从零自学Hadoop(08):第一个MapReduce
阅读目录
本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作。
文章是哥(mephisto)写的,SourceLink
序
上一篇,我们的Eclipse插件搞定,那开始我们的MapReduce之旅。
在这里,我们先调用官方的wordcount例子,然后再手动创建个例子,这样可以更好的理解Job。
数据准备
一:说明
wordcount这个类是对不同的word进行统计个数,所以这里我们得准备数据,当然也不需要很大的数据量,毕竟是自己做试验对吧。
二:造数据
打开记事本,输入各种word,有相同的,不同的。然后保存为words_01.txt。
三:上传
打开eclipse,然后在DFS location 中将我们准备的数据源上传到tmp/input。
这样我们的数据就准备好了。


wordcount
一:官网示例
wordcount是hadoop的一个官网试例,打包在hadoop-mapreduce-examples-<ver>.jar。
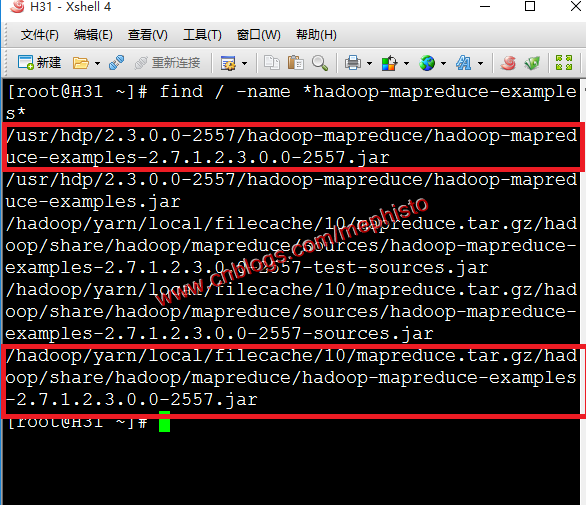
二:找到示例
我们在结果中看到两个地方有,那就找个近一点的地方吧。
find / -name *hadoop-mapreduce-examples*
四:进入目录
我们选择进入/usr/hdp/下面的这个例子。
cd /usr/hdp/2.3.0.0-/hadoop-mapreduce五:执行
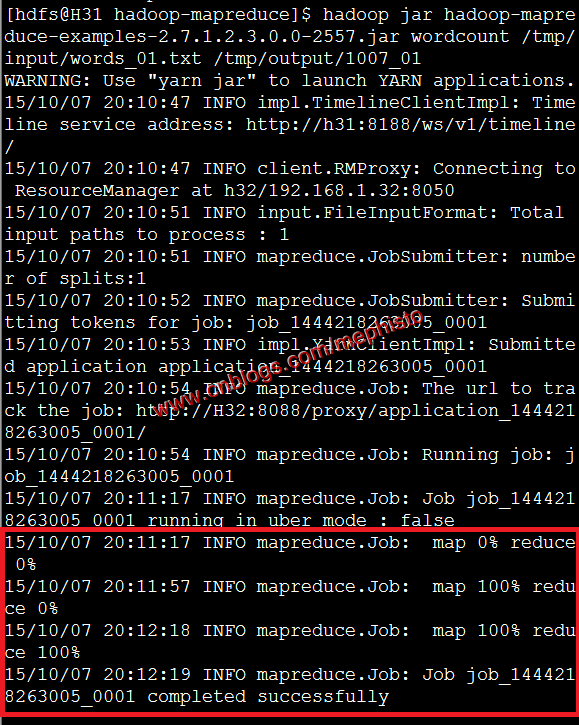
我们先使用hadoop jar这个命令执行。
命令说明:hadoop jar 包名称 方法 输入文件/目录 输出目录
#切换用户
su hsfs
#执行
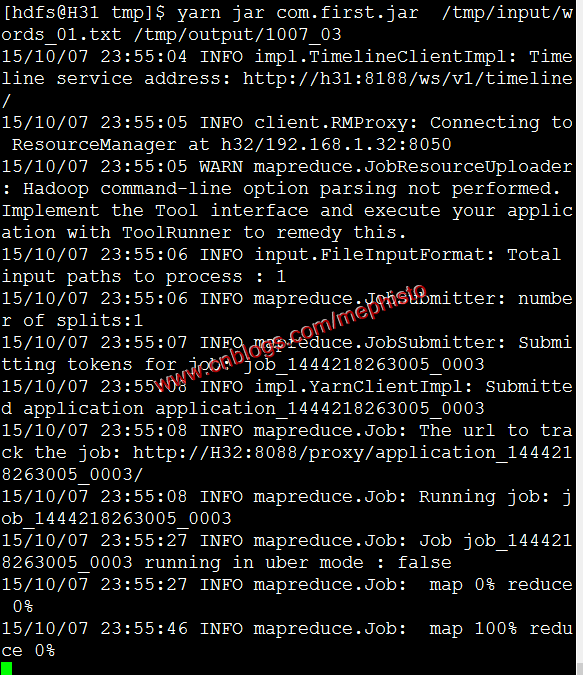
hadoop jar hadoop-mapreduce-examples-2.7.1.2.3.0.-.jar wordcount /tmp/input/words_01.txt /tmp/output/1007_01命令执行结果
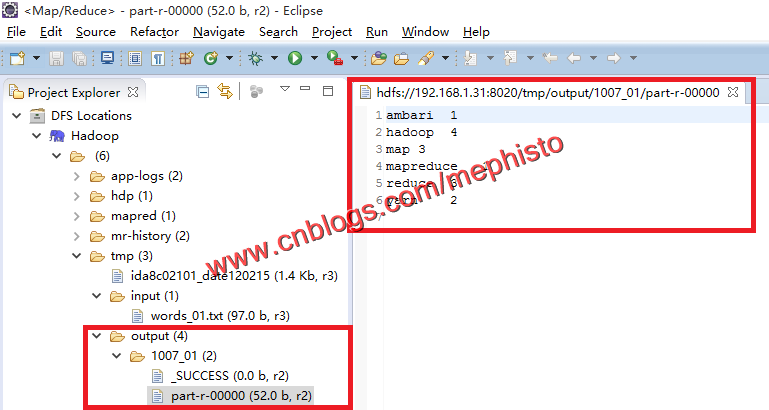
插件结果
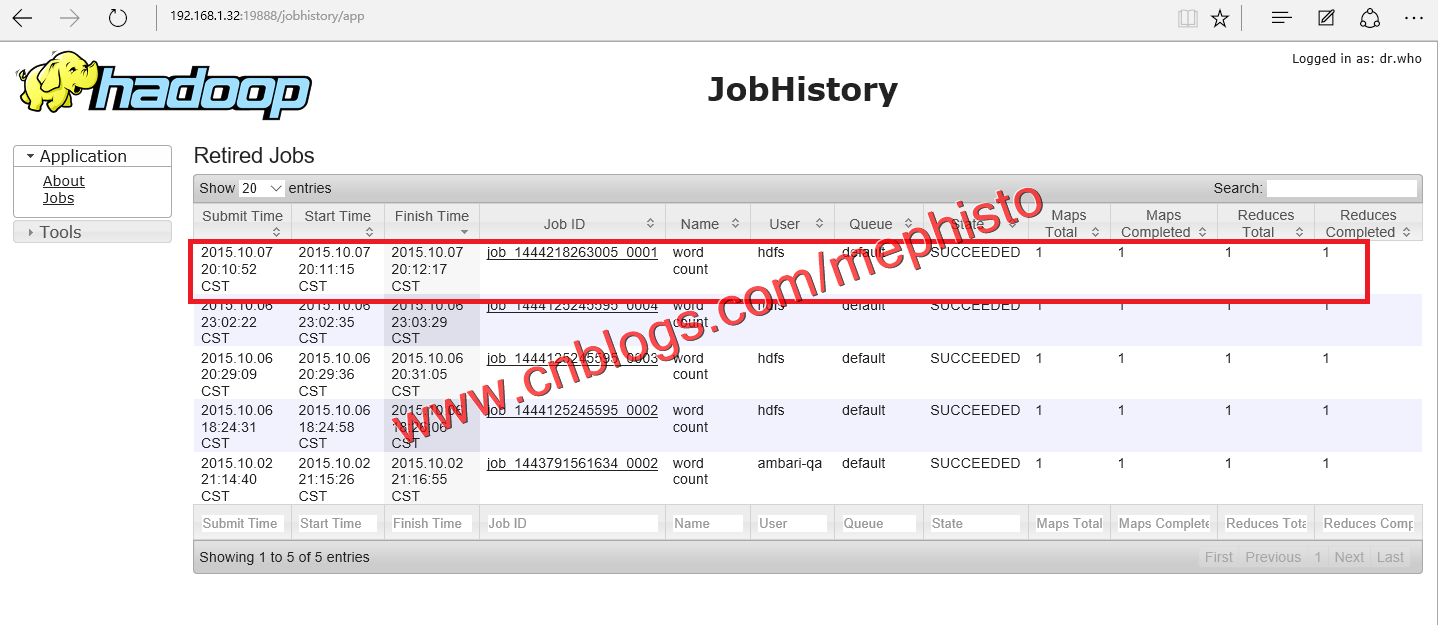
job页面结果
这样我们的第一个job就这样顺利的执行完成了。
Yarn
一:介绍
Hadoop2.X和Hadoop1.X有两个最大的变化,也是根本性变化。
其中一个是Namenode的单点问题解决,然后就是Yarn的引入。在这里我们就不做展开的讲了,后面会安排章节进行讲述。
二:Yarn命令
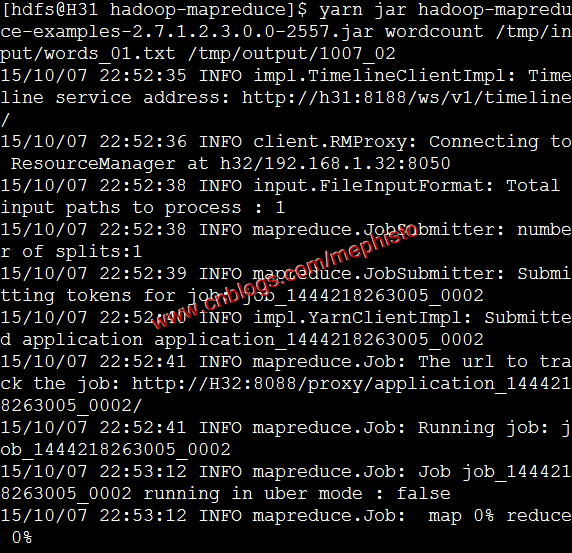
如果仔细看的话,我们可以发现在上面hadoop jar这个命令执行后,会有一个警告。
yarn jar hadoop-mapreduce-examples-2.7.1.2.3.0.-.jar wordcount /tmp/input/words_01.txt /tmp/output/1007_02
新建MapReduce
一:通过插件新建工程
这里就不详说了,在上一篇我们通过插件建立了一个工程,我们直接使用那个工程“com.first”。
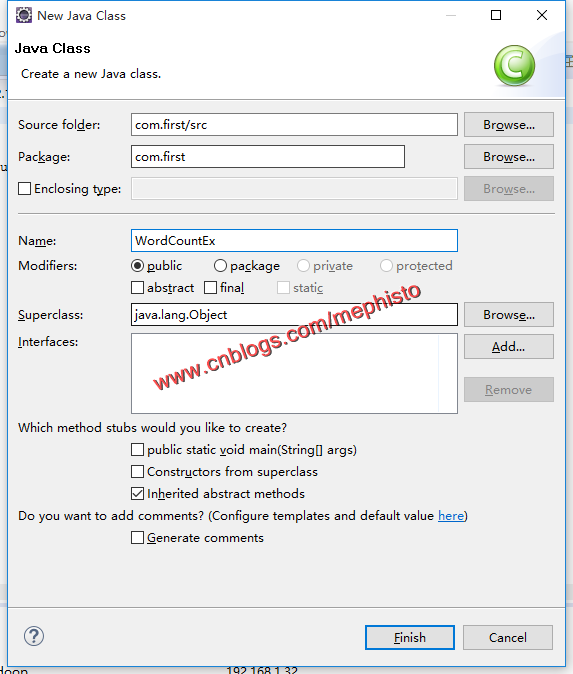
二:新建WordCountEx类
这个是我们的自定义的wordcount类,仿照官网例子写的,做了点DIY,方便大家理解。
完成后
三:新建Mapper
在WordCountEx类中建一个内部类MyMapper。
在这里我们做了点DIY,排除了字母长度小于5的数据,方便大家对比理解程序。
static class MyMapper extends Mapper<Object, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1);
private Text word = new Text(); @Override
protected void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException { // 分割字符串
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
// 排除字母少于5个的
String tmp = itr.nextToken();
if (tmp.length() < 5)
continue;
word.set(tmp);
context.write(word, one);
}
} }四:新建Reduce
同上,我们将map的结果乘以2,然后输出的内容的key加了个前缀。
static class MyReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
private Text keyEx = new Text(); @Override
protected void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException { int sum = 0;
for (IntWritable val : values) {
// 将map的结果放大,乘以2
sum += val.get() * 2;
}
result.set(sum);
// 自定义输出key
keyEx.set("输出:" + key.toString());
context.write(keyEx, result);
} }五:新建Main
在main方法中我们得定义一个job,配置它。
public static void main(String[] args) throws Exception { //配置信息
Configuration conf = new Configuration(); //job名称
Job job = Job.getInstance(conf, "mywordcount"); job.setJarByClass(WordCountEx.class);
job.setMapperClass(MyMapper.class);
// job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); //输入、输出path
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1])); //结束
System.exit(job.waitForCompletion(true) ? 0 : 1);
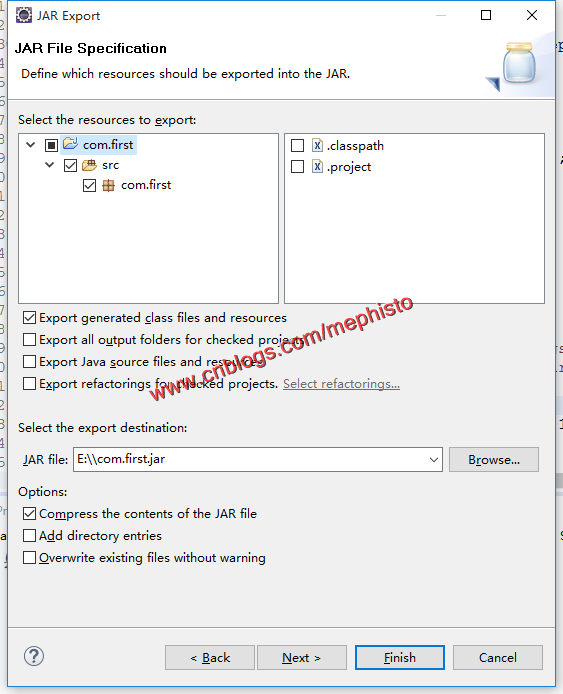
}六:导出jar包
导出我们写好的jar包。命名为com.first.jar
七:放入Linux
将导出的jar包放到H31的/var/tmp下
cd /var/tmp
ls八:执行
大家仔细看下命令和结果会发现有什么不同
yarn jar com.first.jar /tmp/input/words_01.txt /tmp/output/1007_03
如果是仔细看了,发现少个wordcount对吧,为什么列,因为在导出jar包的时候制定的main函数。
九:导出不指定main入口的jar包
我们在导出的时候,不指定main的入口。
十:执行2
我们发现这里就得多带一个参数了,就是方法的入口,这里得全路径。
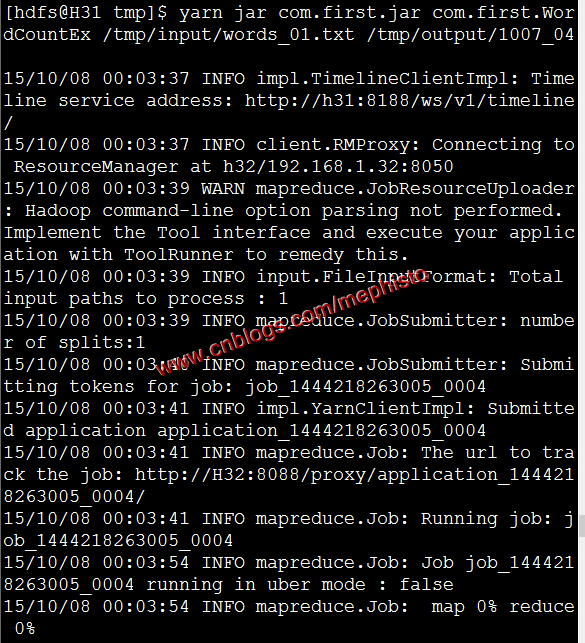
yarn jar com.first.jar com.first.WordCountEx /tmp/input/words_01.txt /tmp/output/1007_04
十一:结果
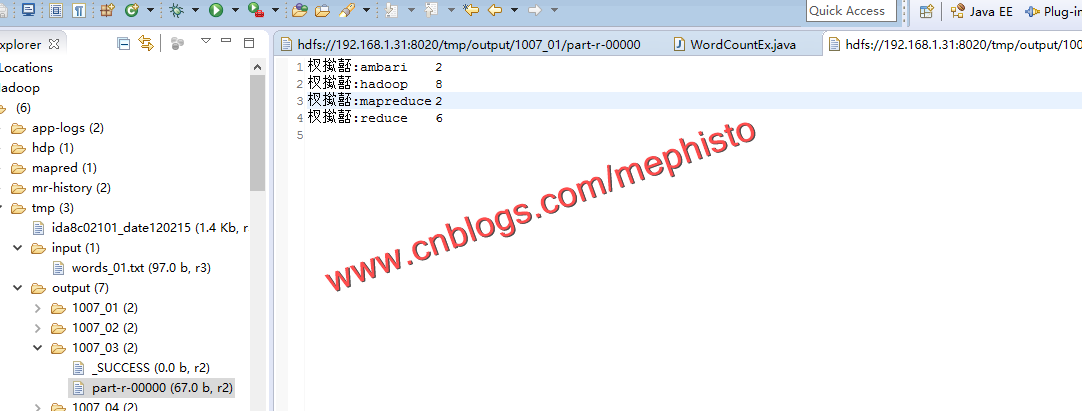
我们看下输出的结果,可以明显的看到少于5个长度的被排除了,而且结果的count都乘以了2。前缀乱码的不要纠结了,换个编码方式就好了。
--------------------------------------------------------------------
到此,本章节的内容讲述完毕。
示例下载
Github:https://github.com/sinodzh/HadoopExample/tree/master/2015/com.first
系列索引
本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作。
文章是哥(mephisto)写的,SourceLink
从零自学Hadoop(08):第一个MapReduce的更多相关文章
- 从零自学Hadoop系列索引
本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的,SourceLink 从零自学Hadoop(01):认识Hadoop ...
- 从零自学Hadoop(01):认识Hadoop
本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的,SourceLink 阅读目录 序 Hadoop 项目起源 优点 核心 ...
- 从零自学Hadoop(07):Eclipse插件
阅读目录 序 Eclipse Eclipse插件 新建插件项目 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写 ...
- 从零自学Hadoop(09):使用Maven构建Hadoop工程
阅读目录 序 Maven 安装 构建 示例下载 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的,Source ...
- 从零自学Hadoop(10):Hadoop1.x与Hadoop2.x
阅读目录 序 里程碑 Hadoop1.x与Hadoop2.x 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的 ...
- 从零自学Hadoop(11):Hadoop命令上
阅读目录 序 概述 Hadoop Common Commands User Commands Administration Commands File System Shell 引用 系列索引 本文版 ...
- 从零自学Hadoop(13):Hadoop命令下
阅读目录 序 MapReduce Commands User Commands Administration Commands YARN Commands User Commands Administ ...
- 从零自学Hadoop(14):Hive介绍及安装
阅读目录 序 介绍 安装 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的,SourceLink 序 本系列已 ...
- 从零自学Hadoop(16):Hive数据导入导出,集群数据迁移上
阅读目录 序 导入文件到Hive 将其他表的查询结果导入表 动态分区插入 将SQL语句的值插入到表中 模拟数据文件下载 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并 ...
随机推荐
- Project Server 2010 配置详解
应公司要求,需要加强对项目的管理.安排我学习一下微软的Project是如何进行项目管理的,并且在公司服务器上搭建出这样的一个项目管理工具.可以通过浏览器就可以访问.我因为用的单机是Project Pr ...
- Win8.1 安装Express 框架
1.安装Windows Node.js客户端 2.安装Express框架 我本机是Win8.1的,使用命令npm install -g express安装Express,安装完成后显示一些安装明细,刚 ...
- 【知识积累】SBT+Scala+MySQL的Demo
一.背景 由于项目需要,需要在Sbt+Scala项目中连接MySQL数据库.由于之前使用Maven+Java进行依赖管理偏多,在Sbt+Scala方面也在不断进行摸索,特此记录,作为小模块知识的积累. ...
- AppCan学习笔记----Request和登录功能简单实现
appcan.ajax(options) 实现appcan中网络数据的上传和获取 发起一个ajax请求,并获取相应的内容 常用参数 options.type: 请求的类型,包括GET.POST等 op ...
- 8.Struts2类型转换器
类型转换器1.引入在Struts2中,请求参数类型不仅可以是String,还可以是其它类型.如,定义一个请求参数birthday为Date类型,给其赋值为1949-10-1,则birthday接收到的 ...
- 关于Javascript中通过实例对象修改原型对象属性值的问题
Javascript中的数据值有两大类:基本类型的数据值和引用类型的数据值. 基本类型的数据值有5种:null.undefined.number.boolean和string. 引用类型的数据值往大的 ...
- Centos 7 开启端口
CentOS 7 默认没有使用iptables,所以通过编辑iptables的配置文件来开启80端口是不可以的 CentOS 7 采用了 firewalld 防火墙 如要查询是否开启80端口则: 1 ...
- CSS3 media queries + jQuery实现响应式导航
目的: 实现一个响应式导航,当屏幕宽度大于700px时,效果如下: 当屏幕宽度小于700px时,导航变成一个小按钮,点击之后有一个菜单慢慢拉下来: 思路: 1.为了之后在菜单上绑定事件,并且不向DOM ...
- scikit-learn一般实例之三:连接多个特征提取方法
在很多现实世界的例子中,有很多从数据集中提取特征的方法.很多时候我们需要结合多种方法获得好的效果.本例将展示怎样使用FeatureUnion通过主成分分析和单变量选择相进行特征结合. 结合使用转换器的 ...
- javascript作用域中令你意想不到的问题
大多数类c的语言,由一对花括号封闭的代码块就是一个作用域.但是javascript的作用域则是通过函数来定义.在一个函数中定义的变量只对这个函数内部可见,我们称为函数作用域. 1.在函数中引用一个变量 ...