Spark开发环境搭建(IDEA、Scala、SVN、SBT)
软件版本
| 软件名称 | 版本 | 下载地址 | 备注 |
| Java | 1.8 | https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html | 64位版本的 |
| Scala | 2.10.5 | https://www.scala-lang.org/download/2.10.5.html | |
| SBT | sbt 1.1.6 | https://www.scala-sbt.org/download.html | |
| SVN | 最新版本 | https://tortoisesvn.net/downloads.html | 64位版本 |
| IDEA | http://www.jetbrains.com/idea/ |
安装JDK
下载JDK

安装JDK
下载后直接安装就好了,设置一下安装路径:D:\Program Files\Java
安装完后的文件结构(我的版本是171的)
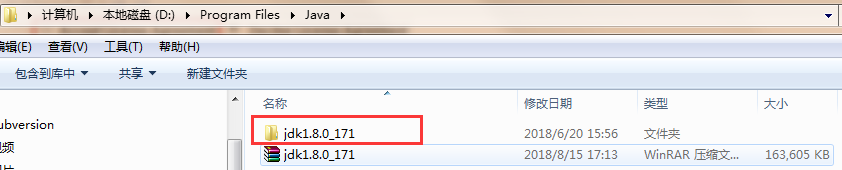
配置环境变量
创建JAVA_HOME:
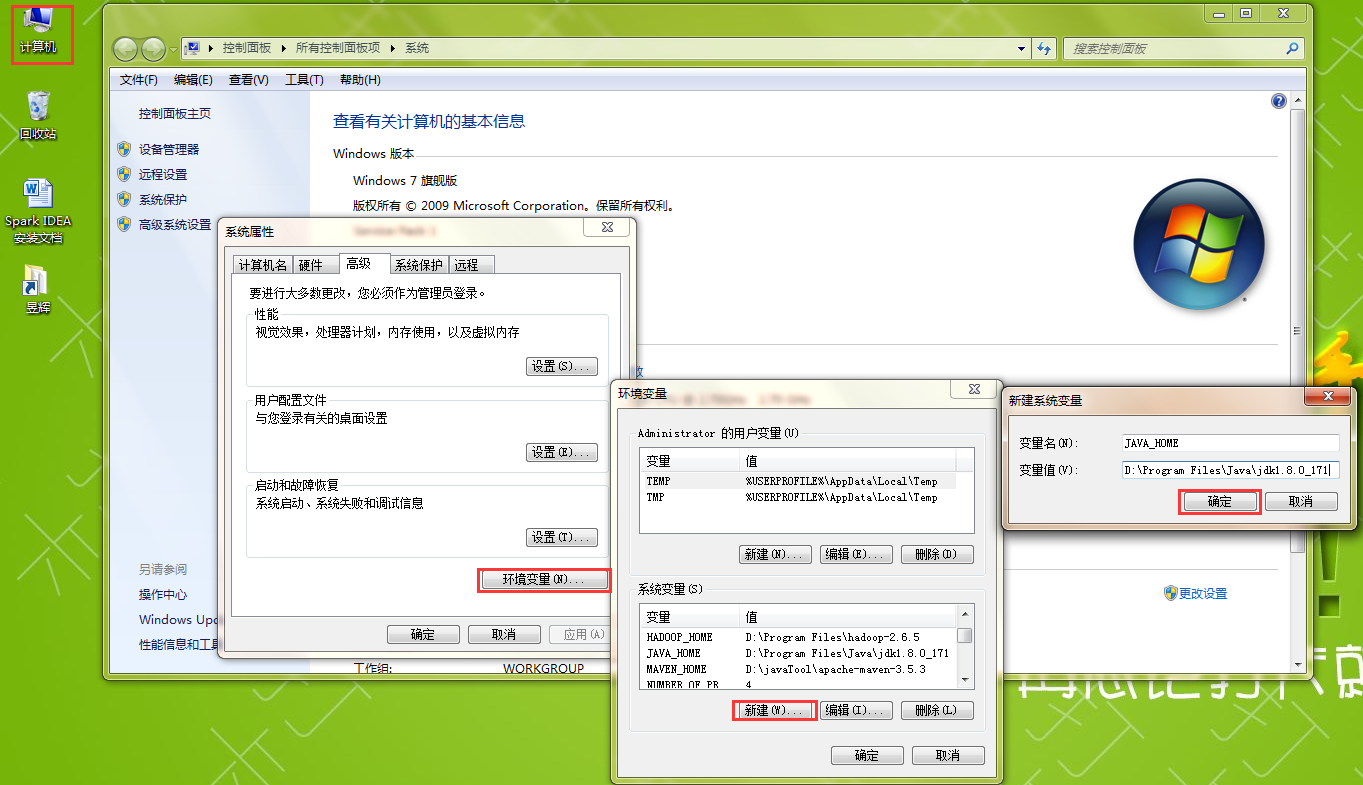
配置path:%JAVA_HOME%\bin;

查看安装情况
打开cmd终端 输入java -version
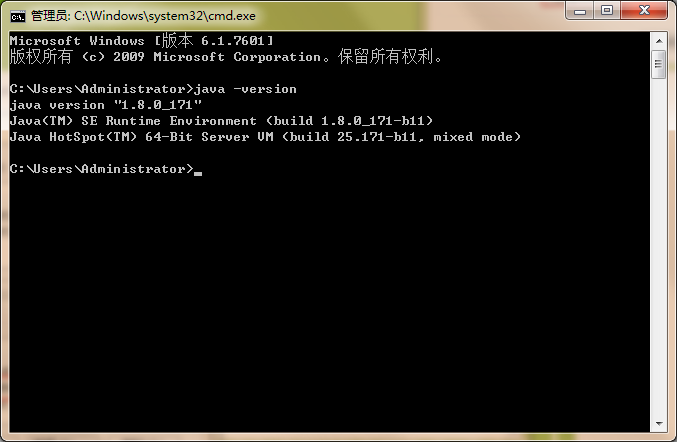
出现java版本号则表示安装成功
安装Scala
下载Scala
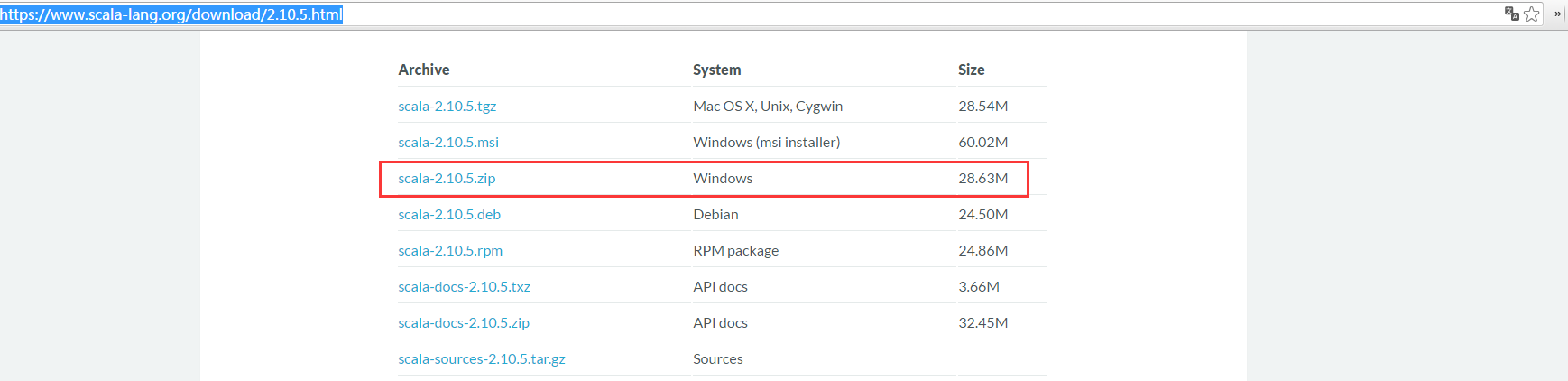
安装Scala
直接解压到D:\Program Files\Scala
解压后文件结构
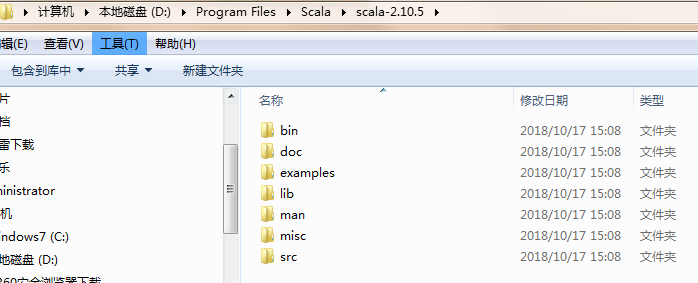
配置环境变量
参考JDK环境变量设置
查看安装情况
输入scala,出现版本号则表示安装成功

安装SVN
下载SVN

安装SVN
制定安装路径:D:\javaTool
这里有个要注意的地方
command line client tools 选项一定要勾选上,否则IDEA配置的时候会找不到svn.exe

配置环境变量
参考JDK环境变量的配置
查看安装情况
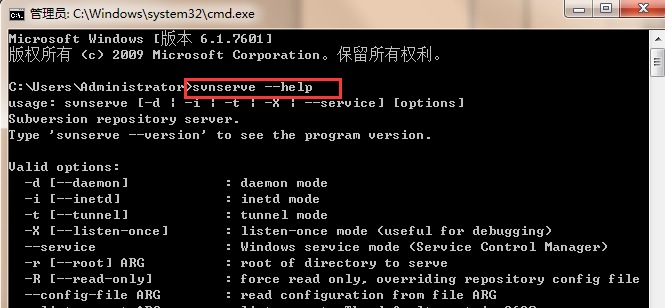
执行svnserve --help,出现一下页面
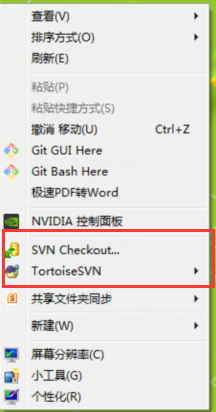
桌面任意位置右键,出现
安装SBT
下载SBT
安装SBT
解压到D:\javaTool,文件结构如下

配置环境变量
参考JDK环境变量设置
配置SBT
repo.repositories
进入D:\javaTool\sbt\conf 下
创建一个文件repo.repositories
编辑以下内容
[repositories]
local
cloudera: https://repository.cloudera.com/artifactory/cloudera-repos/
aliyun: http://maven.aliyun.com/nexus/content/groups/public/
- maven-local: D:/javaTool/mavenLocalRepository cloudera:这是cdh版本的库,如果使用的是cloudera的hadoop全家桶需要使用这个库
aliyun:阿里云的库,国内的比较快
maven-local:因为我还配置了一个Maven,所以可以吧maven的本地仓库加进来,如果没有就不需要加了。
以上是repo.repositories文件的内容
修改完后如下

sbtconfig
编辑sbtconfig文件输入以下内容
# Set the java args to high
-Xmx512M -XX:MaxPermSize=256m -XX:ReservedCodeCacheSize=128m # Set the extra SBT options -Dsbt.log.format=true -Dsbt.ivy.home=D:/javaTool/sbt/ivy
-Dsbt.global.base=D:/javaTool/sbt/.sbt
-Dsbt.repository.config=D:/javaTool/sbt/conf/repo.properties
-Dsbt.log.format=true 说明:前一部分是jvm的一些配置
-Dsbt.ivy.home:是本地库,类似与maven的本地库
-Dsbt.repository.config:指定使用的配置文件
另外另个还没去查找啥意思
配置完如下

到目前为止sbt配置部分就结束了,接下来只要到开一个命令行输入sbt,不出意外的话sbt就会构建成功,会生成D:/javaTool/sbt/ivy等等
但是可能是版本原因,配置的本地仓库并没有生效,jar还是下载到了C盘,在查找资料后,发现还有另一个地方需要配置。
D:\javaTool\sbt\bin\sbt-launch.jar
配置文件是在D:\javaTool\sbt\bin\sbt-launch.jar中的\sbt\sbt.boot.properties中(可用rar解压工具直接打开修改并覆盖,记住是用rar打开文件不需要解压,否则弄不回jar了),修改里面的内容:
[scala]
version: ${sbt.scala.version-auto} [app]
org: ${sbt.organization-org.scala-sbt}
name: sbt
version: ${sbt.version-read(sbt.version)[1.1.6]}
class: ${sbt.main.class-sbt.xMain}
components: xsbti,extra
cross-versioned: ${sbt.cross.versioned-false}
resources: ${sbt.extraClasspath-} [repositories]
local
spring: http://conjars.org/repo/
cloudera: https://repository.cloudera.com/artifactory/cloudera-repos/
aliyun: http://maven.aliyun.com/nexus/content/groups/public/
maven-central
sbt-maven-releases: https://repo.scala-sbt.org/scalasbt/maven-releases/, bootOnly
sbt-maven-snapshots: https://repo.scala-sbt.org/scalasbt/maven-snapshots/, bootOnly
typesafe-ivy-releases: https://repo.typesafe.com/typesafe/ivy-releases/, [organization]/[module]/[revision]/[type]s/[artifact](-[classifier]).[ext], bootOnly
sbt-ivy-snapshots: https://repo.scala-sbt.org/scalasbt/ivy-snapshots/, [organization]/[module]/[revision]/[type]s/[artifact](-[classifier]).[ext], bootOnly [boot]
directory: ${sbt.boot.directory-${sbt.global.base-${user.home}/.sbt}/boot/}
lock: ${sbt.boot.lock-true} [ivy]
ivy-home: D:/javaTool/sbt/ivy
checksums: ${sbt.checksums-sha1,md5}
override-build-repos: ${sbt.override.build.repos-false}
repository-config: ${sbt.repository.config-${sbt.global.base-${user.home}/.sbt}/repositories}
修改后如下:

查看安装情况
再终端执行sbt
经测试,此时下载的jar会放在D:/javaTool/sbt/ivy中,即自己设置的本地库中
安装IDEA
因为我的IDEA早就安装完了,所以在网上找了个教程,参照下面教程就可以把IDEA安装完毕
下载IDEA
关于JDK版本,在scala的官网上有这么一段话
Installation
1.Make sure you have the Java 8 JDK (also known as 1.8)
o Run javac -version on the command line and make sure you seejavac 1.8.___
o If you don’t have version 1.8 or higher, install the JDK
2.Next, download and install IntelliJ Community Edition
3.Then, after starting up IntelliJ, you can download and install the Scala plugin by following the instructions on how to install IntelliJ plugins (search for “Scala” in the plugins menu.)
When we create the project, we’ll install the latest version of Scala. Note: If you want to open an existing Scala project, you can click Open when you start IntelliJ.
大概意思是 需要1.8以上版本的jdk,所以我们需要安装jdk1.8或以上版本
IntelliJ IDEA有免费的社区版(Community Edition)和收费的旗舰版(Ultimate Edition),我安装的是社区版本

安装IDEA
Windows版本安装比较简单,找到我们下载好的exe执行文件,傻瓜式安装,其中的一些选项建议参考下面的
将IDEA安装到:D:\javaTool
操作系统位数选择,大家选择自己操作系统的位数,还有需要安装的一些插件
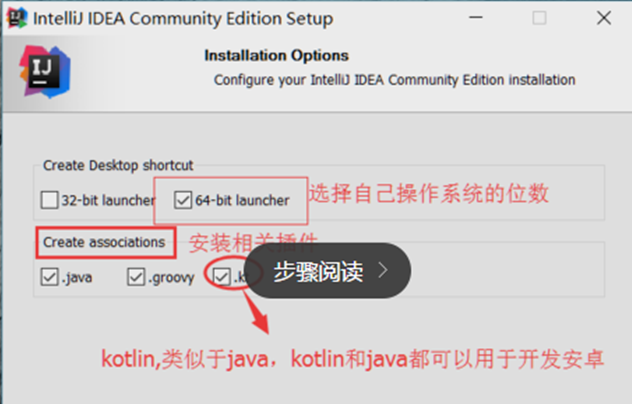
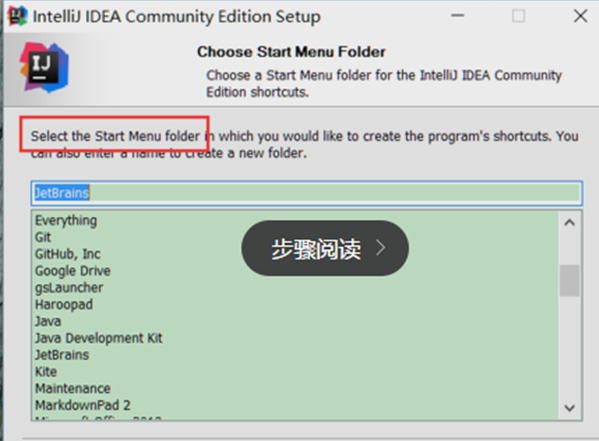
接下来就是选择我们的菜单,然后点击【install】安装就会进入安装过程
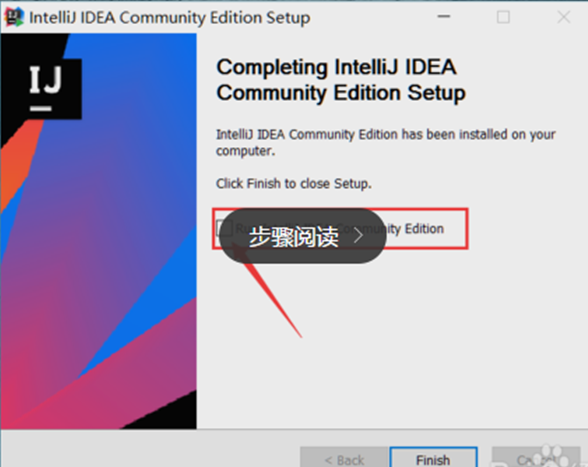
安装完成后,会出现下图【finish】,结束按钮,上面的选项是问我们是否现在打开IDEA
到现在,我们的安装过程就讲完了,我们讲解下如何配置IDEA,假如已经有配置的话,可以直接导入之前的配置,我们选择不导入配置

开始进入配置,首先配置的是IDEA的主题颜色,这里选择了黑色的炫酷色
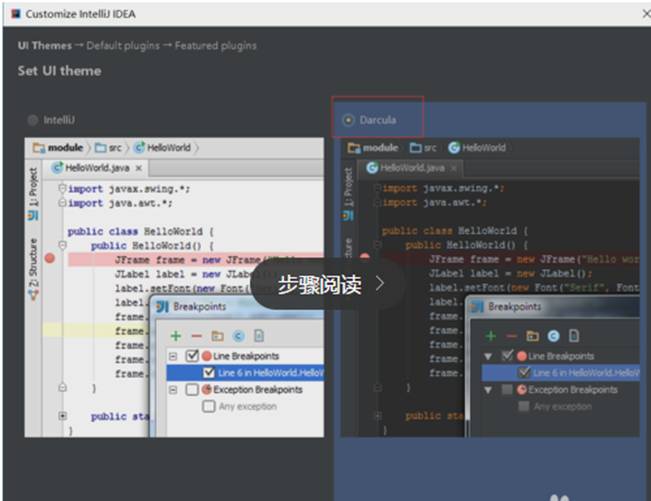
接下来是设置IDEA的一些默认的plugins,也就是默认的插件,大家根据自己的开发需要选择

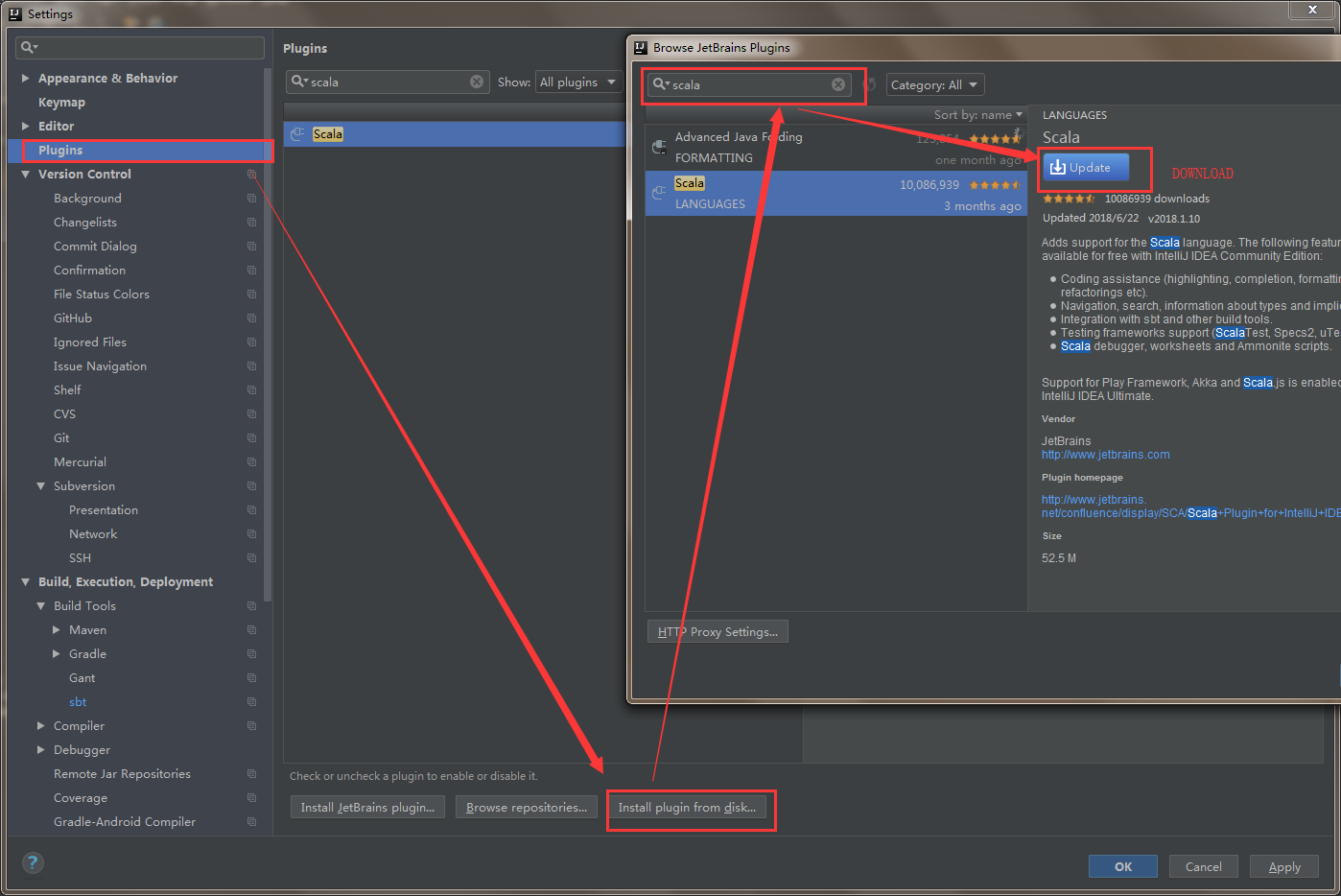
选择,一些第三方的编辑方式,例如vim,可以方便我们在键盘上跳舞,如果要进行scala开发 不建议在此处选择scala插件,下载实在太慢了,可以进入idea后在setting中的plugins中下载插件或者添加已下载的插件
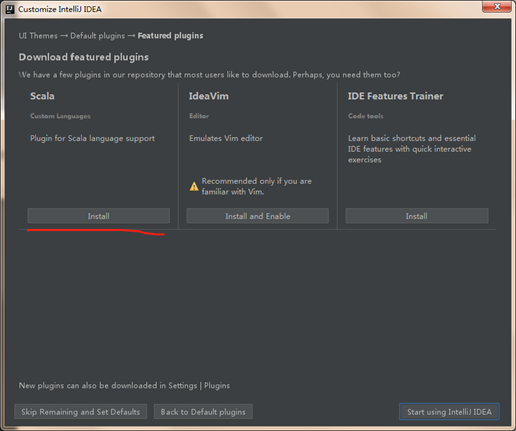
接下来就可以直接开始使用我们的IDEA啦

IDEA的配置


Scala插件安装
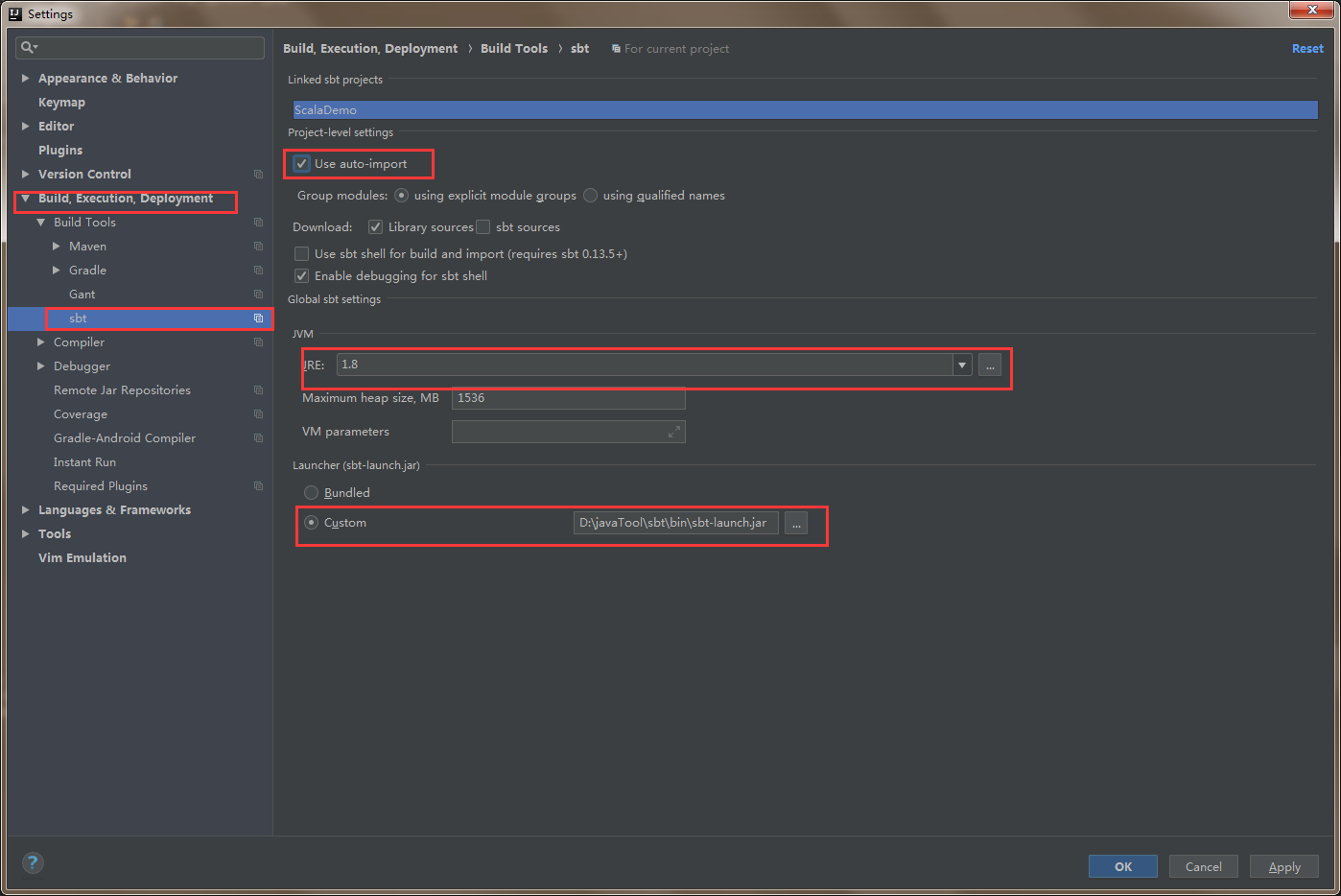
SBT配置
SVN配置

项目配置

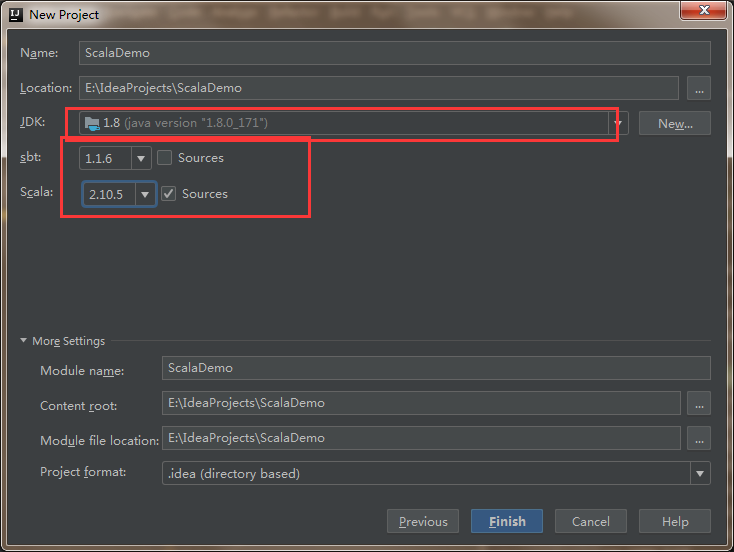
配置JDK
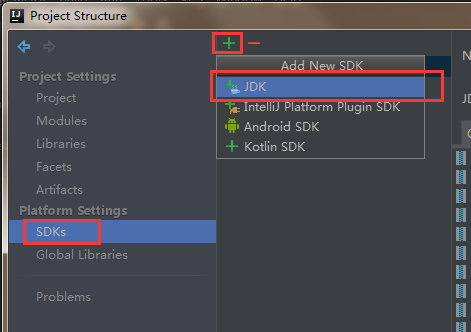
配置scala

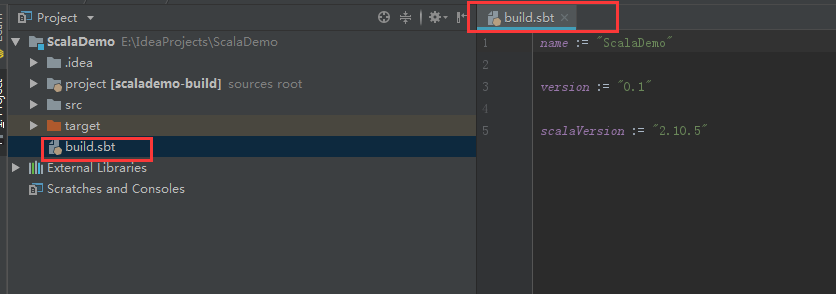
至此配置如果不出意外应该在你的build文件加入相关依赖后,会自动下载相关的jar
最后一点在IDEA中使用SVN
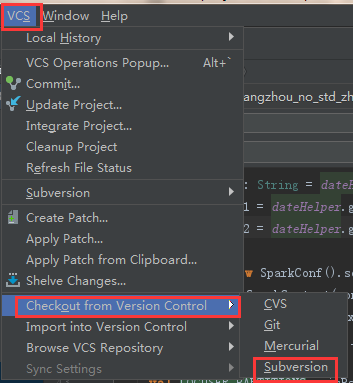

剩下的看着就知道怎么弄了这里就不累赘了
还有更新和提交代码

搞定
遇到的问题(不定期更新)
1、在添加svn项目的时候,由于svn的目录(建议类似的目录不要包含空格和中文)带有中文,
导致项目虽然加进了idea,但是在本地测试的时候由于中文的乱满会导致一些奇怪的错,这个好像是idea的bug,eclipse就没有这样的问题。
解决办法,在导入svn项目的时候,本地存储路径修改为不含有中文和空的的路径即可
Spark开发环境搭建(IDEA、Scala、SVN、SBT)的更多相关文章
- Spark 开发环境搭建
原文见 http://xiguada.org/spark-develop/ 本文基于Spark 0.9.0,由于它基于Scala 2.10,因此必须安装Scala 2.10,否则将无法运行Spar ...
- 【原创干货】大数据Hadoop/Spark开发环境搭建
已经自学了好几个月的大数据了,第一个月里自己通过看书.看视频.网上查资料也把hadoop(1.x.2.x).spark单机.伪分布式.集群都部署了一遍,但经历短暂的兴奋后,还是觉得不得门而入. 只有深 ...
- Spark编译及spark开发环境搭建
最近需要将生产环境的spark1.3版本升级到spark1.6(尽管spark2.0已经发布一段时间了,稳定可靠起见,还是选择了spark1.6),同时需要基于spark开发一些中间件,因此需要搭建一 ...
- Spark开发环境搭建和作业提交
Spark高可用集群搭建 在所有节点上下载或上传spark文件,解压缩安装,建立软连接 配置所有节点spark安装目录下的spark-evn.sh文件 配置slaves 配置spark-default ...
- HBase、Hive、MapReduce、Hadoop、Spark 开发环境搭建后的一些步骤(export导出jar包方式 或 Ant 方式)
步骤一 若是,不会HBase开发环境搭建的博文们,见我下面的这篇博客. HBase 开发环境搭建(Eclipse\MyEclipse + Maven) 步骤一里的,需要补充的.如下: 在项目名,右键, ...
- 【Spark机器学习速成宝典】基础篇01Windows下spark开发环境搭建+sbt+idea(Scala版)
注意: spark用2.1.1 scala用2.11.11 材料准备 spark安装包 JDK 8 IDEA开发工具 scala 2.11.8 (注:spark2.1.0环境于scala2.11环境开 ...
- Spark学习之路(二)—— Spark开发环境搭建
一.安装Spark 1.1 下载并解压 官方下载地址:http://spark.apache.org/downloads.html ,选择Spark版本和对应的Hadoop版本后再下载: 解压安装包: ...
- Spark 系列(二)—— Spark开发环境搭建
一.安装Spark 1.1 下载并解压 官方下载地址:http://spark.apache.org/downloads.html ,选择 Spark 版本和对应的 Hadoop 版本后再下载: 解压 ...
- 入门大数据---Spark开发环境搭建
一.安装Spark 1.1 下载并解压 官方下载地址:http://spark.apache.org/downloads.html ,选择 Spark 版本和对应的 Hadoop 版本后再下载: 解压 ...
随机推荐
- python入门(三)
一.判断(精简代码) 非空为真,非0为真# 不为空的话就是true,是空的话就是false# 只要不是0就是true,是0就是falsea=[]#list也是假的b={}#字典也是假的c=0 #也是假 ...
- Apache强制WWW跳转以及强制HTTPS加密跳转的方法
一般我会较多的使用WORDPRESS程序,其在安装的时候我们如果直接用WWW打开,或者在后台设置WWW域名则默认会强制301指向WWW站点域名.而这里有使用ZBLOG或者TYPECHO等其他博客程序则 ...
- 关注Yumiot公众号,了解最新的物联网资讯
Yumiot,专注于物联网行业,每天不定期推送最新的物联网行业新闻.详情请用微信搜索关注 yumiot .
- ansible-play变量的基本应用
--- - host: appsrvs remote_user: root tasks: - name: install package yum: name={{ pkname }} - name: ...
- 请解释ASP.NET 中的web 页面与其隐藏类之间的关系?
一个ASP.NET 页面一般都对应一个隐藏类,一般都在ASP.NET 页面的声明中指定了隐藏类例如一个页面 Tst1.aspx 的页面声明如下 <%@ Page language="c ...
- Python中集合set()的使用及处理
在Python中集合(set)与字典(dict)比较相似,都具有无序以及元素不能重复的特点 1.创建set 创建set需要一个list或者tuple或者dict作为输入集合 重复的元素在set中会被自 ...
- CentOS7基本配置一
CentOS7基本配置一 安装VMwareTools 1.点击重新安装VM-tool, 继而找到压缩文件VMwareTools-10.2.0...tar.gz,复制到桌面下,解压这么压缩文件到桌面下 ...
- el和jstl标签库讲解视频
https://www.bilibili.com/video/av22415283/?p=1
- cocos Studio使用问题
使用的时候最好是同一套资源饭在一个文件夹下,或者新建的文件和资源类,一个资源分一个产生的层文件
- Problem: 棋盘小游戏(一道有意思的acm入门题
Problem Description 现有一个2行13列的棋盘,棋盘上的任意一个位置可以向他临近的8个位置移动.棋盘上的每一个位置的标号由一个大写的英文字母表示.现在给你一个移动的顺序,问你如何设置 ...