Coursera, Big Data 1, Introduction (week 3)
什么是分布式文件系统?为什么需要分布式文件系统?
如果文件系统可以管理用网络连接的很多个存储单元,叫分布式文件系统. 分布式文件系统提供了数据可扩展性,容错性,高并发. 这些是传统文件系统不具有的.
Hadoop getting started
为什么用Hadoop? Hadoop 的 4 个What 和 How.

Hadoop 的主要Goal:
1. 可扩展来增加 node
2. 容错,Node down 可以很容易recover
3. 可以读取各种格式的数据(structured, unstructured)
4. 把task 分配到不同node,具有并行计算能力
Hadoop 生态系统:
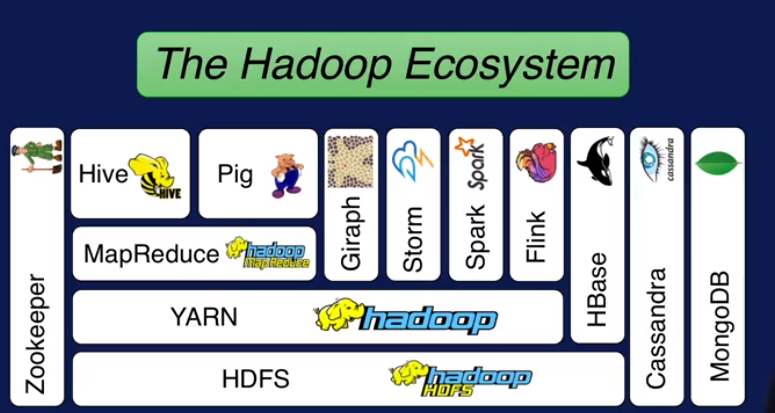
接下来先将整个Hadoop 生态系统,然后讲主要模块(HDFS分布式存储, YARN提供调度和资源管理, MapReduce并行计算) ,最后讲云计算(IaaS, PaaS, SaaS), 此外还有什么时候不适用 Hadoop.
Hadoop生态系统:
前面已经提到了HDFS 是管理分布式存储的, YARN 是负责调度和管理资源的,MapReduce 是做分布式计算的,用户只需要写两个函数就可以实现分布式计算了.
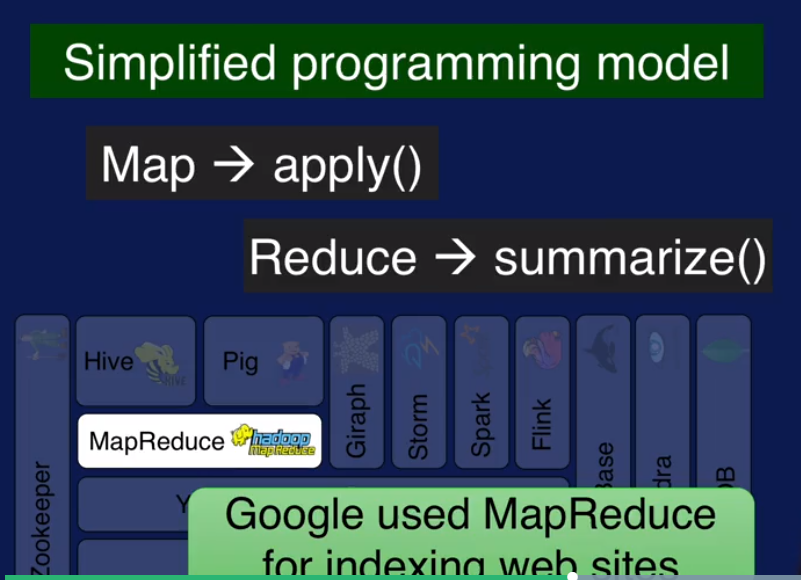
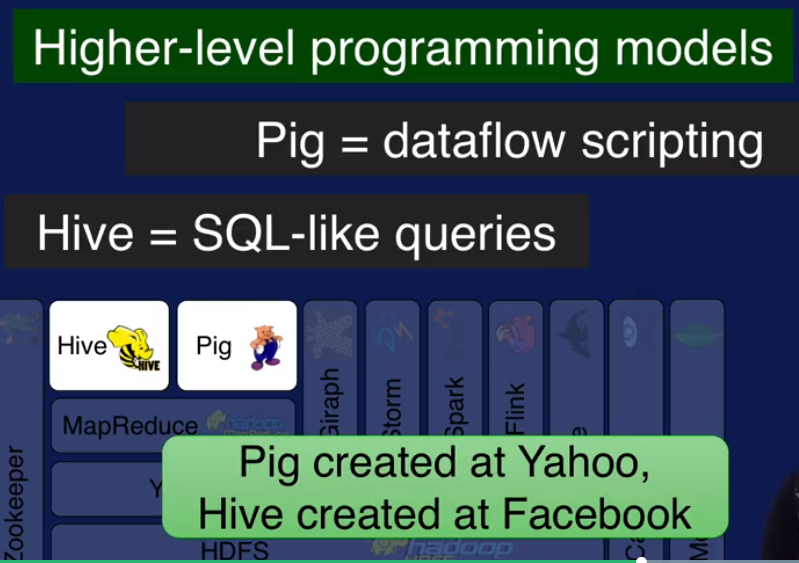
MapReduce 支持的数据model 有限,Hive 和 Pig 是分别针对 SQL-Like query 和 dataflow 类型数据的,可以理解为对MapReduce的扩展.
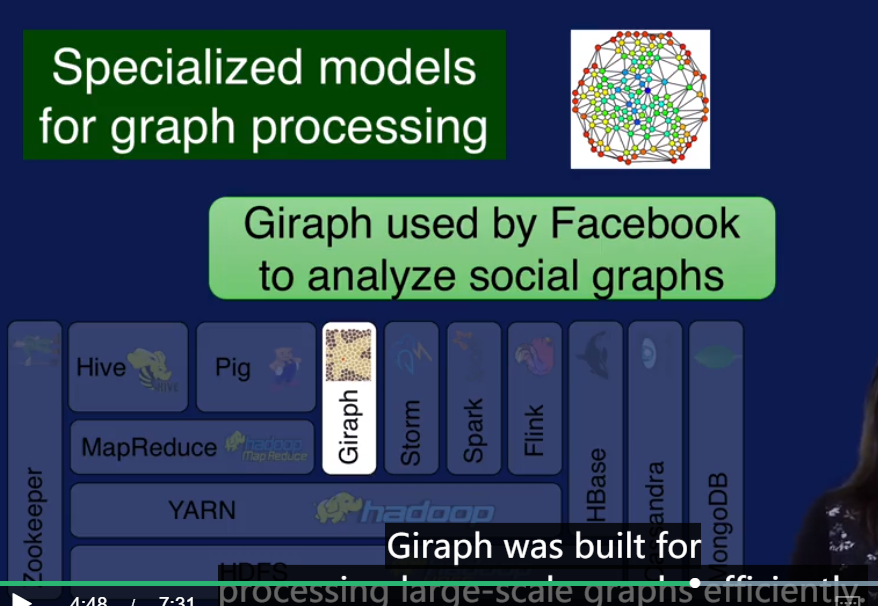
Giraph 用来处理大规模图表.
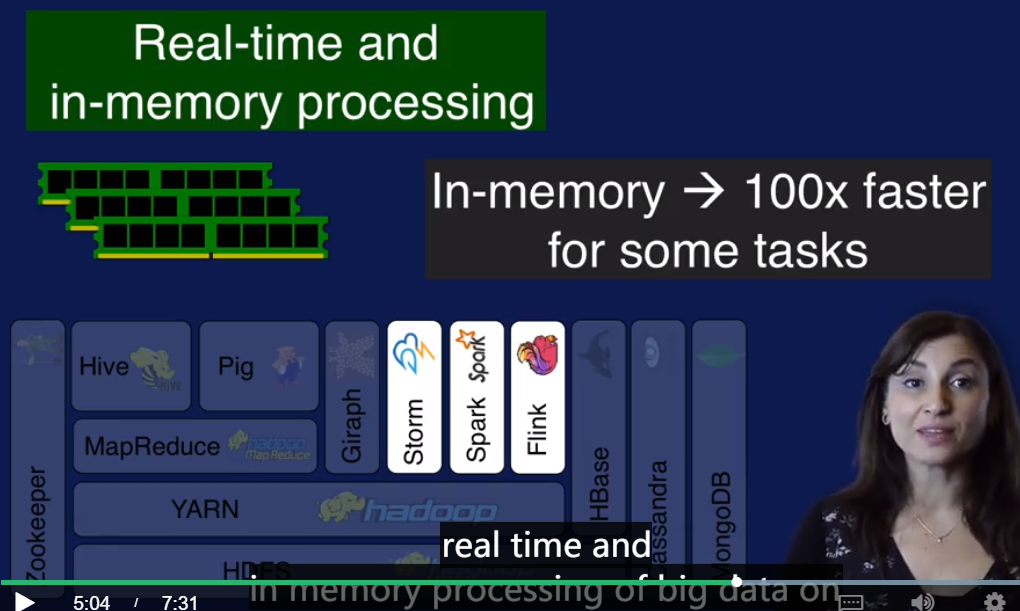
Storm, Spark, Flink 是内存处理大数据的技术.
Strom for streaming data analysis. Spark for in-memory data analysis.
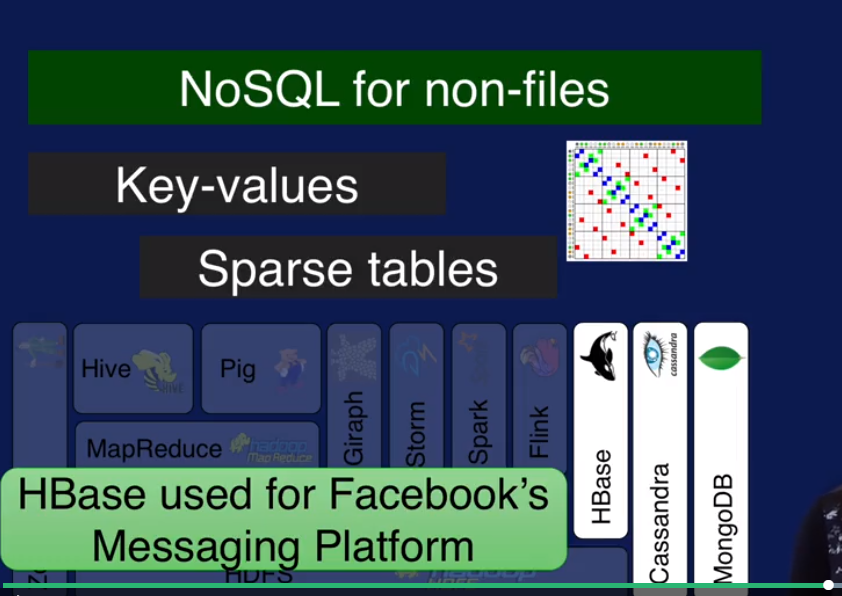
HBase, Cassandra, MongoDB 来处理一些不适合放在关系型数据库的数据,比如 key-value 数据,Sparse tables 数据. 这些都属于 NoSQL 数据库.
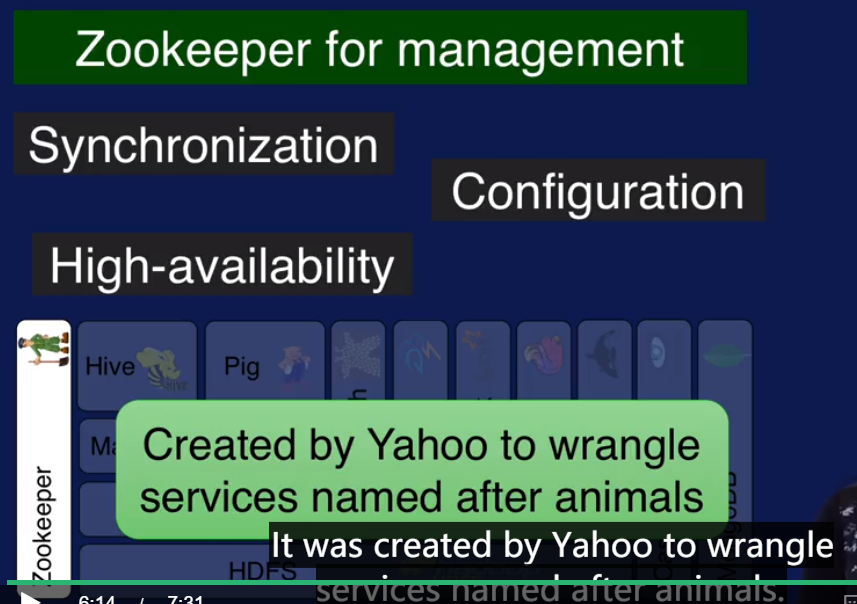
有了上面介绍的这么多模块,需要一个统一的集中管理工具来管理,就是Zookeeper.
这么多工具,如果自己来安排配置其实挺麻烦的,所有就有一些公司提供了集成的预装好的core工具集合,并对production env提供Support. 比如 Cloudera, MAPR, Hortonworks.

讲完了整个生态系统,接下来分别讲模块.
HDFS:
HDFS 怎么提供扩张性和可靠性? 以及它的两个关键模块 NameNode 和 DataNode.

HDFS 默认每一块数据放三份拷贝来提供可靠性. HDFS支持多种数据类型, 读和写时都需要提供数据类型.
HDFS由两种node 组成, Name Node (一般一个cluster就一个)和 Data Node (每个machine都是一个 data node).
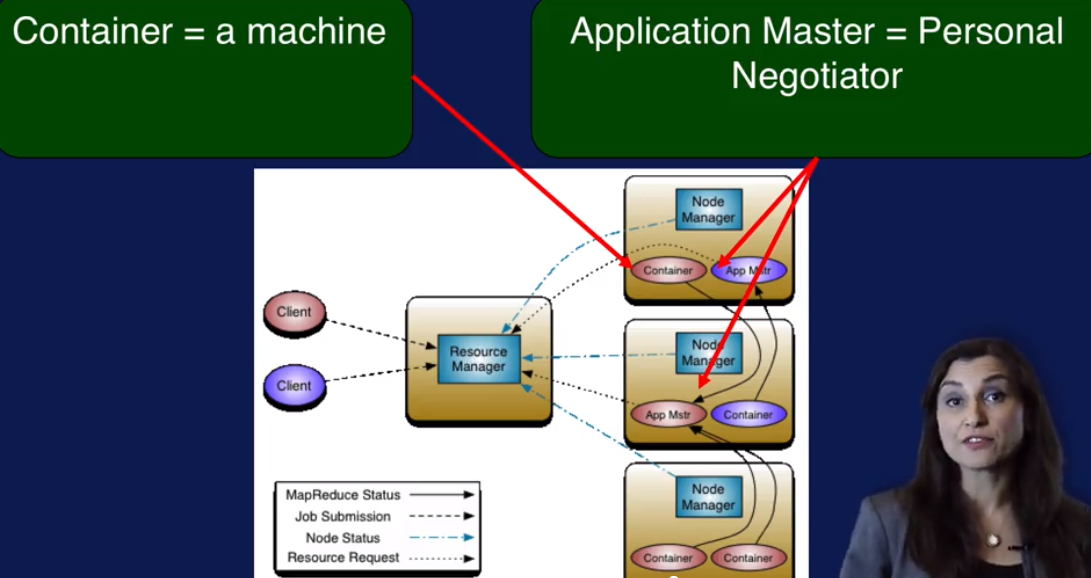
YARN: Resource manager for Hadoop
1. Resource manager and node manager
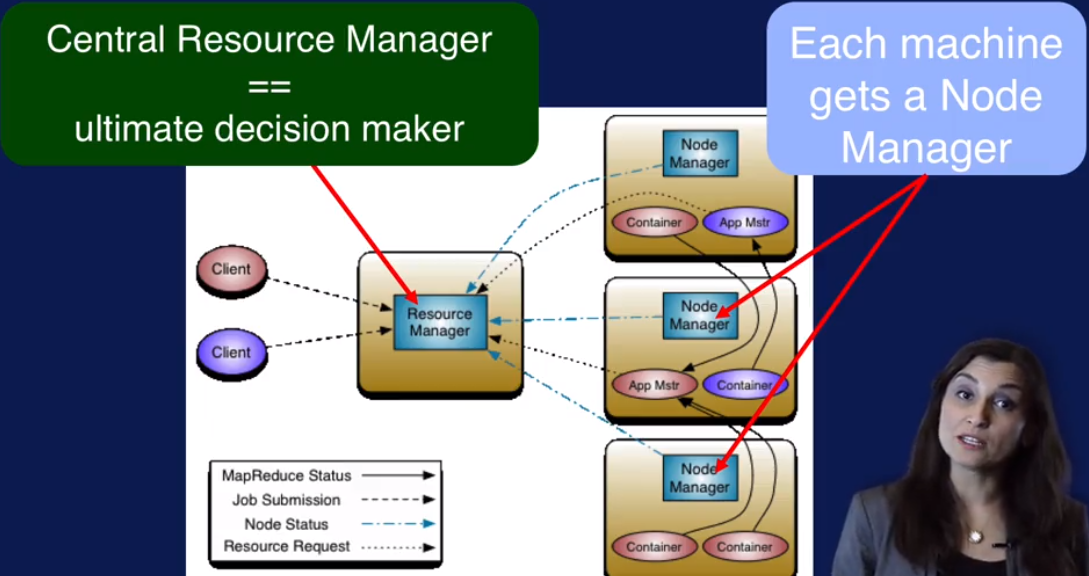
2. Appliacation Master 就像一个谈判人员, 从resource manager 协调资源,让node manager 来负责执行。
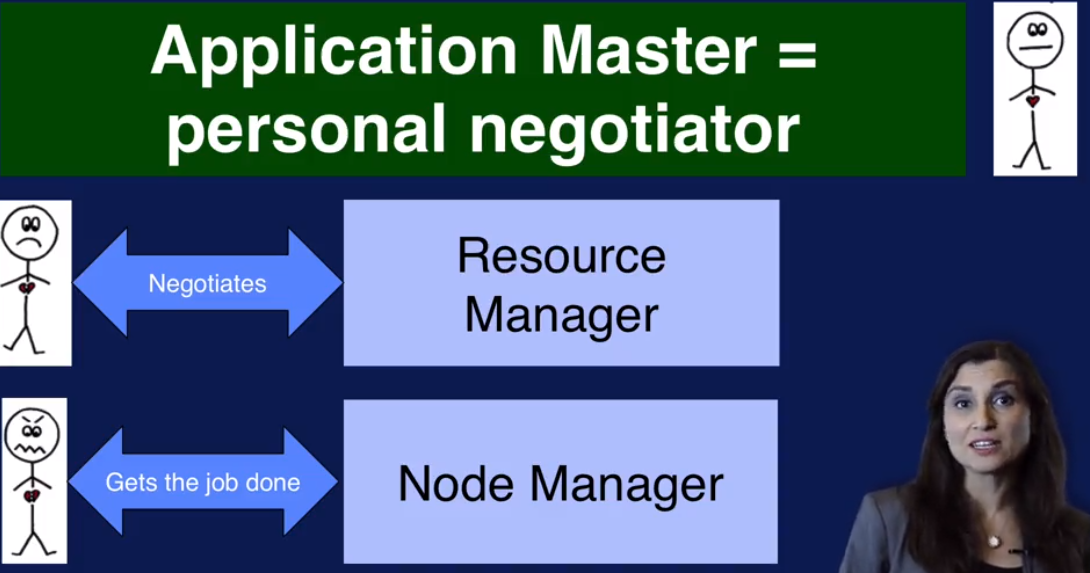
3. Container: 可以把它看做资源的抽象.
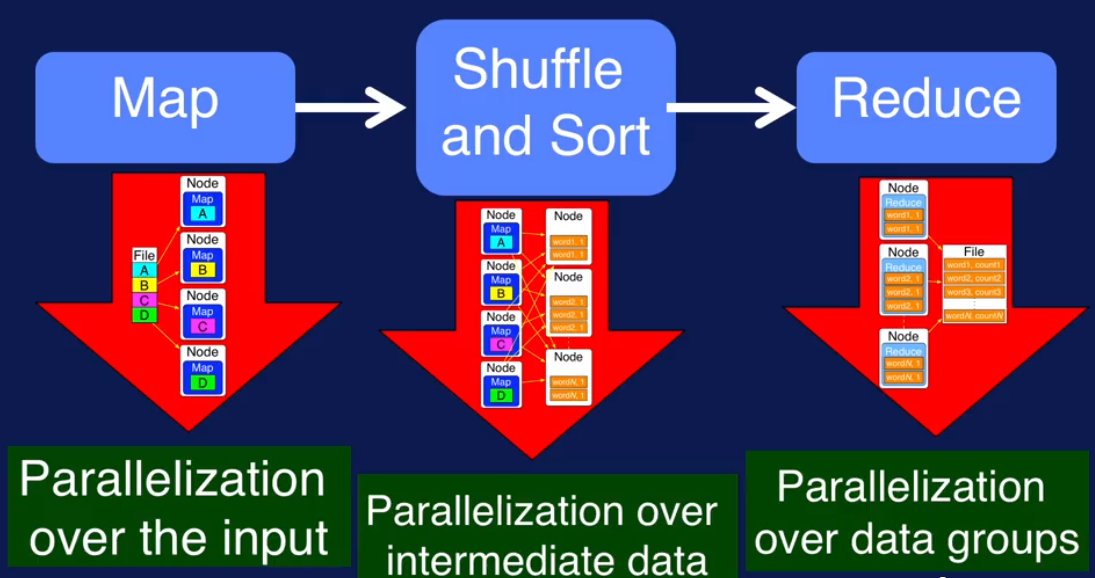
MapReduce:
计算分三步:Map -> Shuffle and Sort -> Reduce
下面图片用了WordCount 例子来显示这三个步骤



全局图
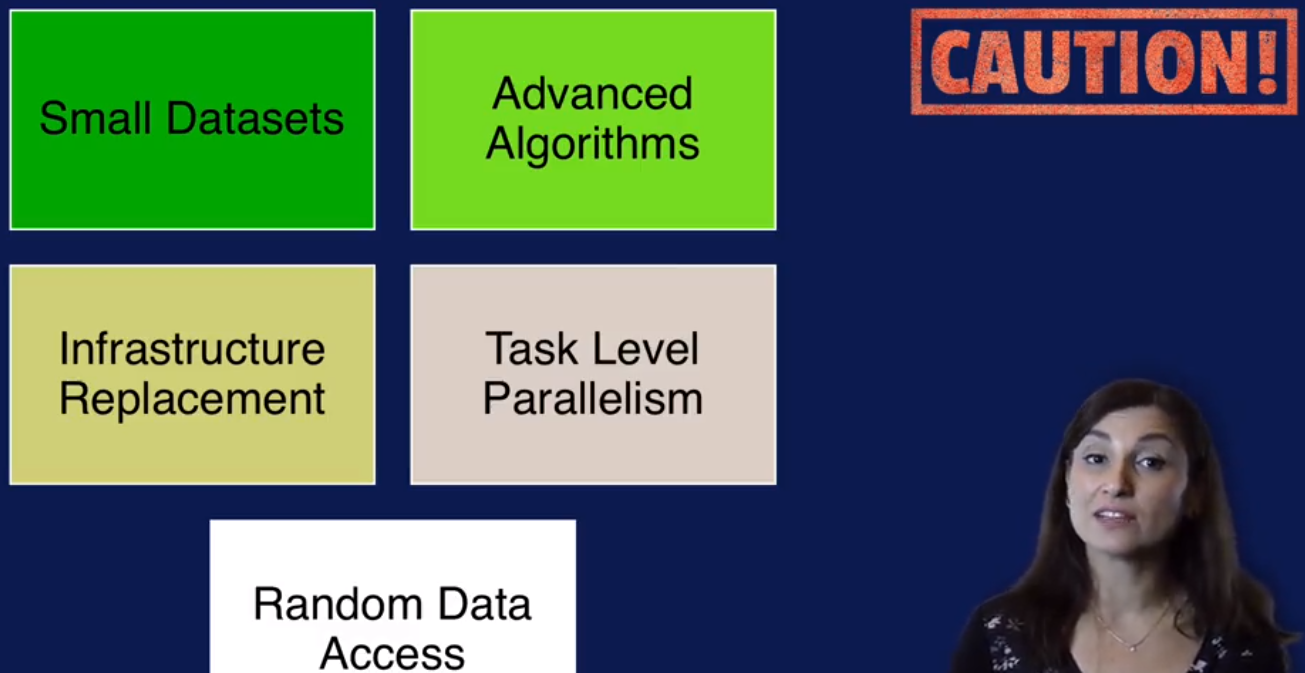
哪些情况不适合使用MapReduce: 因为每次都需要读取Input数据,所有Input数据不能随时变化,还有task 不能有先后依赖,还有MR 算完了才出结果也就不适合交互型的task.

什么情况下Hadoop使用或者不适用?
适用的场景包括了数据量比较大,数据格式多样等
不适用的场景:小数据量;一些数据之间有依赖的高级算法也不适用
云计算:
把基础架构交给云服务商,团队只需要关注应用.
IaaS: 比如 Amazon EC2, 阿里云
PaaS: Microsoft Azure, Google App Engine
SaaS: Dropbox
Value from Hadoop:
Coursera, Big Data 1, Introduction (week 3)的更多相关文章
- Coursera, Big Data 1, Introduction (week 1/2)
Status: week 2 done. Week 1, 主要讲了大数据的的来源 - 机器产生的数据,人产生的数据(比如社交软件上的update, 一般是unstructed data), 组织产生的 ...
- Building Applications with Force.com and VisualForce(Dev401)(十六):Data Management: Introduction to Upsert
Dev401-017:Data Management: Introduction to Upsert Module Objectives1.Define upsert.2.Define externa ...
- Coursera, Big Data 2, Modeling and Management Systems (week 1/2/3)
Introduction to data management 整个coures 2 是讲data management and storage 的,主要内容就是分布式文件系统,HDFS, Redis ...
- Coursera, Big Data 4, Machine Learning With Big Data (week 1/2)
Week 1 Machine Learning with Big Data KNime - GUI based Spark MLlib - inside Spark CRISP-DM Week 2, ...
- Coursera, Big Data 3, Integration and Processing (week 5)
Week 5, Big Data Analytics using Spark Programing in Spark Spark Core: Programming in Spark us ...
- Coursera, Big Data 3, Integration and Processing (week 4)
Week 4 Big Data Precessing Pipeline 上图可以generalize 成下图,也就是Big data pipeline some high level processi ...
- Coursera, Big Data 3, Integration and Processing (week 1/2/3)
This is the 3rd course in big data specification courses. Data model reivew 1, data model 的特点: Struc ...
- Coursera, Big Data 2, Modeling and Management Systems (week 4/5/6)
week4 streaming data format 下面讲 data lakes schema-on-read: 从数据源读取raw data 直接放到 data lake 里,然后再读到mode ...
- Coursera, Big Data 4, Machine Learning With Big Data (week 3/4/5)
week 3 Classification KNN :基本思想是 input value 类似,就可能是同一类的 Decision Tree Naive Bayes Week 4 Evaluating ...
随机推荐
- android开发学习 ------- 关于getSupportFragmentManager()不可用的问题
在Android开发中,少不了Fragment的运用. 目前在实际运用中,有v-4包下支持的Fragment以及app包下的Fragment,这两个包下的FragmentManager获取方式有点区别 ...
- Linux 实例常用内核网络参数介绍与常见问题处理
本文总结了常见的 Linux 内核参数及相关问题.修改内核参数前,您需要: 从实际需要出发,最好有相关数据的支撑,不建议随意调整内核参数. 了解参数的具体作用,且注意同类型或版本环境的内核参数可能有所 ...
- go笔记-值传递、引用传递
eg: func sliceModify(slice []int) { // slice[0] = 88 slice = append(slice, ) } func main() { slice : ...
- left join inner join 区别
left 以左表为准,左表在右表没有对应的记录,也为显示(右表字段填空). inner 需要满足两张表都有记录. 不管哪种join 一对多最终的结局 只会是多条记录
- 关于B树B+树的详细解释——绝对精彩
B树是一种完全平衡树,B+树是B树的升级版,使用更多.B树和B+树存在的目的是如何提高磁盘文件的访问(如数据库)效率. 关于B树和B+树的一篇比较好的文章: https://www.cnblogs.c ...
- Django2.0 models中的on_delete参数
一.外键.OneToOne字段等on_delete为必须参数 如下ForeignKey字段源码,to.on_delete为必须参数 to:关联的表 on_delete:当该表中的某条数据删除后,关 ...
- apply和call与this
函数本身的apply方法,改变this指向哪个对象: function getAge() { var y = new Date().getFullYear(); return y - this.bir ...
- 2 数据分析之Numpy模块(1)
Numpy Numpy(Numerical Python的简称)是高性能科学计算和数据分析的基础包.它是我们课程所介绍的其他高级工具的构建基础. 其部分功能如下: ndarray, 一个具有复杂广播能 ...
- Vue项目搭建与部署
Vue项目搭建与部署 一,介绍与需求 1.1,介绍 Vue 是一套用于构建用户界面的渐进式框架.与其它大型框架不同的是,Vue 被设计为可以自底向上逐层应用.Vue两大核心思想:组件化和数据驱动.组 ...
- Django标签和过滤器
过滤器格式{{ }} 标签格式{% %} 模板中过滤器filter只能使用一个参数,自定义标签中则可以使用多个参数!!! 过滤器能够采用链式的方式使用,例如:{{ text | escape | ...