ES--06
第51.初识搜索引擎_上机动手实战多搜索条件组合查询
课程大纲
GET /website/article/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "elasticsearch"
}
}
],
"should": [
{
"match": {
"content": "elasticsearch"
}
}
],
"must_not": [
{
"match": {
"author_id": 111
}
}
]
}
}
}
{
"bool": {
"must": { "match": { "title": "how to make millions" }},
"must_not": { "match": { "tag": "spam" }},
"should": [
{ "match": { "tag": "starred" }}
],
"filter": {
"range": { "date": { "gte": "2014-01-01" }}
}
}
}
bool
must,must_not,should,filter
每个子查询都会计算一个document针对它的相关度分数,然后bool综合所有分数,合并为一个分数,当然filter是不会计算分数的
{
"bool": {
"must": { "match": { "title": "how to make millions" }},
"must_not": { "match": { "tag": "spam" }},
"should": [
{ "match": { "tag": "starred" }}
],
"filter": {
"bool": {
"must": [
{ "range": { "date": { "gte": "2014-01-01" }}},
{ "range": { "price": { "lte": 29.99 }}}
],
"must_not": [
{ "term": { "category": "ebooks" }}
]
}
}
}
}
GET /company/employee/_search
{
"query": {
"constant_score": { 使用constant_score单纯的过滤也可以
"filter": {
"range": {
"age": {
"gte": 30
}
}
}
}
}
}
第52.初识搜索引擎_上机动手实战如何定位不合法的搜索以及其原因
课程大纲
GET /test_index/test_type/_validate/query?explain
{
"query": {
"math": {
"test_field": "test"
}
}
}
{
"valid": false,
"error": "org.elasticsearch.common.ParsingException: no [query] registered for [math]"
}
GET /test_index/test_type/_validate/query?explain
{
"query": {
"match": {
"test_field": "test"
}
}
}
{
"valid": true,
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"explanations": [
{
"index": "test_index",
"valid": true,
"explanation": "+test_field:test #(#_type:test_type)"
}
]
}
一般用在那种特别复杂庞大的搜索下,比如你一下子写了上百行的搜索,这个时候可以先用validate api去验证一下,搜索是否合法
第53.初识搜素引擎_上机动手实战如何定制搜索结果的排序规则
课程大纲
1、默认排序规则
默认情况下,是按照_score降序排序的
然而,某些情况下,可能没有有用的_score,比如说filter
GET /_search
{
"query" : {
"bool" : {
"filter" : {
"term" : {
"author_id" : 1
}
}
}
}
}
当然,也可以是constant_score
GET /_search
{
"query" : {
"constant_score" : {
"filter" : {
"term" : {
"author_id" : 1
}
}
}
}
}
2、定制排序规则
GET /company/employee/_search
{
"query": {
"constant_score": {
"filter": {
"range": {
"age": {
"gte": 30
}
}
}
}
},
"sort": [
{
"join_date": {
"order": "asc"
}
}
]
}
第54.初识搜索引擎_解密如何将一个field索引两次来解决字符串排序问题.avi
课程大纲
如果对一个string field进行排序,结果往往不准确,因为分词后是多个单词,再排序就不是我们想要的结果了
通常解决方案是,将一个string field建立两次索引,一个分词,用来进行搜索;一个不分词,用来进行排序
PUT /website
{
"mappings": {
"article": {
"properties": {
"title": {
"type": "text",
"fields": {
"raw": {
"type": "string",
"index": "not_analyzed"
}
},
"fielddata": true 正排索引??
},
"content": {
"type": "text"
},
"post_date": {
"type": "date"
},
"author_id": {
"type": "long"
}
}
}
}
}

PUT /website/article/1
{
"title": "first article",
"content": "this is my second article",
"post_date": "2017-01-01",
"author_id": 110
}
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 3,
"max_score": 1,
"hits": [
{
"_index": "website",
"_type": "article",
"_id": "2",
"_score": 1,
"_source": {
"title": "first article",
"content": "this is my first article",
"post_date": "2017-02-01",
"author_id": 110
}
},
{
"_index": "website",
"_type": "article",
"_id": "1",
"_score": 1,
"_source": {
"title": "second article",
"content": "this is my second article",
"post_date": "2017-01-01",
"author_id": 110
}
},
{
"_index": "website",
"_type": "article",
"_id": "3",
"_score": 1,
"_source": {
"title": "third article",
"content": "this is my third article",
"post_date": "2017-03-01",
"author_id": 110
}
}
]
}
}
GET /website/article/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"title.raw": {
"order": "desc"
}
}
]
}
55.初识搜索引擎_相关度评分TF&IDF算法独家解密
课程大纲
1、算法介绍
relevance score算法,简单来说,就是计算出,一个索引中的文本,与搜索文本,他们之间的关联匹配程度
Elasticsearch使用的是 term frequency/inverse document frequency算法,简称为TF/IDF算法
Term frequency:搜索文本中的各个词条在field文本中出现了多少次,出现次数越多,就越相关
搜索请求:hello world
doc1:hello you, and world is very good
doc2:hello, how are you
Inverse document frequency:搜索文本中的各个词条在整个索引的所有文档中出现了多少次,出现的次数越多,就越不相关
搜索请求:hello world
doc1:hello, today is very good
doc2:hi world, how are you
比如说,在index中有1万条document,hello这个单词在所有的document中,一共出现了1000次;world这个单词在所有的document中,一共出现了100次
doc2更相关(物以稀为贵)
Field-length norm:field长度,field越长,相关度越弱
搜索请求:hello world
doc1:{ "title": "hello article", "content": "babaaba 1万个单词" }
doc2:{ "title": "my article", "content": "blablabala 1万个单词,hi world" }
hello world在整个index中出现的次数是一样多的
doc1更相关,title field更短
doc1中hello出现的字段中长度更短
doc2中world出现的field更长
2、_score是如何被计算出来的
GET /test_index/test_type/_search?explain
{
"query": {
"match": {
"test_field": "test hello"
}
}
}
{
"took": 6,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 4,
"max_score": 1.595089,
"hits": [
{
"_shard": "[test_index][2]",
"_node": "4onsTYVZTjGvIj9_spWz2w",
"_index": "test_index",
"_type": "test_type",
"_id": "20",
"_score": 1.595089,
"_source": {
"test_field": "test hello"
},
"_explanation": {
"value": 1.595089,
"description": "sum of:",
"details": [
{
"value": 1.595089,
"description": "sum of:",
"details": [
{
"value": 0.58279467,
"description": "weight(test_field:test in 0) [PerFieldSimilarity], result of:",
"details": [
{
"value": 0.58279467,
"description": "score(doc=0,freq=1.0 = termFreq=1.0\n), product of:",
"details": [
{
"value": 0.6931472,
"description": "idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5)) from:",
"details": [
{
"value": 2,
"description": "docFreq",
"details": []
},
{
"value": 4,
"description": "docCount",
"details": []
}
]
},
{
"value": 0.840795,
"description": "tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength)) from:",
"details": [
{
"value": 1,
"description": "termFreq=1.0",
"details": []
},
{
"value": 1.2,
"description": "parameter k1",
"details": []
},
{
"value": 0.75,
"description": "parameter b",
"details": []
},
{
"value": 1.75,
"description": "avgFieldLength",
"details": []
},
{
"value": 2.56,
"description": "fieldLength",
"details": []
}
]
}
]
}
]
},
{
"value": 1.0122943,
"description": "weight(test_field:hello in 0) [PerFieldSimilarity], result of:",
"details": [
{
"value": 1.0122943,
"description": "score(doc=0,freq=1.0 = termFreq=1.0\n), product of:",
"details": [
{
"value": 1.2039728,
"description": "idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5)) from:",
"details": [
{
"value": 1,
"description": "docFreq",
"details": []
},
{
"value": 4,
"description": "docCount",
"details": []
}
]
},
{
"value": 0.840795,
"description": "tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength)) from:",
"details": [
{
"value": 1,
"description": "termFreq=1.0",
"details": []
},
{
"value": 1.2,
"description": "parameter k1",
"details": []
},
{
"value": 0.75,
"description": "parameter b",
"details": []
},
{
"value": 1.75,
"description": "avgFieldLength",
"details": []
},
{
"value": 2.56,
"description": "fieldLength",
"details": []
}
]
}
]
}
]
}
]
},
{
"value": 0,
"description": "match on required clause, product of:",
"details": [
{
"value": 0,
"description": "# clause",
"details": []
},
{
"value": 1,
"description": "*:*, product of:",
"details": [
{
"value": 1,
"description": "boost",
"details": []
},
{
"value": 1,
"description": "queryNorm",
"details": []
}
]
}
]
}
]
}
},
{
"_shard": "[test_index][2]",
"_node": "4onsTYVZTjGvIj9_spWz2w",
"_index": "test_index",
"_type": "test_type",
"_id": "6",
"_score": 0.58279467,
"_source": {
"test_field": "tes test"
},
"_explanation": {
"value": 0.58279467,
"description": "sum of:",
"details": [
{
"value": 0.58279467,
"description": "sum of:",
"details": [
{
"value": 0.58279467,
"description": "weight(test_field:test in 0) [PerFieldSimilarity], result of:",
"details": [
{
"value": 0.58279467,
"description": "score(doc=0,freq=1.0 = termFreq=1.0\n), product of:",
"details": [
{
"value": 0.6931472,
"description": "idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5)) from:",
"details": [
{
"value": 2,
"description": "docFreq",
"details": []
},
{
"value": 4,
"description": "docCount",
"details": []
}
]
},
{
"value": 0.840795,
"description": "tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength)) from:",
"details": [
{
"value": 1,
"description": "termFreq=1.0",
"details": []
},
{
"value": 1.2,
"description": "parameter k1",
"details": []
},
{
"value": 0.75,
"description": "parameter b",
"details": []
},
{
"value": 1.75,
"description": "avgFieldLength",
"details": []
},
{
"value": 2.56,
"description": "fieldLength",
"details": []
}
]
}
]
}
]
}
]
},
{
"value": 0,
"description": "match on required clause, product of:",
"details": [
{
"value": 0,
"description": "# clause",
"details": []
},
{
"value": 1,
"description": "*:*, product of:",
"details": [
{
"value": 1,
"description": "boost",
"details": []
},
{
"value": 1,
"description": "queryNorm",
"details": []
}
]
}
]
}
]
}
},
{
"_shard": "[test_index][3]",
"_node": "4onsTYVZTjGvIj9_spWz2w",
"_index": "test_index",
"_type": "test_type",
"_id": "7",
"_score": 0.5565415,
"_source": {
"test_field": "test client 2"
},
"_explanation": {
"value": 0.5565415,
"description": "sum of:",
"details": [
{
"value": 0.5565415,
"description": "sum of:",
"details": [
{
"value": 0.5565415,
"description": "weight(test_field:test in 0) [PerFieldSimilarity], result of:",
"details": [
{
"value": 0.5565415,
"description": "score(doc=0,freq=1.0 = termFreq=1.0\n), product of:",
"details": [
{
"value": 0.6931472,
"description": "idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5)) from:",
"details": [
{
"value": 1,
"description": "docFreq",
"details": []
},
{
"value": 2,
"description": "docCount",
"details": []
}
]
},
{
"value": 0.8029196,
"description": "tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength)) from:",
"details": [
{
"value": 1,
"description": "termFreq=1.0",
"details": []
},
{
"value": 1.2,
"description": "parameter k1",
"details": []
},
{
"value": 0.75,
"description": "parameter b",
"details": []
},
{
"value": 2.5,
"description": "avgFieldLength",
"details": []
},
{
"value": 4,
"description": "fieldLength",
"details": []
}
]
}
]
}
]
}
]
},
{
"value": 0,
"description": "match on required clause, product of:",
"details": [
{
"value": 0,
"description": "# clause",
"details": []
},
{
"value": 1,
"description": "_type:test_type, product of:",
"details": [
{
"value": 1,
"description": "boost",
"details": []
},
{
"value": 1,
"description": "queryNorm",
"details": []
}
]
}
]
}
]
}
},
{
"_shard": "[test_index][1]",
"_node": "4onsTYVZTjGvIj9_spWz2w",
"_index": "test_index",
"_type": "test_type",
"_id": "8",
"_score": 0.25316024,
"_source": {
"test_field": "test client 2"
},
"_explanation": {
"value": 0.25316024,
"description": "sum of:",
"details": [
{
"value": 0.25316024,
"description": "sum of:",
"details": [
{
"value": 0.25316024,
"description": "weight(test_field:test in 0) [PerFieldSimilarity], result of:",
"details": [
{
"value": 0.25316024,
"description": "score(doc=0,freq=1.0 = termFreq=1.0\n), product of:",
"details": [
{
"value": 0.2876821,
"description": "idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5)) from:",
"details": [
{
"value": 1,
"description": "docFreq",
"details": []
},
{
"value": 1,
"description": "docCount",
"details": []
}
]
},
{
"value": 0.88,
"description": "tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength)) from:",
"details": [
{
"value": 1,
"description": "termFreq=1.0",
"details": []
},
{
"value": 1.2,
"description": "parameter k1",
"details": []
},
{
"value": 0.75,
"description": "parameter b",
"details": []
},
{
"value": 3,
"description": "avgFieldLength",
"details": []
},
{
"value": 4,
"description": "fieldLength",
"details": []
}
]
}
]
}
]
}
]
},
{
"value": 0,
"description": "match on required clause, product of:",
"details": [
{
"value": 0,
"description": "# clause",
"details": []
},
{
"value": 1,
"description": "*:*, product of:",
"details": [
{
"value": 1,
"description": "boost",
"details": []
},
{
"value": 1,
"description": "queryNorm",
"details": []
}
]
}
]
}
]
}
}
]
}
}
3、分析一个document是如何被匹配上的
GET /test_index/test_type/6/_explain
{
"query": {
"match": {
"test_field": "test hello"
}
}
}
56.初识搜索引擎_内核级知识点之doc value初步探秘
课程大纲
搜索的时候,要依靠倒排索引;排序的时候,需要依靠正排索引,看到每个document的每个field,然后进行排序,所谓的正排索引,其实就是doc values
在建立索引的时候,一方面会建立倒排索引,以供搜索用;一方面会建立正排索引,也就是doc values,以供排序,聚合,过滤等操作使用
doc values是被保存在磁盘上的,此时如果内存足够,os会自动将其缓存在内存中,性能还是会很高;如果内存不足够,os会将其写入磁盘上
doc1: hello world you and me
doc2: hi, world, how are you

hello you --> hello, you
hello --> doc1
you --> doc1,doc2
doc1: hello world you and me
doc2: hi, world, how are you
sort by age
doc1: { "name": "jack", "age": 27 }
doc2: { "name": "tom", "age": 30 }

57.初识搜索引擎_分布式搜索引擎内核解密之query phase
课程大纲
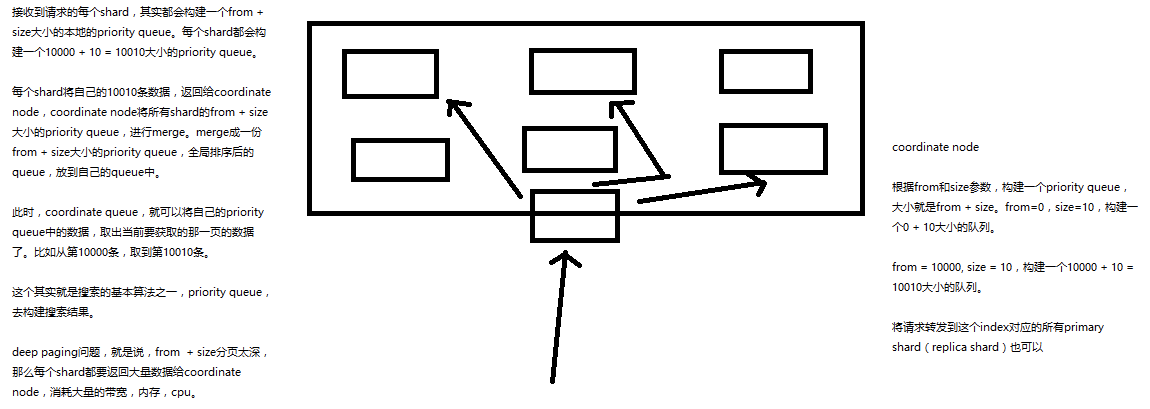
1、query phase
(1)搜索请求发送到某一个coordinate node,构构建一个priority queue,长度以paging操作from和size为准,默认为10
(2)coordinate node将请求转发到所有shard,每个shard本地搜索,并构建一个本地的priority queue
(3)各个shard将自己的priority queue返回给coordinate node,并构建一个全局的priority queue
2、replica shard如何提升搜索吞吐量
一次请求要打到所有shard的一个replica/primary上去,如果每个shard都有多个replica,那么同时并发过来的搜索请求可以同时打到其他的replica上去
58.初识搜索引擎_分布式搜索引擎内核解密之fetch phase.avi
课程大纲
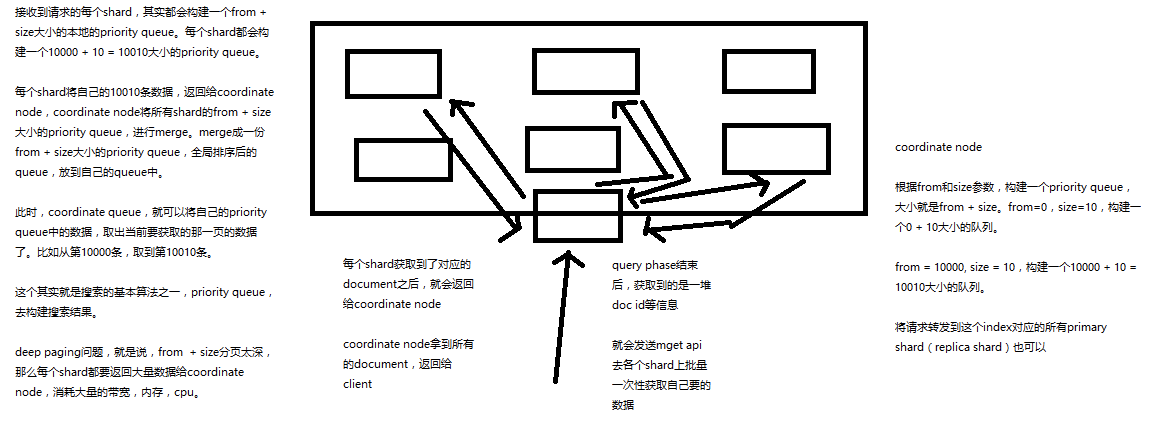
1、fetch phbase工作流程
(1)coordinate node构建完priority queue之后,就发送mget请求去所有shard上获取对应的document
(2)各个shard将document返回给coordinate node
(3)coordinate node将合并后的document结果返回给client客户端
2、一般搜索,如果不加from和size,就默认搜索前10条,按照_score排序
59.初识搜索引擎_搜索相关参数梳理以及bouncing results问题解决方案
课程大纲
1、preference
决定了哪些shard会被用来执行搜索操作
_primary, _primary_first, _local, _only_node:xyz, _prefer_node:xyz, _shards:2,3
bouncing results问题,两个document排序,field值相同;不同的shard上,可能排序不同;每次请求轮询打到不同的replica shard上;每次页面上看到的搜索结果的排序都不一样。这就是bouncing result,也就是跳跃的结果。
搜索的时候,是轮询将搜索请求发送到每一个replica shard(primary shard),但是在不同的shard上,可能document的排序不同
解决方案就是将preference设置为一个字符串,比如说user_id,让每个user每次搜索的时候,都使用同一个replica shard去执行,就不会看到bouncing results了
2、timeout,已经讲解过原理了,主要就是限定在一定时间内,将部分获取到的数据直接返回,避免查询耗时过长
3、routing,document文档路由,_id路由,routing=user_id,这样的话可以让同一个user对应的数据到一个shard上去
4、search_type
default:query_then_fetch
dfs_query_then_fetch,可以提升revelance sort精准度
60.初识搜索引擎_上机动手实战基于scoll技术滚动搜索大量数据
课程大纲
如果一次性要查出来比如10万条数据,那么性能会很差,此时一般会采取用scoll滚动查询,一批一批的查,直到所有数据都查询完处理完
使用scoll滚动搜索,可以先搜索一批数据,然后下次再搜索一批数据,以此类推,直到搜索出全部的数据来
scoll搜索会在第一次搜索的时候,保存一个当时的视图快照,之后只会基于该旧的视图快照提供数据搜索,如果这个期间数据变更,是不会让用户看到的
采用基于_doc进行排序的方式,性能较高
每次发送scroll请求,我们还需要指定一个scoll参数,指定一个时间窗口,每次搜索请求只要在这个时间窗口内能完成就可以了
GET /test_index/test_type/_search?scroll=1m
{
"query": {
"match_all": {}
},
"sort": [ "_doc" ],
"size": 3
}
{
"_scroll_id": "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAACxeFjRvbnNUWVZaVGpHdklqOV9zcFd6MncAAAAAAAAsYBY0b25zVFlWWlRqR3ZJajlfc3BXejJ3AAAAAAAALF8WNG9uc1RZVlpUakd2SWo5X3NwV3oydwAAAAAAACxhFjRvbnNUWVZaVGpHdklqOV9zcFd6MncAAAAAAAAsYhY0b25zVFlWWlRqR3ZJajlfc3BXejJ3",
"took": 5,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 10,
"max_score": null,
"hits": [
{
"_index": "test_index",
"_type": "test_type",
"_id": "8",
"_score": null,
"_source": {
"test_field": "test client 2"
},
"sort": [
0
]
},
{
"_index": "test_index",
"_type": "test_type",
"_id": "6",
"_score": null,
"_source": {
"test_field": "tes test"
},
"sort": [
0
]
},
{
"_index": "test_index",
"_type": "test_type",
"_id": "AVp4RN0bhjxldOOnBxaE",
"_score": null,
"_source": {
"test_content": "my test"
},
"sort": [
0
]
}
]
}
}
获得的结果会有一个scoll_id,下一次再发送scoll请求的时候,必须带上这个scoll_id
GET /_search/scroll
{
"scroll": "1m",
"scroll_id" : "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAACxeFjRvbnNUWVZaVGpHdklqOV9zcFd6MncAAAAAAAAsYBY0b25zVFlWWlRqR3ZJajlfc3BXejJ3AAAAAAAALF8WNG9uc1RZVlpUakd2SWo5X3NwV3oydwAAAAAAACxhFjRvbnNUWVZaVGpHdklqOV9zcFd6MncAAAAAAAAsYhY0b25zVFlWWlRqR3ZJajlfc3BXejJ3"
}
11,4,7
3,2,1
20
scoll,看起来挺像分页的,但是其实使用场景不一样。分页主要是用来一页一页搜索,给用户看的;scoll主要是用来一批一批检索数据,让系统进行处理的
ES--06的更多相关文章
- ES 06 - 通过Kibana插件增删改查ES中的索引文档
目录 1 document的结构 2 document的常见CRUD操作 2.1 添加商品: 添加文档并建立索引 2.2 查询商品: 检索文档 2.3 修改商品: 替换文档 2.4 修改商品: 更新文 ...
- ES 04 - 安装Kibana插件(6.6.0版本)
目录 1 Kibana是什么 2 安装并启动Kibana 2.1 准备安装包 2.2 修改配置文件 2.3 启动Kibana并验证 2.4 关闭Kibana服务 3 Kibana功能测试 3.1 关于 ...
- OpenGL ES教程系列(经典合集)
为了搞透播放器的开发,花了些时间收集这些资料,虽然我已经搞定opengles渲染视频的内容,但是想玩玩opengles,往深里玩,图像处理这块是个好的方向,所以opengles是值得好好学的. O ...
- webpack-工程化工具
一.简介 1.webpack 是 facebook 公司发布的一款工程化工具,早期有 react 使用. 2.核心理念: 一切都是资源,是资源我们就能模块化打包加载. 3.webpack 默认支持 c ...
- ES性能测试
测试背景 因为ES(ElasticSearch)前段时间查询效率有点慢,技术小组对索引做了一些改动,因此需要测试一下修改后的查询效率,跟之前的结果做一下对比,所以有了这次测试. 需求简述 ...
- 使用 ES.later 的装饰器作为 mixin
原文链接:http://raganwald.com/2015/06/26/decorators-in-es7.html 在函数式 mixin 中,我们讨论了将功能糅合进 JavaScript 类中 ...
- ES 02 - 部署Elasticsearch单机服务 + 部署中的常见问题
目录 1 准备工作 1.1 安装JDK 1.2 下载安装包 1.3 创建elastic用户 2 启动ES服务 2.1 修改配置文件 2.2 启动服务 3 验证ES服务是否可用 4 关闭与重启服务 4. ...
- Lucene、ES好文章
1.lucene4.5源码分析系列:lucene概述 http://blog.csdn.net/liweisnake/article/details/10348969 http://www.cnblo ...
- ES 31 - 从0开始搭建Elasticsearch生产集群
目录 1 配置环境 1.1 服务器IP映射 1.2 配置各节点的ssh免密通信 1.3 安装JDK并配置环境变量 2 部署单节点服务 3 部署集群服务 4 启动集群中的所有节点 4.2 启动各个节点中 ...
- ES索引瘦身 压缩——_source _all 均disable filed store为no,引入第三方DB存储原始数据,去掉pos倒排和doc_values,强制定期merge segments,将所有fileds合并为一个field big string
原始数据:835MB ES 设置了_source _all disabled 且设置了仅仅存docs倒排Wed Feb 22 11:58:27 CST 2017Before size:1 /home/ ...
随机推荐
- 爬虫基础(四)-----MongoDB的使用
------------------------------------------------------------------------摆脱穷人思维 <四> :减少无意义的频繁决策 ...
- python之configparser模块详解--小白博客
configparse模块 一.ConfigParser简介 ConfigParser 是用来读取配置文件的包.配置文件的格式如下:中括号“[ ]”内包含的为section.section 下面为类似 ...
- vue入门之编译项目
好记性不如烂笔头,最近又开始学习vue了,编译的过程中遇到几个小坑,特此一记. 首先说一下vue项目如何编译,其实很简单,cd到项目文件夹,然后执行命令: npm run bulid 不过np ...
- nginx代理部署Vue与React项目
nginx代理部署Vue与React项目 一,介绍与需求 1.1,介绍 Nginx (engine x) 是一个高性能的HTTP和反向代理服务,也是一个IMAP/POP3/SMTP服务.Nginx是由 ...
- Flask 构建微电影视频网站(四)
后台管理 实现后台管理系统使用flask sqlalchemy结合mysql数据库进行增删改查操作.分页的使用.路由装饰器定义.模板中变量调用.登录会话机制.上传文件.flask wtforms表单使 ...
- Codeforces #381(div2)
A.题目:http://codeforces.com/contest/740/problem/A 题意:现有n本书,买一本书需要花a元,两本书b元,三本书c元,问买够书是4的倍数所需要的最小花费 思路 ...
- 51nod 1318 最大公约数与最小公倍数方程组(2-SAT)
题意 给你 \(n\) 个元素,\(m\) 个方程. 每个方程形如 \[ \begin{align} \gcd(x_i, y_i)=c_i\\ \mathrm{lcm}(x_i,y_i) = d_i ...
- 整体二分(SP3946 K-th Number ZOJ 2112 Dynamic Rankings)
SP3946 K-th Number (/2和>>1不一样!!) #include <algorithm> #include <bitset> #include & ...
- GWAS群体分层 (Population stratification):利用plink对基因型进行PCA
一.为什么要做祖先成分的PCA? GWAS研究时经常碰到群体分层的现象,即该群体的祖先来源多样性,我们知道的,不同群体SNP频率不一样,导致后面做关联分析的时候可能出现假阳性位点(不一定是显著信号位点 ...
- EM算法(Expectation Maximization Algorithm)初探
1. 通过一个简单的例子直观上理解EM的核心思想 0x1: 问题背景 假设现在有两枚硬币Coin_a和Coin_b,随机抛掷后正面朝上/反面朝上的概率分别是 Coin_a:P1:-P1 Coin_b: ...