文献阅读报告 - Move, Attend and Predict
Citation
Al-Molegi A , Martínez-Ballesté, Antoni, Jabreel M . Move, Attend and Predict: An Attention-based Neural Model for People’s Movement Prediction[J]. Pattern Recognition Letters, 2018:S016786551830182X.

概览
本文与之前所阅读的几篇轨迹预测文章不同,从实质上说,前面的轨迹预测是回归问题,而本文则是一个分类问题,其采纳循环神经网络对小场景中轨迹预测的提升,将其运用于更大时间跨度(最小为小时,由GPS、打卡机等设备采集)的地点变换预测上。具体来说,定义Move, Attend and Predict (MAP)模型,模型的输入由(二维地址, 时间戳)构成,输出则为根据以往地址信息所预测的下一个地址,模型由RNN编码器、注意力模型和预测模型三部分组成,总体来说结构比较简单,但其在实验评估部分的方法留留给我了一些启示,稍后将在文章中给出。
HighLights
- 时间信息与注意力机制:以往相关研究如STF-RNN网络将(地点独热值,时间点独热值)元组一并嵌入作为循环神经网络的输入。而MAP模型则采用另一种思路,引入注意力模型,使用RNN单独处理二维地址信息并保存输出,时间戳信息则以计算注意力权重并生成注意力向量的身份参与到模型中。
- 神经网络的可解释性研究:文章在实验部分对数据时间戳的定义、注意力机制的有效性、嵌入维度进行了细致地探讨,通过可视化方式较为直观地得出了:
- 注意力机制令模型更关注最近时间的信息
- 时间戳以小时效果最佳且应设为离开地点的时刻
- 嵌入维度对模型提升瓶颈与24小时制有关
- 离散化衡量指标:设备限制和数据处理方法使得模型的地点信息是离散且有限的,因此模型的评估同之前行人轨迹预测中ADE和FDE连续化指标不同,分别为准确率,召回率和F1-Score。
Future Work
- 尝试使用更高级的RNN单元如GRN、LSTM。
- 纳入更多信息考虑因素,如行人交互和地点之间的距离。
- 克服模型无法预测未知地点的问题,引入未知地点的概率预测。
模型
MAP模型由三部分组成:地点信息模型(左部灰色区)、注意力模型(右部灰色区)、分类器(上)
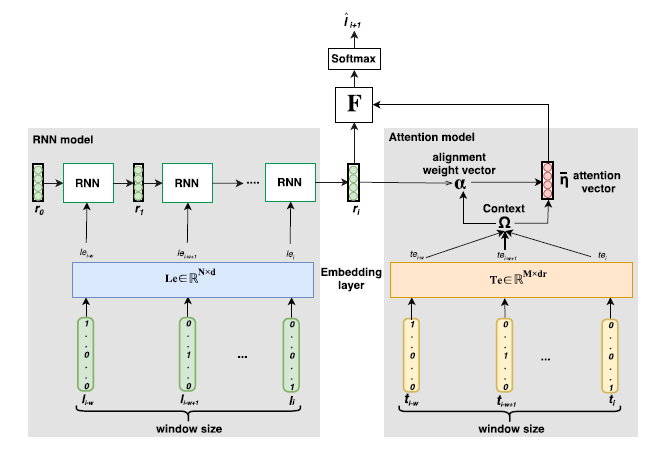
规范
对于行人,给定\(w\)对\(p_i=(l_i,t_i)\ \ (1 \le i \le w)\)元组-分别表示地点和时间戳,表示该行人过去的轨迹序列。
- 地点处在有限集合中,因此已经编码为独热编码(维度N)。
- 时间戳以小时为单位划分,其代表的均是离开与其对应地点的时刻,也采用的是独热编码(维度M)。
模型的目的是基于这\(w\)对信息,推测行人下一步的地点:\(P(l_{i+1}|p_i,...,p_1)\)
地点信息模型
地点信息模型是基本的RNN结构,其首先将\(N\)维的独热值地点信息经过嵌入矩阵\(Le\)生成\(d_l\)维向量,而后作为RNN的每一步的输入参与编码,最后一次的RNN输出(维度为\(d_r\))作为summary vector参与注意力模型运算和分类器:
\[le_i = l_i \cdot Le, \ \ r_i = RNN(le_i;W_{rnn})\]
\[r_i \in \R^{d_r}\]
[注意]:模型下标编号是倒序的,以\(i\)为结尾,一直到\(i-w+1\),因此\(r_i\)是RNN最后一个输出。
注意力模型
Question
请仔细参考结构图明确MAP的注意力模型中,“注意的对象到底是谁?“。
应该为时间戳经过嵌入后形成的W个嵌入向量,而不是RNN模型输出,这点需要和带注意力机制的RNN模型区分开。
用Attention Mechanism机制中的三个指标(Query,Key和Value)来具体刻画此模型的注意力机制:
- Query:来自RNN网络的Summary Vector \(r_i\)
- Key = Value=\(\Omega\):时间戳独热值经嵌入处理后的\(w\)个向量, \(te_i = t_i \cdot Te, \ \ \{te_{i-w},..,i\} = \Omega\)
注意力权重由Query和Key点乘并归一化得到:
\[\alpha =softmax(\Omega \cdot r_i) \ \ \alpha \in \R^{w \times 1}\]
注意力向量由注意力权重和Value进行element-wise的乘法运算:
\[\eta = \alpha * \Omega \ \ \eta \in \R^{w \times d_r}\]
分类器
分类器实质就是综合RNN编码器和注意力模型两部分模型的信息,进行简单的线性变换,并用softmax压缩为概率对于每个地点的预测概率。这里的综合函数文章给出了两种参考,一种是拼接,另一种是相加,\(W_F\)根据不同策略维度需要有所变化。
\[\hat y = softmax(F(r_i, \eta) \cdot W_F+b)\]
Optimize
模型最后是优化方法和损失函数,优化方法采用的是ADADELTA,损失函数则直接基于softmax输出的连续概率分布计算(否则离散化后无法求导进行反向传播),这与评估时需要离散的方式是不同的。
\[Loss = - \Sigma^n_{i=1}y_i \cdot log(\hat y_i)\]
[注意]:上述公式只是一个人的损失,i遍历的是有限n个地点,\(y_i\)只有0和1的取值,\(\hat y_i\)是\(\hat y\)中的具体数值。
模型评估
数据集
MAP模型的数据集相比之前轨迹预测的数据集更宏观,时间跨度以小时为最小单位,并且地点也是离散和有限的。
- Geolife:GPS设备记录的原始信息,作者在将Log信息转换为轨迹信息时,首先使用算法侦测一些地区,而后用DBSCAN聚类算法(\(\varepsilon = 100, \ minPts=3\))形成了离散固定的地点,行人的位置信息只能由这些固定地点所表示。
- Gowalla:处在固定地点的打卡机所记录的时间戳数据。
量化评价
- 评价指标:由于位置离散有限,因此预测是采用softmax计算概率分布并采样,这使得MAP模型与之前预测连续分布的模型评价指标(ADE,FDE)不同。
- 取前N个最有可能地点最为预测地点集合\(L_{N,u}\), 真实的地点集合\(L_u\)。
- 准确率 - 预测地点集合中有多少真实命中的:\(Precision@N={1 \over |U|}\Sigma _{u \in U}{|L_u \bigcap P_{N,u}| \over |P_{N,u}|}\)。
- 召回率 - 真实地点集合中有多少被预测到的:\(Recall@N = {1 \over |U|}{\Sigma_{u \in U}}{|L_u \bigcap P_{N,u}| \over |L_u|}\)
- \(F1-Score@N = 2 \times {Precision@N \times Recall@N \over Precision@N + Recall@N}\)
- 简要结论(具体请参见原文)
- 基础RNN模型提升的预测能力,若考虑加入时间因素,预测能力进一步提升。
- 数据嵌入(embedding)对模型预测能力提升明显,这是因为嵌入层能模型很好提取潜在的语义信息。
- MAP表现最好……
神经网络可解释化的研究
文章在神经网络的可解释方面做了很深的研究,进一步加强了数据定义与模型设计的合理性。
注意力机制
首先,文章中"被注意"的对象是时间独热值经嵌入层得到的\(w\)个时间嵌入向量,文章探讨在计算注意力权重\(\alpha\)时考虑因素的不同对注意力产生的影响。设置已知轨迹长度\(w=2\),两个对比分别是\(\alpha_1 = softamx(g(r_i, \Omega)) \ \ VS \ \ \alpha_2=softmax(g(r_i))\),最后探讨\(\alpha\)的权重分布特点,下图中case1是考虑空间+时间,case2只考虑空间。

结论:将时间因素$\Omega \(纳入考虑得到的\)\alpha$符合人为的认知结果 - 更关注距离当前时间点更近的时间嵌入向量。
隐藏层(时间嵌入)维度最优值
模型中为保证维度正确性,隐藏层维度和时间嵌入向量维度保持一致,根据实验结果,在\(d_r=24\)左右达到峰值,或高或低都导致预测能力下降。这恰好说明模型对24小时制的学习效果,过高或过低维度形成的时间段都将导致与时间戳定义(小时制)的不吻合。

时间戳定义
时间戳的定义由两方面问题,一是单位的定义(小时,时辰,天,月……),二是选择哪个时刻与对应地点相对应,经过对比,最终得出:
- 小时制度效果更好。
- 选择离开该地点的时刻作为时间戳效果更好,印证了“离开时刻对预测下一步地点最具影响力”的人为认知。
文献阅读报告 - Move, Attend and Predict的更多相关文章
- 文献阅读报告 - Social BiGAT + Cycle GAN
原文文献 Social BiGAT : Kosaraju V, Sadeghian A, Martín-Martín R, et al. Social-BiGAT: Multimodal Trajec ...
- 文献阅读报告 - Social Ways: Learning Multi-Modal Distributions of Pedestrian Trajectories with GANs
文献引用 Amirian J, Hayet J B, Pettre J. Social Ways: Learning Multi-Modal Distributions of Pedestrian T ...
- 文献阅读报告 - Situation-Aware Pedestrian Trajectory Prediction with Spatio-Temporal Attention Model
目录 概览 描述:模型基于LSTM神经网络提出新型的Spatio-Temporal Graph(时空图),旨在实现在拥挤的环境下,通过将行人-行人,行人-静态物品两类交互纳入考虑,对行人的轨迹做出预测 ...
- 文献阅读报告 - 3DOF Pedestrian Trajectory Prediction
文献 Sun L , Yan Z , Mellado S M , et al. 3DOF Pedestrian Trajectory Prediction Learned from Long-Term ...
- 文献阅读报告 - Social GAN: Socially Acceptable Trajectories with Generative Adversarial Networks
paper:Gupta A , Johnson J , Fei-Fei L , et al. Social GAN: Socially Acceptable Trajectories with Gen ...
- 文献阅读报告 - Social LSTM:Human Trajectory Prediction in Crowded Spaces
概览 简述 文献所提出的模型旨在解决交通中行人的轨迹预测(pedestrian trajectory prediction)问题,特别是在拥挤环境中--人与人交互(interaction)行为常有发生 ...
- 文献阅读报告 - Pedestrian Trajectory Prediction With Learning-based Approaches A Comparative Study
概述 本文献是一篇文献综述,以自动驾驶载具对外围物体行动轨迹的预测为切入点,介绍了基于运动学(kinematics-based)和基于机器学习(learning-based)的两大类预测方法. 并选择 ...
- 文献阅读报告 - Context-Based Cyclist Path Prediction using RNN
原文引用 Pool, Ewoud & Kooij, Julian & Gavrila, Dariu. (2019). Context-based cyclist path predic ...
- 文献阅读笔记——group sparsity and geometry constrained dictionary
周五实验室有同学报告了ICCV2013的一篇论文group sparsity and geometry constrained dictionary learning for action recog ...
随机推荐
- 百度地图javascript API,每个功能每天免费的次数
- Python实现的远程登录windows系统功能示例
https://www.jb51.net/article/142326.htm 重点是这几本书要好好读读!: 更多关于Python相关内容感兴趣的读者可查看本站专题:<Python进程与线程操作 ...
- python学习0day
一开始学习python没有什么感觉,也没怎么用到,时间间隔大概有一年了开始重新拾起python,话说滋味不太好受,推荐大家学到就常常的练习,不要和小白一样,难受.... 推荐一个网站: 菜鸟教程 - ...
- VUE - 引入 npm 安装的模块 以及 uuid模块的使用
<template> <div> <form @submit.prevent="addTodo"> <in ...
- jenkins#自动构建并部署springboot的jar包
1.GitLab 8.0.0(版本比较低,配置比较简单) 配置 点击项目 --> settings --> web Hooks 2.jenkins配置
- WAFの基本防护透明流模式v1.0
一.WAFの透明流模式 1)首先先配置WAF的网络,配置一个网桥接口,设置IP便于带内管理. 2)当然,如果需要不同网段之间都能够管 ...
- [Codeforces #608 div2]1271A Suits
Description A new delivery of clothing has arrived today to the clothing store. This delivery consis ...
- 神奇的i++
神奇的i++ i++,++i,多简单啊,不需要深入研究吧!!! 我是这样想的. 直到我做了一道Java基础检测题,才发现,哦,原来是这样啊!!! 题是这样的 public class Demo { p ...
- 060、Java中定义有返回值有参数的方法
01.代码如下: package TIANPAN; /** * 此处为文档注释 * * @author 田攀 微信382477247 */ public class TestDemo { public ...
- .net 4.0 : Missing compiler required member 'Microsoft.CSharp.RuntimeBinder.Binder.****'
解决办法,添加 MicroSoft.CSharp 的引用.