YouTube数据:谁获得了最多订阅者?
原文来源:
https://www.kaggle.com/roshan77/youtube-data-who-got-the-most-subscribers
介绍:
Python笔记 使用来自Socialblade的Youtube前5000个频道的数据。
数据来源:
Socialblade提供的Youtube最受欢迎的5000个频道数据。
Socialblade列出的YouTube前5000个频道的总体指标。
https://www.kaggle.com/mdhrumil/top-5000-youtube-channels-data-from-socialblade
数据下载:https://www.kaggle.com/mdhrumil/top-5000-youtube-channels-data-from-socialblade/downloads/top-5000-youtube-channels-data-from-socialblade.zip/2
你对以下方面感兴趣:
1、哪个YouTube频道拥有最多的观众、订阅者、视频上传量等等?
2、更多的视频上传会带来更多的视频浏览量和更多的订阅者吗?
3、更多的用户会提供更多的视频浏览量吗?
4、有没有一种方法可以根据频道上传的视频数量和观看视频的次数来预测订阅用户的数量?
我试着用一些视觉工具和分析工具来回答这些问题。
import numpy as np
import pandas as pd
import os
print(os.listdir("../input")) #选择数据存放路径 获取到data.csv文件
[‘data.csv’]
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn import metrics
import statsmodels.api as sm
from pandas.core import datetools
df = pd.read_csv('../input/data.csv')
df.head()
Out():
Rank Grade Channel name Video Uploads Subscribers Video views
1st A++ Zee TV 82757 18752951 20869786591
2nd A++ T-Series 12661 61196302 47548839843
3rd A++ Cocomelon-Nursery Rhymes 373 19238251 9793305082
4th A++ SET India 27323 31180559 22675948293
5th A++ WWE 36756 32852346 26273668433
df.tail()
Out():
Rank Grade Channel name Video Uploads Subscribers Video views
4995 4,996th B+ Uras Benlioğlu 706 2072942 441202795
4996 4,997th B+ HI-TECH MUSIC LTD 797 1055091 377331722
4997 4,998th B+ Mastersaint 110 3265735 311758426
4998 4,999th B+ Bruce McIntosh 3475 32990 14563764
4999 5,000th B+ SehatAQUA 254 21172 73312511
df.info()
Out():
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 5000 entries, 0 to 4999
Data columns (total 6 columns):
Rank 5000 non-null object
Grade 5000 non-null object
Channel name 5000 non-null object
Video Uploads 5000 non-null object
Subscribers 5000 non-null object
Video views 5000 non-null int64
dtypes: int64(1), object(5)
memory usage: 234.5+ KB
#df['Subscribers'] = df['Subscribers'].convert_objects(convert_numeric=True)
#df['Video Uploads'] = df['Video Uploads'].convert_objects(convert_numeric=True)
df['Subscribers'] = pd.to_numeric(df['Subscribers'], errors='coerce')
df['Video Uploads'] = pd.to_numeric(df['Video Uploads'], errors='coerce')
探索性数据分析
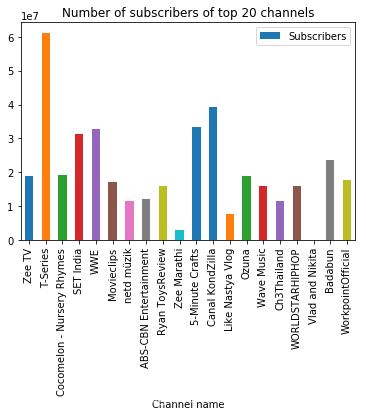
在这里,我首先绘制一些条形图,显示每种通道分类的前20名。根据排名,前三名都是前20名,他们的上传视频数量、订阅者和视频浏览量都在前三名。根据每个小组各自的情况,最后三名都进入了前20名。
df.head(20).plot.bar(x = 'Channel name', y = 'Subscribers')
plt.title('Number of subscribers of top 20 channels')
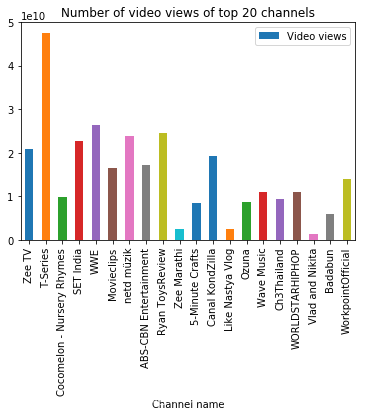
df.head(20).plot.bar(x = 'Channel name', y = 'Video views')
plt.title('Number of video views of top 20 channels')
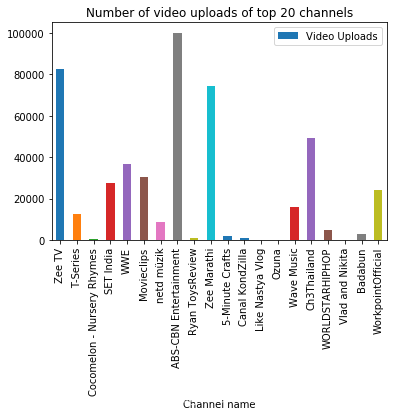
df.head(20).plot.bar(x = 'Channel name', y = 'Video Uploads')
plt.title('Number of video uploads of top 20 channels')
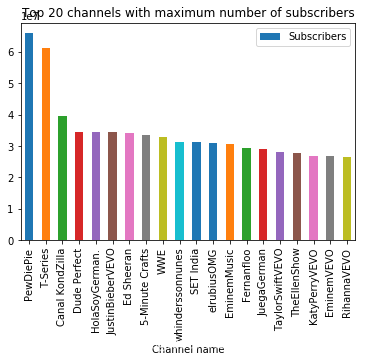
df.sort_values(by = ['Subscribers'], ascending = False).head(20).plot.bar(x = 'Channel name', y = 'Subscribers')
plt.title('Top 20 channels with maximum number of subscribers')
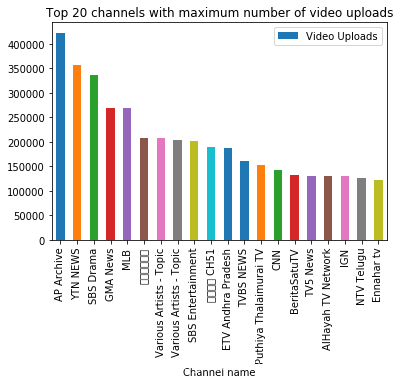
df.sort_values(by = ['Video views'], ascending = False).head(20).plot.bar(x = 'Channel name', y = 'Video views')
plt.title('Top 20 channels with maximum number of video views')
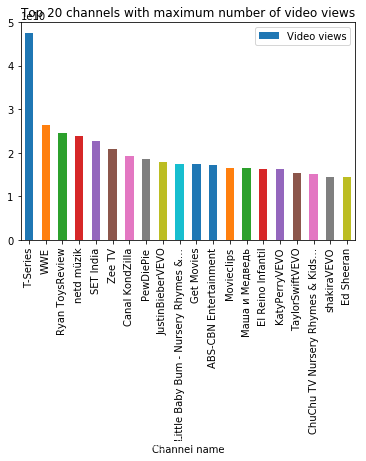
df.sort_values(by = ['Video Uploads'], ascending = False).head(20).plot.bar(x = 'Channel name', y = 'Video Uploads')
plt.title('Top 20 channels with maximum number of video uploads')
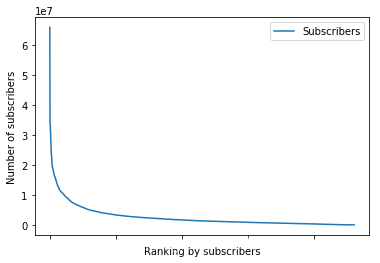
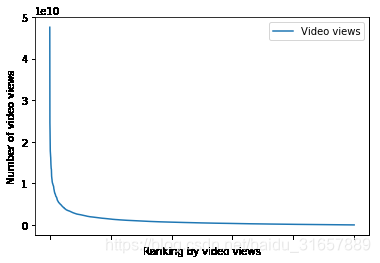
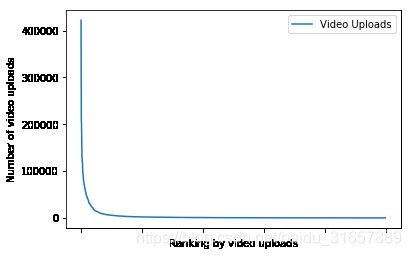
在这里,我感兴趣的是列表中的所有通道是如何按照订阅服务器、视频上传和订阅服务器在每个类中从最大值到最小值分布的。令人感兴趣的是,在顶部列表处有巨大的峰值,并且趋向于快速地获得一个趋于平缓的平台。
df.sort_values(by = ['Subscribers'], ascending = False).plot(x = 'Channel name', y = 'Subscribers')
plt.xlabel('Ranking by subscribers')
plt.ylabel('Number of subscribers')
df.sort_values(by = ['Video views'], ascending = False).plot(x = 'Channel name', y = 'Video views')
plt.xlabel('Ranking by video views')
plt.ylabel('Number of video views')
df.sort_values(by = ['Video Uploads'], ascending = False).plot(x = 'Channel name', y = 'Video Uploads')
plt.xlabel('Ranking by video uploads')
plt.ylabel('Number of video uploads')
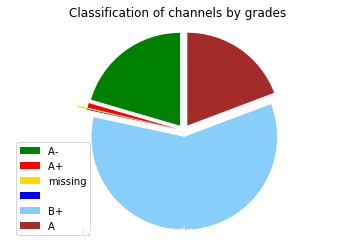
按照频道等级分析
grade_name = list(set(df['Grade']))
grade_name
output:['A- ', 'A+ ', 'A++ ', '\xa0 ', 'B+ ', 'A ']
df_by_grade = df.set_index(df['Grade'])
count_grade = list()
for grade in grade_name:
count_grade.append(len(df_by_grade.loc[[grade]]))
df_by_grade.head()
out:
Grade Rank Grade Channel name Video Uploads Subscribers Video views
A++ 1st A++ Zee TV 82757.0 18752951.0 20869786591
A++ 2nd A++ T-Series 12661.0 61196302.0 47548839843
A++ 3rd A++ Cocomelon - Nursery Rhymes 373.0 19238251.0 9793305082
A++ 4th A++ SET India 27323.0 31180559.0 22675948293
A++ 5th A++ WWE 36756.0 32852346.0 26273668433
print(count_grade)
print(grade_name)
out:
[963, 2956, 10, 1024, 41, 6]
['A ', 'B+ ', 'A++ ', 'A- ', 'A+ ', '\xa0 ']
grade_name[2] = 'missing'
labels = grade_name
sizes = count_grade
explode1 = (0.2, 0.2, 0.5, 0.2, 0.2, 0.2)
color_list = ['green', 'red', 'gold', 'blue', 'lightskyblue', 'brown']
patches, texts = plt.pie(sizes, colors = color_list, explode = explode1,
shadow = False, startangle = 90, radius = 3)
plt.legend(patches, labels, loc = "best")
plt.axis('equal')
plt.title('Classification of channels by grades')
plt.show()
df.describe()
out:
Video Uploads Subscribers Video views
count 4994.000000 4.613000e+03 5.000000e+03
mean 3859.463556 2.620004e+06 1.071449e+09
std 17085.866498 3.926447e+06 2.003844e+09
min 1.000000 3.010000e+02 7.500000e+01
25% 141.000000 6.098940e+05 1.862329e+08
50% 443.000000 1.350477e+06 4.820548e+08
75% 1501.750000 2.950056e+06 1.124368e+09
max 422326.000000 6.599531e+07 4.754884e+10
变量之间的关系
从下图可以看出,订阅者的数量与观看者的数量呈正相关关系。这是预期。但用户数量与该频道上传的视频数量呈负相关。这可能令人惊讶。吸引更多浏览者的视频频道和用户上传的视频数量都在减少。
YouTube数据:谁获得了最多订阅者?的更多相关文章
- C# 数据推送 实时数据推送 轻量级消息订阅发布 多级消息推送 分布式推送
前言 本文将使用一个NuGet公开的组件技术来实现数据订阅推送功能,由服务器进行推送数据,客户端订阅指定的数据后,即可以接收服务器推送过来的数据,包含了自动重连功能,使用非常方便 nuget地址:ht ...
- L1-2. 点赞【求多组数据中出现次数最多的】
L1-2. 点赞 时间限制 200 ms 内存限制 65536 kB 代码长度限制 8000 B 判题程序 Standard 作者 陈越 微博上有个“点赞”功能,你可以为你喜欢的博文点个赞表示支持.每 ...
- 使用SQLServer同义词和SQL邮件,解决发布订阅中订阅库丢失数据的问题
最近给客户做了基于SQLServer的发布订阅的“读写分离”功能,但是某些表数据很大,经常发生某几条数据丢失的问题,导致订阅无法继续进行.但是每次发现问题重新做一次发布订阅又非常消耗时间,所以还得根据 ...
- SQL Server 复制 - 发布订阅(SQL Server 数据同步)
原文:SQL Server 复制 - 发布订阅(SQL Server 数据同步) SQL Server的同步是通过SQL Server自带的复制工具来实现的,分发布和订阅2大步. A,复制-发布 发布 ...
- Angular通过订阅观察者对象实现不同组件中数据的实时传递
在angular官方定义中,组件直接的数据交换只要在父子直接传递,但是我们在项目中经常需要在各种层级之间传递数据,下面介绍关于订阅可观察对象实现的数据传递. 首先定义一个服务app.sevice.ts ...
- vue双向绑定(数据劫持+发布者-订阅者模式)
参考文献:https://www.cnblogs.com/libin-1/p/6893712.html 实现mvvm主要包含两个方面,数据变化更新视图,视图变化更新数据. 关键点在于data如何更新v ...
- Sql2008 r2 使用ftp 公布和订阅方式同步数据
Sql2008 r2使用公布和订阅方式同步数据 因为非常多图片 本篇没有图片 详情能够进入下载页 http://download.csdn.net/download/yefighter/760374 ...
- SQLServer 可更新订阅数据在线架构更改(增加字段)方案
原文:SQLServer 可更新订阅数据在线架构更改(增加字段)方案 之前一直查找冲突发布和订阅数据不一致的原因,后来发现多少数据库升级引起,因为一直以来都是在发布数据库增加字段,订阅也会自动同步.在 ...
- [Vue源码]一起来学Vue双向绑定原理-数据劫持和发布订阅
有一段时间没有更新技术博文了,因为这段时间埋下头来看Vue源码了.本文我们一起通过学习双向绑定原理来分析Vue源码.预计接下来会围绕Vue源码来整理一些文章,如下. 一起来学Vue双向绑定原理-数据劫 ...
随机推荐
- CodeForces - 1040B Shashlik Cooking(水题)
题目: B. Shashlik Cooking time limit per test 1 second memory limit per test 512 megabytes input stand ...
- swiper使用中一些点的总结
最近做了PC端改版,要求移动端有更好的体验,一些产品滚屏的展示,就用了swiper插件,以方便用户在移动端访问可以滑动翻屏展示. 本次项目中使用的是swiper2.0版本. 首先要引入swiper的j ...
- python 生成器(generator)的生成方式
generator包括生成器和带yield的generator函数. 写了一个生成杨辉三角的小例子: # -*- coding:utf-8 -*- def triangles(): l = [1] w ...
- using Newtonsoft.Json;
using Newtonsoft.Json; //数组转义为json string result = JsonConvert.SerializeObject(list1); //josn转 ...
- P1403 [AHOI2005]约数研究 题解
转载luogu某位神犇的题解QAQ 这题重点在于一个公式: f(i)=n/i 至于公式是怎么推出来的,看我解释: 1-n的因子个数,可以看成共含有2因子的数的个数+含有3因子的数的个数……+含有n因子 ...
- 5 第一个Django第4部分(表单和通用视图)
上一节完成了视图编写,这一节为应用添加投票功能,也就是表单提交. 5.1编写一个简单的表单 5.2使用通用视图 5.3改良视图 5.1编写一个简单的表单 在网页设计中添加Form元素 polls/te ...
- install openjdk & tomcat on the centos
1.检查当前服务器是否已安装openjdk
- shell编程(二)
第三十二次课 shell编程(二) 目录 十五.shell中的函数 十六.shell中的数组 十七.告警系统需求分析 十八.告警系统主脚本 十九.告警系统配置文件 二十.告警系统监控项目 二十一.告警 ...
- java基础知识—运算符和基本选择结构
1.保存真假,使用boolean变量 boolean有两个值:true 真 false 假 2.从控制台接受输入信息,通过创建扫描器 Sacnner input=new Sacnner(System. ...
- VS添加WebService工具
最近在做和WebService相关的项目,因为只是在学校里面用过,出来工作一直没有用到,所以不是很熟悉,于是自己配置了一个WebService工具给添加到了VS(VisualStudio)里面,其实就 ...