【转】浅谈分布式服务协调技术 Zookeeper
非常好介绍Zookeeper的文章,
|
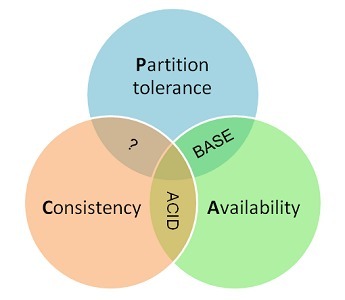
Google的三篇论文影响了很多很多人,也影响了很多很多系统。这三篇论文一直是分布式领域传阅的经典。根据MapReduce,于是我们有了Hadoop;根据GFS,于是我们有了HDFS;根据BigTable,于是我们有了HBase。而在这三篇论文里都提及Google的一个Lock Service —— Chubby,哦,于是我们有了Zookeeper。 随着大数据的火热,Hxx们已经变得耳熟能详,现在作为一个开发人员如果都不知道这几个名词出门都好像不好意思跟人打招呼。但实际上对我们这些非大数据开发人员而言,Zookeeper是比Hxx们可能接触到更多的一个基础服务。但是,无奈的是它一直默默的位于二线,从来没有Hxx们那么耀眼。那么到底什么是Zookeeper呢?Zookeeper可以用来干什么?我们将如何使用Zookeeper?Zookeeper又是怎么实现的? 什么是Zookeeper 在Zookeeper的官网上有这么一句话:ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services。 这大概描述了Zookeeper主要是一个分布式服务协调框架,实现同步服务,配置维护和命名服务等分布式应用。是一个高性能的分布式数据一致性解决方案。 通俗地讲,ZooKeeper是动物园管理员,它是拿来管大象 Hadoop、鲸鱼 HBase、Kafka等的管理员。 Zookeeper和CAP的关系 作为一个分布式系统,分区容错性是一个必须要考虑的关键点。一个分布式系统一旦丧失了分区容错性,也就表示放弃了扩展性。因为在分布式系统中,网络故障是经常出现的,一旦出现在这种问题就会导致整个系统不可用是绝对不能容忍的。所以,大部分分布式系统都会在保证分区容错性的前提下在一致性和可用性之间做权衡。
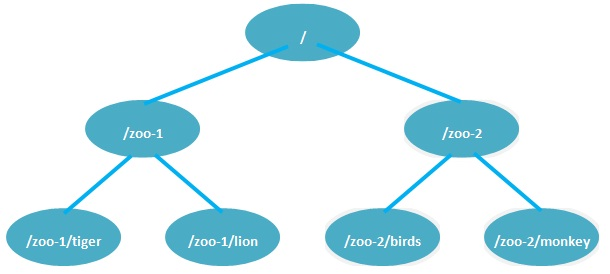
ZooKeeper是个CP(一致性+分区容错性)的,即任何时刻对ZooKeeper的访问请求能得到一致的数据结果,同时系统对网络分割具备容错性;但是它不能保证每次服务请求的可用性。也就是在极端环境下,ZooKeeper可能会丢弃一些请求,消费者程序需要重新请求才能获得结果。 ZooKeeper是分布式协调服务,它的职责是保证数据在其管辖下的所有服务之间保持同步、一致;所以就不难理解为什么ZooKeeper被设计成CP而不是AP特性的了。而且, 作为ZooKeeper的核心实现算法Zab,就是解决了分布式系统下数据如何在多个服务之间保持同步问题的。 Zookeeper节点特性及节点属性分析 Zookeeper提供基于类似于文件系统的目录节点树方式的数据存储,但是Zookeeper并不是用来专门存储数据的,它的作用主要是用来维护和监控你存储的数据的状态变化。通过监控这些数据状态的变化,从而可以达到基于数据的集群管理。 数据模型 与Linux文件系统不同的是,Linux文件系统有目录和文件的区别,而Zookeeper的数据节点称为ZNode,ZNode是Zookeeper中数据的最小单元,每个ZNode都可以保存数据,同时还可以挂载子节点,因此构成了一个层次化的命名空间,称为树。
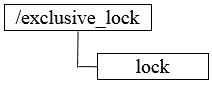
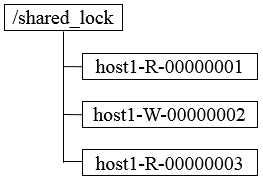
Zookeeper中ZNode的节点创建时候是可以指定类型的,主要有下面几种类型。
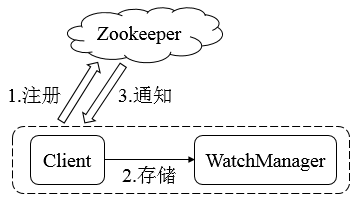
Watcher数据变更通知 Zookeeper使用Watcher机制实现分布式数据的发布/订阅功能。
Zookeeper的Watcher机制主要包括客户端线程、客户端WatcherManager、Zookeeper服务器三部分。客户端在向Zookeeper服务器注册的同时,会将Watcher对象存储在客户端的WatcherManager当中。当Zookeeper服务器触发Watcher事件后,会向客户端发送通知,客户端线程从WatcherManager中取出对应的Watcher对象来执行回调逻辑。 ACL保障数据的安全 Zookeeper内部存储了分布式系统运行时状态的元数据,这些元数据会直接影响基于Zookeeper进行构造的分布式系统的运行状态,如何保障系统中数据的安全,从而避免因误操作而带来的数据随意变更而导致的数据库异常十分重要,Zookeeper提供了一套完善的ACL权限控制机制来保障数据的安全。 我们可以从三个方面来理解ACL机制:权限模式 Scheme、授权对象 ID、权限 Permission,通常使用"scheme:id:permission"来标识一个有效的ACL信息。 内存数据 Zookeeper的数据模型是树结构,在内存数据库中,存储了整棵树的内容,包括所有的节点路径、节点数据、ACL信息,Zookeeper会定时将这个数据存储到磁盘上。
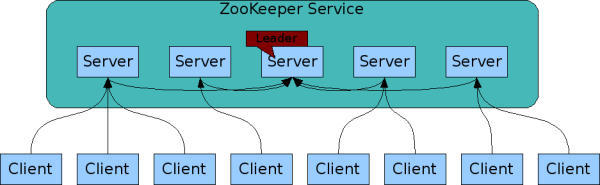
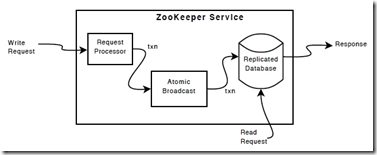
Zookeeper的实现原理分析 1. Zookeeper Service网络结构 Zookeeper的工作集群可以简单分成两类,一个是Leader,唯一一个,其余的都是follower,如何确定Leader是通过内部选举确定的。
2. Zookeeper读写数据
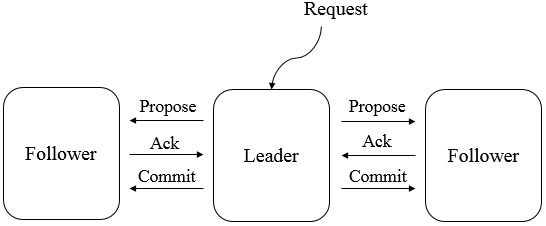
3. Zookeeper工作原理 Zab协议 Zookeeper的核心是广播,这个机制保证了各个Server之间的同步。实现这个机制的协议叫做Zab协议。 Zab(ZooKeeper Atomic Broadcast)原子消息广播协议作为数据一致性的核心算法,Zab协议是专为Zookeeper设计的支持崩溃恢复原子消息广播算法。 Zab协议核心如下: 所有的事务请求必须一个全局唯一的服务器(Leader)来协调处理,集群其余的服务器称为follower服务器。Leader服务器负责将一个客户端请求转化为事务提议(Proposal),并将该proposal分发给集群所有的follower服务器。之后Leader服务器需要等待所有的follower服务器的反馈,一旦超过了半数的follower服务器进行了正确反馈后,那么Leader服务器就会再次向所有的follower服务器分发commit消息,要求其将前一个proposal进行提交。 Zab模式 Zab协议包括两种基本的模式:崩溃恢复和消息广播。
Zookeeper只允许唯一的一个Leader服务器来进行事务请求的处理,Leader服务器在接收到客户端的事务请求后,会生成对应的事务提议并发起一轮广播协议,而如果集群中的其他机器收到客户端的事务请求后,那么这些非Leader服务器会首先将这个事务请求转发给Leader服务器。 消息广播
Zab协议的消息广播过程使用是一个原子广播协议,类似一个2PC提交过程。具体的:
Zab协议简化了2PC事务提交:
崩溃恢复 上面我们讲了Zab协议在正常情况下的消息广播过程,那么一旦Leader服务器出现崩溃或者与过半的follower服务器失去联系,就进入崩溃恢复模式。 恢复模式需要重新选举出一个新的Leader,让所有的Server都恢复到一个正确的状态。 Zookeeper实践,共享锁,Leader选举 分布式锁用于控制分布式系统之间同步访问共享资源的一种方式,可以保证不同系统访问一个或一组资源时的一致性,主要分为排它锁和共享锁。
推荐文章:基于Zk实现分布式锁 Leader选举 Leader选举是保证分布式数据一致性的关键所在。当Zookeeper集群中的一台服务器出现以下两种情况之一时,需要进入Leader选举。
Zookeeper在3.4.0版本后只保留了TCP版本的 FastLeaderElection 选举算法。当一台机器进入Leader选举时,当前集群可能会处于以下两种状态:
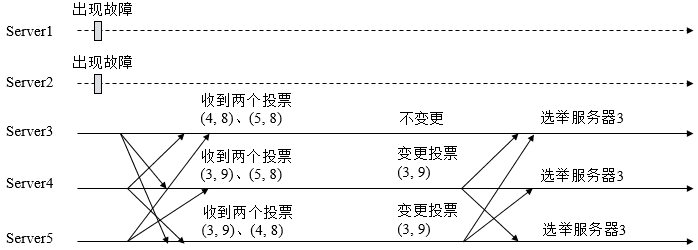
对于集群中已经存在Leader而言,此种情况一般都是某台机器启动得较晚,在其启动之前,集群已经在正常工作,对这种情况,该机器试图去选举Leader时,会被告知当前服务器的Leader信息,对于该机器而言,仅仅需要和Leader机器建立起连接,并进行状态同步即可。 而在集群中不存在Leader情况下则会相对复杂,其步骤如下: (1) 第一次投票。无论哪种导致进行Leader选举,集群的所有机器都处于试图选举出一个Leader的状态,即LOOKING状态,LOOKING机器会向所有其他机器发送消息,该消息称为投票。投票中包含了SID(服务器的唯一标识)和ZXID(事务ID),(SID, ZXID)形式来标识一次投票信息。假定Zookeeper由5台机器组成,SID分别为1、2、3、4、5,ZXID分别为9、9、9、8、8,并且此时SID为2的机器是Leader机器,某一时刻,1、2所在机器出现故障,因此集群开始进行Leader选举。在第一次投票时,每台机器都会将自己作为投票对象,于是SID为3、4、5的机器投票情况分别为(3, 9),(4, 8), (5, 8)。 (2) 变更投票。每台机器发出投票后,也会收到其他机器的投票,每台机器会根据一定规则来处理收到的其他机器的投票,并以此来决定是否需要变更自己的投票,这个规则也是整个Leader选举算法的核心所在,其中术语描述如下
每次对收到的投票的处理,都是对(vote_sid, vote_zxid)和(self_sid, self_zxid)对比的过程。
(3) 确定Leader。经过第二轮投票后,集群中的每台机器都会再次接收到其他机器的投票,然后开始统计投票,如果一台机器收到了超过半数的相同投票,那么这个投票对应的SID机器即为Leader。此时Server3将成为Leader。 由上面规则可知,通常那台服务器上的数据越新(ZXID会越大),其成为Leader的可能性越大,也就越能够保证数据的恢复。如果ZXID相同,则SID越大机会越大。 「 浅谈大规模分布式系统中那些技术点」系列文章: Reference http://www.cnblogs.com/yuyijq/p/3391945.html http://www.cnblogs.com/kms1989/p/5504505.html http://www.hollischuang.com/archives/1275 http://www.jianshu.com/p/bf32e44d3113 http://www.jianshu.com/p/4654bdbb8792 http://www.jianshu.com/p/8fba732af0cd http://www.jianshu.com/p/6af7362701c5 http://www.jianshu.com/p/6929446d3b10 http://www.jianshu.com/p/5dce97c9ba85 http://www.cnblogs.com/sunddenly/articles/4073157.html http://www.dczou.com/viemall/454.html 转载请并标注: “本文转载自 linkedkeeper.com (文/张松然)” |
【转】浅谈分布式服务协调技术 Zookeeper的更多相关文章
- 分布式服务协调技术zookeeper笔记
本文主要学习ZooKeeper的体系结构.节点类型.节点监听.常用命令等基础知识,最后还学习了ZooKeeper的高可用集群的搭建与测试.希望能给想快速掌握ZooKeeper的同学有所帮助. ZooK ...
- 浅谈分布式消息技术 Kafka(转)
一只神秘的程序猿. Kafka的基本介绍 Kafka是最初由Linkedin公司开发,是一个分布式.分区的.多副本的.多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可 ...
- 浅谈分布式消息技术 Kafka
Kafka的基本介绍Kafka是最初由Linkedin公司开发,是一个分布式.分区的.多副本的.多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/ngin ...
- 搞懂分布式技术21:浅谈分布式消息技术 Kafka
搞懂分布式技术21:浅谈分布式消息技术 Kafka 浅谈分布式消息技术 Kafka 本文主要介绍了这几部分内容: 1基本介绍和架构概览 2kafka事务传输的特点 3kafka的消息存储格式:topi ...
- 个人学习分布式专题(二)分布式服务治理之分布式协调技术Zookeeper
分布式协调技术Zookeeper 2.1 zookeeper集群安装部署(略) 2.2 zookeeper的基本原理,数据模型 2.3 zookeeper Java api的使用 2.4 zookee ...
- Zookeeper分布式服务协调组件
1.简介 Zookeeper是一个分布式服务协调组件,是Hadoop.Hbase.Kafka的重要组件,它是一个为分布式应用提供一致性服务的组件. Zookeeper的目标就是封装好复杂易出错的服 ...
- 浅谈surging服务引擎中的rabbitmq组件和容器化部署
1.前言 上个星期完成了surging 的0.9.0.1 更新工作,此版本通过nuget下载引擎组件,下载后,无需通过代码build集成,引擎会通过Sidecar模式自动扫描装配异构组件来构建服务引擎 ...
- 浅谈微服务架构与服务治理的Eureka和Dubbo
前言 本来计划周五+周末三天自驾游,谁知人算不如天算,周六恰逢台风来袭,湖州附近的景点全部关停,不得已只能周五玩完之后,于周六踩着台风的边缘逃回上海.周末过得如此艰难,这次就聊点务虚的话题,一是浅谈微 ...
- 分布式服务:Dubbo+Zookeeper+Proxy+Restful 分布式架构
分布式 分布式服务:Dubbo+Zookeeper+Proxy+Restful 分布式消息中间件:KafKa+Flume+Zookeeper 分布式缓存:Redis 分布式文件:FastDFS ...
随机推荐
- Java基础:整型数组(int[]、Integer[])排序
Windows 10家庭中文版,java version "1.8.0_152",Eclipse Oxygen.1a Release (4.7.1a), 参考链接:http://w ...
- 每天一个linux命令:scp命令
scp是secure copy的简写,用于在Linux下进行远程拷贝文件的命令,和它类似的命令有cp,不过cp只是在本机进行拷贝不能跨服务器,而且scp传输是加密的.可能会稍微影响一下速度.当你服务器 ...
- WPF设置对象隐藏、不可用
设置隐藏时,这里将控件分为两类, 1.普通的按钮.下拉框等,根据控件的Name进行查找,设置IsEnabled为false; 2.ListView中嵌套控件,直接将列隐藏,根据GridViewColu ...
- mpVue小程序全栈开发
1.微信小程序,mpVue和wepy的对比 2. 3.es6中关于数组的一些方法 <script> let arr = [,,,] // 遍历 arr.forEach(v => { ...
- css怎么让页面上的内容不能被选中
body{ -webkit-user-select:none; -moz-user-select:none; -ms-user-select:none; user-se ...
- 石头剪刀布三局两胜(平局重来break用法)
- 一张纸,折多少次和珠穆拉峰一样高(for if 和break)
- html标签之Object标签详解
定义和用法 定义一个嵌入的对象.请使用此元素向您的 XHTML 页面添加多媒体.此元素允许您规定插入 HTML 文档中的对象的数据和参数,以及可用来显示和操作数据的代码. <object> ...
- Django整合Keras报错:ValueError: Tensor Tensor("Placeholder:0", shape=(3, 3, 1, 32), dtype=float32) is not an element of this graph.解决方法
本人在写Django RESful API时,碰到一个难题,老出现,整合Keras,报如下错误:很纠结,探索找资料近一个星期,皇天不负有心人,解决了 Internal Server Error: /p ...
- (String中)正则表达式使用如下
package zhengze;/* * 正则表达式 */public class StringTestZhengZe { public static void main(String[] args) ...