DataFrame.nunique(),DataFrame.count()
1. nunique()
DataFrame.nunique(axis = 0,dropna = True )
功能:计算请求轴上的不同观察结果
参数:
- axis : {0或'index',1或'columns'},默认为0。0或'index'用于行方式,1或'列'用于列方式。
- dropna : bool,默认为True,不要在计数中包含NaN。
返回: Series
>>> df = pd.DataFrame({'A': [1, 2, 3], 'B': [1, 1, 1]})
>>> df.nunique()
A 3
B 1
dtype: int64
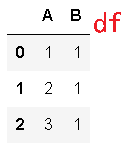
>>> df.nunique(axis=1)
0 1
1 2
2 2
dtype: int64
2. count()
DataFrame.count(axis = 0,level = None,numeric_only = False )
功能:计算每列或每行的非NA单元格。
None,NaN,NaT和numpy.inf都被视作NA
参数:
- axis : {0或'index',1或'columns'},默认为0(行),如果为每列生成0或'索引'计数。如果为每行生成1或'列'计数。
- level : int或str,可选,如果轴是MultiIndex(分层),则沿特定级别计数,折叠到DataFrame中。一个STR指定级别名称。
- numeric_only : boolean,默认为False,仅包含float,int或boolean数据。
返回:Series或DataFrame对于每个列/行,非NA / null条目的数量。如果指定了level,则返回DataFrame。
从字典构造DataFrame
>>> df = pd.DataFrame({"Person":
... ["John", "Myla", "Lewis", "John", "Myla"],
... "Age": [24., np.nan, 21., 33, 26],
... "Single": [False, True, True, True, False]})
>>> df
Person Age Single
0 John 24.0 False
1 Myla NaN True
2 Lewis 21.0 True
3 John 33.0 True
4 Myla 26.0 False
注意不计数的NA值
>>> df.count()
Person 5
Age 4
Single 5
dtype: int64
每行计数:
>>> df.count(axis='columns')
0 3
1 2
2 3
3 3
4 3
dtype: int64
计算MultiIndex的一个级别:
>>> df.set_index(["Person", "Single"]).count(level="Person")
Age
Person
John 2
Lewis 1
Myla 1
参考文献:
DataFrame.nunique(),DataFrame.count()的更多相关文章
- spark RDD,DataFrame,DataSet 介绍
弹性分布式数据集(Resilient Distributed Dataset,RDD) RDD是Spark一开始就提供的主要API,从根本上来说,一个RDD就是你的数据的一个不可变的分布式元素集合,在 ...
- (原)怎样解决python dataframe loc,iloc循环处理速度很慢的问题
怎样解决python dataframe loc,iloc循环处理速度很慢的问题 1.问题说明 最近用DataFrame做大数据 处理,发现处理速度特别慢,追究原因,发现是循环处理时,loc,iloc ...
- Pandas之Dataframe叠加,排序,统计,重新设置索引
Pandas之Dataframe索引,排序,统计,重新设置索引 一:叠加 import pandas as pd a_list = [df1,df2,df3] add_data = pd.concat ...
- pandas 的数据结构(Series, DataFrame)
Pandas 讲解 Python Data Analysis Library 或 pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的. Pandas 纳入了大量库和一些标 ...
- 在使用R做数据挖掘时,最常用的数据结构莫过于dataframe了,下面列出几种常见的dataframe的操作方法
原网址 http://blog.sina.com.cn/s/blog_6bb07f83010152z0.html 在使用R做数据挖掘时,最常用的数据结构莫过于dataframe了,下面列出几种常见的d ...
- 5 pandas模块,DataFrame类
DataFrame DataFrame是一个[表格型]的数据结构,可以看作是[由Series组成的字典](共用同一个索引).DataFrame由一定顺序排列的多列数据组 ...
- 怎样解决python dataframe loc,iloc循环处理速度很慢的问题
怎样解决python dataframe loc,iloc循环处理速度很慢的问题 1.问题说明 最近用DataFrame做大数据 处理,发现处理速度特别慢,追究原因,发现是循环处理时,loc,iloc ...
- python,pandas, DataFrame数据获取方式
一.创建DataFrame df=pd.DataFrame(np.arange(,).reshape(,)) my_col=dict(zip(range(),['A','B','C'])) df.re ...
- [Spark][Python][DataFrame][RDD]从DataFrame得到RDD的例子
[Spark][Python][DataFrame][RDD]从DataFrame得到RDD的例子 $ hdfs dfs -cat people.json {"name":&quo ...
随机推荐
- MySQL的JDBC驱动源码解析
原文: MySQL的JDBC驱动源码解析 大家都知道JDBC是Java访问数据库的一套规范,具体访问数据库的细节有各个数据库厂商自己实现 Java数据库连接(JDBC)由一组用 Java 编程语言 ...
- tar命令参数详解
命令总览:tar [-]A --catenate --concatenate | c --create | d --diff --compare | r --append | t --list | u ...
- 存储json数据的编码问题
在使用json.dumps时要注意一个问题 >>> import json >>> print json.dumps('中国') "\u4e2d\u5 ...
- 下载文件的协议:HTTP、FTP、P2P
本篇学习笔记以HTTP.FTP.P2P叙述与网上下载文件有关的协议 需要掌握的要点: 下载一个文件可以使用 HTTP 或 FTP,这两种都是集中下载的方式,而 P2P 则换了一种思路,采取非中心化下载 ...
- Rodrigues Formula
https://en.wikipedia.org/wiki/Rodrigues%27_formula https://en.wikipedia.org/wiki/Rodrigues%27_rotati ...
- 【实战解析】基于HBase的大数据存储在京东的应用场景
京东技术 https://mp.weixin.qq.com/s?src=11×tamp=1551342955&ver=1455&signature=0hYp8OsxY ...
- Chap4:区块链的应用技术[《区块链中文词典》维京&甲子]
- [adminitrative][archlinux][setfont] 设置console的字体大小
电脑的分辨率高了之后,用命令行进入的时候,完全看不清楚,是否容易导致眼瞎. 第一步便把字体调大就成了很必要的操作. 使用一个命令能马上生效: setfont 使用配置文件 /etc/vconsole. ...
- [daily][archlinux] 本地字符乱码, 无法显示中文
一: 突然有一天,Konsole里边看见的中文文件名的文件,就变成了乱码.thunderbird存到本地的附件,文件名也变成了乱码. 在X下查看locale,内容如下: 手动设置了之后也不对. 但是在 ...
- python中dict的fromkeys用法
fromkeys是创造一个新的字典.就是事先造好一个空字典和一个列表,fromkeys会接收两个参数,第一个参数为从外部传入的可迭代对象,会将循环取出元素作为字典的key值,另外一个参数是字典的val ...