吴裕雄--天生自然 R语言开发学习:分类(续二)








#-----------------------------------------------------------------------------#
# R in Action (2nd ed): Chapter 17 #
# Classification #
# requires packaged rpart, party, randomForest, kernlab, rattle #
# install.packages(c("rpart", "party", "randomForest", "e1071", "rpart.plot") #
# install.packages(rattle, dependencies = c("Depends", "Suggests")) #
#-----------------------------------------------------------------------------# par(ask=TRUE) # Listing 17.1 - Prepare the breast cancer data
loc <- "http://archive.ics.uci.edu/ml/machine-learning-databases/"
ds <- "breast-cancer-wisconsin/breast-cancer-wisconsin.data"
url <- paste(loc, ds, sep="") breast <- read.table(url, sep=",", header=FALSE, na.strings="?")
names(breast) <- c("ID", "clumpThickness", "sizeUniformity",
"shapeUniformity", "maginalAdhesion",
"singleEpithelialCellSize", "bareNuclei",
"blandChromatin", "normalNucleoli", "mitosis", "class") df <- breast[-1]
df$class <- factor(df$class, levels=c(2,4),
labels=c("benign", "malignant")) set.seed(1234)
train <- sample(nrow(df), 0.7*nrow(df))
df.train <- df[train,]
df.validate <- df[-train,]
table(df.train$class)
table(df.validate$class) # Listing 17.2 - Logistic regression with glm()
fit.logit <- glm(class~., data=df.train, family=binomial())
summary(fit.logit)
prob <- predict(fit.logit, df.validate, type="response")
logit.pred <- factor(prob > .5, levels=c(FALSE, TRUE),
labels=c("benign", "malignant"))
logit.perf <- table(df.validate$class, logit.pred,
dnn=c("Actual", "Predicted"))
logit.perf # Listing 17.3 - Creating a classical decision tree with rpart()
library(rpart)
set.seed(1234)
dtree <- rpart(class ~ ., data=df.train, method="class",
parms=list(split="information"))
dtree$cptable
plotcp(dtree) dtree.pruned <- prune(dtree, cp=.0125) library(rpart.plot)
prp(dtree.pruned, type = 2, extra = 104,
fallen.leaves = TRUE, main="Decision Tree") dtree.pred <- predict(dtree.pruned, df.validate, type="class")
dtree.perf <- table(df.validate$class, dtree.pred,
dnn=c("Actual", "Predicted"))
dtree.perf # Listing 17.4 - Creating a conditional inference tree with ctree()
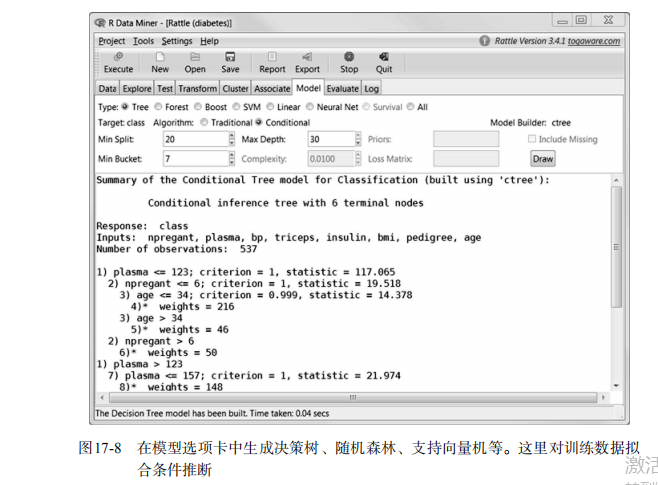
library(party)
fit.ctree <- ctree(class~., data=df.train)
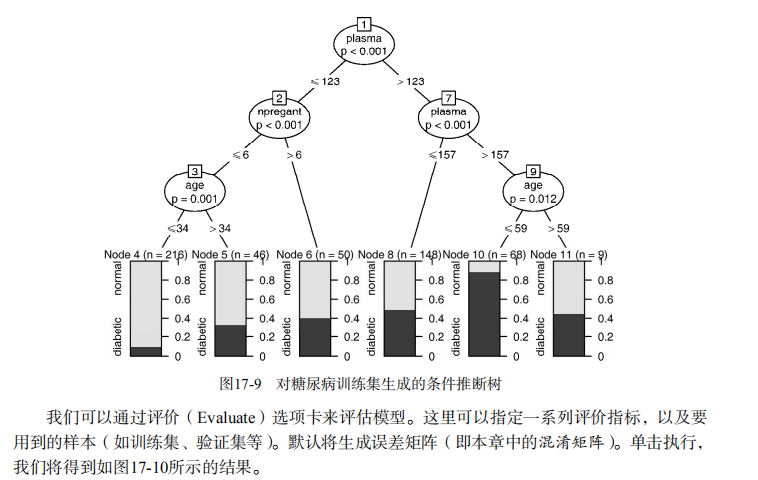
plot(fit.ctree, main="Conditional Inference Tree") ctree.pred <- predict(fit.ctree, df.validate, type="response")
ctree.perf <- table(df.validate$class, ctree.pred,
dnn=c("Actual", "Predicted"))
ctree.perf # Listing 17.5 - Random forest
library(randomForest)
set.seed(1234)
fit.forest <- randomForest(class~., data=df.train,
na.action=na.roughfix,
importance=TRUE)
fit.forest
importance(fit.forest, type=2)
forest.pred <- predict(fit.forest, df.validate)
forest.perf <- table(df.validate$class, forest.pred,
dnn=c("Actual", "Predicted"))
forest.perf # Listing 17.6 - A support vector machine
library(e1071)
set.seed(1234)
fit.svm <- svm(class~., data=df.train)
fit.svm
svm.pred <- predict(fit.svm, na.omit(df.validate))
svm.perf <- table(na.omit(df.validate)$class,
svm.pred, dnn=c("Actual", "Predicted"))
svm.perf # Listing 17.7 Tuning an RBF support vector machine (this can take a while)
set.seed(1234)
tuned <- tune.svm(class~., data=df.train,
gamma=10^(-6:1),
cost=10^(-10:10))
tuned
fit.svm <- svm(class~., data=df.train, gamma=.01, cost=1)
svm.pred <- predict(fit.svm, na.omit(df.validate))
svm.perf <- table(na.omit(df.validate)$class,
svm.pred, dnn=c("Actual", "Predicted"))
svm.perf # Listing 17.8 Function for assessing binary classification accuracy
performance <- function(table, n=2){
if(!all(dim(table) == c(2,2)))
stop("Must be a 2 x 2 table")
tn = table[1,1]
fp = table[1,2]
fn = table[2,1]
tp = table[2,2]
sensitivity = tp/(tp+fn)
specificity = tn/(tn+fp)
ppp = tp/(tp+fp)
npp = tn/(tn+fn)
hitrate = (tp+tn)/(tp+tn+fp+fn)
result <- paste("Sensitivity = ", round(sensitivity, n) ,
"\nSpecificity = ", round(specificity, n),
"\nPositive Predictive Value = ", round(ppp, n),
"\nNegative Predictive Value = ", round(npp, n),
"\nAccuracy = ", round(hitrate, n), "\n", sep="")
cat(result)
} # Listing 17.9 - Performance of breast cancer data classifiers
performance(dtree.perf)
performance(ctree.perf)
performance(forest.perf)
performance(svm.perf) # Using Rattle Package for data mining loc <- "http://archive.ics.uci.edu/ml/machine-learning-databases/"
ds <- "pima-indians-diabetes/pima-indians-diabetes.data"
url <- paste(loc, ds, sep="")
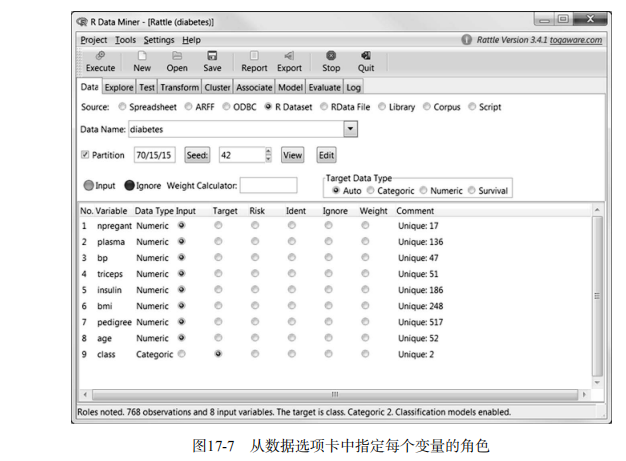
diabetes <- read.table(url, sep=",", header=FALSE)
names(diabetes) <- c("npregant", "plasma", "bp", "triceps",
"insulin", "bmi", "pedigree", "age", "class")
diabetes$class <- factor(diabetes$class, levels=c(0,1),
labels=c("normal", "diabetic"))
library(rattle)
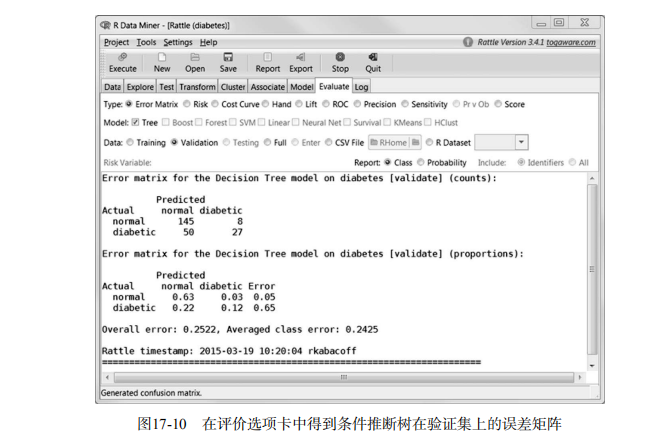
rattle()
吴裕雄--天生自然 R语言开发学习:分类(续二)的更多相关文章
- 吴裕雄--天生自然 R语言开发学习:R语言的安装与配置
下载R语言和开发工具RStudio安装包 先安装R
- 吴裕雄--天生自然 R语言开发学习:数据集和数据结构
数据集的概念 数据集通常是由数据构成的一个矩形数组,行表示观测,列表示变量.表2-1提供了一个假想的病例数据集. 不同的行业对于数据集的行和列叫法不同.统计学家称它们为观测(observation)和 ...
- 吴裕雄--天生自然 R语言开发学习:导入数据
2.3.6 导入 SPSS 数据 IBM SPSS数据集可以通过foreign包中的函数read.spss()导入到R中,也可以使用Hmisc 包中的spss.get()函数.函数spss.get() ...
- 吴裕雄--天生自然 R语言开发学习:使用键盘、带分隔符的文本文件输入数据
R可从键盘.文本文件.Microsoft Excel和Access.流行的统计软件.特殊格 式的文件.多种关系型数据库管理系统.专业数据库.网站和在线服务中导入数据. 使用键盘了.有两种常见的方式:用 ...
- 吴裕雄--天生自然 R语言开发学习:R语言的简单介绍和使用
假设我们正在研究生理发育问 题,并收集了10名婴儿在出生后一年内的月龄和体重数据(见表1-).我们感兴趣的是体重的分 布及体重和月龄的关系. 可以使用函数c()以向量的形式输入月龄和体重数据,此函 数 ...
- 吴裕雄--天生自然 R语言开发学习:基础知识
1.基础数据结构 1.1 向量 # 创建向量a a <- c(1,2,3) print(a) 1.2 矩阵 #创建矩阵 mymat <- matrix(c(1:10), nrow=2, n ...
- 吴裕雄--天生自然 R语言开发学习:图形初阶(续二)
# ----------------------------------------------------# # R in Action (2nd ed): Chapter 3 # # Gettin ...
- 吴裕雄--天生自然 R语言开发学习:图形初阶(续一)
# ----------------------------------------------------# # R in Action (2nd ed): Chapter 3 # # Gettin ...
- 吴裕雄--天生自然 R语言开发学习:图形初阶
# ----------------------------------------------------# # R in Action (2nd ed): Chapter 3 # # Gettin ...
- 吴裕雄--天生自然 R语言开发学习:基本图形(续二)
#---------------------------------------------------------------# # R in Action (2nd ed): Chapter 6 ...
随机推荐
- 【按位dp】1出现的次数
l-r1出现的次数 注意端点处理 垃圾算法书 垃圾代码毁我青春 自己研究写了写 #include <iostream> #include <string> #include & ...
- ubuntu14 编译tensorflow C++ 接口
tensorflow1.11 bazel 0.15.2 protobuf 3.6.0 eigen 3.3.5 wget -t 0 -c https://github.com/eigenteam/eig ...
- Redis--初识Redis
Redis 是一个远程内存数据库,它不仅性能强劲,而且还具有复制特性以及为解决问题而生的独一无二的数据模型.Redis 提供了 5 种不同类型的数据结构,各式各样的问题都可以很自然的映射到这些数据结构 ...
- P2P平台爆雷不断到底是谁的过错?
早在此前,范伟曾经在春晚上留下一句经典台词,"防不胜防啊".而将这句台词用在当下的P2P行业,似乎最合适不过了.就在这个炎热夏季,P2P行业却迎来最冷冽的寒冬. 引发爆雷潮的众多P ...
- Linux-竟态初步引入
(1).竟态全称是:竞争状态,多进程环境下,多个进程同时抢占系统资源(内存.CPU.文件IO). (2).竞争状态对于操作系统OS来说是很危险的,此时的操作系统OS如果没有处理好就会造成结果不确定. ...
- Django内置标签
在Django中也提供了大量Django自带的内置标签来供我们使用.标签的写法与过滤器的写法不同,标签是具有开始和结束的,例如:{% if %}为开始标签,{% endif %}为结束标签. 可以查 ...
- 网页滚动条CSS样式
滚动条样式主要涉及到如下CSS属性: overflow属性: 检索或设置当对象的内容超过其指定高度及宽度时如何显示内容 overflow: auto; 在需要时内容会自动添加滚动条overflow: ...
- 吴裕雄--天生自然 JAVA开发学习:重写(Override)与重载(Overload)
class Animal{ public void move(){ System.out.println("动物可以移动"); } } class Dog extends Anim ...
- K 破忒头的匿名信(ac自动机+小dp)
题:https://ac.nowcoder.com/acm/contest/4010/K 题意:用一些模式串凑成一个目标串,每个模式串有消耗,问组合的最小消耗,或不能组成输出-1: 分析:典型的AC自 ...
- java连接外部接口获取数据工具类
package com.yqzj.util; import org.apache.log4j.LogManager;import org.apache.log4j.Logger; import jav ...