划线查询语法时,使用__contains和__icontains的结果是一样的,因为sqlite3无论怎么样都不区分大小写,而且它还会自动把日期格式的字段转为时间戳(该体验贼差)。
不过除此之外还好,目前也没发现其他问题,做一些数据的小测试还是绰绰有余的。
1.1 项目settings.py文件
连接其他数据库时,我们需要修改settings.py里面的相关配置,不过默认的配置就是sqlite3的,所以我们不需要修改涉及数据库的配置。
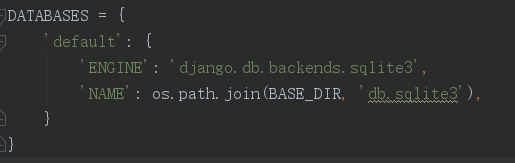
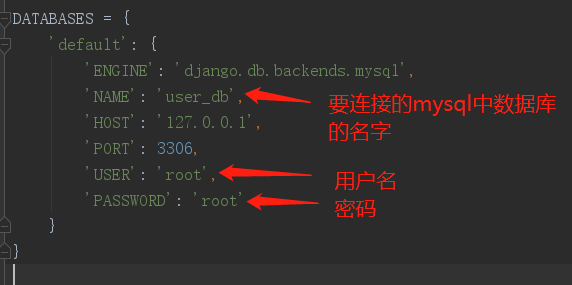
回忆一下,连接其他数据库时(以连接myqsl数据库为例),应该修改为以下配置:
1.2 修改应用下或项目下的的__init__.py文件
跟连接其他数据库一样,需要在__init__.py中加入替换操作数据库的模块的语句:
- import pymysql
- pymysql.install_as_MySQLdb()
1.3 连接sqlite3数据库
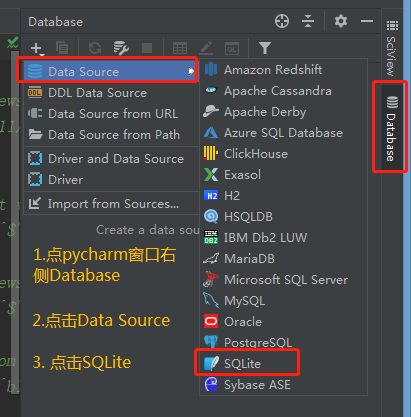
选择连接sqlite3数据库:
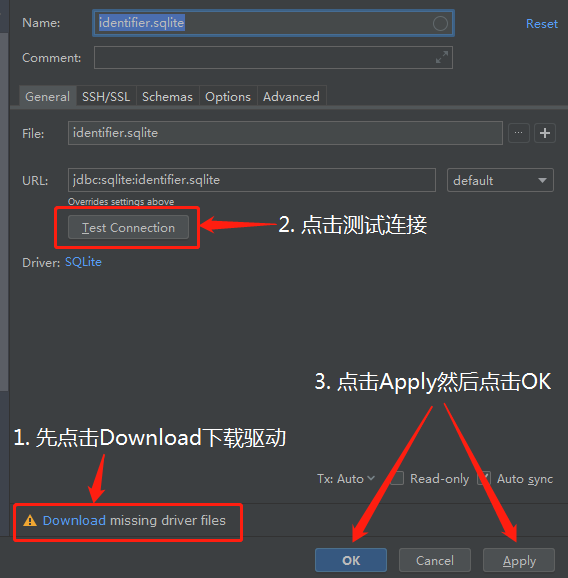
安装驱动,测试连接成功后点击OK连接sqlite数据库:
1.3步骤执行完毕后,我们可以将下图显示的那个数据库删除(当然留着也没事)。
1.4 在模型层中写几个映射数据库中表的类
- from django.db import models
- # Create your models here.
- class User(models.Model):
- name = models.CharField(max_length=32)
- age = models.IntegerField()
- register_time = models.DateField()
1.5 执行数据库迁移命令(可以使用Tools中的Run manage.py Task)
- #pycharm下方点击Terminal打开命令行窗口,执行以下两句命令
- python3 manage.py makemigrations
- python3 manage.py migrate
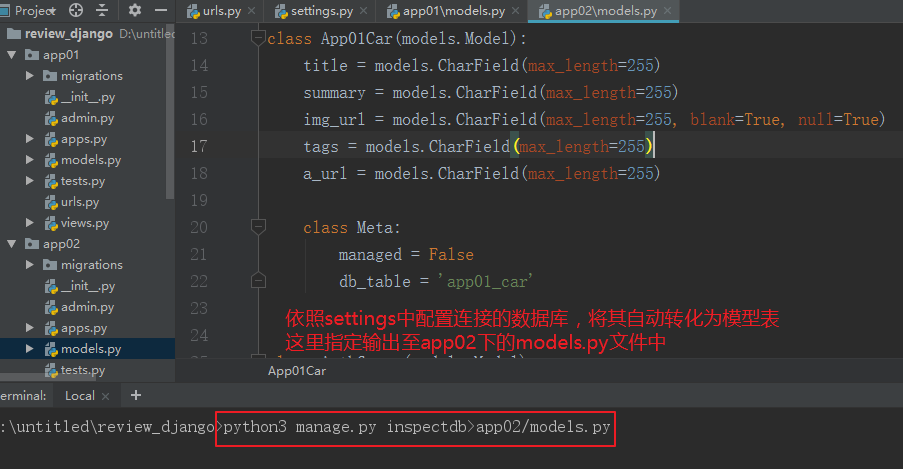
实际上也可以根据数据库中的表逆向在models中生成模型表:
- python3 manage.py inspectdb>app02/models.py
执行完数据库迁移命令后,我们会发现项目中出现了db.sqlite3数据库,直接双击打开:
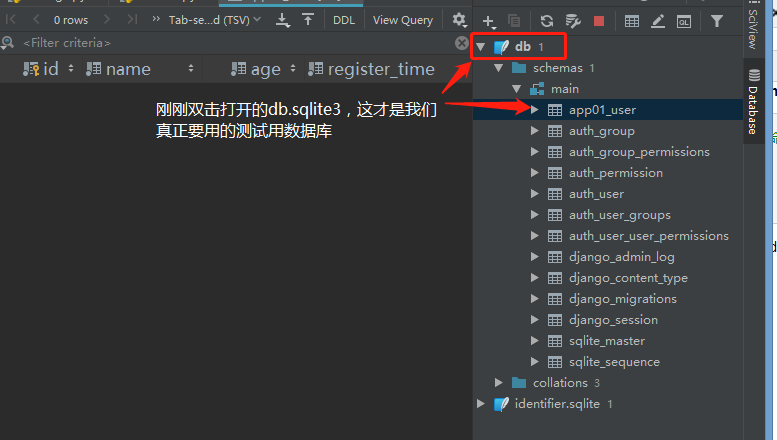
1.6 数据库sqlite3连接完成
2. 测试ORM的准备工作
数据库连接完毕后,我们可以选择新建.py文件或者使用应用文件夹下自带的tests.py来导入模型层models.py中的类来熟悉一下ORM语句,不过在这之前要做一些准备工作,不然当你通过ORM操作数据库时会报错。
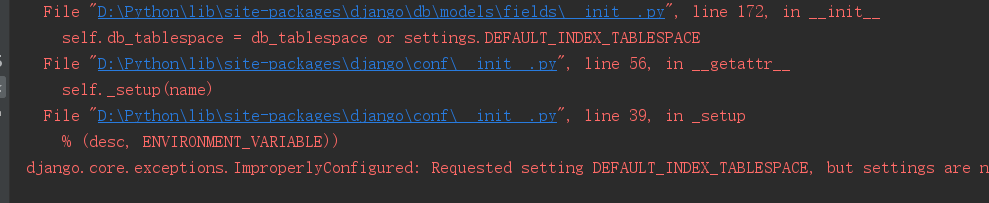
我们直接使用应用文件夹下自带的tests.py文件测试ORM。首先输入以下语句(前几行可以从manage.py中复制)。
- from django.test import TestCase
- # Create your tests here.
- import os
- if __name__ == "__main__":
- os.environ.setdefault("DJANGO_SETTINGS_MODULE", "day58.settings")
- import django
- django.setup()
- # 以上语句固定写法,接下来写导入models模块的语句
- from app01 import models
- # 从这开始正常写ORM操作数据库的语句即可
3. 查看ORM操作数据库内部走的mysql语句
当我们操作数据库拿回来的是QuerySet对象是,我们可以通过QuerySet对象.query查看内部的sql语句,那么返回的不是QuerySet对象时该怎么做呢?只需要在settings.py中找个地方将下面语句放着即可(运用日志)。
- 配置文件配置参数查看所有orm操作内部的sql语句
- LOGGING = {
- 'version': 1,
- 'disable_existing_loggers': False,
- 'handlers': {
- 'console':{
- 'level':'DEBUG',
- 'class':'logging.StreamHandler',
- },
- },
- 'loggers': {
- 'django.db.backends': {
- 'handlers': ['console'],
- 'propagate': True,
- 'level':'DEBUG',
- },
- }
- }
二. ORM单表查询、双下划线查询
为了更好的了解ORM对数据库的操作,我们选择连接mysql数据库,毕竟sqlite3还是有点小瑕疵的。
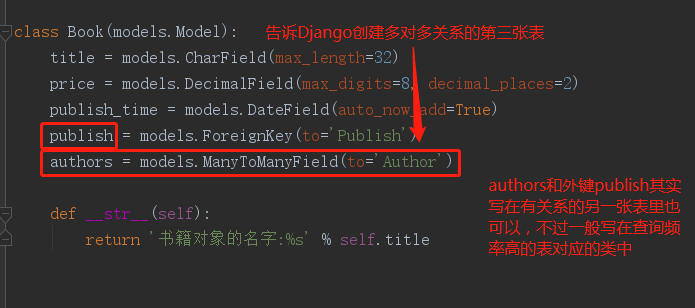
- from django.db import models
- # Create your models here.
- class Book(models.Model):
- title = models.CharField(max_length=32)
- price = models.DecimalField(max_digits=8, decimal_places=2)
- publish_time = models.DateField(auto_now_add=True)
- publish = models.ForeignKey(to='Publish')
- authors = models.ManyToManyField(to='Author')
- class Publish(models.Model):
- name = models.CharField(max_length=32)
- addr = models.CharField(max_length=32)
- email = models.EmailField()
- class Author(models.Model):
- name = models.CharField(max_length=32)
- age = models.IntegerField()
- author_detail = models.OneToOneField(to='AuthorDetail')
- class AuthorDetail(models.Model):
- phone = models.CharField(max_length=32)
- addr = models.CharField(max_length=32)
models.py中创建的类
ORM有很多常用字段,其中字段DateField的参数有auto_now跟auto_now_add,如果我们配置了这两个参数中的一个,创建数据对象时DateField字段会自动创建,无需我们传值。配置auto_now_add=True,创建数据记录的时候会把当前时间添加到数据库,之后就不在变化。配置上auto_now=True,每次更新数据记录的时候会更新该字段。友情提示,DateFIeld和DateTImeField可以直接接收datetime对象。
ForeignKey有to_field参数,可以指定你想跟一张表的什么字段建立外键,不写默认是id。
当使用数据对象进行数据的save()和delete()时,实际上找的是类Model中的方法(属性与方法的查找顺序),所以我们可以通过重写save、delete方法来对数据对象保存和删除的过程加以限制。
1. 单表查询
1.1 新增数据
- # 第一种:有返回值,并且就是当前被创建的数据对象
- modles.Publish.objects.create(name='',addr='',email='')
- # 第二种:先实例化产生对象,然后调用save方法保存
- book_obj = models.Publish(name='',addr='',email='')
- book_obj.save()
1.2 修改数据
- # 基于数据对象
- user_obj = models.User.objects.filter(name='jason').first()
- user_obj.age = 17
- user_obj.save()
- # 基于queryset对象
- models.User.objects.filter(name='kevin').update(age=66)
1.3 删除数据
- # 基于数据对象
- # user_obj = models.User.objects.filter(name='owen').first()
- # user_obj.delete()
- # 基于queryset对象
- models.User.objects.filter(name='egon').delete()
1.4 查询数据
之前常用的查询是all(惰性查询)查所有及filter条件查询,其中filter条件查询有多个条件时,各条件是and的关系。
- models.User.objects.filter(name='egon', age=18) # name='egon' and 'age'=18
其实查询数据能用到的方法一共有13个(objects对象和QuerySet对象方法),最好都记住。然后QuerySet对象能够无限制的点QuerySet方法(后面点方法可能会没有提示,别慌,继续手打):
- # 在过滤得到的QuerySet对象的基础上再进行过滤,依次类推
- models.User.objects.filter(过滤条件1).filter(过滤条件2).order_by(排序依据的字段名).reverse()
- # reverse方法使用的前提是QuerySet对象被排序过,order_by是排序(排序依据的字段名前加-号即是反向排序)
- <1> all(): #查询所有结果
- <2> filter(**kwargs): #它包含了与所给筛选条件相匹配的对象
- <3> get(**kwargs): #返回与所给筛选条件相匹配的对象,返回结果有且只有一个,如果符合筛选条件的对象超过一个或者没有都会抛出错误。
- <4> exclude(**kwargs): #它包含了与所给筛选条件不匹配的对象
- <5> order_by(*field): #对查询结果排序('-id')/('price')
- <6> reverse(): #对查询结果反向排序 >>>前面要先有排序才能反向
- <7> count(): #返回数据库中匹配查询(QuerySet)的对象数量。
- <8> first(): #返回第一条记录
- <9> last(): #返回最后一条记录
- <10> exists(): #如果QuerySet包含数据,就返回True,否则返回False
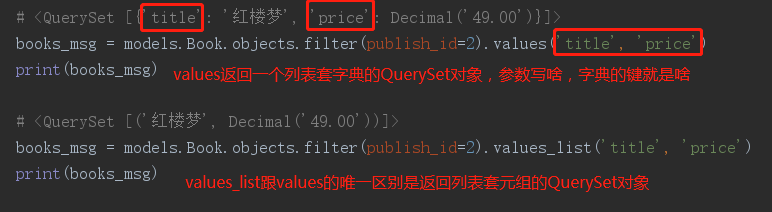
- <11> values(*field): #返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列model的实例化对象,而是一个可迭代的字典序列
- <12> values_list(*field): #它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列
- <13> distinct(): #从返回结果中剔除重复纪录
查询用到的13种方法
着重记住values方法(普通QuerySet对象:<QuerySet [<Author: Author object>]>):
在上述13种方法中,有些方法执行完返回的不一定是QuerySet对象,可能是其他对象。
- # 返回QuerySet对象的方法
- all()、filter()、exclude()、order_by()、reverse()、distinct()
- # 特殊的QuerySet
- values() #返回一个可迭代的字典序列
- values_list() #返回一个可迭代的元祖序列
- # 返回具体数据对象的
- get()、first()、last()
- # 返回布尔值的方法
- exists() #判断QuerySet对象是否为空,空返回False,否则返回True
- # 返回数字的方法
- count() #返回当前QuerySet对象中的数据对象个数
温馨提示:all()跟filter()是惰性查询,即返回QuerySet对象,只有调用QuerySet对象时内部的sql语句才会执行(这就是惰性的精髓)。objects是管理器对象(objects = Manage()),是Models和数据库进行查询的接口。Manage存在于models模块中,所以我们其实是可以自定义一个类,继承models.Manage来定义自己的管理器对象的。
2. 双下划线查询
上述的查询中,filter的查询条件都是name='值',age=值之类的,可是我们查询时条件肯定会有age>18,age<=18等情况。这个时候就需要用的双下划线查询。
2.1 大于 小于 大于等于 小于等于
- filter(price__gt=) # 大于 great than
- filter(price__lt=) # 小于 less than
- filter(price__gte=) # 大于等于 great than equal
- filter(price__lte=) # 小于等与 less than equal
2.2 存在于某几个条件中
- filter(age__in=[,,])
2.3 在某个范围内
- filter(age__range=[50,90])
2.4 模糊查询
- filter(title__contains='p') # 区分大小写
- filter(title__icontains='P') # 不区分大小写
2.5 以什么开头,以什么结尾
- # 查询名字以j开头的用户
- res = models.User.objects.filter(name__startswith='j')
- print(res)
- # 查询名字以n结尾的用户
- res = models.User.objects.filter(name__endswith='n')
- print(res)
2.6 按年查询(针对DateField和针对DateTImeField)
- filter(create_time__year='')
三. 多表操作
1. 一对多记录增删改查
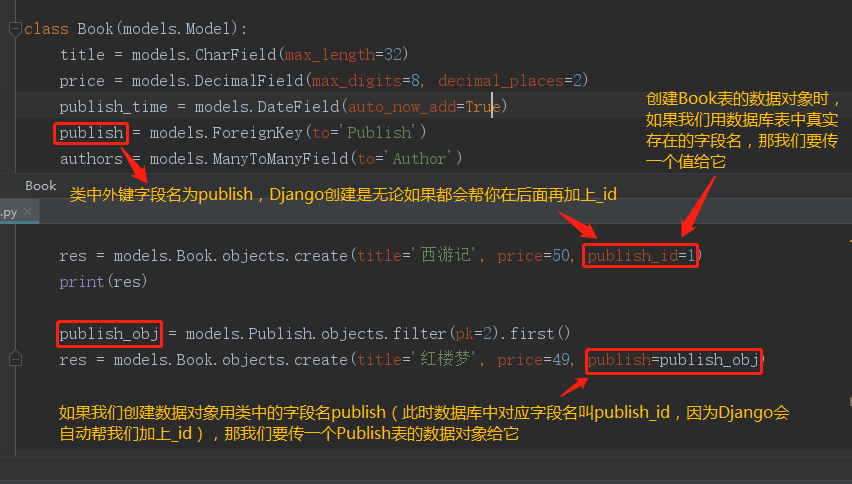
1.1 新增(主键用pk传比较好,比较稳)
- # 直接写id
- models.Book.objects.create(title='红楼梦',price=66.66,publish_id=1)
- # 传数据对象
- publish_obj = models.Publish.objects.filter(pk=2).first()
- models.Book.objects.create(title='三国演义',price=199.99,publish=publish_obj)
1.2 修改
- # Queryset修改
- models.Book.objects.filter(pk=1).update(publish_id=3)
- publish_obj = models.Publish.objects.filter(pk=2).first()
- models.Book.objects.filter(pk=1).update(publish=publish_obj)
- # 对象修改
- book_obj = models.Book.objects.filter(pk=1).first()
- book_obj.publish_id = 3 # 点表中真实存在的字段名
- book_obj.save()
- publish_obj = models.Publish.objects.filter(pk=2).first()
- book_obj.publish = publish_obj # 点orm中字段名 传该字段对应的表的数据对象
- book_obj.save()
1.3 删除
- # 使用QuerySet对象删除
- models.Book.objects.filter(pk=1).delete()
- models.Publish.objects.filter(pk=1).delete()
- # 使用数据对象删除
- book_obj = models.Book.objects.filter(pk=3).first()
- book_obj.delete()
2. 多对多记录增删改查
2.1 添加(add)
- # 拿到id=3的书籍数据对象
- book_obj = models.Book.objects.filter(pk=3).first()
- # 数据对象.authors可以直接跳到多对多那张表里
- # add传值传作者id,可以传多个
- book_obj.authors.add(1)
- book_obj.authors.add(2,3)
- # add传值支持传对象,而且可以传多个
- author_obj = models.Author.objects.filter(pk=1).first()
- author_obj1 = models.Author.objects.filter(pk=3).first()
- book_obj.authors.add(author_obj)
- book_obj.authors.add(author_obj,autor_obj1)
2.2 修改(set)
set接收的参数必须是可迭代对象!!!
- # 拿到id=3的书籍数据对象
- book_obj = models.Book.objects.filter(pk=3).first()
- # 数据对象.authors可以直接跳到多对多那张表里
- # set传值传作者id,可以传多个
- book_obj.authors.set((1,))
- book_obj.authors.set((1,2,3))
- # set传值支持传对象,而且可以传多个
- author_list = models.Author.objects.all()
- book_obj = models.Book.objects.filter(pk=3).first()
- book_obj.authors.set(author_list)
2.3 删除(remove)
- # 拿到id=3的书籍数据对象
- book_obj = models.Book.objects.filter(pk=3).first()
- # 数据对象.authors可以直接跳到多对多那张表里
- # remove传值支持传值,而且可以传多个
- book_obj.authors.remove(1)
- book_obj.authors.remove(2,3)
- # remove传值支持传对象,而且可以传多个
- author_obj = models.Author.objects.all().first()
- author_list = models.Author.objects.all()
- book_obj.authors.remove(author_obj)
- book_obj.authors.remove(*author_list) #需要将Queryset对象打散
2.4 清空(clear)
清空的是你当前这个表记录对应的绑定关系,不会影响其他表。
- book_obj = models.Book.objects.filter(pk=3).first()
- book_obj.authors.clear()
3. 正向反向查询
正向反向查询概念及方法:
- # 一对一
- # 正向:author---关联字段在author表里--->authordetail 按字段
- # 反向:authordetail---关联字段在author表里--->author 按表名小写
- # 查询jason作者的手机号 正向查询
- # 查询地址是 :山东 的作者名字 反向查询
- # 一对多
- # 正向:book---关联字段在book表里--->publish 按字段
- # 反向:publish---关联字段在book表里--->book 按表名小写_set.all() 因为一个出版社对应着多个图书
- # 多对多
- # 正向:book---关联字段在book表里--->author 按字段
- # 反向:author---关联字段在book表里--->book 按表名小写_set.all() 因为一个作者对应着多个图书
- # 连续跨表
- # 查询图书是三国演义的作者的手机号,先查书,再正向查到作者,在正向查手机号
- # 总结:基于对象的查询都是子查询,这里可以用django配置文件自动打印sql语句的配置做演示
3.1 基于对象的表查询
- # 查询书籍是三国演义的出版社邮箱
- book_obj = models.Book.objects.filter(title='三国演义').first()
- print(book_obj.publish.email)
- # 查询书籍是水浒传的作者的姓名
- book_obj = models.Book.objects.filter(title='水浒传').first()
- print(book_obj.authors) # app01.Author.None
- print(book_obj.authors.all())
- # 查询作者为jason电话号码
- user_obj = models.Author.objects.filter(name='jason').first()
- print(user_obj.authordetail.phone)
正向查询示例
- # 查询出版社是东方出版社出版的书籍 一对多字段的反向查询
- publish_obj = models.Publish.objects.filter(name='东方出版社').first()
- print(publish_obj.book_set) # app01.Book.None
- print(publish_obj.book_set.all())
- # 查询作者jason写过的所有的书 多对多字段的反向查询
- author_obj = models.Author.objects.filter(name='jason').first()
- print(author_obj.book_set) # app01.Book.None
- print(author_obj.book_set.all())
- # 查询作者电话号码是110的作者姓名 一对一字段的反向查询
- authordetail_obj = models.AuthorDetail.objects.filter(phone=110).first()
- print(authordetail_obj.author.name)
反向查询示例
3.2 基于双下划线的查询
- # 查询书籍为三国演义的出版社地址
- res = models.Book.objects.filter(title='三国演义').values('publish__addr','title')
- print(res)
- # 查询书籍为水浒传的作者的姓名
- res = models.Book.objects.filter(title='水浒传').values("authors__name",'title')
- print(res)
- # 查询作者为jason的家乡
- res = models.Author.objects.filter(name='jason').values('authordetail__addr')
- print(res)
正向示例
- # 查询南方出版社出版的书名
- res = models.Publish.objects.filter(name='南方出版社').values('book__title')
- print(res)
- # 查询电话号码为120的作者姓名
- res = models.AuthorDetail.objects.filter(phone=120).values('author__name')
- print(res)
- # 查询作者为jason的写的书的名字
- res = models.Author.objects.filter(name='jason').values('book__title')
- print(res)
- # 查询书籍为三国演义的作者的电话号码
- res = models.Book.objects.filter(title='三国演义').values('authors__authordetail__phone')
- print(res)
反向示例
3.3 小练习
- # 查询jason作者的手机号
- # 正向
- res = models.Author.objects.filter(name='jason').values('authordetail__phone')
- print(res)
- # 反向
- res = models.AuthorDetail.objects.filter(author__name='jason').values('phone')
- print(res)
- # 查询出版社为东方出版社的所有图书的名字和价格
- # 正向
- res = models.Publish.objects.filter(name='东方出版社').values('book__title','book__price')
- # print(res)
- 反向
- # res = models.Book.objects.filter(publish__name='东方出版社').values('title','price')
- print(res)
- # 查询东方出版社出版的价格大于400的书
- # 正向
- res = models.Publish.objects.filter(name="东方出版社",book__price__gt=400).values('book__title','book__price')
- print(res)
- # 反向
- res = models.Book.objects.filter(price__gt=400,publish__name='东方出版社').values('title','price')
- print(res)
在查询的时候先把orm查询语句写出来,再看用到的条件是否在当前表内,在就直接获取,不在就按照正向按字段反向按表名小写来查即可。切忌一口吃成胖子。
4 聚合查询(aggregate)
需要先导入模块:
- from django.db.models import Max,Min,Count,Sum,Avg
- # 查询所有书籍的作者个数
- res = models.Book.objects.filter(pk=3).aggregate(count_num=Count('authors'))
- print(res)
- # 查询所有出版社出版的书的平均价格
- res = models.Publish.objects.aggregate(avg_price=Avg('book__price'))
- print(res) # 4498.636
- # 统计东方出版社出版的书籍的个数
- res = models.Publish.objects.filter(name='东方出版社').aggregate(count_num=Count('book__id'))
- print(res)
聚合查询例子
5 分组查询(annotate)
- # 统计每个出版社出版的书的平均价格
- res = models.Publish.objects.annotate(avg_price=Avg('book__price')).values('name','avg_price')
- print(res)
- # 统计每一本书的作者个数
- res = models.Book.objects.annotate(count_num=Count('authors')).values('title','count_num')
- print(res)
- # 统计出每个出版社卖的最便宜的书的价格
- res = models.Publish.objects.annotate(min_price=Min('book__price')).values('name','min_price')
- print(res)
- # 查询每个作者出的书的总价格
- res = models.Author.objects.annotate(sum_price=Sum('book__price')).values('name','sum_price')
- print(res)
分组查询例子
四. 其他
1. F、Q查询
目前为止我们filter的条件的值都是我们自己给的,比如age=18。而且filter多个查询条件时,它们是and的关系。当我们查询条件的值是来自表中某字段的值,或者我们查询条件是or的关系,我们就要引入F、Q查询。
首先F、Q使用前要先导入:
- from django.db.models import F,Q
1.1 F查询
假如有一张服装店的销售表(商品、价格、库存、销量),当我们想要查询销量大于50的商品时很好实现:
- res = models.Product.objects.filter(sell__gt=50)
- print(res)
当我们要查询销量大于库存的商品时,就要使用F查询了:
- from django.db.models import F,Q
- # F查询
- res = models.Product.objects.filter(sell__gt=F('stock'))
- print(res)
将所有商品的价格提高100:
- models.Product.objects.update(price=F('price')+100)
将所有商品的名字后面都加一个爆款:
- # 是不是本能会这么想?注意,这是错误的写法,因为ORM不支持+拼接字符串
- models.Product.objects.update(price=F('name')+'爆款')
ORM不支持+拼接字符串,mysql中我们拼接字符串要用concat,此处同理:
- # 要进行字符串的拼接需要先导入Concat和Value模块
- from django.db.models.functions import Concat
- from django.db.models import Value
- models.Product.objects.update(name=Concat(F('name'), Value('爆款')))
1.2 Q查询
Q查询可以将filter中的查询条件变成or的关系,而且还能通过实例化对象的方法实现属性可以是字符串的形式(查询时本来要写name='xxx',Q查询可以实现'name'='xxx')。
注意:Q对象必须放在普通的过滤条件前面。
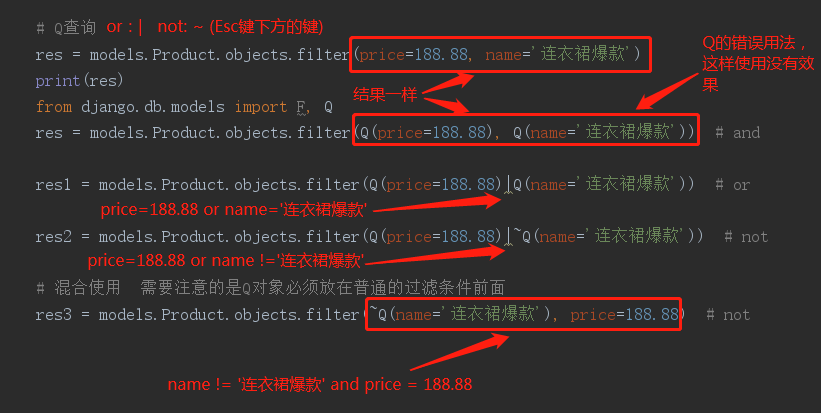
- # Q查询
- res = models.Product.objects.filter(price=188.88, name='连衣裙爆款')
- print(res)
- from django.db.models import F, Q
- res = models.Product.objects.filter(Q(price=188.88), Q(name='连衣裙爆款')) # and
- res1 = models.Product.objects.filter(Q(price=188.88)|Q(name='连衣裙爆款')) # or
- res2 = models.Product.objects.filter(Q(price=188.88)|~Q(name='连衣裙爆款')) # not
- # 混合使用 需要注意的是Q对象必须放在普通的过滤条件前面
- res3 = models.Product.objects.filter(~Q(name='连衣裙爆款'), price=188.88) # not
上图代码
前面说Q查询可以实现查询条件写成'name'='xxx'的格式(比如说我们写一个函数,根据用户输入去数据库中查询,而用户输入都是字符串的形式)。也许你会进行以下尝试:
- user_input = 'name'
- res = models.Author.objects.filter(eval(user_input)='jason')
- print(res)
然后就会马上迎来喜报:

要实现该需求,我们需要使用Q实例化出的对象来实现(先来看一下Q的源码):
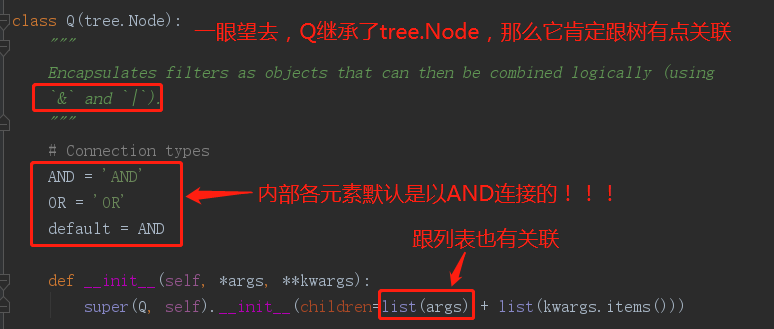
实现的代码如下:
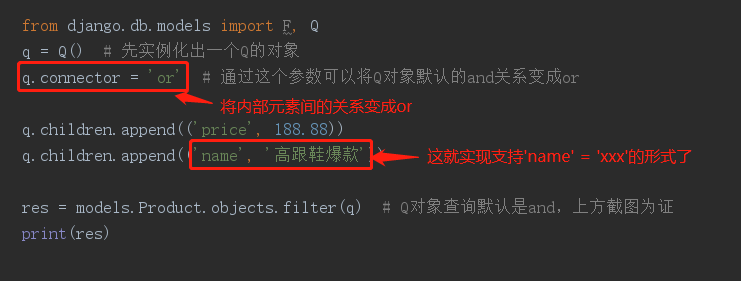
- from django.db.models import F, Q
- q = Q() # 先实例化出一个Q的对象
- q.connector = 'or' # 通过这个参数可以将Q对象默认的and关系变成or
- q.children.append(('price', 188.88))
- q.children.append(('name', '高跟鞋爆款'))
- res = models.Product.objects.filter(q) # Q对象查询默认是and,上方截图为证
- print(res)
上图代码
2. 事务
2.1 事务的四大特性:
Atomic(原子性):事务中包含的操作被看做一个逻辑单元,这个逻辑单元中的操作要么全部成 功,要么全部失败。
Consistency(一致性):事务完成时,数据必须处于一致状态,数据的完整性约束没有被破坏,事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没 有执行过一样。
Isolation(隔离性):事务允许多个用户对同一个数据进行并发访问,而不破坏数据的正确性 和完整性。同时,并行事务的修改必须与其他并行事务的修改相互独立。
Durability(持久性):事务结束后,事务处理的结果必须能够得到固化。
2.2 事务的语法
在sql语句中使用事务时,我们需要用start开启事务,又要用end结束事务,这就需要我们判断事务何时开始和结束比较好。而在Django的ORM中,直接使用上下文管理即可,省事又省心。
这里直接拿上面提到过的销售表做示例,比如一件商品卖出后,销量要+1,对应的库存要-1。
- # 导入事务的模块
- from django.db import transaction
- from django.db.models import F
- with transaction.atomic(): # atomic原子性,要么全成功,要么全失败
- # 在with代码块儿写你的事务操作
- models.Product.objects.filter(id=1).update(stock=F('stock')-1)
- models.Product.objects.filter(id=1).update(sell=F('sell')+1)
- # 写其他代码逻辑
- print('支付宝到账~~~')
3. only和defer
only和defer是相反的两个过程,有点类似filter()和exclude()的区别。我们知道values返回的是列表套字典形式的QuerySet对象,而only和defer返回的是列表套对象的QuerySet对象。
以Product为例,当使用only('name')时,返回的对象只携带Product对象的name属性,如果用对象.未携带的属性,那么它会自动再去数据库中Product映射的表中查找该属性,有就带回来返回给你。defer正好相反,defer('name')表示携带除name之外的所有属性,当对象.name时,会自动去数据库中Product映射的表中找name属性带回来给你。注意:only和defer自动找数据库找属性时会走sql语句。
- # 输出一下用values取出来的结果(列表套字典,键为'name')
- test = models.Product.objects.values('name')
- print(test)
- # only取出来的是列表套对象,对象只有name属性
- res = models.Product.objects.only('name')
- for i in res:
- print(i.name)
- # defer取出来的是列表套对象,对象除了name属性,其他属性都有
- res1 = models.Product.objects.defer('name')
- for i in res:
- print(i.name)
4. 自定义字段
Django支持自定义字段,需要继承models.Field类。
- # 自定义字段,对应数据库中的Char类型
- class MyCharField(models.Field):
- # 数据库中Char类型需要指定长度,所以要传max_length
- def __init__(self,max_length,*args,**kwargs):
- self.max_length = max_length
- # 调用父类init,一定要写关键字传参,因为Field的init参数很多,可以看一下它的源码
- super().__init__(max_length=max_length,*args,**kwargs)
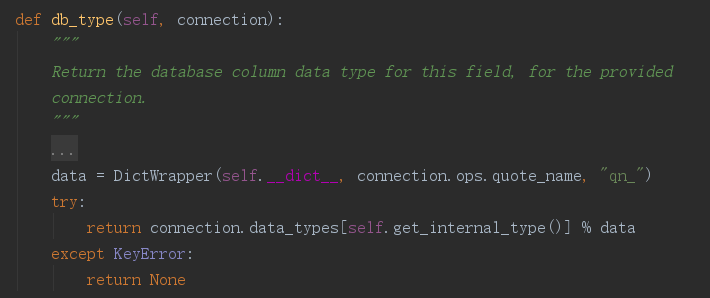
- # 该方法也不能少
- def db_type(self, connection):
- return 'char(%s)'%self.max_length
父类models.Field中的db_type方法
5. 字段中的choices属性
提一下,当我们给一个表新增一个字段时,如果表中已经有数据了,那么我们可以将models.py中新增的字段名null设置默认值或者是设置为空。
- # 设置默认值
- gender = models.IntegerField(default=2)
- # 允许为空
- gender = models.IntegerField(null=True)
choices属性使用的场景也挺多,比如性别,在数据库中我们可以存储数字,比如1代表男,2代表女,而显示给用户看时,要转变为对应的男或女。
简单示范一下:
- class User(models.Model):
- name = models.CharField(max_length=32)
- choices = ((1,'男'),(2,'女'),(3,'其他'))
- gender = models.IntegerField(choices=choices,default=2)
这样数据库里存的就是数字了,那么取出来怎么变成对应的男、女呢:
- res = models.User.objects.filter(id=1).first()
- print(res.gender)
- # 获取编号对应的中文注释,固定写法get_字段名_display()
- print(res.get_gender_display())
- # 创建对象是传数字即可
- models.User.objects.create(...gender=1)
五. 补充
1. MVC与MTV
Django大致分为模型层(models)、模板层(templates)、视图层(views)、路由层(urls)。因为Django中控制器接受用户输入的部分由框架自行处理,所以 Django 里更关注的是模型models、模板templates和视图views,称为 MTV模式。不过本质上也是属于MVC框架(模型model,视图view和控制器controller)。
2. 多对多表创建的三种方式
之前创建测试ORM的表时,多对多关系的表是通过语句让ORM自动帮我们创建的,实际上创建多对多的表有三种方式。
第一种:Django主动我们帮我们创建
该方法很方便,但是第三张表字段都是固定的,无法扩展
- class Book(models.Model):
- name = models.CharField(max_length=32)
- # 该命令让Django自动帮我们创建多对多关系的第三张表
- authors = models.ManyToManyField(to='Author')
- class Author(models.Model):
- name = models.CharField(max_length=32)
第二种:纯手动创建第三张表
该方式可以在第三张表中增加额外的字段,但是无法像第一种方式创建的表一样直接利用ORM正向反向查询信息(比如book对象要查询Author表中的内容,只能是反向查询至Book2Author这张表,然后通过该表正向查询Author表的内容)。
- class Book(models.Model):
- name = models.CharField(max_length=32)
- class Author(models.Model):
- name = models.CharField(max_length=32)
- class Book2Author(models.Model):
- # 通过创建多对多关系的两张表的外键来实现
- book = models.ForeignKey(to='Book')
- author = models.ForeignKey(to='Author')
- info = models.CharField(max_length=32)
第三种:半自动创建
当一个项目中对数据库扩展性有要求时,虽然第二种的确增加了扩展性,但是无法充分利用ORM的多表查询。接下来说的第三种方法结合了前两种的优点。建议使用该方式,扩展性高,如果使用第一种,后期需要在多对多关系的表增加字段时,需要改动的地方很多。
注意:使用第三种方式创建多对多关联关系时,就无法使用set、add、remove、clear方法来管理多对多的关系了,只能通过第三张表的model来管理多对多关系。当更改book对应的author信息时,可以先将book2author中该book对象对应的信息全部删除,然后再根据author信息重新创建数据,实际上ORM管理多对多表关系的set方法内部也是采用该方式。
- class Book(models.Model):
- name = models.CharField(max_length=32)
- # 第三种创建表的方式
- authors = models.ManyToManyField(to='Author',through='Book2Author',through_fields=('book','author'))
- class Author(models.Model):
- name = models.CharField(max_length=32)
- # 跟上面的ManyToManyField选一个写即可
- book = models.ManyToManyField(to='Book',through='Book2Author',through_fields=('author','book'))
- class Book2Author(models.Model):
- book = models.ForeignKey(to='Book')
- author = models.ForeignKey(to='Author')
- info = models.CharField(max_length=32)
小提示:
- 如果数据库迁移命令一直有问题,可以选择删除migrations下的文件(__init__.py不要删,不然再次执行数据库迁移命令时会报错)。
- 千万不要多个项目共用一个数据库,不然很容易出各种bug,有时候第1条问题的出现跟多项目共用数据库也有关系,严重的可能需要删库重建。
Django模型层ORM学习笔记的更多相关文章
- Django模型层—ORM
目录 一.模型层(models) 1-1. 常用的字段类型 1-2. 字段参数 1-3. 自定义char字段 1-4. 外键关系 二.Django中测试脚本的使用 三.单表操作 3-1. 添加记录 3 ...
- Django 模型层 ORM 操作
运行环境 1. Django:2.1.3 version 2. PyMysql: 0.9.3 version 3. pip :19.0.3 version 4. python : 3.7 versio ...
- python 全栈开发,Day70(模板自定义标签和过滤器,模板继承 (extend),Django的模型层-ORM简介)
昨日内容回顾 视图函数: request对象 request.path 请求路径 request.GET GET请求数据 QueryDict {} request.POST POST请求数据 Quer ...
- Django基础(2)--模板自定义标签和过滤器,模板继承 (extend),Django的模型层-ORM简介
没整理完 昨日回顾: 视图函数: request对象 request.path 请求路径 request.GET GET请求数据 QueryDict {} request.POST POST请求数据 ...
- Django模型层之ORM
Django模型层之ORM操作 一 ORM简介 我们在使用Django框架开发web应用的过程中,不可避免地会涉及到数据的管理操作(如增.删.改.查),而一旦谈到数据的管理操作,就需要用到数据库管理软 ...
- {django模型层(二)多表操作}一 创建模型 二 添加表记录 三 基于对象的跨表查询 四 基于双下划线的跨表查询 五 聚合查询、分组查询、F查询和Q查询
Django基础五之django模型层(二)多表操作 本节目录 一 创建模型 二 添加表记录 三 基于对象的跨表查询 四 基于双下划线的跨表查询 五 聚合查询.分组查询.F查询和Q查询 六 xxx 七 ...
- Django模型层之单表操作
Django模型层之单表操作 一 .ORM简介 我们在使用Django框架开发web应用的过程中,不可避免地会涉及到数据的管理操作(如增.删.改.查),而一旦谈到数据的管理操作,就需要用到数据库管理软 ...
- day 70 Django基础五之django模型层(二)多表操作
Django基础五之django模型层(二)多表操作 本节目录 一 创建模型 二 添加表记录 三 基于对象的跨表查询 四 基于双下划线的跨表查询 五 聚合查询.分组查询.F查询和Q查询 六 ORM ...
- day 56 Django基础五之django模型层(二)多表操作
Django基础五之django模型层(二)多表操作 本节目录 一 创建模型 二 添加表记录 三 基于对象的跨表查询 四 基于双下划线的跨表查询 五 聚合查询.分组查询.F查询和Q查询 六 ORM ...
随机推荐
- hexo NexT主题首页title链接的优化
在默认设置下,文章链接都会改变,不利于搜索引擎收录,也不利于分享 更改index.swig文件 文件路径是your-hexo-sitethemesnextlayout,将下面代码 1 {% block ...
- 网购分期不还 N种恶果等着你
N种恶果等着你" title="网购分期不还 N种恶果等着你"> 网购市场狂飙突进的发展,让每个人都享受到随时随地购物的乐趣,也在很大程度上推动商品之间的流通.目前 ...
- 查漏补缺:QObject类介绍
QObject是Qt对象模型的中心.这个模型的核心特征就是一种用于无缝对象间通信的被叫做信号和槽的非常强大的机制,可以使用connect()把信号和槽连接起来,也可以通过disconnect()来破坏 ...
- Errors running builder JavaScript Validator
问题: 解决方法: 方法一. 选择对应项目—-右键Properties—-Builders—-取消“JavaScript Validator”的勾就OK了 方法二. 找到“.project”文件,找到 ...
- Windows下python3登陆和操作linux服务器
一.环境准备 python3远程连接需要用到pycrytodome和paramiko库,其中后者依赖前者,所以按照顺序来安装 1. 安装pycrytodome 1 pip install pycryt ...
- Java入门教程四(字符串处理)
Java 语言的文本数据被保存为字符或字符串类型.字符及字符串的操作主要用到 String 类和 StringBuffer 类,如连接.修改.替换.比较和查找等. 定义字符串 直接定义字符串 直接定义 ...
- 震惊,当我运行了这条Linux命令后,服务器竟然... (Linux中的删除命令)
震惊,当我运行了这条Linux命令后,服务器竟然... 0X00 写在前面 大家都听说过删库命令rm -rf /*,但是谁又真正实践过呢?但作为一个程序员,不看看这条命令执行后会发生什么,怎么能甘心呢 ...
- 关于IT培训机构的个人看法
1.前言 缘分与巧合,最近接触比较多的培训机构出来的人,以及看过关于培训机构的文章和问答.虽然没在培训机构上过课,但是接触过很多培训机构出来的人,也看过一些培训机构的课程.关于培训机构,我也有自己的看 ...
- 数据加密标准(DES)详解
1 简介 1.1 历史 DES(Data Encryption Standard)是由IBM公司在1974年提出的加密算法,在1977年被NIST定位数据加密标准.随后的很多年里,DES都是最流行的对 ...
- git删除远程仓库中的文件夹
具体操作如下: git rm -r --cached .history #删除目录 git commit -m”删除.history文件夹” git push -r表示递归所有子目录,如果你要删 ...