python生成数据后,快速导入数据库
1、使用python生成数据库文件内容
# coding=utf-8
import random
import time
def create_user():
start = time.time()
count = 1000 # 一千万条数据
beginId = 200010000
with open(r"./userInfo.txt", "w") as fp:
for i in range(1,count+1):
id = str(i)
userId = beginId + i
name = ''.join(random.sample('zyxwvutsrqponmlkjihgfedcba', 4)).replace('', '')
sex = str(random.choice(['男', '女']))
weight = str(random.randrange(10, 99))
address = str(random.choice(['北京', '上海', '深圳', '广州', '杭州']))
insert_t_user_weight = (
"INSERT INTO t_user_weight VALUES ('%s', '%s', '%s','%s', '%s', '%s', '%s');"
% (id, userId, name, sex, weight, address, time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))
)
insert_t_user_weight = insert_t_user_weight + '\n'
# print(insert_t_user_weight)
fp.write(insert_t_user_weight)
print('共创建%d条sql耗时:'% count, time.time() - start)
if __name__ == "__main__":
create_user()
2、使用命令导入数据库
load data infile "/tmp/userInfo.txt" into table test_insert fields terminated by ',';
3、MYSQL导入数据出现The MySQL server is running with the --secure-file-priv option so it cannot execute this statement
这个原因是因为在安装MySQL的时候限制了导入与导出的目录权限,只能在规定的目录下才能导入,我们需要通过下面命令查看 secure-file-priv 当前的值是什么。
show variables like '%secure%';
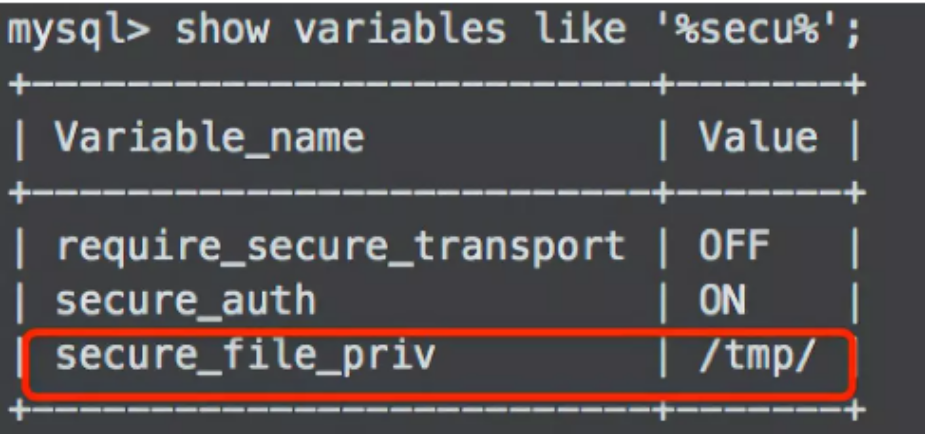
只需要把相对应的文件放在上面的目录下,即可成功读取,而不会报上面的错误了。
python生成数据后,快速导入数据库的更多相关文章
- 图解JanusGraph系列 - 关于JanusGraph图数据批量快速导入的方案和想法(bulk load data)
大家好,我是洋仔,JanusGraph图解系列文章,实时更新~ 图数据库文章总目录: 整理所有图相关文章,请移步(超链):图数据库系列-文章总目录 源码分析相关可查看github(码文不易,求个sta ...
- mysql分批导出数据和分批导入数据库
mysql分批导出数据和分批导入数据库 由于某些原因,比如说测试环境有很多库,需要迁移到新的环境中,不需要导出系统库的数据.而数据库又有好多,如何才能将每个库导出到独立的文件中呢?导入到一个文件的话, ...
- [DJANGO] excel十几万行数据快速导入数据库研究
先贴原来的导入数据代码: 8 import os os.environ.setdefault("DJANGO_SETTINGS_MODULE", "www.setting ...
- excel十几万行数据快速导入数据库研究(转,下面那个方法看看还是可以的)
先贴原来的导入数据代码: 8 import os os.environ.setdefault("DJANGO_SETTINGS_MODULE", "www.setting ...
- python时间序列数据的对齐和数据库的分批查询
欲直接下载代码文件,关注我们的公众号哦!查看历史消息即可! 0. 前言 在机器学习里,我们对时间序列数据做预处理的时候,经常会碰到一个问题:有多个时间序列存在多个表里,每个表的的时间轴不完全相同,要如 ...
- DataTable 快速导入数据库——百万条数据只需几秒
public void InsertTable(DataTable dt, string TabelName, DataColumnCollection dtColum) { string str = ...
- 通过Python将Excel表格信息导入数据库
前言 公司原采用Excel表格方式记录着服务器资产信息,随着业务的增加,相应的硬件资产也增加,同时物理机虚拟化出多台虚拟机,存在表格管理杂乱.变更资产信息不能及时相互同步, 为了紧跟时代的步伐,老大搞 ...
- 包含LOB_Data列的表删除大量数据后表及数据库文件的收缩
最近有一张表(内含varchar(max)字段),占用空间达到240G,删除历史数据后几十万条后,空间并未得到释放. 然后用DBCC CLEANTABLE(0,tb_name,100)来释放删除记录后 ...
- Python生成gexf文件并导入gephi做网络图分析
Gephi是一款优秀的复杂网络分析软件,支持导入多种格式的文件.gexf格式是Gephi 推荐的格式,基于 XML.本文是一个用python写的简单Demo,示例如何生成一个典型的gexf格式文件.代 ...
随机推荐
- 加密:HashUtils,RSAUtil,AESUtils
import java.security.MessageDigest; public class HashUtils { public static String getMD5(String sour ...
- 通过语法设置DNS解析
通过语法设置DNS解析 # 来自 https://dns.he.net/?action=logout # 语法 http://[你的域名]:[你的密码]@dyn.dns.he.net/nic/upda ...
- 关于 永恒之蓝 和 MS17-010 补丁
[KB4012598]:http://www.catalog.update.microsoft.com/Search.aspx?q=KB4012598 适用于Windows XP 32位/64位/嵌入 ...
- 期货大赛项目|六,iCheck漂亮的复选框
废话不多说,直接上图 对,还是上篇文章的图,这次我们不研究datatables,而是看这个复选框,比平常的复选框漂亮太多 看看我是如何实现的吧 插件叫iCheck 用法也简单 引入js和css $(& ...
- P1169 [ZJOI2007]棋盘制作 DP悬线法
题目描述 国际象棋是世界上最古老的博弈游戏之一,和中国的围棋.象棋以及日本的将棋同享盛名.据说国际象棋起源于易经的思想,棋盘是一个8 \times 88×8大小的黑白相间的方阵,对应八八六十四卦,黑白 ...
- BigDecimal类型转换
djjfbr.setMoney(new BigDecimal(djjfbillrecord.getMoney()));
- CLR Via 第一 章 知识点整理(2)程序集和CLR的启动
这一节先简单的讨论一下程序集以及CLR的初始化 虽然对应的编译器会生成托管模块,但实际上CLR不与托管模块工作,编译器除了编译还有将生成的托管模块转换为程序集的功能,微软还提供了工具AL.exe(程序 ...
- String painter HDU - 2476 -区间DP
HDU - 2476 思路:分解问题,先考虑从一个空串染色成 B串的最小花费 ,区间DP可以解决这个问题 具体的就是,当 str [ l ] = = str [ r ]时 dp [ L ] [ R ] ...
- 【SQL】sql语句在insert一条记录后返回该记录的ID
insert into test(name,age) values(') SELECT @@IDENTITY test是表名 重点是这句SELECT @@IDENTITY
- 按比例缩放DIV
class ResponsiveDiv extends React.Component { constructor(props) { super(props); this.state = { widt ...