数据分析---《Python for Data Analysis》学习笔记【02】
《Python for Data Analysis》一书由Wes Mckinney所著,中文译名是《利用Python进行数据分析》。这里记录一下学习过程,其中有些方法和书中不同,是按自己比较熟悉的方式实现的。
第二个实例:MovieLens 1M Data Set
简介: GroupLens Research提供了从MovieLens用户那里收集来的一系列对90年代电影评分的数据
数据地址:http://files.grouplens.org/datasets/movielens/ml-1m.zip
准备工作:导入pandas和matplotlib
import pandas as pd
import matplotlib.pyplot as plt
fig,ax=plt.subplots()
压缩包里有三个.dat文件,分别是movies, users, ratings。这几个文件可以用pandas的read_table()方法读入并变为DataFrame格式,用names参数设置各个表的列名。
movies=pd.read_table(r"...\movies.dat", sep='::', engine='python', names=["movieId", "title", "genre"])
users=pd.read_table(r"...\users.dat", sep='::', engine='python', names=["userId", "gender", "age", "occupation", "zip"])
ratings=pd.read_table(r"...\ratings.dat", sep='::', engine='python', names=["userId", "movieId", "rating", "timestamp"])
接下来把这三张表合并在一起,以便于分析。其中movies和ratings先通过movieId列进行连接,然后合并的表再与users通过userId列进行连接。
data=pd.merge(pd.merge(movies, ratings, on="movieId", how="inner"), users, on="userId", how="inner")
合并的表前5行显示如下:
movieId title \
0 1 Toy Story (1995)
1 48 Pocahontas (1995)
2 150 Apollo 13 (1995)
3 260 Star Wars: Episode IV - A New Hope (1977)
4 527 Schindler's List (1993) genre userId rating timestamp gender \
0 Animation|Children's|Comedy 1 5 978824268 F
1 Animation|Children's|Musical|Romance 1 5 978824351 F
2 Drama 1 5 978301777 F
3 Action|Adventure|Fantasy|Sci-Fi 1 4 978300760 F
4 Drama|War 1 5 978824195 F age occupation zip
0 1 10 48067
1 1 10 48067
2 1 10 48067
3 1 10 48067
4 1 10 48067
上面可以看到,age这一列有明显的异常(1岁?),因此这里把data中age小于18岁和大于100岁的人去除。
data=data[(data["age"]>=18) & (data["age"]<=100)]
我们来看一下,按性别分组,对各部电影的平均评分是多少:
by_gender_movie_rating=pd.pivot_table(data, values="rating", index="title", columns="gender", aggfunc="mean")
这里用透视表展示了男女分别对各部电影的平均评分:
gender F M
title
$1,000,000 Duck (1971) 3.375000 2.761905
'Night Mother (1986) 3.400000 3.424242
'Til There Was You (1997) 2.694444 2.571429
'burbs, The (1989) 2.793478 2.947368
...And Justice for All (1979) 3.828571 3.693252
1-900 (1994) 2.000000 3.000000
10 Things I Hate About You (1999) 3.593137 3.303855
101 Dalmatians (1961) 3.789474 3.512535
101 Dalmatians (1996) 3.210526 2.928934
12 Angry Men (1957) 4.229008 4.318376
然而,我们考虑到如果一部电影打分的人太少,那么此评分就不会太准确,该电影就不能作为取样。因此,我们要对每部电影打分的人数进行统计,并把评分人数超过250的电影筛选出来。
movie_counts=data.groupby('title')['title'].count()
movies_select=movie_counts.index[movie_counts.values>=250]
然后,我们把上面的透视表按照选出的电影movies_select进行筛选,选出所有符合条件的行:
by_gender_movie_rating=by_gender_movie_rating.loc[movies_select]
我们再来看看现在透视表变成了什么样:
gender F M
title
'burbs, The (1989) 2.793478 2.947368
10 Things I Hate About You (1999) 3.593137 3.303855
101 Dalmatians (1961) 3.789474 3.512535
101 Dalmatians (1996) 3.210526 2.928934
12 Angry Men (1957) 4.229008 4.318376
13th Warrior, The (1999) 3.084746 3.172185
2 Days in the Valley (1996) 3.477273 3.246862
20,000 Leagues Under the Sea (1954) 3.648936 3.723404
2001: A Space Odyssey (1968) 3.829341 4.125931
2010 (1984) 3.456522 3.418269
现在,如果我们想知道女性评分最高的10部电影分别是什么,那么我们可以对F列的值进行排序:
top_female_rating=by_gender_movie_rating.sort_values(by='F', ascending=False)
以下是结果:
gender F M
title
Close Shave, A (1995) 4.672619 4.479121
Wrong Trousers, The (1993) 4.611607 4.485390
Wallace & Gromit: The Best of Aardman Animation... 4.587629 4.413043
Grand Day Out, A (1992) 4.581967 4.288820
Sunset Blvd. (a.k.a. Sunset Boulevard) (1950) 4.575221 4.476744
Schindler's List (1993) 4.563333 4.493325
To Kill a Mockingbird (1962) 4.539792 4.395387
Shawshank Redemption, The (1994) 4.539088 4.560944
Creature Comforts (1990) 4.514286 4.287958
Usual Suspects, The (1995) 4.512255 4.520864
现在,我们想看一下男女评分差异最大的10部电影分别是什么。首先,给透视表增加差别列-diff,然后再对diff列的值进行排序。
import numpy as np
by_gender_movie_rating["diff"]=np.abs(by_gender_movie_rating["F"]-by_gender_movie_rating["M"]) top_diff_rating=by_gender_movie_rating.sort_values(by='diff', ascending=False)
来看一下top_diff_rating的前10行:
gender F M diff
title
Dirty Dancing (1987) 3.762590 2.961929 0.800661
Good, The Bad and The Ugly, The (1966) 3.484536 4.223776 0.739240
Jumpin' Jack Flash (1986) 3.269231 2.582707 0.686524
Kentucky Fried Movie, The (1977) 2.875000 3.555970 0.680970
Dumb & Dumber (1994) 2.700000 3.318275 0.618275
Hidden, The (1987) 3.137931 3.744094 0.606163
Cable Guy, The (1996) 2.280488 2.878472 0.597984
Grease (1978) 3.958955 3.376673 0.582282
Rocky III (1982) 2.361702 2.939828 0.578126
Evil Dead II (Dead By Dawn) (1987) 3.328767 3.900000 0.571233
如果想知道不论男女,所有观众评分差异最大的10部电影,那么我们先计算出总评分的标准差,再提取评分人数超过250的电影,最后按标准差进行排序。
movie_rating_std=data.groupby('title')['rating'].std()
movie_rating_std=movie_rating_std.loc[movies_select]
top_rating_std=movie_rating_std.sort_values(ascending=False)
结果如下:
title
Dumb & Dumber (1994) 1.324767
Blair Witch Project, The (1999) 1.319496
Natural Born Killers (1994) 1.305525
Tank Girl (1995) 1.278513
Rocky Horror Picture Show, The (1975) 1.259985
Eyes Wide Shut (1999) 1.254972
Fear and Loathing in Las Vegas (1998) 1.247835
Evita (1996) 1.247072
Hellraiser (1987) 1.243238
South Park: Bigger, Longer and Uncut (1999) 1.237987
Name: rating, dtype: float64
至此,书中的分析已全部结束。以下是我自己增加的一些分析内容:
如果我们想知道总评分最高的10部电影,男女评分之间有没有很大的差异,那么我们先在上面的透视表by_gender_movie_rating里增加一个总评分栏,然后按照总评分进行排序。
movie_rating=data.groupby('title')['rating'].mean() #先把总平均评分算出来
movie_rating=movie_rating.loc[movies_select] #摘选评分人数超过250的电影
by_gender_movie_rating['total']=movie_rating.values #在透视表中增加总平均评分一列
top_rating=by_gender_movie_rating.sort_values(by='total', ascending=False) #按总平均评分排序
top_rating的前10行如下:
gender F M \
title
Seven Samurai (The Magnificent Seven) (Shichini... 4.471154 4.580392
Shawshank Redemption, The (1994) 4.539088 4.560944
Close Shave, A (1995) 4.672619 4.479121
Godfather, The (1972) 4.319829 4.583186
Wrong Trousers, The (1993) 4.611607 4.485390
Usual Suspects, The (1995) 4.512255 4.520864
Schindler's List (1993) 4.563333 4.493325
Sunset Blvd. (a.k.a. Sunset Boulevard) (1950) 4.575221 4.476744
Raiders of the Lost Ark (1981) 4.341727 4.529474
Rear Window (1954) 4.475524 4.482480 gender diff total
title
Seven Samurai (The Magnificent Seven) (Shichini... 0.109238 4.561889
Shawshank Redemption, The (1994) 0.021857 4.554791
Close Shave, A (1995) 0.193498 4.531300
Godfather, The (1972) 0.263357 4.526267
Wrong Trousers, The (1993) 0.126218 4.519048
Usual Suspects, The (1995) 0.008609 4.518857
Schindler's List (1993) 0.070008 4.512011
Sunset Blvd. (a.k.a. Sunset Boulevard) (1950) 0.098477 4.501094
Raiders of the Lost Ark (1981) 0.187748 4.486675
Rear Window (1954) 0.006955 4.480545
用柱形图画出来进行比较:
ax.bar(range(10), top_rating['F'][:10], width=-0.3, label='Female', align='edge')
ax.bar([i+0.3 for i in range(10)], top_rating['M'][:10], width=-0.3, label='Male', align='edge')
ax.set_xticks(range(10))
ax.set_ylim(4,5)
ax.set_xticklabels(top_rating[:10].index.values, rotation=90)
ax.legend() plt.show()
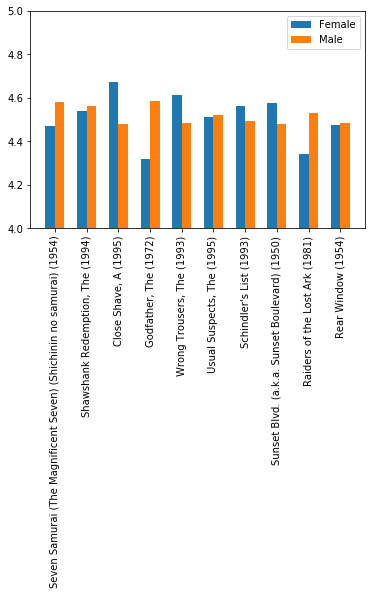
可以看到,男性对教父的评分比女性要高很多。
现在,让我们再来看看各个年龄段最喜欢的10部电影是什么。
首先,对年龄进行分组,并在data数据里添加年龄分组这一列:
age_range=pd.cut(data['age'], 3, labels=['Young', 'Middle', 'Old'])
data['age_range']=age_range
data的前10行现在如下:
movieId title \
53 1 Toy Story (1995)
54 17 Sense and Sensibility (1995)
55 34 Babe (1995)
56 48 Pocahontas (1995)
57 199 Umbrellas of Cherbourg, The (Parapluies de Che...
58 266 Legends of the Fall (1994)
59 296 Pulp Fiction (1994)
60 364 Lion King, The (1994)
61 368 Maverick (1994)
62 377 Speed (1994) genre userId rating timestamp gender \
53 Animation|Children's|Comedy 6 4 978237008 F
54 Drama|Romance 6 4 978236383 F
55 Children's|Comedy|Drama 6 4 978237444 F
56 Animation|Children's|Musical|Romance 6 5 978237570 F
57 Drama|Musical 6 5 978237570 F
58 Drama|Romance|War|Western 6 4 978237909 F
59 Crime|Drama 6 2 978237379 F
60 Animation|Children's|Musical 6 4 978237570 F
61 Action|Comedy|Western 6 4 978237909 F
62 Action|Romance|Thriller 6 3 978236383 F age occupation zip age_range
53 50 9 55117 Old
54 50 9 55117 Old
55 50 9 55117 Old
56 50 9 55117 Old
57 50 9 55117 Old
58 50 9 55117 Old
59 50 9 55117 Old
60 50 9 55117 Old
61 50 9 55117 Old
62 50 9 55117 Old
然后,按年龄段作为列,制作透视表:
by_age_movie_rating=pd.pivot_table(data, values="rating", index="title", columns="age_range", aggfunc="mean")
这里透视表by_age_movie_rating展示了各个年龄段的观众对各部电影的平均评分:
age_range Middle Old Young
title
$1,000,000 Duck (1971) 3.133333 2.600000 3.058824
'Night Mother (1986) 2.904762 3.777778 3.551724
'Til There Was You (1997) 2.900000 2.500000 2.625000
'burbs, The (1989) 2.818182 2.951220 2.912195
...And Justice for All (1979) 3.657143 3.809524 3.692308
1-900 (1994) NaN 3.000000 2.000000
10 Things I Hate About You (1999) 3.102941 3.476190 3.424125
101 Dalmatians (1961) 3.826087 3.692308 3.488746
101 Dalmatians (1996) 3.279570 3.460317 2.764368
12 Angry Men (1957) 4.358333 4.268156 4.293333
可以看到上面有缺失值,应该是该年龄段没有人对此电影进行评分。因此,我们把缺失值变为0。同时,把评分人数超过250的电影筛选出来:
by_age_movie_rating=by_age_movie_rating.fillna(0)
by_age_movie_rating=by_age_movie_rating.loc[movies_select]
然后我们按Young这一列的值来排序,看看年轻人评分最高的10部电影是什么:
top_young_movie_rating=by_age_movie_rating.sort_values(by='Young', ascending=False)
结果如下:
age_range Middle Old \
title
Shawshank Redemption, The (1994) 4.487500 4.423690
Usual Suspects, The (1995) 4.390879 4.319231
Seven Samurai (The Magnificent Seven) (Shichini... 4.532895 4.581006
Godfather, The (1972) 4.541935 4.452290
Close Shave, A (1995) 4.450704 4.577465
Star Wars: Episode IV - A New Hope (1977) 4.354633 4.386760
Raiders of the Lost Ark (1981) 4.475538 4.414737
Wrong Trousers, The (1993) 4.443850 4.663866
Rear Window (1954) 4.479245 4.461818
Sunset Blvd. (a.k.a. Sunset Boulevard) (1950) 4.611570 4.432624 age_range Young
title
Shawshank Redemption, The (1994) 4.617735
Usual Suspects, The (1995) 4.595943
Seven Samurai (The Magnificent Seven) (Shichini... 4.565371
Godfather, The (1972) 4.552921
Close Shave, A (1995) 4.551220
Star Wars: Episode IV - A New Hope (1977) 4.524260
Raiders of the Lost Ark (1981) 4.514109
Wrong Trousers, The (1993) 4.513109
Rear Window (1954) 4.491803
Sunset Blvd. (a.k.a. Sunset Boulevard) (1950) 4.482051
第一名是肖申克的救赎。
用同样的方法,我们可以看到老年组评分最高的电影是Wrong Trousers, The (1993),中年组评分最高的电影是Sunset Blvd. (a.k.a. Sunset Boulevard) (1950)。
数据分析---《Python for Data Analysis》学习笔记【02】的更多相关文章
- Python for Data Analysis 学习心得(一) - numpy介绍
一.简介 Python for Data Analysis这本书的特点是将numpy和pandas这两个工具介绍的很详细,这两个工具是使用Python做数据分析非常重要的一环,numpy主要是做矩阵的 ...
- Python for Data Analysis 学习心得(四) - 数据清洗、接合
一.文字处理 之前在练习爬虫时,常常爬了一堆乱七八糟的字符下来,当时就有找网络上一些清洗数据的方式,这边pandas也有提供一些,可以参考使用看看.下面为两个比较常见的指令,往往会搭配使用. spli ...
- Python for Data Analysis 学习心得(三) - 文件读写和数据预处理
一.Pandas文件读写 pandas很核心的一个功能就是数据读取.导入,pandas支援大部分主流的数据储存格式,并在导入的时候可以做筛选.预处理.在读取数据时的选项有超过50个参数,可见panda ...
- Python for Data Analysis 学习心得(二) - pandas介绍
一.pandas介绍 本篇程序上篇内容,在numpy下面继续介绍pandas,本书的作者是pandas的作者之一.pandas是非常好用的数据预处理工具,pandas下面有两个数据结构,分别为Seri ...
- 数据分析---《Python for Data Analysis》学习笔记【03】
<Python for Data Analysis>一书由Wes Mckinney所著,中文译名是<利用Python进行数据分析>.这里记录一下学习过程,其中有些方法和书中不同 ...
- 数据分析---《Python for Data Analysis》学习笔记【04】
<Python for Data Analysis>一书由Wes Mckinney所著,中文译名是<利用Python进行数据分析>.这里记录一下学习过程,其中有些方法和书中不同 ...
- 数据分析---《Python for Data Analysis》学习笔记【01】
<Python for Data Analysis>一书由Wes Mckinney所著,中文译名是<利用Python进行数据分析>.这里记录一下学习过程,其中有些方法和书中不同 ...
- 学习笔记之Python for Data Analysis
Python for Data Analysis, 2nd Edition https://www.safaribooksonline.com/library/view/python-for-data ...
- 1.2 Why Python for Data Analysis(为什么使用Python做数据分析)
1.2 Why Python for Data Analysis?(为什么使用Python做数据分析) 这节我就不进行过多介绍了,Python近几年的发展势头是有目共睹的,尤其是在科学计算,数据处理, ...
随机推荐
- 深海中的STL—mt19937
mt19937 当你第一眼看到这玩意儿的时候 肯定禁不住吐槽:纳尼?这是什么鬼? 确实,这个东西鲜为人知,但是它却有着卓越的性能 简介 mt19937是c++11中加入的新特性 它是一种随机数算法,用 ...
- arcgis api 3.x for js入门开发系列九热力图效果(附源码下载)
前言 关于本篇功能实现用到的 api 涉及类看不懂的,请参照 esri 官网的 arcgis api 3.x for js:esri 官网 api,里面详细的介绍 arcgis api 3.x 各个类 ...
- C++ 死循环在语言层面的检测
英文概念 Infinite loop without side-effects 这个目前只有CLang实现了这个C++特色 #include <iostream> int 费马定理() { ...
- MTK Android O1平台预置apk
在MTK Android O1平台预置apk为可卸载时.预置到旧的路径system/vendor/operator/app会编译报错,"You cannot install files to ...
- AngularJS学习之旅—AngularJS 服务(八)
1.AngularJS 服务(Service) AngularJS 中你可以创建自己的服务,或使用内建服务.2.什么是服务? 在 AngularJS 中,服务是一个函数或对象,可在你的 Angular ...
- Kafka 特性
Kafka 特性 标签(空格分隔): Kafka 支持多个生产者 多个生成者连接Kafka来推送消息,这个和其他的消息队列功能基本上是一样的 支持多个消费者 Kafka支持多个消费者来读取同一个消息流 ...
- ThinkPHP中使用聚合查询去重求和
我使用的是TP5.1 首先去model类里面设置failed条件: 想要的效果: 数据库展示: 代码: eturn self::alias('gr') ->join('gs_staff gs', ...
- Gitlab利用Webhook实现Push代码后的jenkins自动构建
之前部署了Gitlab的代码托管平台和Jenkins的代码发布平台.通常是开发后的代码先推到Gitlab上管理,然后在Jenkins里通过脚本构建代码发布.这种方式每次在发版的时候,需要人工去执行je ...
- 【任务】Python语言程序设计.MOOC学习
[博客导航] [Python导航] 任务 18年11月29日开始,通过9周时间跨度,投入约50小时时间,在19年1月25日之前,完成中国大学MOOC平台上的<Python语言程序设计>课程 ...
- Java学习笔记记录(一)
1.Java编写的一个基本结构 1 public class demo{ //以下包含权限修饰符.静态修饰符.返回值修饰符以及主方法main() 2 public static void main(S ...