IDEA下调试和运行Hadoop程序例子
准备
配置好JDK和Hadoop环境,
在IDEA中建立maven项目,建立后的目录结构为:

修改pom..xml引入相关支持:
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>com.xuan</groupId>
<artifactId>hadoopdemo</artifactId>
<version>1.0-SNAPSHOT</version> <name>hadoopdemo</name>
<!-- FIXME change it to the project's website -->
<url>http://www.example.com</url> <properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties> <dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.5.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.5.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.5.2</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
</dependencies> </project>
一,测试字母统计
创建测试类WordCount.java:
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
配置输入和输出结果文件夹:
添加和src目录同级的input文件夹到项目中
在input文件夹中放置一个或多个输入文件源,比如file1.txt;file2.txt
file1.txt内容为:
q
w
ww
q
we
qwe
as
q
w
ww
q
w
we
file2.txt内容也类似的随意输入。
配置运行参数
在Intellij菜单栏中选择Run->Edit Configurations,在弹出来的对话框中点击+,新建一个Application配置。配置Main class为WordCount(可以点击右边的...选择),
Program arguments为input/ output/,即输入路径为刚才创建的input文件夹,输出为output
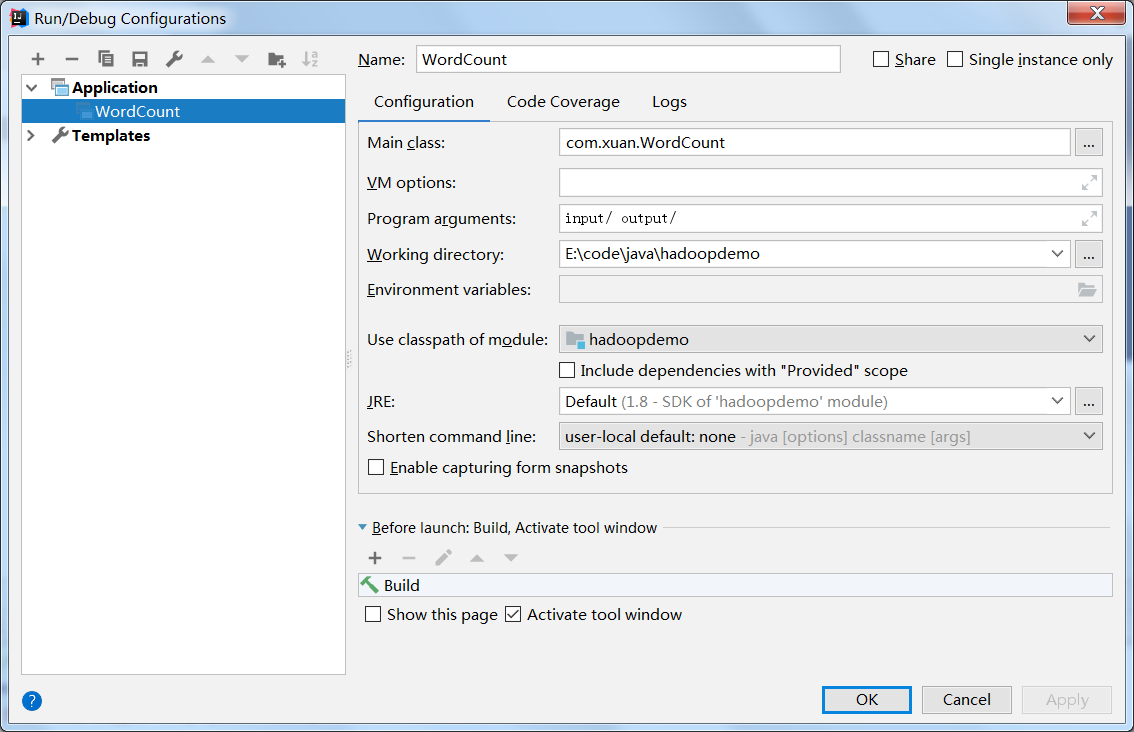
由于Hadoop的设定,下次运行时务必删除output文件夹
运行程序,结果生成out目录,里面有执行结果文件“part-r-00000”,其内容:

二。在多条数据中查找包含某个字符串的语句。
创建Search.java统计类
public class Search {
public static class Map extends Mapper<Object, Text, Text, Text> {
private static final String word = "月";
private FileSplit fileSplit;
@Override
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
fileSplit = (FileSplit) context.getInputSplit();
String fileName = fileSplit.getPath().getName().toString();
//按句号分割
StringTokenizer st = new StringTokenizer(value.toString(), "。");
while (st.hasMoreTokens()) {
String line = st.nextToken().toString();
if (line.indexOf(word) >= 0) {
context.write(new Text(fileName), new Text(line));
}
}
}
}
public static class Reduce extends Reducer<Text, Text, Text, Text> {
@Override
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
String lines = "";
for (Text value : values) {
lines += value.toString() + "---|---";
}
context.write(key, new Text(lines));
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
String[] otherArgs = {"input/", "output/"};
//配置作业名
Job job = Job.getInstance(conf, "search");
//配置作业各个类
job.setJarByClass(Search.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
此例子中的运行目录是直接在代码中写的
修改file1.txt和file2.txt的内容:
浔阳江头夜送客,枫叶荻花秋瑟瑟。主人下马客在船,举酒欲饮无管弦。醉不成欢惨将别,别时茫茫江浸月。忽闻水上琵琶声,主人忘归客不发。寻声暗问弹者谁?琵琶声停欲语迟。移船相近邀相见,添酒回灯重开宴。千呼万唤始出来,犹抱琵琶半遮面。转轴拨弦三两声,未成曲调先有情。弦弦掩抑声声思,似诉平生不得志。低眉信手续续弹,说尽心中无限事。轻拢慢捻抹复挑,初为霓裳后六幺。大弦嘈嘈如急雨,小弦切切如私语。嘈嘈切切错杂弹,大珠小珠落玉盘。间关莺语花底滑,幽咽泉流冰下难。冰泉冷涩弦凝绝,凝绝不通声暂歇。别有幽愁暗恨生,此时无声胜有声。银瓶乍破水浆迸,铁骑突出刀枪鸣。曲终收拨当心画,四弦一声如裂帛。东船西舫悄无言,唯见江心秋月白。
沉吟放拨插弦中,整顿衣裳起敛容。自言本是京城女,家在虾蟆陵下住。十三学得琵琶成,名属教坊第一部。曲罢曾教善才服,妆成每被秋娘妒。五陵年少争缠头,一曲红绡不知数。钿头银篦击节碎,血色罗裙翻酒污。今年欢笑复明年,秋月春风等闲度。弟走从军阿姨死,暮去朝来颜色故。门前冷落鞍马稀,老大嫁作商人妇。商人重利轻别离,前月浮梁买茶去。去来江口守空船,绕船月明江水寒。夜深忽梦少年事,梦啼妆泪红阑干。
我闻琵琶已叹息,又闻此语重唧唧。同是天涯沦落人,相逢何必曾相识!我从去年辞帝京,谪居卧病浔阳城。浔阳地僻无音乐,终岁不闻丝竹声。住近湓江地低湿,黄芦苦竹绕宅生。其间旦暮闻何物?杜鹃啼血猿哀鸣。春江花朝秋月夜,往往取酒还独倾。岂无山歌与村笛?呕哑嘲哳难为听。今夜闻君琵琶语,如听仙乐耳暂明。莫辞更坐弹一曲,为君翻作《琵琶行》。感我此言良久立,却坐促弦弦转急。凄凄不似向前声,满座重闻皆掩泣。座中泣下谁最多?江州司马青衫湿。
汉皇重色思倾国,御宇多年求不得。
杨家有女初长成,养在深闺人未识。
天生丽质难自弃,一朝选在君王侧。
回眸一笑百媚生,六宫粉黛无颜色。
春寒赐浴华清池,温泉水滑洗凝脂。
侍儿扶起娇无力,始是新承恩泽时。
云鬓花颜金步摇,芙蓉帐暖度春宵。
春宵苦短日高起,从此君王不早朝。
承欢侍宴无闲暇,春从春游夜专夜。
后宫佳丽三千人,三千宠爱在一身。
金屋妆成娇侍夜,玉楼宴罢醉和春。
姊妹弟兄皆列土,可怜光彩生门户。
遂令天下父母心,不重生男重生女。
骊宫高处入青云,仙乐风飘处处闻。
缓歌谩舞凝丝竹,尽日君王看不足。
渔阳鼙鼓动地来,惊破霓裳羽衣曲。
九重城阙烟尘生,千乘万骑西南行。
翠华摇摇行复止,西出都门百余里。
六军不发无奈何,宛转蛾眉马前死。
花钿委地无人收,翠翘金雀玉搔头。
君王掩面救不得,回看血泪相和流。
黄埃散漫风萧索,云栈萦纡登剑阁。
峨嵋山下少人行,旌旗无光日色薄。
蜀江水碧蜀山青,圣主朝朝暮暮情。
行宫见月伤心色,夜雨闻铃肠断声。
天旋地转回龙驭,到此踌躇不能去。
马嵬坡下泥土中,不见玉颜空死处。
君臣相顾尽沾衣,东望都门信马归。
归来池苑皆依旧,太液芙蓉未央柳。
芙蓉如面柳如眉,对此如何不泪垂。
春风桃李花开日,秋雨梧桐叶落时。
西宫南内多秋草,落叶满阶红不扫。
梨园弟子白发新,椒房阿监青娥老。
夕殿萤飞思悄然,孤灯挑尽未成眠。
迟迟钟鼓初长夜,耿耿星河欲曙天。
鸳鸯瓦冷霜华重,翡翠衾寒谁与共。
悠悠生死别经年,魂魄不曾来入梦。
临邛道士鸿都客,能以精诚致魂魄。
为感君王辗转思,遂教方士殷勤觅。
排空驭气奔如电,升天入地求之遍。
上穷碧落下黄泉,两处茫茫皆不见。
忽闻海上有仙山,山在虚无缥渺间。
楼阁玲珑五云起,其中绰约多仙子。
中有一人字太真,雪肤花貌参差是。
金阙西厢叩玉扃,转教小玉报双成。
闻道汉家天子使,九华帐里梦魂惊。
揽衣推枕起徘徊,珠箔银屏迤逦开。
云鬓半偏新睡觉,花冠不整下堂来。
风吹仙袂飘飘举,犹似霓裳羽衣舞。
玉容寂寞泪阑干,梨花一枝春带雨。
含情凝睇谢君王,一别音容两渺茫。
昭阳殿里恩爱绝,蓬莱宫中日月长。
回头下望人寰处,不见长安见尘雾。
惟将旧物表深情,钿合金钗寄将去。
钗留一股合一扇,钗擘黄金合分钿。
但教心似金钿坚,天上人间会相见。
临别殷勤重寄词,词中有誓两心知。
七月七日长生殿,夜半无人私语时。
在天愿作比翼鸟,在地愿为连理枝。
天长地久有时尽,此恨绵绵无绝期。
在增加一个文件file3.txt
春江潮水连海平,海上明月共潮生。
滟滟随波千万里,何处春江无月明!
江流宛转绕芳甸,月照花林皆似霰;
空里流霜不觉飞,汀上白沙看不见。
江天一色无纤尘,皎皎空中孤月轮。
江畔何人初见月?江月何年初照人?
人生代代无穷已,江月年年只相似。
不知江月待何人,但见长江送流水。
白云一片去悠悠,青枫浦上不胜愁。
谁家今夜扁舟子?何处相思明月楼?
可怜楼上月徘徊,应照离人妆镜台。
玉户帘中卷不去,捣衣砧上拂还来。
此时相望不相闻,愿逐月华流照君。
鸿雁长飞光不度,鱼龙潜跃水成文。
昨夜闲潭梦落花,可怜春半不还家。
江水流春去欲尽,江潭落月复西斜。
斜月沉沉藏海雾,碣石潇湘无限路。
不知乘月几人归,落月摇情满江树。
运行程序Search.java,结果生成out目录,里面有执行结果文件“part-r-00000”,其内容:
file1.txt 春江花朝秋月夜,往往取酒还独倾---|---去来江口守空船,绕船月明江水寒---|---商人重利轻别离,前月浮梁买茶去---|---今年欢笑复明年,秋月春风等闲度---|---东船西舫悄无言,唯见江心秋月白---|---醉不成欢惨将别,别时茫茫江浸月---|---
file2.txt 七月七日长生殿,夜半无人私语时---|---昭阳殿里恩爱绝,蓬莱宫中日月长---|---行宫见月伤心色,夜雨闻铃肠断声---|---
file3.txt 不知乘月几人归,落月摇情满江树---|---斜月沉沉藏海雾,碣石潇湘无限路---|---江水流春去欲尽,江潭落月复西斜---|---此时相望不相闻,愿逐月华流照君---|---可怜楼上月徘徊,应照离人妆镜台---|---谁家今夜扁舟子?何处相思明月楼?---|---不知江月待何人,但见长江送流水---|---人生代代无穷已,江月年年只相似---|---江畔何人初见月?江月何年初照人?---|---江天一色无纤尘,皎皎空中孤月轮---|---江流宛转绕芳甸,月照花林皆似霰;---|---滟滟随波千万里,何处春江无月明!---|---春江潮水连海平,海上明月共潮生---|---
三。Partitioner与自定义Partitioner,生成多个结果文件
参考:https://www.cnblogs.com/edisonchou/p/4297828.html
创建MyKpiJob.java
public class MyKpiJob extends Configured implements Tool {
/*
* 自定义数据类型KpiWritable
*/
public static class KpiWritable implements Writable {
long upPackNum; // 上行数据包数,单位:个
long downPackNum; // 下行数据包数,单位:个
long upPayLoad; // 上行总流量,单位:byte
long downPayLoad; // 下行总流量,单位:byte
public KpiWritable() {
}
public KpiWritable(String upPack, String downPack, String upPay,
String downPay) {
upPackNum = Long.parseLong(upPack);
downPackNum = Long.parseLong(downPack);
upPayLoad = Long.parseLong(upPay);
downPayLoad = Long.parseLong(downPay);
}
@Override
public String toString() {
String result = upPackNum + "\t" + downPackNum + "\t" + upPayLoad
+ "\t" + downPayLoad;
return result;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(upPackNum);
out.writeLong(downPackNum);
out.writeLong(upPayLoad);
out.writeLong(downPayLoad);
}
@Override
public void readFields(DataInput in) throws IOException {
upPackNum = in.readLong();
downPackNum = in.readLong();
upPayLoad = in.readLong();
downPayLoad = in.readLong();
}
}
/*
* 自定义Mapper类,重写了map方法
*/
public static class MyMapper extends
Mapper<LongWritable, Text, Text, KpiWritable> {
@Override
protected void map(
LongWritable k1,
Text v1,
Context context)
throws IOException, InterruptedException {
String[] spilted = v1.toString().split("\t");
String msisdn = spilted[1]; // 获取手机号码
Text k2 = new Text(msisdn); // 转换为Hadoop数据类型并作为k2
KpiWritable v2 = new KpiWritable(spilted[6], spilted[7],
spilted[8], spilted[9]);
context.write(k2, v2);
}
;
}
/*
* 自定义Reducer类,重写了reduce方法
*/
public static class MyReducer extends
Reducer<Text, KpiWritable, Text, KpiWritable> {
@Override
protected void reduce(
Text k2,
Iterable<KpiWritable> v2s,
Context context)
throws IOException, InterruptedException {
long upPackNum = 0L;
long downPackNum = 0L;
long upPayLoad = 0L;
long downPayLoad = 0L;
for (KpiWritable kpiWritable : v2s) {
upPackNum += kpiWritable.upPackNum;
downPackNum += kpiWritable.downPackNum;
upPayLoad += kpiWritable.upPayLoad;
downPayLoad += kpiWritable.downPayLoad;
}
KpiWritable v3 = new KpiWritable(upPackNum + "", downPackNum + "",
upPayLoad + "", downPayLoad + "");
context.write(k2, v3);
}
}
// 输入文件目录
public static final String INPUT_PATH = "hdfs://hadoop-master:9000/testdir/input/HTTP_20130313143750.dat";
// 输出文件目录
public static final String OUTPUT_PATH = "hdfs://hadoop-master:9000/testdir/output/mobilelog";
/*
* 自定义Partitioner类
*/
public static class KpiPartitioner extends Partitioner<Text, KpiWritable> {
//返回值要小于setNumReduceTasks的值
@Override
public int getPartition(Text key, KpiWritable value, int numPartitions) {
// 实现不同的长度不同的号码分配到不同的reduce task中
int numLength = key.toString().length();
if (numLength == 11) {
return 1;
} else {
return 2;
}
}
}
@Override
public int run(String[] args) throws Exception {
String[] otherArgs = {"input/", "output/"};
//配置作业名
Job job = Job.getInstance(this.getConf(), "search");
// 设置自定义Mapper类
job.setMapperClass(MyMapper.class);
// 指定<k2,v2>的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(KpiWritable.class);
// 设置自定义Reducer类
job.setReducerClass(MyReducer.class);
// 指定<k3,v3>的类型
job.setOutputKeyClass(Text.class);
job.setOutputKeyClass(KpiWritable.class);
// 设置Partitioner
job.setPartitionerClass(KpiPartitioner.class);
job.setNumReduceTasks(3);
// // 设置输入,输出目录
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
// 提交作业
Boolean res = job.waitForCompletion(true);
if (res) {
System.out.println("Process success!");
System.exit(0);
} else {
System.out.println("Process failed!");
System.exit(1);
}
return 0;
}
public static void main(String[] args) {
Configuration conf = new Configuration();
try {
int res = ToolRunner.run(conf, new MyKpiJob(), args);
System.exit(res);
} catch (Exception e) {
e.printStackTrace();
}
}
}
删除input文件下面除file1.txt文件的其它文件,修改file1.txt的内容为
1363157985066 13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 24 27 2481 24681 200
1363157995052 13826544101 5C-0E-8B-C7-F1-E0:CMCC 120.197.40.4 4 0 264 0 200
1363157991076 13926435656 20-10-7A-28-CC-0A:CMCC 120.196.100.99 2 4 132 1512 200
1363154400022 13926251106 5C-0E-8B-8B-B1-50:CMCC 120.197.40.4 4 0 240 0 200
1363157993044 18211575961 94-71-AC-CD-E6-18:CMCC-EASY 120.196.100.99 iface.qiyi.com 视频网站 15 12 1527 2106 200
1363157995074 84138413 5C-0E-8B-8C-E8-20:7DaysInn 120.197.40.4 122.72.52.12 20 16 4116 1432 200
1363157993055 13560439658 C4-17-FE-BA-DE-D9:CMCC 120.196.100.99 18 15 1116 954 200
1363157995033 15920133257 5C-0E-8B-C7-BA-20:CMCC 120.197.40.4 sug.so.360.cn 信息安全 20 20 3156 2936 200
1363157983019 13719199419 68-A1-B7-03-07-B1:CMCC-EASY 120.196.100.82 4 0 240 0 200
1363157984041 13660577991 5C-0E-8B-92-5C-20:CMCC-EASY 120.197.40.4 s19.cnzz.com 站点统计 24 9 6960 690 200
1363157973098 15013685858 5C-0E-8B-C7-F7-90:CMCC 120.197.40.4 rank.ie.sogou.com 搜索引擎 28 27 3659 3538 200
1363157986029 15989002119 E8-99-C4-4E-93-E0:CMCC-EASY 120.196.100.99 www.umeng.com 站点统计 3 3 1938 180 200
1363157992093 13560439658 C4-17-FE-BA-DE-D9:CMCC 120.196.100.99 15 9 918 4938 200
1363157986041 13480253104 5C-0E-8B-C7-FC-80:CMCC-EASY 120.197.40.4 3 3 180 180 200
1363157984040 13602846565 5C-0E-8B-8B-B6-00:CMCC 120.197.40.4 2052.flash2-http.qq.com 综合门户 15 12 1938 2910 200
1363157995093 13922314466 00-FD-07-A2-EC-BA:CMCC 120.196.100.82 img.qfc.cn 12 12 3008 3720 200
1363157982040 13502468823 5C-0A-5B-6A-0B-D4:CMCC-EASY 120.196.100.99 y0.ifengimg.com 综合门户 57 102 7335 110349 200
1363157986072 18320173382 84-25-DB-4F-10-1A:CMCC-EASY 120.196.100.99 input.shouji.sogou.com 搜索引擎 21 18 9531 2412 200
1363157990043 13925057413 00-1F-64-E1-E6-9A:CMCC 120.196.100.55 t3.baidu.com 搜索引擎 69 63 11058 48243 200
1363157988072 13760778710 00-FD-07-A4-7B-08:CMCC 120.196.100.82 2 2 120 120 200
1363157985079 13823070001 20-7C-8F-70-68-1F:CMCC 120.196.100.99 6 3 360 180 200
1363157985069 13600217502 00-1F-64-E2-E8-B1:CMCC 120.196.100.55 18 138 1080 186852 200
运行程序MyKpiJob.java,结果生成out目录,里面有执行结果文件“part-r-00000”,“part-r-00001”,“part-r-00002”
IDEA下调试和运行Hadoop程序例子的更多相关文章
- Ubuntu下Eclipse中运行Hadoop程序的参数问题
需要统一的参数: 当配置好eclipse中hadoop的程序后,几个参数需要统一一下: hadoop安装目录下/etc/core_site.xml中 fs.default.name的端口号一定要与ha ...
- 使用ToolRunner运行Hadoop程序基本原理分析
为了简化命令行方式运行作业,Hadoop自带了一些辅助类.GenericOptionsParser是一个类,用来解释常用的Hadoop命令行选项,并根据需要,为Configuration对象设置相应的 ...
- 使用ToolRunner运行Hadoop程序基本原理分析 分类: A1_HADOOP 2014-08-22 11:03 3462人阅读 评论(1) 收藏
为了简化命令行方式运行作业,Hadoop自带了一些辅助类.GenericOptionsParser是一个类,用来解释常用的Hadoop命令行选项,并根据需要,为Configuration对象设置相应的 ...
- eclipse运行hadoop程序报错:Connection refused: no further information
eclipse运行hadoop程序报错:Connection refused: no further information log4j:WARN No appenders could be foun ...
- 【爬坑】在 IDEA 中运行 Hadoop 程序 报 winutils.exe 不存在错误解决方案
0. 问题说明 环境为 Windows 10 在 IDEA 中运行 Hadoop 程序报 winutils.exe 不存在 错误 1. 解决方案 [1.1 解压] 解压 hadoop-2.7.3 ...
- 如何在Ubuntu的idea上运行Hadoop程序
如何在Ubuntu的idea上运行Hadoop程序 一.前言 在idea上运行Hadoop程序,需要使用Hadoop的相关库,Ubuntu为Hadoop的运行提供了良好的支持. 二.操作方法 首先我们 ...
- WIN7下运行hadoop程序报:Failed to locate the winutils binary in the hadoop binary path
之前在mac上调试hadoop程序(mac之前配置过hadoop环境)一直都是正常的.因为工作需要,需要在windows上先调试该程序,然后再转到linux下.程序运行的过程中,报Failed to ...
- hadoop——在命令行下编译并运行map-reduce程序 2
hadoop map-reduce程序的编译需要依赖hadoop的jar包,我尝试javac编译map-reduce时指定-classpath的包路径,但无奈hadoop的jar分布太散乱,根据自己 ...
- 在AE10.1环境下调试其他版本的程序
不同人的可能使用的开发环境不一样,使用SDK版本也不一样,比如用ArcEngine9.3开发的程序在ArcEngine10.1下就不能运行,需要重新调试,才能运行. 这里的例子程序是其他网友在ArcE ...
随机推荐
- 新手学习之浅析一下c/c++中的指针
一.我们先来回忆一下指针的概念吧,方便下面的介绍 指针是存放地址值的变量或者常量.例如:int a=1;&a就表示指针常量(“&”表示取地址运算符,也即引用).int *b,b表示的是 ...
- mybatis进行一对多时发现的问题总结
1.定义一对多xml文件时,所有的resultMap中的column的值一定不要重复,否则mybatis会发生错误,如果有重名,定义别名,column中的名字一定要与查询出的名字一致,如: 52行的别 ...
- Fiddler抓取https的设置
在抓取https的设置中,出现了The root certificate could not be located; 需要下载并安装证书生成器,勾选Capture HTTPS traffic.
- Holer实现外网访问本地MySQL数据库
外网访问内网MySQL数据库 内网主机上安装了MySQL数据库,只能在局域网内访问,怎样从公网也能访问本地MySQL数据库? 本文将介绍使用holer实现的具体步骤. 1. 准备工作 1.1 安装并启 ...
- dubbo could not get local host ip address will use 127.0.0.1 instead 异常处理
dubbo could not get local host ip address will use 127.0.0.1 instead 查看hostname localhost:spring wls ...
- html css样式子元素相对父级元素定位
废话不多说. 父级元素 样式设置: position:relative; 子元素样式: position: absolute; 这样就可以达到子元素相对父级元素定位了.
- tableview前端基础设计(初级版)
tableView前端基础设计 实现的最终效果 操作目的:熟悉纯代码编辑TableView和常用的相关控件SearchBar.NavigationBar.TabBar等,以及布局和基本功能的实现. 一 ...
- Web 建站技术中,HTML、HTML5、XHTML、CSS、SQL、JavaScript、PHP、ASP.NET、Web Services 是什么(转)
Web 建站技术中,HTML.HTML5.XHTML.CSS.SQL.JavaScript.PHP.ASP.NET.Web Services 是什么?修改 建站有很多技术,如 HTML.HTML5.X ...
- css之line-height及图片文字垂直居中
css虽然没有算法,但还是很神奇的,踩到坑都不知道到底是哪里?看到张鑫旭大佬的博客讲的超级好https://www.zhangxinxu.com 行高line-height用到的频率极高,指一行文字的 ...
- git 恢复本地误删文件
git status git reset HEAD 路径(git status 会显示的路径) git checkout 路径