【Hadoop 分布式部署 八:分布式协作框架Zookeeper架构功能讲解 及本地模式安装部署和命令使用 】
What is Zookeeper
是一个开源的分布式的,为分布式应用提供协作服务的Apache项目
提供一个简单的原语集合,以便与分布式应用可以在他之上构建更高层次的同步服务
设计非常简单易于编程,他使用的是类似于文件系统那样的树形数据结构。
目的就是将分布式服务不再需要有协作冲突而另外实现协作服务
从设计模式角度来看,是一个基于观察者设计模式的分布式服务管理框架。
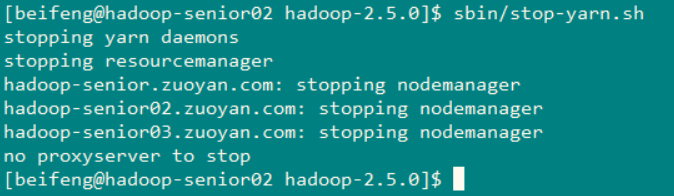
先将节点上的服务都停止掉
在节点一上执行命令:sbin/stop-dfs.sh

然后在节点二上执行命令: sbin/stop-yarn.sh
将zookeeper 文件上传上去

然后将zookeeper 的权限设置为可执行

将zookeeper 解压到 /opt/moudles 下 使用命令:tar -zxvf zookeeper-3.4.5.tar.gz -C /opt/modules/
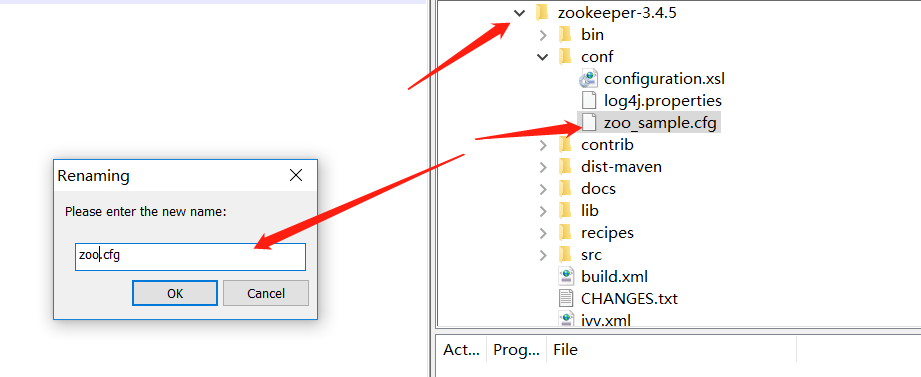
下一步 修改zookeeper的配置文件
修改配置文件名称
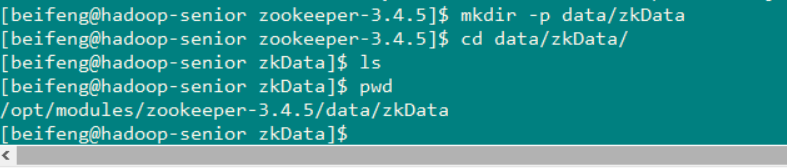
在zookeeper的目录中创建文件夹
复制这个路径,然后到配置文件中去配置 就修改这个,其余的都不需要修改
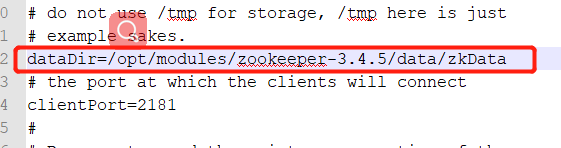
配置完成后启动 zookeeper ,在zookeeper的目录下,执行命令 : bin/zkServer.sh start

查看zookeeper的状态 可以看到是单机节点

进入客户端的命令: bin/zkCli.sh

创建一个节点的命令:
create /test "test-data"

查看节点命令 ls /

获取节点 命令 get /test (数据下面的 是这个节点的属性信息)

删除节点: rmr /test

到此,本地的安装就已经结束了!
【Hadoop 分布式部署 八:分布式协作框架Zookeeper架构功能讲解 及本地模式安装部署和命令使用 】的更多相关文章
- 【Hadoop 分布式部署 九:分布式协作框架Zookeeper架构 分布式安装部署 】
1.首先将运行在本地上的 zookeeper 给停止掉 2.到/opt/softwares 目录下 将 zookeeper解压到 /opt/app 目录下 命令: tar -zxvf zoo ...
- Zookeeper本地模式安装
本地模式安装部署 1.安装前准备 (1)安装Jdk (2)拷贝Zookeeper安装包到Linux系统下 (3)解压到指定目录 tar -zxvf zookeeper-3.4.10.tar.gz -C ...
- hadoop记录-[Flink]Flink三种运行模式安装部署以及实现WordCount(转载)
[Flink]Flink三种运行模式安装部署以及实现WordCount 前言 Flink三种运行方式:Local.Standalone.On Yarn.成功部署后分别用Scala和Java实现word ...
- Flink本地环境安装部署
本次主要介绍flink1.5.1版本的本地环境安装部署,该版本要求jdk版本1.8以上. 下载flink安装包:http://archive.apache.org/dist/flink/flink-1 ...
- 初学者值得拥有【Hadoop伪分布式模式安装部署】
目录 1.了解单机模式与伪分布模式有何区别 2.安装好单机模式的Hadoop 3.修改Hadoop配置文件---五个核心配置文件 (1)hadoop-env.sh 1.到hadoop目录中 2.修 ...
- Hadoop完全分布式模式安装部署
在Linux上搭建Hadoop系列:1.Hadoop环境搭建流程图2.搭建Hadoop单机模式3.搭建Hadoop伪分布式模式4.搭建Hadoop完全分布式模式 注:此教程皆是以范例讲述的,当然你可以 ...
- 【Spark】Spark的Standalone模式安装部署
Spark执行模式 Spark 有非常多种模式,最简单就是单机本地模式,还有单机伪分布式模式,复杂的则执行在集群中,眼下能非常好的执行在 Yarn和 Mesos 中.当然 Spark 还有自带的 St ...
- spark运行模式之二:Spark的Standalone模式安装部署
Spark运行模式 Spark 有很多种模式,最简单就是单机本地模式,还有单机伪分布式模式,复杂的则运行在集群中,目前能很好的运行在 Yarn和 Mesos 中,当然 Spark 还有自带的 Stan ...
- spark运行模式之一:Spark的local模式安装部署
Spark运行模式 Spark 有很多种模式,最简单就是单机本地模式,还有单机伪分布式模式,复杂的则运行在集群中,目前能很好的运行在 Yarn和 Mesos 中,当然 Spark 还有自带的 Stan ...
随机推荐
- Robot - 1. robot framework环境搭建
Fom:https://www.cnblogs.com/puresoul/p/3854963.html 一. robot framework环境搭建: 官网:http://robotframework ...
- uva 11183 Teen Girl Squad
题意: 有一个女孩,需要打电话让所有的人知道一个消息,消息可以被每一个知道消息的人传递. 打电话的关系是单向的,每一次电话需要一定的花费. 求出打电话最少的花费或者判断不可能让所有人知道消息. 思路: ...
- 20155228 实验三 敏捷开发与XP实践
20155228 实验三 敏捷开发与XP实践 实验内容 1. XP基础 2. XP核心实践 3. 相关工具 实验要求 1.没有Linux基础的同学建议先学习<Linux基础入门(新版)>& ...
- 设计模式之Observer(观察者)(转)
Java深入到一定程度,就不可避免的碰到设计模式(design pattern)这一概念,了解设计模式,将使自己对java中的接口或抽象类应用有更深的理解.设计模式在java的中型系统中应用广泛,遵循 ...
- いろはちゃんとマス目 / Iroha and a Grid (组合数学)
题目链接:http://abc042.contest.atcoder.jp/tasks/arc058_b Time limit : 2sec / Memory limit : 256MB Score ...
- python docopt模块详解
python docopt模块详解 docopt 本质上是在 Python 中引入了一种针对命令行参数的形式语言,在代码的最开头使用 """ ""&q ...
- Autel Maxisys MS908CV Description
The new Autel MaxiSys CV Heavy Duty Diagnostic is built on the powerful MaxiSys 908 platform and pro ...
- ubunta apt install error
ubuntu系统: 用apt-get命令安装一些软件包时,总报错:E:could not get lock /var/lib/dpkg/lock -open等 出现这个问题的原因可能是有另外一个程序正 ...
- Spring Boot 实现RESTful webservice服务端实例
1.Spring Boot configurations application.yml spring: profiles: active: dev mvc: favicon: enabled: fa ...
- Golang错误处理函数defer、panic、recover、errors.New介绍
在默认情况下,当发生错误(panic)后,程序就会终止运行 如果发生错误后,可以捕获错误,并通知管理人员(邮件或者短信),程序还可以继续运行,这当然无可厚非 errors.New("错误信息 ...