ThreadPoolExecutor 源码阅读
ThreadPoolExecutor 源码阅读
读了一下 ThreadPoolExecutor 的源码(JDK 11), 简单的做个笔记.
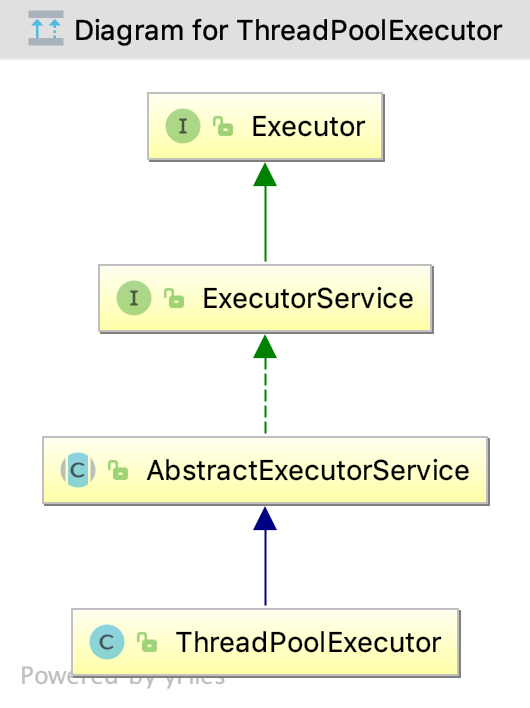
Executor 框架
Executor
Executor 接口只有一个方法:
public interface Executor {
void execute(Runnable command);
}
Executor 接口提供了一种将任务提交和任务执行机制解耦的方法. Executor 的实现并不须要是异步的.
ExecutorService
ExecutorService 在 Executor 的基础上, 提供了一些管理终止的方法和可以生成 Future 来跟踪一个或多个异步任务的进度的方法:

shutdown()方法会启动比较柔和的关闭过程, 并且不会阻塞.ExecutorService将会继续执行已经提交的任务, 但不会再接受新的任务. 如果ExecutorService已经被关闭, 则不会有附加的操作.shutdownNow()方法会尝试停止正在执行的任务, 不再执行等待执行的任务, 并且返回等待执行的任务列表, 不会阻塞. 这个方法只能尝试停止任务, 典型的取消实现是通过中断来取消任务, 因此不能响应中断的任务可能永远不会终止.invokeAll()方法执行给定集合中的所有任务, 当所有任务完成时返回Future的列表, 支持中断. 如果在此操作正在进行时修改了给定的集合,则此方法的结果未定义.invokeAny()方法会执行给定集合中的任务, 当有一个任务完成时, 返回这个任务的结果, 并取消其他未完成的任务, 支持中断. 如果在此操作正在进行时修改了给定的集合,则此方法的结果未定义.
AbstractExecutorService
AbstractExecutorService 提供了一些 ExecutorService 的执行方法的默认实现. 这个方法使用了 newTaskFor() 方法返回的 RunnableFuture (默认是 FutureTask ) 来实现 submit() 、invokeAll() 、 invokeAny() 方法.
RunnableFuture 继承了 Runnable 和 Future , 在 run() 方法成功执行后, 将会设置完成状态, 并允许获取执行的结果:
public interface RunnableFuture<V> extends Runnable, Future<V> {
/**
* Sets this Future to the result of its computation
* unless it has been cancelled.
*/
void run();
}
FutureTask
FutureTask 实现了 RunnableFuture 接口, 表示一个可取消的计算任务, 只能在任务完成之后获取结果, 并且在任务完成后, 就不再能取消或重启, 除非使用 runAndReset() 方法.
FutureTask 有 7 个状态:
- NEW
- COMPLETING
- NORMAL
- EXCEPTIONAL
- CANCELLED
- INTERRUPTING
- INTERRUPTED
可能的状态转换:
- NEW -> COMPLETING -> NORMAL
- NEW -> COMPLETING -> EXCEPTIONAL
- NEW -> CANCELLED
- NEW -> INTERRUPTING -> INTERRUPTED
FutureTask 在更新 state 、 runner、 waiters 时, 都使用了 VarHandle.compareAndSet() :
// VarHandle mechanics
private static final VarHandle STATE;
private static final VarHandle RUNNER;
private static final VarHandle WAITERS;
static {
try {
MethodHandles.Lookup l = MethodHandles.lookup();
STATE = l.findVarHandle(FutureTask.class, "state", int.class);
RUNNER = l.findVarHandle(FutureTask.class, "runner", Thread.class);
WAITERS = l.findVarHandle(FutureTask.class, "waiters", WaitNode.class);
} catch (ReflectiveOperationException e) {
throw new ExceptionInInitializerError(e);
}
// Reduce the risk of rare disastrous classloading in first call to
// LockSupport.park: https://bugs.openjdk.java.net/browse/JDK-8074773
Class<?> ensureLoaded = LockSupport.class;
}
protected void set(V v) {
if (STATE.compareAndSet(this, NEW, COMPLETING)) {
outcome = v;
STATE.setRelease(this, NORMAL); // final state
finishCompletion();
}
}
来看一下 get() 方法:
public V get(long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException {
if (unit == null)
throw new NullPointerException();
int s = state;
if (s <= COMPLETING &&
(s = awaitDone(true, unit.toNanos(timeout))) <= COMPLETING)
throw new TimeoutException();
return report(s);
}
private int awaitDone(boolean timed, long nanos)
throws InterruptedException {
long startTime = 0L;
WaitNode q = null;
boolean queued = false;
for (;;) {
int s = state;
if (s > COMPLETING) {
// 已经在终结状态, 返回状态
if (q != null)
q.thread = null;
return s;
}
else if (s == COMPLETING)
// 已经完成了, 但是状态还是 COMPLETING
Thread.yield();
else if (Thread.interrupted()) {
// 检查中断
removeWaiter(q);
throw new InterruptedException();
}
else if (q == null) {
// 没有创建 WaitNode 节点, 如果 timed 并且 nanos 大于 0, 创建一个 WaitNode
if (timed && nanos <= 0L)
return s;
q = new WaitNode();
}
else if (!queued)
// 将新的 WaitNode 放到链表头部, 并尝试 cas 到 waiters
queued = WAITERS.weakCompareAndSet(this, q.next = waiters, q);
else if (timed) {
final long parkNanos;
if (startTime == 0L) { // first time
startTime = System.nanoTime();
if (startTime == 0L)
startTime = 1L;
parkNanos = nanos;
} else {
long elapsed = System.nanoTime() - startTime;
if (elapsed >= nanos) {
// 超时了
removeWaiter(q);
return state;
}
// park 的时间
parkNanos = nanos - elapsed;
}
// nanos 比较慢, 再次检查, 然后阻塞
if (state < COMPLETING)
LockSupport.parkNanos(this, parkNanos);
}
else
// 不需要超时的阻塞
LockSupport.park(this);
}
}
再来看下 run() 方法:
public void run() {
if (state != NEW ||
!RUNNER.compareAndSet(this, null, Thread.currentThread()))
// 不在 NEW 状态, 或者 runner 不为 null
return;
try {
// callable 是在构造器中指定的或用 Executors.callable(runnable, result) 创建的
Callable<V> c = callable;
if (c != null && state == NEW) {
V result;
boolean ran;
try {
result = c.call();
ran = true;
} catch (Throwable ex) {
result = null;
ran = false;
// 设置异常状态和异常结果
setException(ex);
}
if (ran)
// 正常完成, 设置完成状态和结果
set(result);
}
} finally {
// runner must be non-null until state is settled to
// prevent concurrent calls to run()
runner = null;
// state must be re-read after nulling runner to prevent
// leaked interrupts
int s = state;
if (s >= INTERRUPTING)
handlePossibleCancellationInterrupt(s);
}
}
protected void set(V v) {
if (STATE.compareAndSet(this, NEW, COMPLETING)) {
outcome = v;
STATE.setRelease(this, NORMAL); // final state
finishCompletion();
}
}
private void finishCompletion() {
// assert state > COMPLETING;
for (WaitNode q; (q = waiters) != null;) {
if (WAITERS.weakCompareAndSet(this, q, null)) {
// cas 移除 waiters, 对链表中的每个 Node 的线程 unpark
for (;;) {
Thread t = q.thread;
if (t != null) {
q.thread = null;
LockSupport.unpark(t);
}
WaitNode next = q.next;
if (next == null)
break;
q.next = null; // unlink to help gc
q = next;
}
break;
}
}
// 默认实现什么都没做
done();
callable = null; // to reduce footprint
}
AbstractExecutorService 的执行方法
来看下 AbstractExecutorService 实现的几个执行方法, 这里就只放上以 Callable 为参数的方法:
protected <T> RunnableFuture<T> newTaskFor(Callable<T> callable) {
return new FutureTask<T>(callable);
}
public <T> Future<T> submit(Callable<T> task) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task);
execute(ftask);
return ftask;
}
public <T> T invokeAny(Collection<? extends Callable<T>> tasks)
throws InterruptedException, ExecutionException {
try {
return doInvokeAny(tasks, false, 0);
} catch (TimeoutException cannotHappen) {
assert false;
return null;
}
}
private <T> T doInvokeAny(Collection<? extends Callable<T>> tasks,
boolean timed, long nanos)
throws InterruptedException, ExecutionException, TimeoutException {
if (tasks == null)
throw new NullPointerException();
int ntasks = tasks.size();
if (ntasks == 0)
throw new IllegalArgumentException();
ArrayList<Future<T>> futures = new ArrayList<>(ntasks);
ExecutorCompletionService<T> ecs =
new ExecutorCompletionService<T>(this);
try {
ExecutionException ee = null;
final long deadline = timed ? System.nanoTime() + nanos : 0L;
Iterator<? extends Callable<T>> it = tasks.iterator();
// 提交一个任务到 ecs
futures.add(ecs.submit(it.next()));
--ntasks;
int active = 1;
for (;;) {
// 尝试获取第一个完成的任务的 Future
Future<T> f = ecs.poll();
if (f == null) {
// 没有完成的任务
if (ntasks > 0) {
// 还有没提交的任务, 再提交一个到 ecs
--ntasks;
futures.add(ecs.submit(it.next()));
++active;
}
else if (active == 0)
// 没有还没提交的任务和正在执行的任务了
break;
else if (timed) {
f = ecs.poll(nanos, NANOSECONDS);
if (f == null)
throw new TimeoutException();
nanos = deadline - System.nanoTime();
}
else
f = ecs.take();
}
if (f != null) {
// 存在已经完成的任务
--active;
try {
// 获取结果并返回
return f.get();
} catch (ExecutionException eex) {
ee = eex;
} catch (RuntimeException rex) {
ee = new ExecutionException(rex);
}
}
}
// 出错, 抛出
if (ee == null)
ee = new ExecutionException();
throw ee;
} finally {
// 取消所有已经提交的任务
cancelAll(futures);
}
}
public <T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks)
throws InterruptedException {
if (tasks == null)
throw new NullPointerException();
ArrayList<Future<T>> futures = new ArrayList<>(tasks.size());
try {
for (Callable<T> t : tasks) {
// 提交任务
RunnableFuture<T> f = newTaskFor(t);
futures.add(f);
execute(f);
}
for (int i = 0, size = futures.size(); i < size; i++) {
Future<T> f = futures.get(i);
if (!f.isDone()) {
// 任务没有完成, get() 等待任务完成
try { f.get(); }
catch (CancellationException | ExecutionException ignore) {}
}
}
return futures;
} catch (Throwable t) {
cancelAll(futures);
throw t;
}
}
构造器
ThreadPoolExecutor 一共有4个构造器, 这里就只放上两个构造器:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
参数说明:
- corePoolSize: 在线程池中保持的线程的数量, 即使这些线程是空闲的, 除非
allowCoreThreadTimeOut被设置为true; - maximumPoolSize: 线程池中最大线程数量;
- keepAliveTime: 多余空闲线程在终止之前等待新任务的最长时间;
- unit:
keepAliveTime的时间单位; - workQueue: 任务的等待队列, 用于存放等待执行的任务. 仅包含
execute()方法提交的Runnable; - threadFactory: executor 用来创建线程的工厂, 默认使用
Executors.defaultThreadFactory()来创建一个新的工厂; - handler: 任务因为达到了线程边界和队列容量而被阻止时的处理程序, 默认使用
AbortPolicy.
状态
ThreadPoolExecutor 有5个状态:
- RUNNING: 接受新任务, 并且处理队列中的任务;
- SHUTDOWN: 不接受新任务, 但是处理队列中的任务, 此时仍然可能创建新的线程;
- STOP: 不接受新任务, 处理队列中的任务, 中断正在运行的任务;
- TIDYING: 所有的任务都终结了, workCount 的值是0, 将状态转换为 TIDYING 的线程会执行
terminated()方法; - TERMINATED:
terminated()方法执行完毕.
状态转换:
- RUNNING -> SHUTDOWN , On invocation of shutdown()
- (RUNNING or SHUTDOWN) -> STOP , On invocation of shutdownNow()
- SHUTDOWN -> TIDYING , When both queue and pool are empty
- STOP -> TIDYING , When pool is empty
- TIDYING -> TERMINATED , When the terminated() hook method has completed
workCount 和 state 被打包在一个 AtomicInteger 中, 其中的高三位用于表示线程池状态( state ), 低 29 位用于表示 workCount:
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static final int COUNT_BITS = Integer.SIZE - 3;
private static final int COUNT_MASK = (1 << COUNT_BITS) - 1;
// runState is stored in the high-order bits
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
// Packing and unpacking ctl
private static int runStateOf(int c) { return c & ~COUNT_MASK; }
private static int workerCountOf(int c) { return c & COUNT_MASK; }
private static int ctlOf(int rs, int wc) { return rs | wc; }
workCount 表示有效的线程数量, 是允许启动且不允许停止的 worker 的数量, 与实际的线程数量瞬时不同. 用户可见的线程池大小是 Worker 集合的大小.
Worker 与任务调度
工作线程被封装在 Worker 中 , 并且存放在一个 HashSet (workers) 中由 mainLock 保护:
/**
* Set containing all worker threads in pool. Accessed only when
* holding mainLock.
*/
private final HashSet<Worker> workers = new HashSet<>();
private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable
{
/**
* This class will never be serialized, but we provide a
* serialVersionUID to suppress a javac warning.
*/
private static final long serialVersionUID = 6138294804551838833L;
final Thread thread;
Runnable firstTask;
volatile long completedTasks;
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
/** Delegates main run loop to outer runWorker. */
public void run() {
runWorker(this);
}
...
}
Worker.run()方法很简单, 直接调用了 runWorker() 方法, 来看一下这个方法的源码:
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
while (task != null || (task = getTask()) != null) {
// task 不为 null 或 获取到了需要执行的任务; getTask() 会阻塞, 并在线程需要退出时返回 null
w.lock();
// 检查线程池状态和线程的中断状态, 如果被中断, 代表线程池正在 STOP
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
// 重新设置中断状态
wt.interrupt();
try {
// 执行前的钩子
beforeExecute(wt, task);
try {
// 执行任务
task.run();
// 执行后的钩子
afterExecute(task, null);
} catch (Throwable ex) {
// 执行后的钩子
afterExecute(task, ex);
throw ex;
}
} finally {
// 更新状态, 准备处理下一个任务
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
// 处理 Worker 的退出
processWorkerExit(w, completedAbruptly);
}
}
getTask() 方法会在以下4种情况返回 null :
- workCount 大于 maximumPoolSize;
- 线程池已经处于 STOP 状态;
- 线程池已经处于 SHUTDOWN 状态, 并且任务队列为空;
- 等待任务时超时, 并且超时的 worker 需要被终止.
private Runnable getTask() {
boolean timedOut = false; // Did the last poll() time out?
for (;;) {
int c = ctl.get();
if (runStateAtLeast(c, SHUTDOWN)
&& (runStateAtLeast(c, STOP) || workQueue.isEmpty())) {
// 线程池已经处于 SHUTDOWN 状态, 并且不在需要线程 (线程池已经处于 STOP 状态 或 workQueue 为空)
decrementWorkerCount();
return null;
}
int wc = workerCountOf(c);
// 是否需要剔除超时的 worker
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
// 需要剔除当前 worker, 尝试调整 workerCount
if (compareAndDecrementWorkerCount(c))
// 成功 返回 null
return null;
continue;
}
try {
// 阻塞获取任务
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
// 设置超时标记, 下一次循环中检查是否需要返回 null
timedOut = true;
} catch (InterruptedException retry) {
// 被中断, 设置超时标记, 下一次循环中检查是否需要返回 null
timedOut = false;
}
}
}
processWorkerExit() 方法负责垂死 worker 的清理和簿记, 只会被工作线程调用:
private void processWorkerExit(Worker w, boolean completedAbruptly) {
if (completedAbruptly) // If abrupt, then workerCount wasn't adjusted
decrementWorkerCount();
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// 更新线程池完成的任务数量
completedTaskCount += w.completedTasks;
workers.remove(w);
} finally {
mainLock.unlock();
}
// 尝试转换线程池状态到终止
tryTerminate();
int c = ctl.get();
if (runStateLessThan(c, STOP)) {
if (!completedAbruptly) {
// 不是由于用户代码异常而突然退出
int min = allowCoreThreadTimeOut ? 0 : corePoolSize;
if (min == 0 && ! workQueue.isEmpty())
min = 1;
if (workerCountOf(c) >= min)
// 不需要在添加新 worker
return;
}
// 尝试添加新的 worker
addWorker(null, false);
}
}
提交任务
ThreadPoolExecutor 没有重写 submit() 方法, 我们只要看一下 execute() 就够了:
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
// 有效线程数量小于 corePoolSize 尝试调用 addWorker 来增加一个线程(在 addWorker 方法中使用 corePoolSize 来检查是否需要增加线程), 使用 corePoolSize 作为, 并把 command 作为新线程的第一个任务
if (addWorker(command, true))
return;
// 调用失败, 重新获取状态
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
// 线程池仍然在运行, 将 command 加入 workQueue 成功, 再次检查状态, 因为此时线程池状态可能已经改变, 按照新的状态拒绝 command 或尝试添加新的线程
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
// 不再是运行中状态, 尝试从队列移除 command(还会尝试将线程池状态转换为 TERMINATED), 拒绝command
reject(command);
else if (workerCountOf(recheck) == 0)
// 有效线程数量为 0 , 创建新的线程, 在 addWorker 方法中使用 maximumPoolSize 来检查是否需要增加线程
addWorker(null, false);
}
else if (!addWorker(command, false))
// 将任务放入队列失败或线程池不在运行状态, 并且尝试添加线程失败(此时线程池已经 shutdown 或饱和), 拒绝任务
reject(command);
}
addWorker() 方法有两个参数 Runnable firstTask 和 boolean core . firstTask 是新建的工作线程的第一个任务; core 如果为 true , 表示用 corePoolSize 作为边界条件, 否则表示用 maximumPoolSize. 这里的 core 用布尔值是为了确保检查最新的状态.
addWorker() 主要做了这么两件事情:
- 是否可以在当前线程池状态和给定的边界条件(core or maximum)下创建一个新的工作线程;
- 如果可以, 调整 worker counter, 如果可能的话, 创建一个新的 worker 并启动它, 把 firstTask 作为这个新 worker 的第一个任务;
来看下 addWorker() 方法的源码:
private boolean addWorker(Runnable firstTask, boolean core) {
// 重试标签
retry:
for (int c = ctl.get();;) {
// 获取最新的状态, 检查状态
if (runStateAtLeast(c, SHUTDOWN)
&& (runStateAtLeast(c, STOP)
|| firstTask != null
|| workQueue.isEmpty()))
// 如果线程池状态已经进入 SHUDOWN, 并且不再需要工作线程(已经进入 STOP 状态 或 firstTask 不为 null 或 workQueue为空) 返回 false
return false;
for (;;) {
if (workerCountOf(c)
>= ((core ? corePoolSize : maximumPoolSize) & COUNT_MASK))
// 有效线程数量大于边界条件, 返回 false
return false;
if (compareAndIncrementWorkerCount(c))
// 调整 workerCount, break retry, 退出外部循环
break retry;
c = ctl.get(); // Re-read ctl
if (runStateAtLeast(c, SHUTDOWN))
// 因为状态变化导致 CAS 失败, continue retry, 重试外部循环
continue retry;
// 由于 workerCount 改变导致 CAS 失败, 重试内嵌循环
}
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
// 新建 Worker
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
// threadFactory 成功创建了线程
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
int c = ctl.get();
// 重新检查状态
if (isRunning(c) ||
(runStateLessThan(c, STOP) && firstTask == null)) {
// 线程池在 RUNNING 状态 或 需要线程(线程池还不在 STOP 状态 并且 firstTask 为 null)
// 检查线程是否可启动
if (t.isAlive())
throw new IllegalThreadStateException();
// 将 worker 添加到 workers
workers.add(w);
// 更新 largestPoolSize
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
// 更新 worker 添加的标记
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
// 启动线程, 更新启动标记
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
// 失败回滚
addWorkerFailed(w);
}
return workerStarted;
}
private void addWorkerFailed(Worker w) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// 从 workers 中移除 worker
if (w != null)
workers.remove(w);
// 调整 workerCount()
decrementWorkerCount();
// 尝试将线程池状态改变为 TERMINATED
tryTerminate();
} finally {
mainLock.unlock();
}
}
线程池关闭
来看一下线程池的关闭方法:
public void shutdown() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
// 如果线程池状态还没有达到SHUTDOWN, 将线程池状态改为 SHUTDOWN
advanceRunState(SHUTDOWN);
// 中断空闲的工作者线程
interruptIdleWorkers();
// 钩子
onShutdown(); // hook for ScheduledThreadPoolExecutor
} finally {
mainLock.unlock();
}
// 尝试转换状态到终止
tryTerminate();
}
public List<Runnable> shutdownNow() {
List<Runnable> tasks;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
// 如果线程池状态还没有达到 STOP, 将线程池状态改为 STOP
advanceRunState(STOP);
// 中断所有 worker
interruptWorkers();
// 获取任务队列中的任务, 并将这些任务从任务队列中删除
tasks = drainQueue();
} finally {
mainLock.unlock();
}
// 尝试转换状态到终止
tryTerminate();
return tasks;
}
public boolean awaitTermination(long timeout, TimeUnit unit)
throws InterruptedException {
long nanos = unit.toNanos(timeout);
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// 等待线程池终止或超时
while (runStateLessThan(ctl.get(), TERMINATED)) {
if (nanos <= 0L)
// 剩余时间小于 0 , 超时
return false;
nanos = termination.awaitNanos(nanos);
}
return true;
} finally {
mainLock.unlock();
}
}
tryTerminate() 方法中, 如果成功将线程池状态转换到了 TERMINATED, 将会termination.signalAll() 来唤醒等待线程池终结的线程:
final void tryTerminate() {
for (;;) {
int c = ctl.get();
if (isRunning(c) ||
runStateAtLeast(c, TIDYING) ||
(runStateLessThan(c, STOP) && ! workQueue.isEmpty()))
// 状态不需要改变 (处于 RUNNING 状态 或 已经处于 TIDYING 状态 或 (还没到达 STOP 状态, 并且 workQueue 不为空))
return;
if (workerCountOf(c) != 0) { // Eligible to terminate
// 中断一个空闲的 worker, 以传播关闭状态到工作线程
interruptIdleWorkers(ONLY_ONE);
return;
}
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
if (ctl.compareAndSet(c, ctlOf(TIDYING, 0))) {
// 将状态成功更新为 TIDYING
try {
// 默认实现没有做任何事情
terminated();
} finally {
// 将线程池状态更新为 TERMINATED
ctl.set(ctlOf(TERMINATED, 0));
// 唤醒等待终结的线程
termination.signalAll();
}
return;
}
} finally {
mainLock.unlock();
}
// else retry on failed CAS
}
}
ThreadPoolExecutor 源码阅读的更多相关文章
- 【详解】ThreadPoolExecutor源码阅读(三)
系列目录 [详解]ThreadPoolExecutor源码阅读(一) [详解]ThreadPoolExecutor源码阅读(二) [详解]ThreadPoolExecutor源码阅读(三) 线程数量的 ...
- 【详解】ThreadPoolExecutor源码阅读(二)
系列目录 [详解]ThreadPoolExecutor源码阅读(一) [详解]ThreadPoolExecutor源码阅读(二) [详解]ThreadPoolExecutor源码阅读(三) AQS在W ...
- 【详解】ThreadPoolExecutor源码阅读(一)
系列目录 [详解]ThreadPoolExecutor源码阅读(一) [详解]ThreadPoolExecutor源码阅读(二) [详解]ThreadPoolExecutor源码阅读(三) 工作原理简 ...
- 转载:ThreadPoolExecutor 源码阅读
前言 之前研究了一下如何使用ScheduledThreadPoolExecutor动态创建定时任务(Springboot定时任务原理及如何动态创建定时任务),简单了解了ScheduledThreadP ...
- 《java.util.concurrent 包源码阅读》13 线程池系列之ThreadPoolExecutor 第三部分
这一部分来说说线程池如何进行状态控制,即线程池的开启和关闭. 先来说说线程池的开启,这部分来看ThreadPoolExecutor构造方法: public ThreadPoolExecutor(int ...
- 《java.util.concurrent 包源码阅读》 结束语
<java.util.concurrent 包源码阅读>系列文章已经全部写完了.开始的几篇文章是根据自己的读书笔记整理出来的(当时只阅读了部分的源代码),后面的大部分都是一边读源代码,一边 ...
- [源码阅读] 阿里SOFA服务注册中心MetaServer(1)
[源码阅读] 阿里SOFA服务注册中心MetaServer(1) 目录 [源码阅读] 阿里SOFA服务注册中心MetaServer(1) 0x00 摘要 0x01 服务注册中心 1.1 服务注册中心简 ...
- [源码阅读] 阿里SOFA服务注册中心MetaServer(2)
[源码阅读] 阿里SOFA服务注册中心MetaServer(2) 目录 [源码阅读] 阿里SOFA服务注册中心MetaServer(2) 0x00 摘要 0x01 MetaServer 注册 1.1 ...
- [源码阅读] 阿里SOFA服务注册中心MetaServer(3)
[源码阅读] 阿里SOFA服务注册中心MetaServer(3) 目录 [源码阅读] 阿里SOFA服务注册中心MetaServer(3) 0x00 摘要 0x01 概念 1.1 分布式一致性 1.2 ...
随机推荐
- 2018-2019-2 网络对抗技术 20165320 Exp5 MSF基础应用
2018-2019-2 网络对抗技术 20165320 Exp5 MSF基础应用 一.实践内容 本实践目标是掌握metasploit的基本应用方式,重点常用的三种攻击方式的思路.具体需要完成: 一个主 ...
- PHP - CentOS下开发运行环境搭建(Apache+PHP+MySQL+FTP)
本文介绍如何在 Linux下搭建一个 PHP 环境.其中 Linux 系统使用是 CentOS 7.3,部署在阿里云服务器上. 1,连接登录服务器 拿到服务器的 ip.初始密码以后.我们先通过远程 ...
- SVM实例及Matlab代码
******************************************************** ***数据集下载地址 :http://pan.baidu.com/s/1geb8CQf ...
- 【Python】zip文件密码破解
掌握基础语法后,尝试使用python的zipfile模块练手. zipfile是Python里用来做zip格式编码的压缩和解压缩的. 这里将大体的思路分解成四段代码,逐一完善功能: 第一段代码:解压z ...
- Nginx软件优化【转】
转自 Nginx软件优化 - 惨绿少年 - 博客园 Nginx软件优化 - 惨绿少年 - 博客园 https://www.cnblogs.com/clsn/p/8484559.html 1.1 Ngi ...
- 在分析nginx日志时常用命令总结【转】
1. 利用grep ,wc命令统计某个请求或字符串出现的次数 比如统计GET /app/kevinContent接口在某天的调用次数,则可以使用如下命令: [root@Fastdfs_storage_ ...
- python3爬虫中文乱码之请求头‘Accept-Encoding’:br 的问题
当用python3做爬虫的时候,一些网站为了防爬虫会设置一些检查机制,这时我们就需要添加请求头,伪装成浏览器正常访问. header的内容在浏览器的开发者工具中便可看到,将这些信息添加到我们的爬虫代码 ...
- Python poll IO多路复用
一.poll介绍 poll本质上和select没有区别,只是没有了最大连接数(linux上默认1024个)的限制,原因是它基于链表存储的. 本人的另一篇博客讲了 python select : ht ...
- freerradius 错误:pap: WARNING: No "known good" password found for the user
具体错误如下: 1) # Executing section authorize from file /usr/local/etc/raddb/sites-enabled/default(1) a ...
- PYTHON-UDP
1.TCP 和 UDP 发送数据时的流程 ***** 解释 为何TCP是可靠的 是因为发送数据后必须收到确认包 2. UDP的模板代码 ***** 1.UDP协议: (数据报协议) 特点: 无连接 优 ...