memory consistency
目前的计算机系统中,都是shared memory结构,提供统一的控制接口给软件,
shared memory结构中,为了memory correctness,可以将问题分为:memory consistency,和memory coherency。
为了memory consistency的正确性,是需要program的编写者的操作,主要描述对一块memory的不同的load,store之间的顺序。
而memory coherency,则对software是完全透明的,主要为了多cache在系统中的表现像单cache一样。
memory consistency实现之后,coherency一定是保证的,但是coherency保证之后,consistency不一定可以保证。
为了避免memory consistency,需要保证对同一address的,多个core或者多个线程store/load都是 in-ordered,为不同的address,无所谓的。
发生memory consistency,可能是store-store,load-load,load-store。store-load之间的out-of order。
memory consistency model是一个系统性的问题,会直接影响程序(多线程,多进程)编写。
涉及到,processor的设计,memory system的设计,interconnect的设计,
compiler的优化,programming language的使用。
关于consistency model最简单的描述是,读操作需要返回最新写入memory的值。
memory reorder只有在软件实现lock-free 编程的时候,才可能影响运算结果。
memory ordering模型,是并发程序设计的基础。主要的内容:
1) atomic VS reorder
与cpu bus总线对齐的read/write,都是atomic的,如果非对齐,比如32bit的bus总线,访问64bit的数据,
映射到str,ldr会变为两条指令,在单核多线程和多核的运行环境下,可能会出现half-read,half-write的
情况。
RMW,read-modified-write,都是非atomic的。
为此很多的微处理器,提出了atomic的指令,一条指令实现较复杂的功能,从而实现atomic性;
CMPXCHG(compare-and-exchange),XCHG等。这些atomic指令,只能保证单核多线程的原子性,在多核情况下,还是需要加lock;
reorder,的主要考虑是performance,在BP失败或者cache miss的时候,都需要reorder,主要是STR或者LDR指令的乱序。
reorder的原则是硬件隐藏细节,使得数据的load,store,按single thread的顺序正确执行。
reorder的类型包括,
Compiler Reordering,程序编译期间,
Barrier指令保证前后的语句不会被reorder。
compiler memory barrier instruction:GNU编译器,asm volatile("":::"memory")
__asm__ __volatile(""::::"memory")
intel ecc compiler
__memory_barrier()
Microsoft Visual C++
——ReadWriteBarrier()
CPU并感知不到compiler memory barrier的存在,而且实现compiler的memory barrier之后,
reorder还是可能在CPU memory reorder中发生的。
CPU memory Ordering,程序执行期间:memory reorder,特指processor通过load,store指令,
system bus访问system memory期间的乱序。
memory reorder的类型可以分为四类:
LoadLoad,
LoadStore,
StoreLoad,
StoreStore,
CPU memory order的实现,对软件来说,是透明的。
CPU会进行reorder的原因 ,可能是指令的BP失败,cache miss等,先将load,store放在load buffer,store buffer,invalid buffer中。
2) Memory Barrier
cpu的memory barrier,相比较于compiler来说,是一条真正的指令,针对四种memory reorder,目前有四种memory barrier的类型:
LoadLoad Barrier
LoadStore Barrier
StoreLoad Barrier
StoreStore Barrier
具体的barrier指令有三种:
Store Barrier(Write Barrier),Store Barrier前后的store操作,必须是按顺序执行的,对load没有影响。
Load Barrier(Read Barrier),Load Barrier前后的load操作,必须是按顺序执行的,对write没有影响。
Full Barrier(Load+Store Barrier),Full Barrier两边的任何操作,均不可以交换顺序。

CPU的memory model根据processor,tool chain的不同,有很多的选择。
主要的CPU memory models:
Programming Order------------------Strong Memory Model
Sequential Consistency(SC模型)
Strict Consistency
Data Dependency Order------------Weaker Memory Model

强弱内存模型的主要区别点:但一个CPU核执行一连串的写操作时,其他的CPU核看到这些值的改变顺序是否与其顺序一致。
目前很难找到一个在硬件层面保证SC模型,所以当用上语言编程时,SC为成为一个重要的软件内存模型,
Java5之后,用violation声明共享变量,
C++11中,使用默认的顺序约束memory_order_seq_cst,做原子操作,
使用这些技术之后,编译器会限制编译乱序,并且插入特定CPU的memory barrier指令,来保证原子操作。
最具典型的consistency model被称为SC (sequential consistency)。
sequential model在实现中的architecture:
1)系统中不带cache的SC model,如果是多核,需要自己实现一个switch:
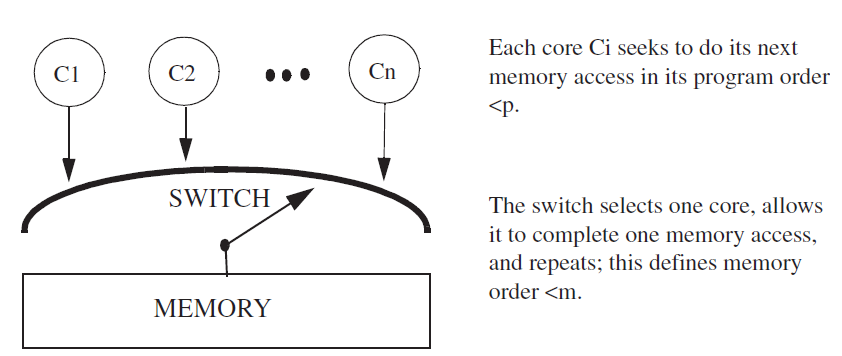
2)系统中带有cache:多核情况下,cache coherence protocol充当了switch的角色,可以看做一个黑盒:
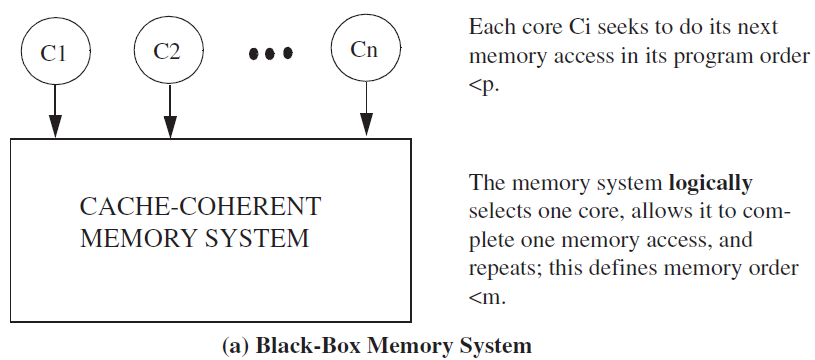
总结:
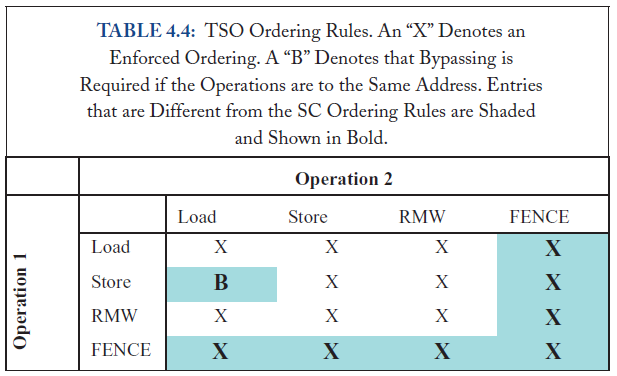
load-load、store-store,是必须按program order来的。
load-store、store-load,是必须按program order来的。
sequential consistency必须保证:1)program order,processor必须保证前一memory访问结束,才能开始新的memory访问;
在cache的系统中,必须保证所有的cache都被invalid或者update,收到相应的ack信号。
2)write atomicity,对同一地址的写操作,必须是serialized,同样必须是收到invalid和update的ack信号。
这些要求,针对任何load-store对。
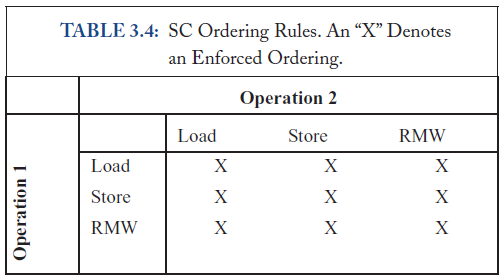
SC Ordering Rule总结,表示的是单核的要求,RMW表示原子操作。
在硬件优化与SC模型中会出现的问题:
1) 没有cache的情况下,
1.带write buffer的结构,read bypass的操作下,后边的读操作可能会越过写操作。
2.重叠写,overlapping write,多个不同地址的同时写,后边的写操作,较前边的写操作,先完成。
3.非阻塞读,nonblocking reads,多个不同地址的同时读,后边的读操作,较前边的读操作,先完成。
2) 有cache的情况下,
1.必须实现cache coherency协议。
2.检查写的ack信号。一个core必须等到另一个core的写ack信号之后,再发送下一个写操作。
3.保证write atomicity,cache的本质是将一个值的改变,传播给多个处理器的缓存,本身是非原子性的,所以有两个要求;
1.针对同一地址的写操作被串行化(serialized)
2.对一个新写的值的读操作,必须是所有其他的core,都返回ack的情况。
与特定的硬件优化结合起来的时候,SC模型的保证是有代价的。
其他的memory model,较SC,有两方面的改变:
1) 放松对程序次序的要求,只适用于不同地址的load,store操作;
2) 放松对原子性的要求,一些模型允许读操作在“一个写操作未对所有处理器可见的情况下”执行。只适用于有buffer的体系结构。
X86多使用的是一种称为TSO(Total Store Order)的memory consistency model, 与SC model相比较。放开了store-load的顺序要求。
只是放开了程序次序中的这一小部分。
TSO中,每个processor都加入了一个write buffer,所以可以memory order上来看store比load晚,但是指令上仍然是load先执行的。
类似于cache中的write-back的policy。
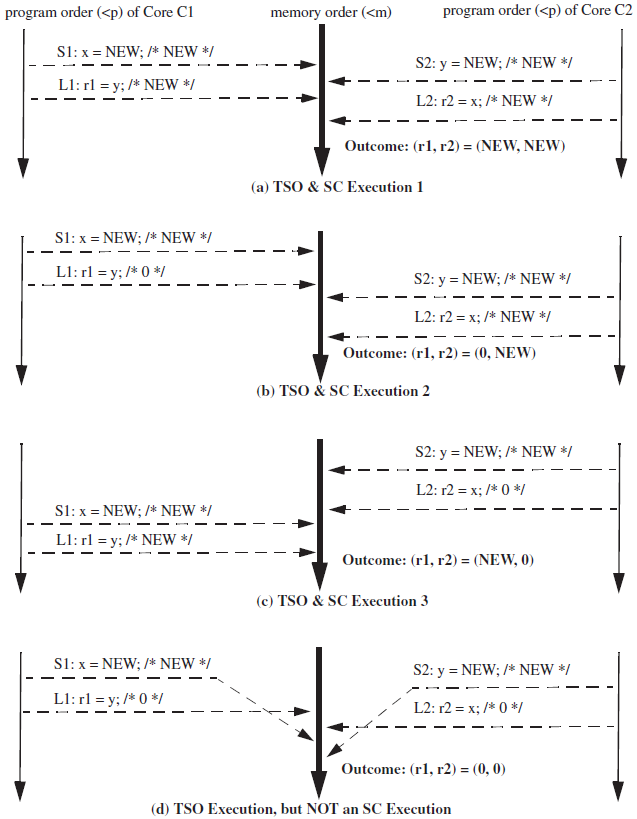
TSO model的实现:
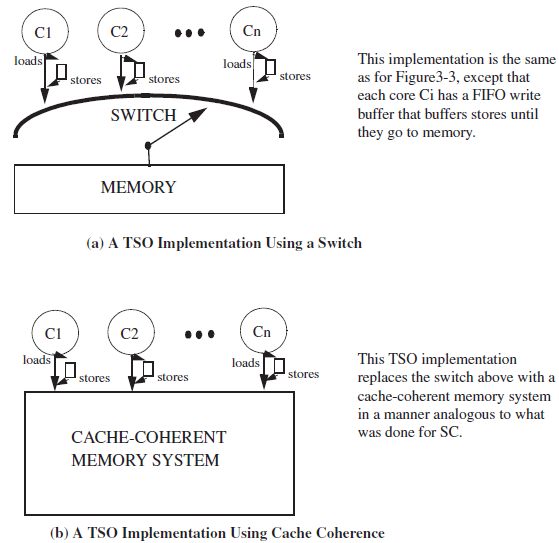
如果programmer要求,store-load必须按顺序执行,则需要在store之后,加入fence命令。
fence命令只能挡住本processor的执行,对其他的processor起不到作用。
但是原子操作可以,用exclusive的访问,其他的processor访问不到该数据。
TSO Ordering Rules要求,针对单核的情况:
Relaxed memory models:
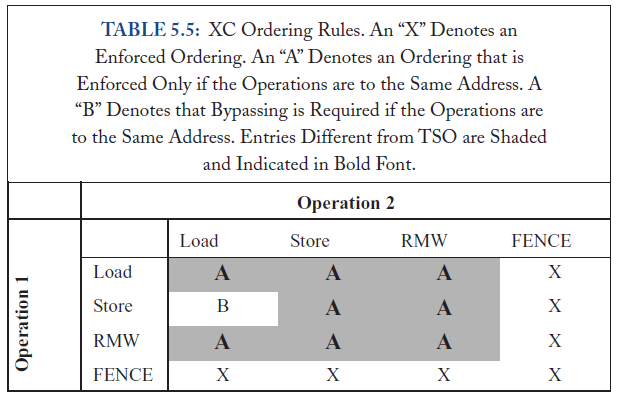
relaxed model既有对program order方面的优化也有write atomicity方面的优化。
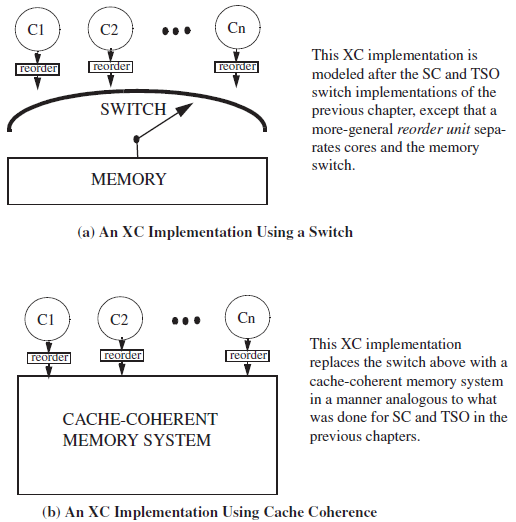
ARM和PowerPC,多使用relax model,一个example model,XC model,
XC model的ordering Rule,单核情况:
XCmodel的实现:
程序设计时的memory相关的指令:
1) violatile,变量修饰词,表示cpu不会每次都从cache中拿值,而是每次都必须访问main-memory。一般计算机中的外设相关的变量都
需要设定为violatile,防止被compiler优化。但是并不能用于构建原子操作。
2) 原子操作,分为blocking和non-blocking两种,类似于AXI中的lock trans和exclusive trans。
3) 互斥锁,mutex,在多进程,多线程间使用,拿不到mutex时,进程或线程被休眠。blocking
底层使用lock transaction。
4) 自旋锁(spinlock),在等待共有资源有效的过程中,会一直等待,线程、进程不会被休眠。non-blocking
5) semaphore,等待一定数量的共有资源,直接在程序中声明。blocking
底层使用lock transaction。
6) read-modify-write,使用strex或者ldrex汇编指令,对读改写进行包装。non-blocking
7) compare-and-swap,等同于LL(load-link)、SC(store-conditional)指令,底层也是调用strex和ldrex指令,non-blocking
8) 其他的atomic operation,test-and-set,fetch-and-add,compare-and-swap指令。
在exclusive trans设计中,会有两个monitor,一个local monitor(只是monitor该cpu,一般放在cpu core内),
一个global monitor(monitor整个sys,一般放在主的interconnect中)
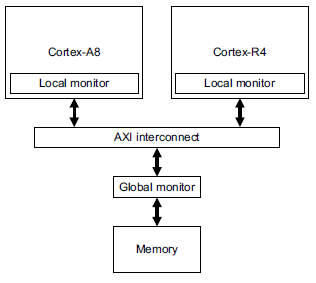
bus trans的memory type如果是Non-Shareable的,此时的exclusive只检查local monitor,然后可能会直接返回Exok
如果是Shareable的,此时的exclusive,会检查local monitor和global monitor,如果有violation,会直接返回Exok。
在有cache的系统中,并且此时的memory type是cacheable的,exclusive的访问需要和local minitor,global monitor,SCU共同决定sync的结果。
这些model在实现中,都是依托于指令集来实现的,arm和intel都有提供相应的原子操作指令。
在程序代码编写的时候,也可以自己控制,通过memory fence命令,来保证多核多线程对共享变量的访问。
在单核系统中,也会出现memory consistent的问题,因为目前的cpu都是超标量,多线程,乱序执行的,所以program order并不能
反映到executed order。
之上是单核memory reorder的问题,之后写一些多核数据一致性的问题。
软件中数据的同步问题,
1.在单核多线程的情况下,可以通过disable所有中断,包括cpu内核调度,来达到目的,只在sync var被处理之后,再放开中断。
这样可以达到sync的目的,但是在增加了interrupt的latency。
2.在多核多线程的情况下,需要保证多核之间的同步,arm增加了自己的指令,来锁住bus,v6架构之前是swp指令,v6架构之后是ldrex指令。
下边讨论一下指令加锁的应用:
X86的很多指令,都可以在前边加lock,来保证原子性,加lock的指令,会保证对当前访问的内存的互斥性。
在单核处理器系统中,能够在单条指令中完成的操作都可以被认为是原子操作。因为中断和线程切换都只能在指令与指令之间;
但是在多核处理器中,由于多个core同时独立的运行,即使能单条指令就可以完成的操作,也会受到其他core的干扰,
导致memory consistent出现问题,所以需要多核之间的同步。
X86的lock指令,做的便是多核之间访问同一memory的同步,类似的有arm中的strex和ldrex,
arm中的strex和ldrex,是armv6之后才引进来的,之前使用的是swp,swpb指令,等效于lock bus+memory swap。
缺点有两点:
1.但是直接锁死bus会导致,其他的core不能访问bus,性能受到影响,
2.由于这个指令既有str又有ldr,多以执行时间会比较长,如果这时有中断,就必须等待这条指令执行结束,这样增加了中断的latency。
所以无论是多核还是单核,swp指令都没有目前的ldrex和strex方便。
参考文档,Shared Memory Consistency Models A Tutorial.pdf
a primer on memory consistency and coherence.pdf
Weak vs. Strong Memory Models 网页
浅谈Memory Reordering 网页
CPU cache and Memory Ordering 并发程序设计入门
https://www.kernel.org/doc/Documentation/memory-barriers.txt
memory consistency的更多相关文章
- [翻译]内存一致性模型 --- memory consistency model
I will just give the analogy with which I understand memory consistency models (or memory models, fo ...
- memory CPU cache books
http://www.amazon.com/Consistency-Coherence-Synthesis-Lectures-Architecture/dp/1608455645/ref=pd_sim ...
- Memory Ordering in Modern Microprocessors
Linux has supported a large number of SMP systems based on a variety of CPUs since the 2.0 kernel. L ...
- [Paper翻译]Scalable Lock-Free Dynamic Memory Allocation
原文: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.87.3870&rep=rep1&type=pdf Abstr ...
- memory barrier 内存屏障 编译器导致的乱序
小结: 1. 很多时候,编译器和 CPU 引起内存乱序访问不会带来什么问题,但一些特殊情况下,程序逻辑的正确性依赖于内存访问顺序,这时候内存乱序访问会带来逻辑上的错误, 2. https://gith ...
- C++ atomic 和 memory ordering 笔记
如果不使用任何同步机制(例如 mutex 或 atomic),在多线程中读写同一个变量,那么,程序的结果是难以预料的.简单来说,编译器以及 CPU 的一些行为,会影响到程序的执行结果: 即使是简单的语 ...
- Java多线程系列--“JUC锁”10之 CyclicBarrier原理和示例
概要 本章介绍JUC包中的CyclicBarrier锁.内容包括:CyclicBarrier简介CyclicBarrier数据结构CyclicBarrier源码分析(基于JDK1.7.0_40)Cyc ...
- jdk8中java.util.concurrent包分析
并发框架分类 1. Executor相关类 Interfaces. Executor is a simple standardized interface for defining custom th ...
- 误用的volatile
在嵌入式编程中,有对某地址重复读取两次的操作,如地址映射IO.但如果编译器直接处理p[0] = *a; p[1] = *a这种操作时,往往会忽略后一个,而直接使用前一个已计算的结果.这是有问题的,因为 ...
随机推荐
- mysql学习【第3篇】:使用DQL查询数据
狂神声明 : 文章均为自己的学习笔记 , 转载一定注明出处 ; 编辑不易 , 防君子不防小人~共勉 ! mysql学习[第3篇]:使用DQL查询数据 DQL语言 DQL( Data Query Lan ...
- 内部排序->交换排序->起泡排序
文字描述 首先将第一个记录的关键字和第二个记录的关键字进行比较,若为逆序(L.r[1].key>L.r[2].key),则将两个记录交换位置,然后比较第二个记录和第三个记录的关键字.依次类推,直 ...
- AVD启动报错:Running an x86 based Android Virtual Device (AVD) is 10x faster
1.cmd窗口中输入emulator -avd test 启动AVD时报错: Running an x86 based Android Virtual Device (AVD) is 10x fast ...
- idea设置文件的编码格式为utf-8
file ---> settings... 然后 editor ---> file encoding 然后设置path和encoding什么的.
- 函数datetime
datetime import datetime.datetime print(datetime.now()) #2019-03-20 11:35:25.(471359)毫秒 # 时间对象 f = d ...
- 从网络上筛选"流媒体"的相关文章
1> 雷神的博客专栏https://blog.csdn.net/leixiaohua1020 [总结]FFMPEG视音频编解码零基础学习方法https://blog.csdn.net/leixi ...
- fopen 的使用
1, fopen() 的使用,在linux环境下,我们可以使用man fopen查看使用说明: #include <stdio.h> FILE *fopen(const char *pat ...
- 01.jupyter环境安装
jupyter notebook环境安装 一.什么是Jupyter Notebook? 1. 简介 Jupyter Notebook是基于网页的用于交互计算的应用程序.其可被应用于全过程计算:开发.文 ...
- Advising controllers with the @ControllerAdvice annotation
The @ControllerAdvice annotation is a component annotation allowing implementation classes to be aut ...
- 7-通用GPIO
7-通用GPIO 1.I/O 端口控制寄存器 每个 GPIO 有 4 个 32 位存储器映射的控制寄存器(GPIOx_MODER.GPIOx_OTYPER.GPIOx_OSPEEDR.GPIOx_PU ...