Linux下RocketMQ环境的配置
RocketMQ是一款分布式消息系统,最初是由阿里巴巴消息中间件团队研发并大规模应用于生产系统,满足线上海量堆积的需求,在去年捐赠给Apache开源基金会,并列为孵化项目,今年成功的正式成为了apache顶级项目;早期阿里曾经基于ActiveMQ研发的消息系统,随着业务消息的规模增大,瓶颈逐渐明显,后来也考虑过Kafka,但是因为在低延迟和高可靠性方面没有选择,最后才自主研发了RocketMQ,各方面的性能都比目前已有的消息队列要好,RocketMQ和kafka在原理和概念上都非常相似,所以也经常被拿来对比;RocketMQ默认采用长轮询的拉模式,单机支持千万级别的消息堆积,可以非常好的应用在海量消息系统中,下面主要叙述一下RocketMQ的安装配置过程和一些相关的概念,因为rocketmq能够很方便的扩展到分布式集群,所以单机情况下也可以很好的说明,所以下面操作都在一台服务器上执行
RocketMQ官网地址为:http://rocketmq.apache.org/ ,个人感觉RocketMQ的官方文档写的非常清晰,简单易懂,通过文档左侧下方可以找到下载链接,下载编译好的二进制版本,最新版本是4.1.0孵化版,下载安装包为:rocketmq-all-4.1.0-incubating-bin-release.zip,下载之后准备安装
首先解压安装包然后放到自己要安装的位置:
unzip rocketmq-all-4.1.-incubating-bin-release.zip
mv rocketmq-all-4.1.-incubating /monchickey/
cd /monchickey/rocketmq-all-4.1.-incubating/
我这里安装到了/monchickey目录下面,首先可以按照官网上面的Quick Start走一遍,看看大致流程,rocketmq集群包括nameserver和broker,nameserver负责管理集群的列表信息,broker是真正作为消息承载和提供数据吞吐服务的,首先执行下面命令启动nameserver:
nohup ./bin/mqnamesrv &
执行之后再敲一次确认键回到命令行,然后查看日志,默认位置在:~/logs/rocketmqlogs/namesrv.log中,如果看到下面内容则表示启动成功:
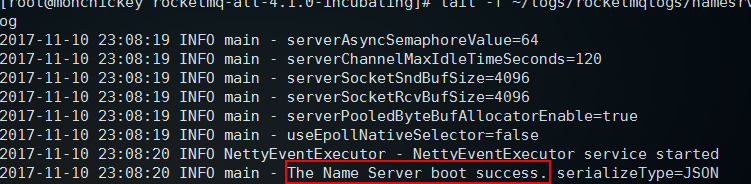
然后执行 jps 可以看到NamesrvStartup,就是nameserver进程了
然后需要启动broker,命令如下:
nohup ./bin/mqbroker -n monchickey: &
这里-n指定nameserver地址,nameserver服务端口为9876,,这里如果在配置比较低的计算机或者虚拟机上很容易瞬间启动失败,这时候如果前台启动可能会看到下面这样的内容:
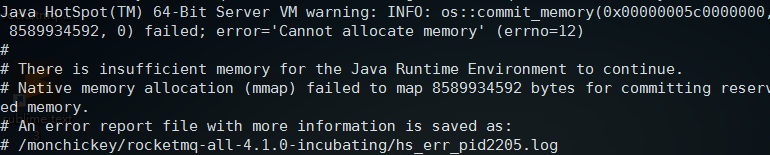
那么这种情况很明显就是内存不足导致的申请失败,RocketMQ默认配置是比较好的,这样可以直接应用于生产环境,所以如果机器内存较小,可以手动调整JVM的配置,可以先编辑bin/mqbroker会看到最后还是调用了bin/runbroker.sh,这里打开bin/runbroker.sh,找到jvm启动配置如下:
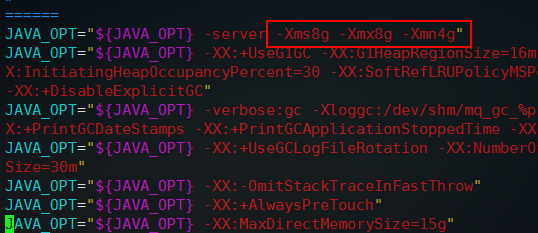
这里broker堆内存最大值和初始值都为8G,年轻代大小为4G,因为是测试环境所以xms和xmx都配置为4g,xmn配置为512m即可,配置完成后再次执行上面的命令启动即可,启动成功后日志位置同样是在家目录下,同样使用jps查看会看到BrokerStartup就是broker的进程
对于nameserver和broker日志位置都可以手动配置,具体配置文件就是conf下的logback_broker.xml和logback_namesrv.xml

现在可以跑一个简单的示例看一下了,现在可以打开两个窗口,一个查看生产者,一个查看消费者,首先两个shell窗口都需要执行命令: export NAMESRV_ADDR=monchickey: 导入一下nameserver变量,然后第一个窗口执行下面命令启动生产者实例发送消息:
bin/tools.sh org.apache.rocketmq.example.quickstart.Producer
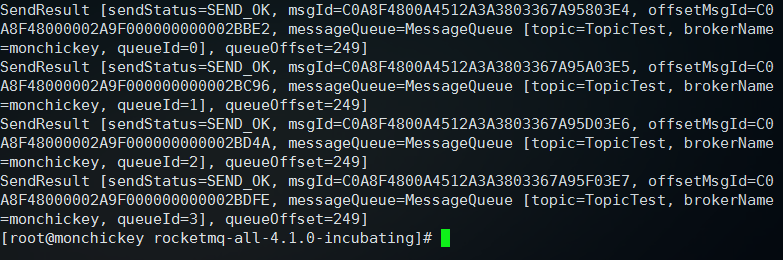
可以看到发送成功的消息返回:
然后另一个窗口可以启动消费者实例消费:
bin/tools.sh org.apache.rocketmq.example.quickstart.Consumer
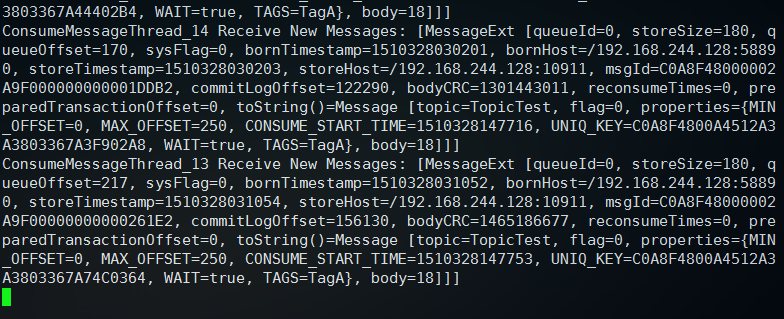
可以看到消费消息如下:
到这里其实最简单的RocketMQ环境就配置好了,可以看到基本上没有什么配置需要修改的,停止nameserver和broker可以分别执行下面命令:
bin/mqshutdown namesrv
bin/mqshutdown namesrv
这样进程就可以结束了,下面来详细说一下生产环境应该怎么部署
对于kafka集群,其中有一个节点为master,并且我们不用干预,master是kafka自动选择出来的,但是rocketMQ的master和slave都需要手动指定,所以kafka是broker中出来master和slave,而rocketmq中是多个master和slave,一块构建成为broker,两个过程基本上是相反的;另外在生产环境中nameserver建议至少设置2个,这样一个挂了集群不受影响
对于rocketmq集群,一个broker-name一般设置一个master以及一个或多个slave,一个集群可以设置多个broker-name,在rocketmq的conf目录下可以看到如下几个常用的配置:
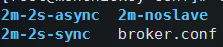
其中2m表示2个master,2s表示2个slave,sync表示同步刷盘,asyna表示异步刷盘和replication,默认情况下rocketmq是async模式的,这样性能会非常好,但是如果需要保证消息的可靠性,建议使用sync的方式,
另外多说一下,kafka的topic里面有分区和副本的概念,使用之前都是根据数据量手动创建,对于rocketmq也一样,需要手动创建topic,rocketmq的topic中有队列(queue)的概念,也就是说一个节点上面可以有多个队列,这样能非常大的提高并发性,而kafka最多只能是一个分区一个进程消费,这样并发性限制非常大,并且单机分区数量不能过多,超过64个分区就出现明显的不稳定,但是rocketmq单机支持上万队列,所以并发性能非常好;类比一下,rocketmq中一个broker-name其实就相当于kafka broker中的一个partition,而rocketmq每一个slave就相当于kafka中的一个replication,这种情况,所以rocketmq的特点相当于单个partition支持多队列,大致的原理图如下:
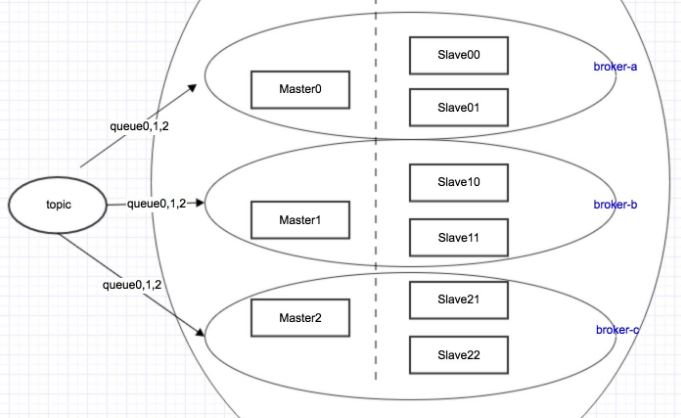
默认情况下,一个topic的队列数是8,当然在实际应用中可以设置的更大,知道了前面这些概念,那么在集群中以2m-2s-sync的方式启动一个集群就简单了,假设2台nameserver主机分别为rocket1和rocket2,则步骤如下:
1). 分别启动两个nameserver
rocket1 > nohup ./bin/mqnamesrv &
rocket2 > nohup ./bin/mqnamesrv &
2). 然后分别在剩下主机中分别启动2个master和2个slave:
bin/mqbroker -c ./conf/2m-2s-sync/broker-a.properties -n rocket1:,rocket2:
bin/mqbroker -c ./conf/2m-2s-sync/broker-a-s.properties -n rocket1:,rocket2:
bin/mqbroker -c ./conf/2m-2s-sync/broker-b.properties -n rocket1:,rocket2:
bin/mqbroker -c ./conf/2m-2s-sync/broker-b-s.properties -n rocket1:,rocket2:
这样就集群就启动完毕了,实际生产中最好是一个服务器只运行一个broker实例
然后在单机上也可以启动多个broker master,为了加深对配置的理解下面是具体的步骤:
首先启动nameserver这个和之前一样,但是启动broker不能按照之前那样启动了,因为单机伪集群模式也必须对应集群名称,同样按照集群中的概念来启动,先进入conf目录,可以看到有一个broker.conf,这个是相当于配置的简单模板,另外其他的配置也可以到上面说的2m-2s那些目录中去参考一下,这个broker.conf是不能直接使用的,因为broker启动的时候用-c参数传入配置文件,这里只认识*.properties的配置文件,所以这里应该分别执行:
cp broker.conf broker1.properties
cp broker1.properties broker2.properties
将配置文件复制为2份,先执行 vim broker1.properties 查看第一个配置文件,内容如下:
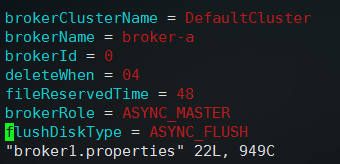
这里第一个是集群名称,一个集群必须配置一个,默认就是DefaultCluster,然后brokerName是broker的名称,master的话brokerId为0,其余的slave依次是1,2,3往后排,然后brokerRole配置表示异步的往slave拷贝,如果是slave节点直接写SLAVE即可,最后一个是刷盘的类型,这样这个配置文件不用动,然后启动第一个broker即可:
nohup bin/mqbroker -c ./conf/broker1.properties -n monchickey: &
然后打开broker2.properties,修改如下:
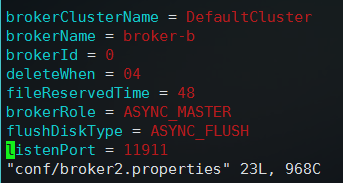
首先是集群名要一致,然后brokerName设置为一个新的broker-b,这个也是master,相当于第二个分区,然后只配置这些启动直接就报端口冲突的失败,因为这是单机环境,而broker默认端口是10911,所以为了避免冲突启动多个broker需要设置个新的端口,当然分布式环境都默认即可,这里添加了一个端口配置为11911,然后启动第二个broker:
nohup bin/mqbroker -c ./conf/broker2.properties -n monchickey: &
这样就启动了第二个进程,此时jps应该可以看到两个broker进程,这就是一个最简单的集群了,另外还有更多配置项这个可以参考官方文档讲的很详细,下面可以使用mqadmin工具执行一些CLI操作,比如直接执行: ./bin/mqadmin 可以看到所有的操作选项,常用的比如:updateTopic - 创建或更新topic,deleteTopic 删除topic,clusterList 列出集群,topicList 列出topic,另外还可以按照时间戳以及id查看消息等,
比如执行: bin/mqadmin clusterList -n monchickey: 查看集群如下:

可以看到只有一个集群2个broker
查看集群状态可以执行: bin/mqadmin brokerStatus -c DefaultCluster -n monchickey:
新建一个默认配置的topic可以执行: bin/mqadmin updateTopic -b monchickey: -n monchickey: -t test
或者执行: bin/mqadmin updateTopic -c DefaultCluster -n monchickey: -t test 这两个命令都可以,也就是说-b broker主机或者-c集群名必须指定一个,
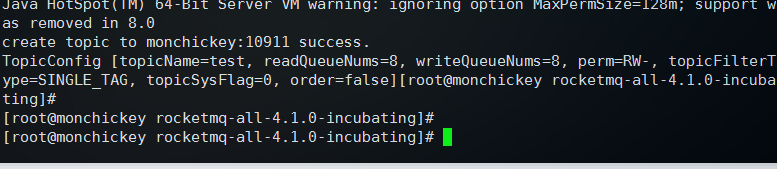
这样一个topic就创建成功了,默认读和写的队列数都是8个,
然后可以执行命令: bin/mqadmin topicList -n monchickey: 查看topic列表:
以及查看test这个topic队列分布的详细信息: bin/mqadmin topicStatus -n monchickey: -t test

可以看到默认情况下队列都被分到broker-a上面了,比如我们要创建更多的队列,那么rocketmq会自动的均衡分布到集群所有的broker中
基本的命令就是上面这些,对于每个命令可以用的时候现查,比如topicStatus这个具体怎么用,可以执行: bin/mqadmin help topicStatus 或者 bin/mqadmin topicStatus -h 查看详细的参数,然后根据需要使用就可以了
好了,关于rocketmq的基本配置使用就先叙述这些,这确实是一个非常好用的消息中间件,值得深入的学习.. 最后感谢花时间阅读,如果有其他内容或问题也欢迎补充,一起交流...
Linux下RocketMQ环境的配置的更多相关文章
- linux下Java环境的配置
linux下Java环境的配置 现在用linux的朋友越来越多了,前几天就有两个朋友问我linux下怎么配置java环境,我想还有很多朋友想了解学习这方面的东西,就写一个完全一点的linux java ...
- linux下jdk环境变量配置深度分析----解决环境变量不生效的问题
1.linux下jdk环境变量配置 是否需要配置环境变量,主要看java -version 显示的版本是否为你期望的版本 1.1 不需要配置环境变量的情况 使用java -version查看,版本显示 ...
- Linux 下android环境的配置
Linux 下android环境的配置 1. JDK下载 http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads- ...
- linux 下java环境的配置
注意:这里选择下载jdk并自行安装,而不是通过源直接安装(apt-get install) 1.下载jkd( http://www.oracle.com/technetwork/java/javase ...
- Linux下java环境变量配置
安装步骤 1.查看当前Linux系统是否安装java rpm -qa | grep java 2.卸载系统中已经存在的openJDK rpm -e --nodeps java--openjdk-1.7 ...
- Linux下Java环境安装配置记录
下载jdk http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html 两种安装方式: 第一 ...
- Linux下JDK环境变量配置
JDK官方下载地址: http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html 我的下载路 ...
- linux下的环境变量配置
方法一: 方法二:
- hadoop搭建杂记:Linux下JDK环境变量的设置(三种配置环境变量的方法)
Linux下JDK环境变量的设置(三种配置环境变量的方法) Linux下JDK环境变量的设置(三种配置环境变量的方法) ①修改/etc/profile文件 如果你的计算机仅仅作为开发使用时推荐使用这种 ...
随机推荐
- liunx rm 命令修改
原文:https://blog.csdn.net/Ace_Shiyuan/article/details/60139791 1.打开一个终端,输入命令:vim ~/.bashrc Linux下修改rm ...
- cf789c
主要是线性时间内求最大连续和 #include<bits/stdc++.h> using namespace std; #define maxn 200005 #define ll lon ...
- hdu3308
区间合并比较模板的题,就是求一个区间的LCIS 线段树维护左最大LCIS,右最大LCIS,区间LCIS 看代码就行 #include<iostream> #include<cstri ...
- JQuery插件jqModal应用详解(十二)
JqModal 是jQuery的一个插件,用来在web浏览器中显示自定义通告,而且它为通用窗口框架奠定了基础. 1. 多模型支持 2. 支持拖拽和重定义大小 3, 支持远程加载窗口内容(ajax和if ...
- JDK1.7+Tomcat6.0+MyEclipse8.6在win7下的安装与配置
http://wenku.baidu.com/view/4f0bef02192e45361066f548.html
- [解决]IP地址非法,请接入联通热点后重新获取
在使用联通chinaunicom WLAN上网时,在弹出的登陆界面后输入账号.密码,点登陆,显示IP地址非法,请接入联通热点后重新获取.现在在其他地方看到解决办法连接chinaunicom,弹出登陆界 ...
- php 代码中的箭头“ ->”是什么意思
类是一个复杂数据类型,这个类型的数据主要有属性.方法两种东西. 属性其实是一些变量,可以存放数据,存放的数据可以是整数.字符串,也可以是数组,甚至是类. 方法实际上是一些函数,用来完成某些功能. 引用 ...
- BZOJ2618 [Cqoi2006]凸多边形 凸包 计算几何
欢迎访问~原文出处——博客园-zhouzhendong 去博客园看该题解 题目传送门 - BZOJ2618 题意概括 给出多个凸包,求面积交. 题解 首先我们考虑两个凸包相交的情况. 例题:HDU16 ...
- java基础面试题-2
第一,谈谈final, finally, finalize的区别. final---修饰符(关键字)如果一个类被声明为final,意味着它不能再派生出新的子类,不能作为父类被继承.因此一个类不能既被 ...
- VSCode tasks.json中的各种替换变量的意思 ${workspaceFolder} ${file} ${fileBasename} ${fileDirname}等
When authoring tasks configurations, it is often useful to have a set of predefined common variables ...