redis缓存雪崩、缓存穿透、数据库和redis数据一致性
一、缓存雪崩
回顾一下我们为什么要用缓存(Redis):减轻数据库压力或尽可能少的访问数据库。
在前面学习我们都知道Redis不可能把所有的数据都缓存起来(内存昂贵且有限),所以Redis需要对数据设置过期时间,并采用的是惰性删除+定期删除两种策略对过期键删除。Redis对过期键的策略+持久化
如果缓存数据设置的过期时间是相同的,并且Redis恰好将这部分数据全部删光了。这就会导致在这段时间内,这些缓存同时失效,全部请求到数据库中。
1.1、什么是缓存雪崩
Redis挂掉了,请求全部走数据库。
对缓存数据设置相同的过期时间,导致某段时间内缓存失效,请求全部走数据库。
缓存雪崩如果发生了,很可能就把我们的数据库搞垮,导致整个服务瘫痪!
1.2、如何解决缓存雪崩
对于“对缓存数据设置相同的过期时间,导致某段时间内缓存失效,请求全部走数据库。”这种情况,非常好解决:
解决方法:在缓存的时候给过期时间加上一个随机值,这样就会大幅度的减少缓存在同一时间过期。
对于“Redis挂掉了,请求全部走数据库”这种情况,我们可以有以下的思路:
事发前:实现Redis的高可用(主从架构+Sentinel 或者Redis Cluster),尽量避免Redis挂掉这种情况发生。
事发中:万一Redis真的挂了,我们可以设置本地缓存(ehcache)+限流(hystrix),尽量避免我们的数据库被干掉(起码能保证我们的服务还是能正常工作的)
事发后:redis持久化,重启后自动从磁盘上加载数据,快速恢复缓存数据。
二、缓存穿透
2.1、什么是缓存穿透
比如,我们有一张数据库表,ID都是从1开始的(正数):
但是可能有黑客想把我的数据库搞垮,每次请求的ID都是负数。这会导致我的缓存就没用了,请求全部都找数据库去了,但数据库也没有这个值啊,所以每次都返回空出去。
缓存穿透是指查询一个一定不存在的数据。由于缓存不命中,并且出于容错考虑,如果从数据库查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,失去了缓存的意义。
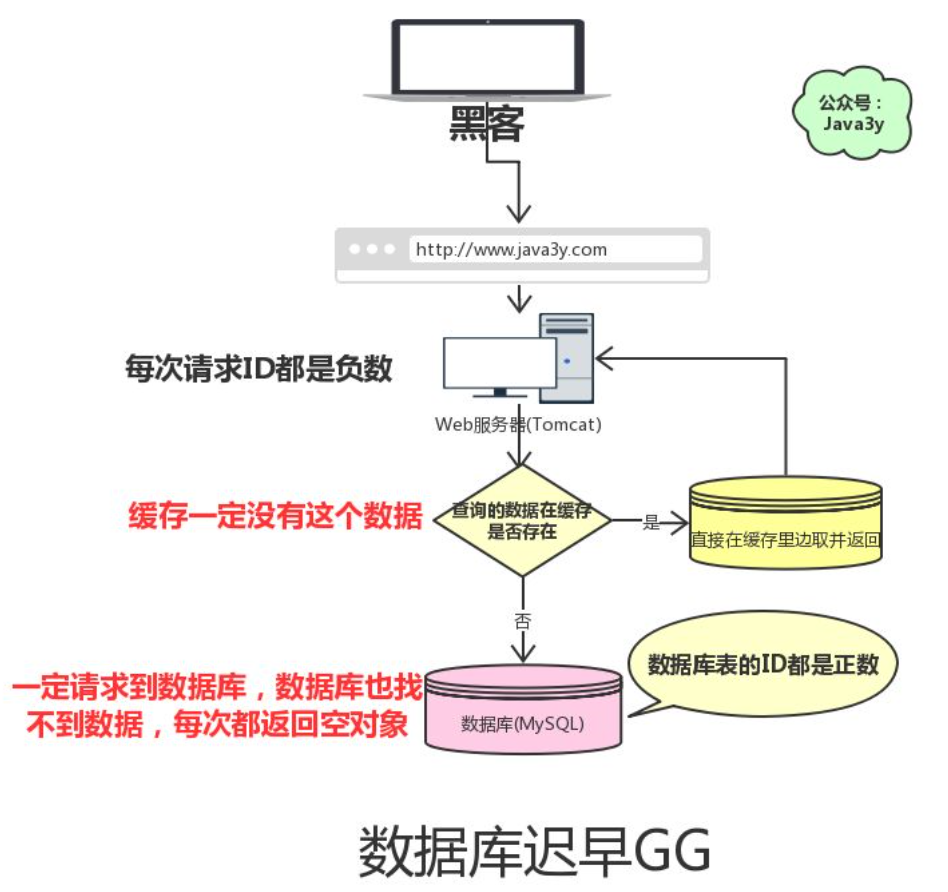
这就是缓存穿透:
请求的数据在缓存大量不命中,导致请求走数据库。
缓存穿透如果发生了,也可能把我们的数据库搞垮,导致整个服务瘫痪!
2.1、如何解决缓存穿透
解决缓存穿透也有两种方案:
由于请求的参数是不合法的(每次都请求不存在的参数),于是我们可以使用布隆过滤器(BloomFilter)或者压缩filter提前拦截,不合法就不让这个请求到数据库层!
当我们从数据库找不到的时候,我们也将这个空对象设置到缓存里边去。下次再请求的时候,就可以从缓存里边获取了。
这种情况我们一般会将空对象设置一个较短的过期时间。
参考资料:
缓存系列文章--5.缓存穿透问题
https://carlosfu.iteye.com/blog/2248185
三、缓存与数据库双写一致
3.1、对于读操作,流程是这样的
上面讲缓存穿透的时候也提到了:如果从数据库查不到数据则不写入缓存。
一般我们对读操作的时候有这么一个固定的套路:
如果我们的数据在缓存里边有,那么就直接取缓存的。
如果缓存里没有我们想要的数据,我们会先去查询数据库,然后将数据库查出来的数据写到缓存中。
最后将数据返回给请求
3.2、什么是缓存与数据库双写一致问题
如果仅仅查询的话,缓存的数据和数据库的数据是没问题的。但是,当我们要更新时候呢?各种情况很可能就造成数据库和缓存的数据不一致了。
这里不一致指的是:数据库的数据跟缓存的数据不一致

从理论上说,只要我们设置了键的过期时间,我们就能保证缓存和数据库的数据最终是一致的。因为只要缓存数据过期了,就会被删除。随后读的时候,因为缓存里没有,就可以查数据库的数据,然后将数据库查出来的数据写入到缓存中。
除了设置过期时间,我们还需要做更多的措施来尽量避免数据库与缓存处于不一致的情况发生。
3.3、对于更新操作
一般来说,执行更新操作时,我们会有两种选择:
先操作数据库,再操作缓存
先操作缓存,再操作数据库
首先,要明确的是,无论我们选择哪个,我们都希望这两个操作要么同时成功,要么同时失败。所以,这会演变成一个分布式事务的问题。
所以,如果原子性被破坏了,可能会有以下的情况:
操作数据库成功了,操作缓存失败了。
操作缓存成功了,操作数据库失败了。
如果第一步已经失败了,我们直接返回Exception出去就好了,第二步根本不会执行。
下面我们具体来分析一下吧。
3.3.1、操作缓存
操作缓存也有两种方案:
更新缓存
删除缓存
一般我们都是采取删除缓存缓存策略的,原因如下:
高并发环境下,无论是先操作数据库还是后操作数据库而言,如果加上更新缓存,那就更加容易导致数据库与缓存数据不一致问题。(删除缓存直接和简单很多)
如果每次更新了数据库,都要更新缓存【这里指的是频繁更新的场景,这会耗费一定的性能】,倒不如直接删除掉。等再次读取时,缓存里没有,那我到数据库找,在数据库找到再写到缓存里边(体现懒加载)
基于这两点,对于缓存在更新时而言,都是建议执行删除操作!
3.3.2、先更新数据库,再删除缓存
正常的情况是这样的:
先操作数据库,成功;
再删除缓存,也成功;
如果原子性被破坏了:
第一步成功(操作数据库),第二步失败(删除缓存),会导致数据库里是新数据,而缓存里是旧数据。
如果第一步(操作数据库)就失败了,我们可以直接返回错误(Exception),不会出现数据不一致。
如果在高并发的场景下,出现数据库与缓存数据不一致的概率特别低,也不是没有:
缓存刚好失效
线程A查询数据库,得一个旧值
线程B将新值写入数据库
线程B删除缓存
线程A将查到的旧值写入缓存
要达成上述情况,还是说一句概率特别低:
因为这个条件需要发生在读缓存时缓存失效,而且并发着有一个写操作。而实际上数据库的写操作会比读操作慢得多,而且还要锁表,而读操作必需在写操作前进入数据库操作,而又要晚于写操作更新缓存,所有的这些条件都具备的概率基本并不大。
对于这种策略,其实是一种设计模式:Cache Aside Pattern
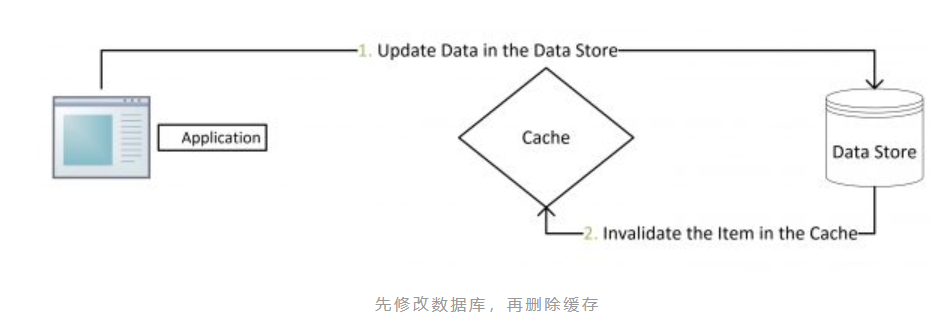
删除缓存失败的解决思路:
将需要删除的key发送到消息队列中
自己消费消息,获得需要删除的key
不断重试删除操作,直到成功
3.3.3、先删除缓存,再更新数据库
正常情况是这样的:
先删除缓存,成功;
再更新数据库,也成功;
如果原子性被破坏了:
第一步成功(删除缓存),第二步失败(更新数据库),数据库和缓存的数据还是一致的。
如果第一步(删除缓存)就失败了,我们可以直接返回错误(Exception),数据库和缓存的数据还是一致的。
看起来是很美好,但是我们在并发场景下分析一下,就知道还是有问题的了:
线程A删除了缓存
线程B查询,发现缓存已不存在
线程B去数据库查询得到旧值
线程B将旧值写入缓存
线程A将新值写入数据库
所以也会导致数据库和缓存不一致的问题。
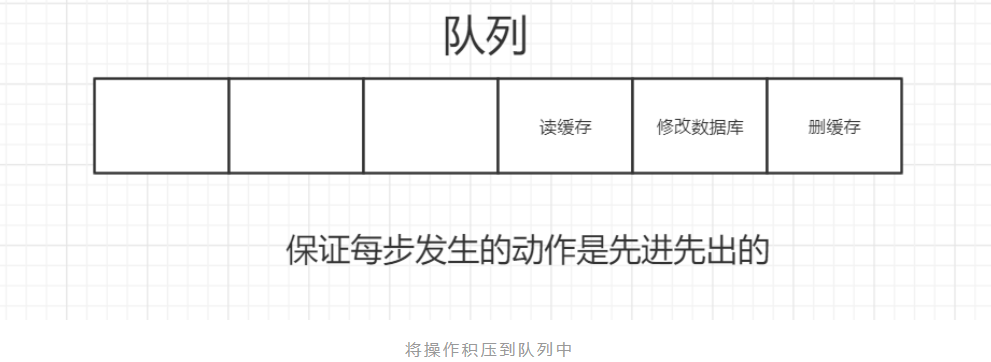
并发下解决数据库与缓存不一致的思路:
将删除缓存、修改数据库、读取缓存等的操作积压到队列里边,实现串行化。
3.4、对比两种策略
我们可以发现,两种策略各自有优缺点:
先删除缓存,再更新数据库
在高并发下表现不如意,在原子性被破坏时表现优异
先更新数据库,再删除缓存(
Cache Aside Pattern设计模式)在高并发下表现优异,在原子性被破坏时表现不如意
3.5、其他保障数据一致的方案与资料
可以用databus或者阿里的canal监听binlog进行更新。
redis缓存雪崩、缓存穿透、数据库和redis数据一致性的更多相关文章
- 什么是redis缓存穿透, 缓存雪崩, 缓存击穿
什么是redis? redis是一个非关系型数据库,相对于其他数据库而言,它的查询速度极快,且能承受的瞬时并发量非常的高.所以常常被用来存放网站的缓存,以减少主要数据库(如mysql)的服务器压力. ...
- 缓存雪崩、穿透如何解决,如何确保Redis只缓存热点数据?
缓存雪崩如何解决? 缓存穿透如何解决? 如何确保Redis缓存的都是热点数据? 如何更新缓存数据? 如何处理请求倾斜? 实际业务场景下,如何选择缓存数据结构 缓存雪崩 缓存雪崩简单说就是所有请求都从缓 ...
- 关于redis的几件小事(七)redis缓存雪崩与穿透
1.缓存雪崩 (1)什么是缓存雪崩 缓存雪崩指的是在同一时刻,缓存大量失效,导致大量的请求直接到了数据库,数据库压力剧增,引起系统崩溃.可能出现的情况有: ①大量的key设置了相同的过期时间,导致在缓 ...
- 8.了解什么是 redis 的雪崩、穿透和击穿?redis 崩溃之后会怎么样?系统该如何应对这种情况?如何处理 redis 的穿透?
作者:中华石杉 面试题 了解什么是 redis 的雪崩.穿透和击穿?redis 崩溃之后会怎么样?系统该如何应对这种情况?如何处理 redis 的穿透? 面试官心理分析 其实这是问到缓存必问的,因为缓 ...
- redis缓存雪崩、穿透、击穿概念及解决办法
缓存雪崩 对于系统 A,假设每天高峰期每秒 5000 个请求,本来缓存在高峰期可以扛住每秒 4000 个请求,但是缓存机器意外发生了全盘宕机.缓存挂了,此时 1 秒 5000 个请求全部落数据库,数据 ...
- Redis 缓存雪崩、穿透、击穿
缓存雪崩 定义: 同一时间所有 key 大面积失效,比如网站首页的数据基本上都是同一批次去缓存的. 解决方法: ① 存的时候设定随机的失效时间. ② 服务做熔断处理(异常或着慢查询 Hystrix 限 ...
- Java Redis缓存穿透/缓存雪崩/缓存击穿,Redis分布式锁实现秒杀,限购等
package com.example.redisdistlock.controller; import com.example.redisdistlock.util.RedisUtil; impor ...
- Redis缓存雪崩和穿透的解决方法
转载自: https://blog.csdn.net/qq_35433716/article/details/86375506 如何解决缓存雪崩?如何解决缓存穿透?如何保证缓存与数据库双写时一致的问题 ...
- redis的雪崩与穿透原理的浅理解
首先列一下主要说什么, 1.什么是Redis缓存的雪崩? 2.什么是Redis缓存的穿透? 3.Redis缓存崩溃会怎么样? 4.怎么预防Redis缓存崩溃? 1.什么是Redis缓存的雪崩? 举个栗 ...
- 什么是redis的雪崩和穿透
缓存雪崩 如何应对缓存雪崩 首先要保证redis的高可用,可以使用redis cluster,开启redis持久化,redis之前要使用本地缓存,请求先走本地缓存,没找到再走redis 如果还是出现了 ...
随机推荐
- Django Rest Framework(二)
•基于Django 先创建一个django项目,在项目中创建一些表,用来测试rest framework的各种组件 models.py class UserInfo(models.Model): &q ...
- Java 关于cannot resolve symbol 'log'报错问题
我用的是IDEA,报错的内容是:cannot resolve symbol 'log' 如图所示: 解决方法: 1.安装插件:Settings→Plugins,输入lom回车: 2.然后选择Insta ...
- 简单解析nestJS目录
使用Nest CLI设置新项目非常简单 .只需确保 安装了npm,然后在OS终端中使用以下命令: $ npm i -g @nestjs/cli $ nest new project-name $ cd ...
- linux 禁用root登录
1.新建一个用户,用来登录 # useradd aaaaa (已添加用户名aaaaa为例). 2.设置密码(需要切换到root下进行设置) # cd /root # ls #passwd bbbb ...
- pytorch错误:Missing key(s) in state_dict、Unexpected key(s) in state_dict解决
版权声明:本文为博主原创文章,欢迎转载,并请注明出处.联系方式:460356155@qq.com 在模型训练时加上: model = nn.DataParallel(model)cudnn.bench ...
- 解决win环境下访问本机虚拟机中centos7 ftp服务器的问题
inux搭建ftp服务器 1.安装软件: yum install vsftpd 2.修改配置文件vsftpd.conf: vim /etc/vsftpd/vsftpd.conf 把anonymous_ ...
- 《转载》最新鲜最详细的Android SDK下载安装及配置教程
Android开发环境搭建可以分: 第一步.安装JDK: 第二步.安装Eclipse: 第三步.下载并安装AndroidSDK: 下面详细介绍. 第一步.安装JDK Android开发工具要求必须 ...
- Activiti6-TaskService(学习笔记)重要
任务管理服务: 可以看出来,TaskService操作对象,主要针对于UserTask, 对于业务方来说,最重要的就是用户任务,可以对用户任务进行增删改查的管理.可以对相关流程的控制.也可以设置一些用 ...
- Manual write code to record error log in .net by Global.asax
完整的Glabal.asax代码: <%@ Application Language="C#" %> <script RunAt="server&quo ...
- 一本通网站 1378:最短路径(shopth)
[题目描述] 给出一个有向图G=(V, E),和一个源点v0∈V,请写一个程序输出v0和图G中其它顶点的最短路径.只要所有的有向环权值和都是正的,我们就允许图的边有负值.顶点的标号从1到n(n为图G的 ...