Map 知识整理
首先是HashMap的学习,理解散列的概念以及相关的实现,并且会学习HashMap的源码,理解为什么HashMap的速度如此之快。
声明:参考到的资料在下方列出。
1.《Java编程思想》 作者BruceEckel
2.http://liujiacai.net/blog/2015/09/03/java-hashmap/#%E5%93%88%E5%B8%8C%E8%A1%A8%EF%BC%88hash-table%EF%BC%89
3.提前需要理解红黑树的知识,可以参考文章(写的非常的详细):
http://www.cnblogs.com/skywang12345/p/3245399.html
一、优先级队列(这个知识点跟本文主题关系不大,但是整理记录一下,所以放在这里了)
直接上例子:
import java.util.PriorityQueue;
public class ToDoList extends PriorityQueue<ToDoList.TodoItem>{
/**
*
*/
private static final long serialVersionUID = 1L;
static class TodoItem implements Comparable<TodoItem> {
private char primary;
private int secondary;
private String item;
public TodoItem (String td, char pri, int sec) {
this.item = td;
this.primary = pri;
this.secondary = sec;
}
@Override
public int compareTo(TodoItem arg) {
if (primary > arg.primary) {
return +1;
}
if (primary == arg.primary) {
if (secondary > arg.secondary) {
return +1;
} else if (secondary == arg.secondary){
return 0;
}
}
return -1;
}
public String toString() {
return Character.toString(primary) + secondary + ": " + item;
}
}
public void add(String td, char pri, int sec) {
super.add(new TodoItem(td, pri, sec));
}
public static void main(String[] args) {
ToDoList toDoList = new ToDoList();
toDoList.add("Empty trash", 'C', 4);
toDoList.add("Feed dog", 'A', 2);
toDoList.add("Mow lawn", 'B', 7);
toDoList.add("Water lawn", 'A', 1);
while (!toDoList.isEmpty()) {
System.out.println(toDoList.remove());
}
}
}
我们可以看到,各项是如何按照我们给定的顺序进行排列的。
二、理解Map
Map的实现类有很多:
HashMap:(结构组成:数组+链表+红黑树)无序
TreeMap:基于红黑树的实现,使用红黑树的好处是能够使得树具有不错的平衡性。同时它是有序的,有序(但是按默认顺充,不能指定)
LinkedHashMap:有序的,它是Hash表和链表的实现,并且依靠着双向链表保证了迭代顺序是插入的顺序。
ConcurrentHashMap(一种线程安全的Map,不涉及同步加锁)、无序 .etc.
最常用的是HashMap,它的性能非常棒。至于如何棒,棒到什么程度,慢慢听我说。
性能是映射表的一个重要问题。我们使用散列码,可以代替缓慢的线性搜索,来提高HashMap的速度。散列码是相对唯一的,用以代表对象的int值(因为hashCode()是Object的方法,所以任何对象都可以生成散列码)。那么什么是散列码呢?在Map中,是通过散列来查找另一个对象的。它将键的信息保存在数组里(因为存储、查找元素最快的数据结构是数组),而数组的下角标就是hashCode()生成的散列码。数组的元素里存储的是键值得list。(为什么是list呢?因为数组的大小是不可变的,当Map存储的量很大时,key的数量肯定会超过数组的范围,因此用的list)。之后,取得list后,遍历其中的元素,用equal()进行比较,最后得到我们的key。
总结查询一个值的过程。首先,计算散列码,然后使用散列码查询数组,之后,对数组中保存的list遍历,用equals()方法进行线程的查询。这就是散列的原理,HashMap如此之快的原因。
使用HashMap存储我们的对象时,必须重写equals()和hasCode().同时有以下几个注意点。
正确的equals()方法必须满足下面5额条件‘:
1.自反性。对于任意x, x.equals(x)一定返回true;
2.对称性。对任意x,y, 如果x.equals(y)返回true,那么,y.equals(x)也返回true;
3.传递性。对任意x,y,z, 如果x.equals(y)返回true,y.equals(z)返回true,那么,x.equals(z)也返回true;
4.一致性。对任意x,y,如果对象中用于等价比较的信息没有改变,那么无论调用x.equals(y)多少次,结果必须一致,全是true,或全是false;
5.对任何不是null的x,x.equlas(null)一定是false。
注意的是,默认的Object.equlas()只是比较对象的地址。
下面说说hashCode的设计。
最重要的因素是:无论何时,对同一个对象调用hashCode()都应该生成同样的值。同时,散列码要速度快,并且有意义。
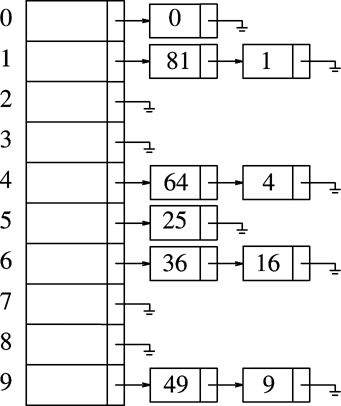
我在这里上个图,大家可以更好的理解散列冲突的解决之道。(
图片出处:http://liujiacai.net/blog/2015/09/03/java-hashmap/#%E5%93%88%E5%B8%8C%E8%A1%A8%EF%BC%88hash-table%EF%BC%89)
左侧竖列为数组,数组角标就是哈希码,每个元素内,是个单向链表,用于解决数据冲突问题。
三、HashMap源码分析
源码版本是JDK1.8
1.初始化
/**
* Constructs an empty <tt>HashMap</tt> with the specified initial
* capacity and load factor.
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
} /**
* Constructs an empty <tt>HashMap</tt> with the specified initial
* capacity and the default load factor (0.75).
*
* @param initialCapacity the initial capacity.
* @throws IllegalArgumentException if the initial capacity is negative.
*/
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
} /**
* Constructs an empty <tt>HashMap</tt> with the default initial capacity
* (16) and the default load factor (0.75).
*/
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
HashMap()的构造方法有三个。
第一个构造方法,需要传入容器大小值和负载因子。这个负载因子代表的是现有的容量size占容器size的比率,当超过这个设定的比率(默认是0.75)时,容器会自动扩容。
第二个构造方法(推荐使用),将容器大小传进去,这样我们根据业务量,给定一个合理大小的容器,可以避免以后,容量的扩容,提高效率。
第三个,不多说了,以前自己经常这么用,现在不了。
2.put()
这个是肯定用到的了,放值,之后取值。
/**
* Associates the specified value with the specified key in this map.
* If the map previously contained a mapping for the key, the old
* value is replaced.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with <tt>key</tt>, or
* <tt>null</tt> if there was no mapping for <tt>key</tt>.
* (A <tt>null</tt> return can also indicate that the map
* previously associated <tt>null</tt> with <tt>key</tt>.)
*/
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
/**
* Computes key.hashCode() and spreads (XORs) higher bits of hash
* to lower. Because the table uses power-of-two masking, sets of
* hashes that vary only in bits above the current mask will
* always collide. (Among known examples are sets of Float keys
* holding consecutive whole numbers in small tables.) So we
* apply a transform that spreads the impact of higher bits
* downward. There is a tradeoff between speed, utility, and
* quality of bit-spreading. Because many common sets of hashes
* are already reasonably distributed (so don't benefit from
* spreading), and because we use trees to handle large sets of
* collisions in bins, we just XOR some shifted bits in the
* cheapest possible way to reduce systematic lossage, as well as
* to incorporate impact of the highest bits that would otherwise
* never be used in index calculations because of table bounds.
*/
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
hash()算法,key不为null时,取【key的哈希值】与【其右移16位的数值】的异或运算。
算法为什么是这样?里面的道理我就不知道了,肯定是经过大量数学运算,得到的这个算法。(我对象总说我是文科的。。。)
/**
* Implements Map.put and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 判断节点数组是否为空,如果为空,初始化节点数组。
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 判断数组中的某个元素是否为空,如果为空,初始化,创建一个新的Node
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
// 判断传进来的key值是否已经存在。通过hash值和key值得两重比较来判断
// 如果key已经存在,存储的Node信息不变
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 如果是TreeNode实例,就将key存入红黑树中保存。
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
// 如果是Node实例,那么将创建一个TreeNode用于管理key的信息。
// 我猜想,如果用单项链表的话,查找key时,还是线性查找,可以通过Red black tree,将性能提升。
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
上面分析,每个分支的目的,至于每一行的具体代码,以及里面算法的实现,无法简短的说清楚,有兴趣的话,可以自己查阅资料。
/**
* Tree version of putVal.
*/
final TreeNode<K,V> putTreeVal(HashMap<K,V> map, Node<K,V>[] tab,
int h, K k, V v) {
Class<?> kc = null;
boolean searched = false;
TreeNode<K,V> root = (parent != null) ? root() : this;
// 往树结构中插入节点
// 遍历节点。代码中是红黑树算法具体代码实现。
for (TreeNode<K,V> p = root;;) {
int dir, ph; K pk;
if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
else if ((pk = p.key) == k || (k != null && k.equals(pk)))
return p;
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0) {
if (!searched) {
TreeNode<K,V> q, ch;
searched = true;
if (((ch = p.left) != null &&
(q = ch.find(h, k, kc)) != null) ||
((ch = p.right) != null &&
(q = ch.find(h, k, kc)) != null))
return q;
}
dir = tieBreakOrder(k, pk);
} TreeNode<K,V> xp = p;
if ((p = (dir <= 0) ? p.left : p.right) == null) {
Node<K,V> xpn = xp.next;
TreeNode<K,V> x = map.newTreeNode(h, k, v, xpn);
if (dir <= 0)
xp.left = x;
else
xp.right = x;
xp.next = x;
x.parent = x.prev = xp;
if (xpn != null)
((TreeNode<K,V>)xpn).prev = x;
moveRootToFront(tab, balanceInsertion(root, x));
return null;
}
}
}
。。。
其他的代码先不分析了。
文章暂时就简要的写到这里吧。有很多细节地方讲解的不到位,只是说明了一个大致的实现思路。里面算法的具体操作实现,以后遇到再做总结。
不足的地方,望前辈指正。
谢过!!!
Map 知识整理的更多相关文章
- Spring Ioc知识整理
Ioc知识整理(一): IoC (Inversion of Control) 控制反转. 1.bean的别名 我们每个bean元素都有一个id属性,用于唯一标识实例化的一个类,其实name属性也可用来 ...
- 【OGG】OGG基础知识整理
[OGG]OGG基础知识整理 一.GoldenGate介绍 GoldenGate软件是一种基于日志的结构化数据复制软件.GoldenGate 能够实现大量交易数据的实时捕捉.变换和投递,实现源数据库与 ...
- ES6知识整理(4)--数组的扩展
最近工作比较忙,基本每天都会加班到很晚.处理一些客户端兼容问题以及提升用户体验的优化.也将近一周没更文了,现在继续es6的学习总结. 上篇回顾 ES6知识整理(三)--函数的扩展 扩展运算符 形式是3 ...
- js事件(Event)知识整理
事件(Event)知识整理,本文由网上资料整理而来,需要的朋友可以参考下 鼠标事件 鼠标移动到目标元素上的那一刻,首先触发mouseover 之后如果光标继续在元素上移动,则不断触发mousemo ...
- Kali Linux渗透基础知识整理(四):维持访问
Kali Linux渗透基础知识整理系列文章回顾 维持访问 在获得了目标系统的访问权之后,攻击者需要进一步维持这一访问权限.使用木马程序.后门程序和rootkit来达到这一目的.维持访问是一种艺术形式 ...
- Kali Linux渗透基础知识整理(二)漏洞扫描
Kali Linux渗透基础知识整理系列文章回顾 漏洞扫描 网络流量 Nmap Hping3 Nessus whatweb DirBuster joomscan WPScan 网络流量 网络流量就是网 ...
- wifi基础知识整理
转自 :http://blog.chinaunix.net/uid-9525959-id-3326047.html WIFI基本知识整理 这里对wifi的802.11协议中比较常见的知识做一个基本的总 ...
- 数据库知识整理<一>
关系型数据库知识整理: 一,关系型数据库管理系统简介: 1.1使用数据库的原因: 降低存储数据的冗余度 提高数据的一致性 可以建立数据库所遵循的标准 储存数据可以共享 便于维护数据的完整性 能够实现数 ...
- 【转载】UML类图知识整理
原文:UML类图知识整理 UML类图 UML,进阶必备专业技能,看不懂UML就会看不懂那些优秀的资料. 这里简单整理 类之间的关系 泛化关系(generalization) 泛化(generalize ...
随机推荐
- learning scala read from file
scala读文件: example: scala> import scala.io.Sourceimport scala.io.Source scala> var inputFile ...
- RabbitMQ 均衡调度(公平分发机制)
均衡调度是针对Consumer来说的.现在有两个Consumer请求同一个队列的消息.RabbitMQ会将序号为奇数的消息发给第一个Consumer,会将序号为偶数的消息发送给第二个Consumer. ...
- Cracking The Coding Interview 2.2
#include <iostream> #include <string> using namespace std; class linklist { private: cla ...
- SQL-11 获取所有员工当前的manager,如果当前的manager是自己的话结果不显示
题目描述 获取所有员工当前的manager,如果当前的manager是自己的话结果不显示,当前表示to_date='9999-01-01'.结果第一列给出当前员工的emp_no,第二列给出其manag ...
- 自定义String
// ShStringNew.cpp : 定义控制台应用程序的入口点. // #include "stdafx.h" #include<iostream> #inclu ...
- JavaWeb基础-Session和Cookie
JSP状态管理 http的无状态性,服务器不会记得发送请求的浏览器是哪一个 保存用户状态的两大机制:session和cookie Cookie:是web服务器保存在客户端的一系列文本信息 作用:对特定 ...
- <Spark><Programming><Key/Value Pairs><RDD>
Working with key/value Pairs Motivation Pair RDDs are a useful building block in many programs, as t ...
- day 60 pyMySQL 的安装及其 增删改查的应用
一 pyMySQL 的安装 1 在pyCharm 中安装pyMySQL 这个模块取决能否顺利链接到MySQL 2 可以在 cod 中 添加 pip install pyMySQL 3 在cmd 中 ...
- 初识linux------用户和用户组
事先说明 本Linux的版本为Ubuntu. 为避免一些初学者由于权限问题特此事先说明,在非root权限下时,所有的代码加sudo:如下 (1)不在root权限 sudo useradd -m 用户名 ...
- ios 手机验证码用户注册(倒计时15秒)
// // ViewController.m // register手机验证码注册 // // Created by zzqqrr on 17/8/28. // Copyright (c) 2017年 ...