redis持久化机制与过期策略
RDB的持久化策略
(快照方式,默认持久化方式): 按照规则定时将内存中的数据同步到磁盘,它有以下4个触发场景。
1. 自己配置的快照规则 vim /redis/bin/ redis.conf;按照save <seconds> <changes>这个规则自己添加或修改规则。
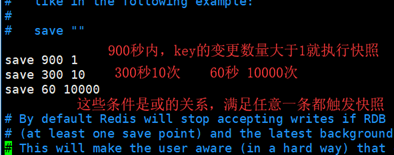
2. save或者bgsave命令
save:将内存的数据同步到磁盘中,这个操作会阻塞客户端的请求(不建议用,太耗时了)。
bgsave:在后台异步执行快照操作,这个操作不会阻塞客户端的请求。
3. 执行flushall清除内存的所有数据时,只要save <seconds> <changes>规则不为空,就会执行快照。
4. 执行复制的时候(集群中 )
快照的实现原理与优缺点:
redis使用fork函数复制出一份当前进程的副本(子进程);父进程继续处理客户端指令,子进程开始将内存的数据写入硬盘中的临时文件,写入完成后就会替换之前的旧文件。优点:1. 多进程处理,性能最快。缺点:1. 若子进程数据未写完而redis异常退出,就会丢失最后一次快照以后更改的所有数据; 2. 如果数据集比较大的时候,fork可以能比较耗时,造成服务器在一段时间内停止处理客户端的请求。
AOF的持久化策略
开启AOF持久化:vim /redis/bin/ redis.conf 将appendonly默认值no改为yes; 重启后执行对数据的变更命令, 会在bin目录下生成对应的.aof文件, aof文件中会记录所有的操作命令!
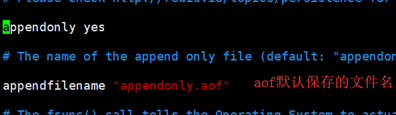
AOF优化:
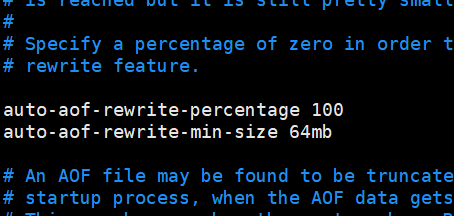
auto-aof-rewrite-percentage 100 表示当前aof文件大小超过上一次aof文件大小的百分之多少的时候会进行重写。如果之前没有重写过,以启动时aof文件大小为准
auto-aof-rewrite-min-size 64mb 限制允许重写最小aof文件大小,也就是文件大小小于64mb的时候,不需要进行重写。
aof重写原理:
执行redis命令的时候,会把命令写入到.aof文件中,.aof文件变得过大时后台会对它进行重写。在将命令写入到.aof时,即使重写过程发生了停机,现有的.aof文件也不会丢失,所以它是绝对安全的。
同步磁盘数据:
redis在变更数据时,命令会实时记录到.aof文件。但是由于操作系统的缓存机制,数据不是直接写入到硬盘,而是写入硬盘缓存,再通过硬盘缓存机制刷新保存到文件。
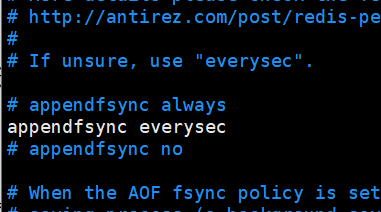
appendfsync always 每次执行写入都会进行同步 , 这个是最安全但是是效率比较低的方式
appendfsync everysec 每一秒执行
appendfsync no 不主动进行同步操作,由操作系统去执行,这个是最快但是最不安全的方式
2.4 aof文件损坏以后如何修复:
例如在执行set name wulei时候,文件只记录了set name ,这种不完整的命令是无法被写入磁盘的。我们可以先将.aof文件备份,然后通过redis-check-aof --fix命令修复,它会将一些不合法的命令清理掉,这样就能被持久化了。
如果要保证数据绝对安全: 可以使用 RDB+AOF 方式来持久化。如果同时使用的话, 那么Redis重启时,会优先使用AOF文件来还原数据。
如果可以接受几分钟的数据丢失:可以使用RDB方式,因为AOF速度没有RDB快。
============================ 手动分割线 ==============================
Redis的过期策略
redis过期是(定期删除+惰性删除+内存淘汰机制)来实现的。reids是用内存来缓存的,内存资源很宝贵。所以我们 set key value 的时候一般都会给它设置过期时间。假设redis里放了10万个数据,redis默认会每隔100ms随机抽取设置了过期时间的key来删除(如果一次性检查所有数据,cpu负载过高redis早就死了),这种方式就叫定期删除。这种策略就会导致很多过期的key并没有被删除,所以还有惰性删除, 也就是在你获取某个key的时候,redis会检查一下,这个key是否过期了,如果是就直接删除不返回任何东西!
但是这种方式还是有问题的,比如10万条全过期了,而redis只定期删除了部分,而客户端有没有对剩下的key操作,key就不会被删除,还是会造成内存的积压。这时候就会走内存淘汰机制,例如:
allkeys-lru:当内存不足以容纳新写入数据时,移除最近最少使用的key。(最常用)
volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键中,将更早过期时间的key优先移除。(还凑合吧)
noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。(脑残的策略,没人用)
allkeys-random:当内存不足以容纳新写入数据时,随机移除某个key。(脑残的策略,没人用)
volatile-lru:当内存不足以容纳新写入数据时,在设了过期时间的键中,移除最近最少使用的key。(脑残的策略,没人用)
volatile-random:当内存不足以容纳新写入数据时,在设了过期时间的键中,随机移除某个key。(脑残的策略,没人用)
缓存淘汰算法LFU算法
lfu算法是根据数据的历史访问频率来淘汰数据的,其核心思想是"如果数据过去被访问多次,那么将来被访问的频率也更高".
缺点:
1. 有存储成本,需要维护队列的引用计数,2.最后添加的数据容易被移除
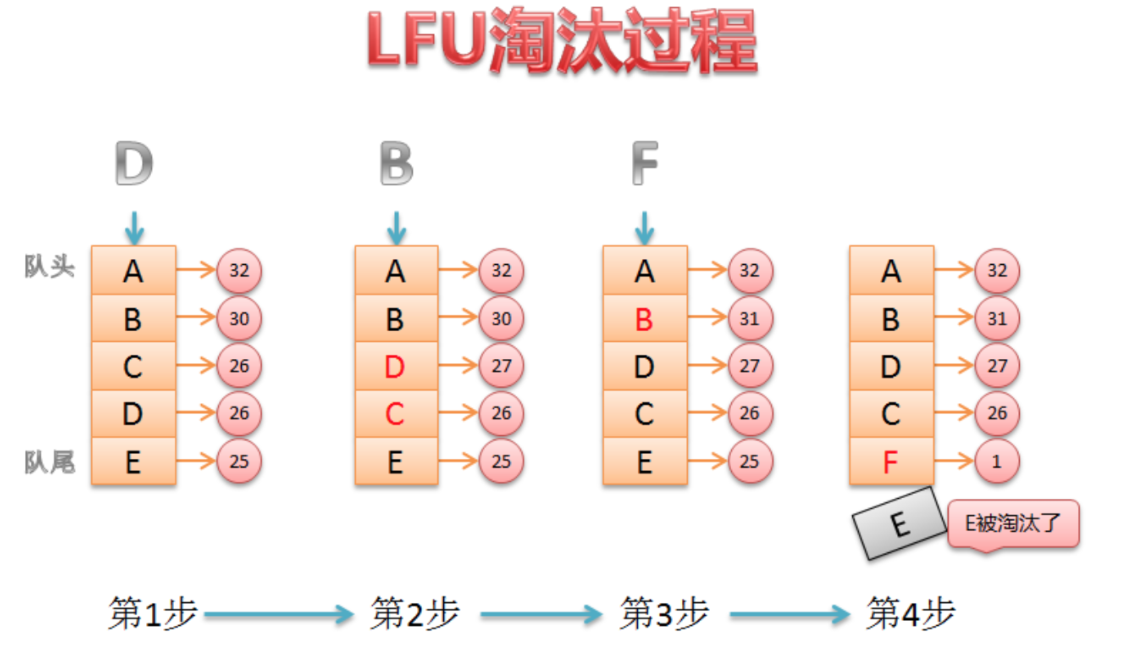
LFU算法原理剖析
1. 新加入的数据插入到队列尾部(因为引用计数为1)
2. 队列中的数据被访问后,其引用计数增加,队列重新排序
3. 当需要淘汰数据时,将已经排序的列表最后的数据块删除
缓存淘汰算法LRU算法
根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”
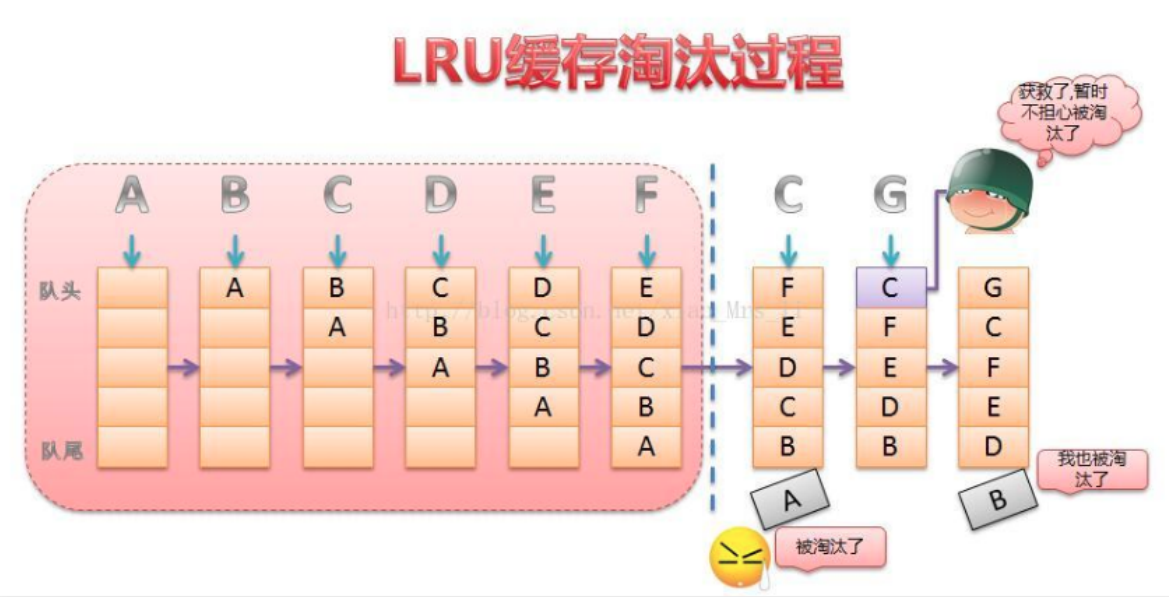
LRU算法原理剖析
1. lru按照一定顺序维护着队列
2. 队列中的数据被访问后,数据会被排列到最前面
3. 当需要淘汰数据时,将已经排序的列表最后的数据块删除
手写LRU算法
import java.util.LinkedHashMap;
import java.util.Map; // lru是有序的,所以这里继承 LinkedHashMap
public class LRUCache<K,V> extends LinkedHashMap<K,V> { private final int CACHE_SIZE;
/**
* 传递进来最多能缓存多少数据
*
* @param cacheSize 缓存大小
*/
public LRUCache(int cacheSize) {
/*
cacheSize是map的初始大小
0.75f是加载因子,容量使用率达到0.75就会扩容一倍
true 表示让 linkedHashMap 按照访问顺序来进行排序,最近访问的放在头部,最老访问的放在尾部。
*/
super(cacheSize, 0.75f, true);
CACHE_SIZE = cacheSize;
} @Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
// 当前map中的数据量大于指定的缓存个数的时候,就自动删除最老的数据。
boolean b = size() > CACHE_SIZE;
if(b){
System.out.println("清除缓存key:"+eldest.getKey());
}
return b;
}
public static void main(String args[]){
LRUCache<String, String> lruCache = new LRUCache<String, String>(3);
lruCache.put("1", "1");
lruCache.put("2", "2");
lruCache.put("3", "3");
lruCache.put("4", "4");
System.out.println("初始化完成:"+lruCache.keySet());
System.out.println(lruCache.get("3"));
System.out.println("访问3之后:"+lruCache.keySet());
System.out.println(lruCache.get("2"));
System.out.println("访问2之后:"+lruCache.keySet());
}
}
redis持久化机制与过期策略的更多相关文章
- 浅谈:Redis持久化机制(一)RDB篇
浅谈:Redis持久化机制(一)RDB篇 众所周知,redis是一款性能极高,基于内存的键值对NoSql数据库,官方显示,它的读效率可达到11万次每秒,写效率能达到8万次每秒,因为它基于内存以及存 ...
- 浅谈:Redis持久化机制(二)AOF篇
浅谈:Redis持久化机制(二)AOF篇 上一篇我们提及到了redis的默认持久化方式RDB,是一种通过存储快照数据方式持久化的机制,它在宕机后会丢失掉最后一次更新RDB文件后的数据,这也是由于它 ...
- 北京大公司二面:了解Redis持久化机制吗?
今日总结 Redis持久化机制:RDB和AOF RDB持久化:定时任务,BGSAVE命令 fork一个子进程生成RDB文件(二进制) AOF持久化:根据配置将写命令存储至日志文件中,顺序写&& ...
- redis持久化机制
redis持久化 redis的数据存在内存中,所以存取性能好.但是存在内存中的数据存在一个问题,一旦机器重启,内存数据消失.为了解决这个问题,redis支持持久化.持久化就是为了解决内存数据丢失时恢复 ...
- Redis 持久化机制
1.背景 之前在使用redis 时候,没有过多的考虑持久化! 但是这样即使你用了redis 也是徒劳,表面上你是用上了redis 进行缓存数据,感觉已经给自己的架构添加了一个道QPS 防护墙! 哈哈, ...
- 细说Redis持久化机制
概述 Redis不仅能够作为缓存来使用,也能够作为内存数据库. Redis作为内存数据库使用时.必需要解决一个问题:数据的持久性.有些将Redis作为缓存使用的场景也需要将缓存的数据持久化到存储介质上 ...
- redis持久化机制【十三】
一.Redis提供了哪些持久化机制: redis的高性能是因为其所有数据都存在了内存中 ,为了使redis在重启之后数据仍然不丢失,需要将数据同步到硬盘中,这一过程就是持久化. redis支持两种方式 ...
- redis持久化机制和内存管理
redis持久化方式有两种:RDB方式和AOF方式 1.RDB方式:内存快照,在指定的时间间隔对数据进行快照存储,支持在客户端直接BGSAVE或者SAVE命令来创建一个内存快照,BGSAVE会fork ...
- Redis持久化机制,优缺点,如何选择合适方式
一.什么是Redis持久化? 持久化就是把内存的数据写到磁盘中去,防止服务宕机了内存数据丢失. 二.Redis 的持久化机制是什么?各自的优缺点? Redis 提供两种持久化机制 RDB(默认) 和 ...
随机推荐
- 容器适配器————heap
堆(heaps)不是容器,而是一种特别的数据组织方式.堆一般用来保存序列容器. 堆是一个完全二叉树,每个节点与其子节点位置相对.父节点总是大于或等于子节点,这种情况下被叫作大顶堆,或者父节点总是小于或 ...
- YOLO_V2
YOLOv2:代表着目前业界最先进物体检测的水平,它的速度要快过其他检测系统(FasterR-CNN,ResNet,SSD),使用者可以在它的速度与精确度之间进行权衡. YOLO9000:这一网络结构 ...
- osm(Openstreetmap)数据下载并导入arcgis
https://3nice.cc/2018/07/18/arcgisosm/ https://blog.csdn.net/zimojiang/article/details/80409139 http ...
- UVA 11988 Broken Keyboard (a.k.a. Beiju Text)(链表)
题目代号:UVA 11988 题目链接:https://uva.onlinejudge.org/index.php?option=com_onlinejudge&Itemid=8&pa ...
- Spotlight_on_mysql 安装和监控
一.下载 1.下载并安装 mysql-connector-3.51.30 2.下载并安装 Quest_Spotlight-on-MySQL_80.exe 二.填写注册码 Authorization K ...
- Firefox_64.0 中selenium ide_3.4.4的使用教程(实操)
说明:旧版的selenium IDE有很多功能,在新版中都去除了,很多功能都做不了. 写于:2018.12.31 一.安装selenium IDE 下载和安装这里推荐参考文章:https://blo ...
- 修改docker下mysql配置
1.在/home/smile/docker/mysql/config/目录下增加一个文件 my.cnf # Copyright (c) , Oracle and/or its affiliates. ...
- spring cloud:hystrix-dashboard-turbine
hystrix-dashboard-turbine-server 1. File-->new spring starter project 2.add dependency <parent ...
- 解决CsvWriter:中文乱码、末尾行多一行空格(/r)、非第一列空字符串""显示null问题
一:主要内容 解决CsvWriter存csv,csv文件打开后中文乱码问题 解决CsvWriter存csv,csv文件最后一行总是多一行空行的问题 解决CsvWriter存csv,csv文件不是第一列 ...
- ACM ICPC 2011-2012 Northeastern European Regional Contest(NEERC)K Kingdom Roadmap
K: 给你n个点以及n-1的条边, 问你最少要加多少条边,使得每两个点割去一条联通的边,还可以使的这两个点连通. 有个一个结论,最少添加的边数为(叶子节点数+1)/ 2. 我们可以只考虑叶子节点数应该 ...