Rich feature hierarchies for accurate object detection and semantic segmentation(理解)
0 - 背景
该论文是2014年CVPR的经典论文,其提出的模型称为R-CNN(Regions with Convolutional Neural Network Features),曾经是物体检测领域的state-of-art模型。
1 - 相关知识补充
1.1 - Selective Search
该算法用来产生粗选的regions区域,在我的另一篇博文Selective Search for Object Recognition(理解)中进行详细讲解。
1.2 - 无监督预训练&有监督预训练
1.2.1 - 无监督预训练(Unsupervised pre-traning)
栈式自编码、DBM采用的都是无监督预训练,预训练阶段样本不需要人工标注数据。(详细思路后续再进行补充)
1.2.2 - 有监督预训练(Supervised pre-training)
有监督预训练可以称为迁移学习,通过在别的训练集上训练好网络之后将参数作为当前任务网络的初始化参数,相比直接采用随机初始化等方法其精度有很大提高。
在该论文提出的时候,图片分类的训练数据相比物体检测的数据多得多,因此通过用分类数据集预训练网络而后再将参数用于目标检测网络参数的初始化,是该论文的一个亮点。
1.3 - IOU
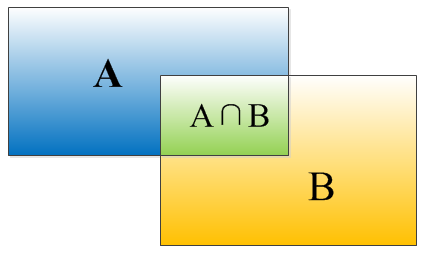
IOU是算法给出的bounding box和真实box的匹配程度,其计算公式为$IOU=\frac{(A\cap B)}{(A\cup B)}$,等价于$IOU=\frac{S_I}{(S_A+S_B-S_I)}$
1.4 - 非极大值抑制
如下图,在检测一个目标时候算法可能会给出一堆的bounding boax,这时候需要判断哪些bounding box是没用的,将它们丢掉。先假设有6个bounding box,根据分类器类别分类概率做排序,从小到大分别属于目标概率为A、B、C、D、E、F。
- 从最大概率矩形框F开始,分别判断A~E与F的重叠度IOU时候大于设定的阈值
- 假设B、D与F的重叠度超过阈值,那么就丢掉B、D;并标记第一个bounding box F是我们保留下来的
- 从剩下的bounding box A、C、E中,选择概率最大的E,然后判断A、C与E的重叠度,重叠度大于阈值就扔掉,并标记E是我们保留下来的第二个bounding box
- 重复上述过程,找到所有被保留下来的bounding box

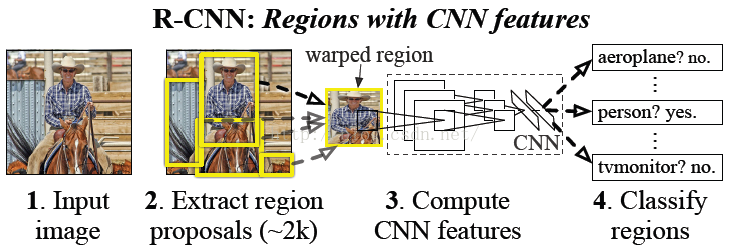
2 - 整体思路
首先输入一张图片,通过selective search定位出2000个物体检测框,然后采用CNN提取每个候选框中图片的特征向量,特征向量的维度为4096维,而后采用线性SVM对每个特征向量进行分类。概括起来有如下三个步骤:
- 找出候选框
- 每一个候选框采用CNN提取特征向量
- 利用线性SVM对特征向量进行分类
- 对分类好的region proposal进行边界回归,用bounding box回归值校正原来的建议窗口,生成预测窗口坐标
2.1 - 各向异性&各向同性缩放
由于selective search生成出的候选框大小规模都不一样,而传统CNN要求输入的图像尺度必须是固定的,因此需要采用各向异性或者各向同性缩放的方法来对图像大小进行缩放。
2.1.1 - 各向异性缩放
不管图片的长宽比例,直接缩放成固定的$227 \times 227$,如下图(D)所示,优点是简单,缺点是很容易造成目标扭曲变形等等。
2.1.2 - 各向同性缩放
- 方法一:直接在原始图片中,把bounding box的边界扩展成需要的固定尺度,然后再进行裁剪,如果已经延伸到原始图片边界外,采用bounding box中的像素颜色均值进行填充,如下图(B)所示
- 方法二:先把bounding box裁剪出来,然后用固定的背景颜色填充成所需的固定大小尺度(背景颜色也是采用bounding box的像素颜色均值),如下图(C)所示

论文中还提出了padding处理,上图1、3行采用了padding=0,而2、4行采用了padding=16。经过试验,作者发现采用各向异性缩放、padding=16的精度最高(这里作者提出,图像扭曲的影响并没有我们直观感觉到的那么大)。
2.2 - 正负样本标注
上述产生的bounding box不可能刚刚好和人工标注的box完全匹配,因此我们需要对这些bounding box打上标签,方便下一步CNN训练使用。标注根据如下规则:
- 如果该bounding box与真实box的IOU大于0.5,则为正样本,打上对应物体类别的标签
- 否则为负样本,将其归为背景的类别
2.3 - 训练
2.3.1 - CNN网络架构
提取特征的CNN结构有两个可选方案:Alexnet和VGG 16,经过测试Alexnet精度为58.5%,VGG 16精度为66%,但VGG 16的计算量大约是Alexnet的7倍。
2.3.2 - CNN有监督预训练
目标检测的数据集较小,采用随机初始化参数则目前的训练量远远不够,因此先用ImageNet的分类数据集训练CNN,而后将模型结构微调成适应检测任务,直接采用分类模型参数,再做fine-tuning训练。(采用随机梯度下降优化方法,学习率大小为0.001)。
2.3.3 - fine-tuning阶段
采用selective search生成的候选框,将其处理到指定大小尺度,对上面有监督预训练后的CNN模型进行fine-tuning训练。假设要检测的物体类别有N类,则需要将预训练的CNN模型最后一层替换成N+1个输出的神经元(额外加1表示背景),这一层采用随机初始化方法,其他网络层参数不变,再采用SGD(随机梯度下降)训练就可以了。(注:SGD学习率选择为0.001,batch size为128,其中32个正样本+86个负样本)。
2.3.3 - 关于CNN的思考
疑问1:如果直接采用Alexnet作为特征提取器而不做fine-tuning训练是否可以?
论文中也对该想法进行了实验,实验结果表明直接采用网络中$p_5$的输出作为特征提取结果的精度跟$f_6$和$f_7$差不多,反而$f_6$提取到的特征还比$f_7$的精度略高。可以总结出一个规则,如果不针对特定任务进行fine-tuning,而是把CNN作为特征提取器,卷积层所学到的特征其实是基础的泛化的特征,而后续的全连接层更多的学习到是特定任务的表示。
疑问2:CNN的输出可以通过一个softmax层直接达成分类目的,为何还需要通过SVM进行分类?
通过上述正负样本标注过程可以知道,训练集中正样本远比负样本少,并且只要IOU大于0.5便标注为正样本(条件宽松),而CNN的效果跟训练数据的大小有一定关系,所以少量的标注数据对于CNN来说还是不够,而SVM更适用于少量样本,因此SVM的效果会比softmax好,所以作者采用了额外的SVM分类器。(注:通过实验发现,当IOU的阈值采用0.3的时候效果最好,采用0.0的时候下降了4个百分点,采用0.5的时候下降了5个百分点)
3 - 参考资料
https://blog.csdn.net/mydear_11000/article/details/51882818
https://blog.csdn.net/liyaohhh/article/details/50824226
https://www.cnblogs.com/CZiFan/p/9901729.html
Rich feature hierarchies for accurate object detection and semantic segmentation(理解)的更多相关文章
- 目标检测--Rich feature hierarchies for accurate object detection and semantic segmentation(CVPR 2014)
Rich feature hierarchies for accurate object detection and semantic segmentation 作者: Ross Girshick J ...
- 论文笔记:Rich feature hierarchies for accurate object detection and semantic segmentation
在上计算机视觉这门课的时候,老师曾经留过一个作业:识别一张 A4 纸上的手写数字.按照传统的做法,这种手写体或者验证码识别的项目,都是按照定位+分割+识别的套路.但凡上网搜一下,就能找到一堆识别的教程 ...
- 目标检测系列 --- RCNN: Rich feature hierarchies for accurate object detection and semantic segmentation Tech report
目标检测系列 --- RCNN: Rich feature hierarchies for accurate object detection and semantic segmentation Te ...
- 2 - Rich feature hierarchies for accurate object detection and semantic segmentation(阅读翻译)
Rich feature hierarchies for accurate object detection and semantic segmentation Ross Girshick Jeff ...
- 深度学习论文翻译解析(八):Rich feature hierarchies for accurate object detection and semantic segmentation
论文标题:Rich feature hierarchies for accurate object detection and semantic segmentation 标题翻译:丰富的特征层次结构 ...
- 论文阅读笔记二十四:Rich feature hierarchies for accurate object detection and semantic segmentation Tech report(R-CNN CVPR2014)
论文源址:http://www.cs.berkeley.edu/~rbg/#girshick2014rcnn 摘要 在PASCAL VOC数据集上,最好的方法的思路是将低级信息与较高层次的上下文信息进 ...
- 目标检测论文解读1——Rich feature hierarchies for accurate object detection and semantic segmentation
背景 在2012 Imagenet LSVRC比赛中,Alexnet以15.3%的top-5 错误率轻松拔得头筹(第二名top-5错误率为26.2%).由此,ConvNet的潜力受到广泛认可,一炮而红 ...
- 论文笔记(一)---翻译 Rich feature hierarchies for accurate object detection and semantic segmentation
论文网址: https://arxiv.org/abs/1311.2524 RCNN利用深度学习进行目标检测. 摘要 可以将ImageNet上的进全图像分类而训练好的大型卷积神经网络用到PASCAL的 ...
- R-CNN(Rich feature hierarchies for accurate object detection and semantic segmentation)论文理解
论文地址:https://arxiv.org/pdf/1311.2524.pdf 翻译请移步: https://www.cnblogs.com/xiaotongtt/p/6691103.html ht ...
随机推荐
- SDOI2019R1游记
差点退役,真是开心 Day -2 吐了一晚上,差点死掉 被拉去医院打针,结果蛇皮的被扎了两针,真是好疼啊嘤嘤嘤 决定第二天在家里咕一天 Day -1 结果在家里也得做\(loli\)昨天的不知道从哪里 ...
- MyCP(课下作业,必做)
MyCP(课下作业,必做) 要求 编写MyCP.java 实现类似Linux下cp XXX1 XXX2 的功能,要求MyCP支持两个参数: java MyCP -tx XXX1.txt XXX2.bi ...
- logrotate日志处理
介绍 logrotate旨在简化生成大量日志文件的系统的管理.它允许日志文件的自动轮换.压缩.删除和邮件.每个日志文件可以每天.每周.每月处理,也可以在它变得太大时处理.通常,logrotate作为每 ...
- Do You Kown Asp.Net Core -- Asp.Net Core 2.0 未来web开发新趋势 Razor Page
Razor Page介绍 前言 上周期待已久的Asp.Net Core 2.0提前发布了,一下子Net圈热闹了起来,2.0带来了很多新的特性和新的功能,其中Razor Page引起我的关注,作为web ...
- 家庭记账本小程序之查(java web基础版六)
实现查询消费账单 1.main_left.jsp中该部分,调用search.jsp 2.search.jsp,提交到Servlet中的search方法 <%@ page language=&qu ...
- react的jsx语法
在webpack.config.js中配置解析的loader { test:/\.jsx?$/, use:{ loader:"babel-loader", options:{ pr ...
- Django配置404页面
一.settings配置 1.首先需要在settings中将DEBUG由原来的True改为False DEBUG = False 2.需要设置 ALLOWED_OSTS = ["*" ...
- 证明与计算(4): 完美散列函数(Perfect Hash function)
原文:wiki: 完美散列函数 假设,写一个SQL语句解析器,词法分析对SQL语句解析,把语句分成了多个token,一般这个时候会需要查询这个token是否是一个关键字token. 例如keyword ...
- [转帖]十二 个经典 Linux 进程管理命令介绍
https://www.cnblogs.com/swordxia/p/4550825.html 接了 http referer 头 没法显示图片 可以去原始blog 里面去查看. 随笔- 109 ...
- gitignore的使用
gitignore的作用是忽略文件的提交,被加入到gitignore中的文件不会被提交到文件服务器 通常需要添加到.gitignore的文件有: (1)缓存相关文件,编译相关文件,运行时相关文件 (2 ...