SQL执行计划之sql_trace
一,sql_trace的作用:用以描述SQL的执行过程的trace输出。
SQL>alter session set max_dump_file_size = unlimited;
SQL>alter session set tracefile_identifier = liangjian

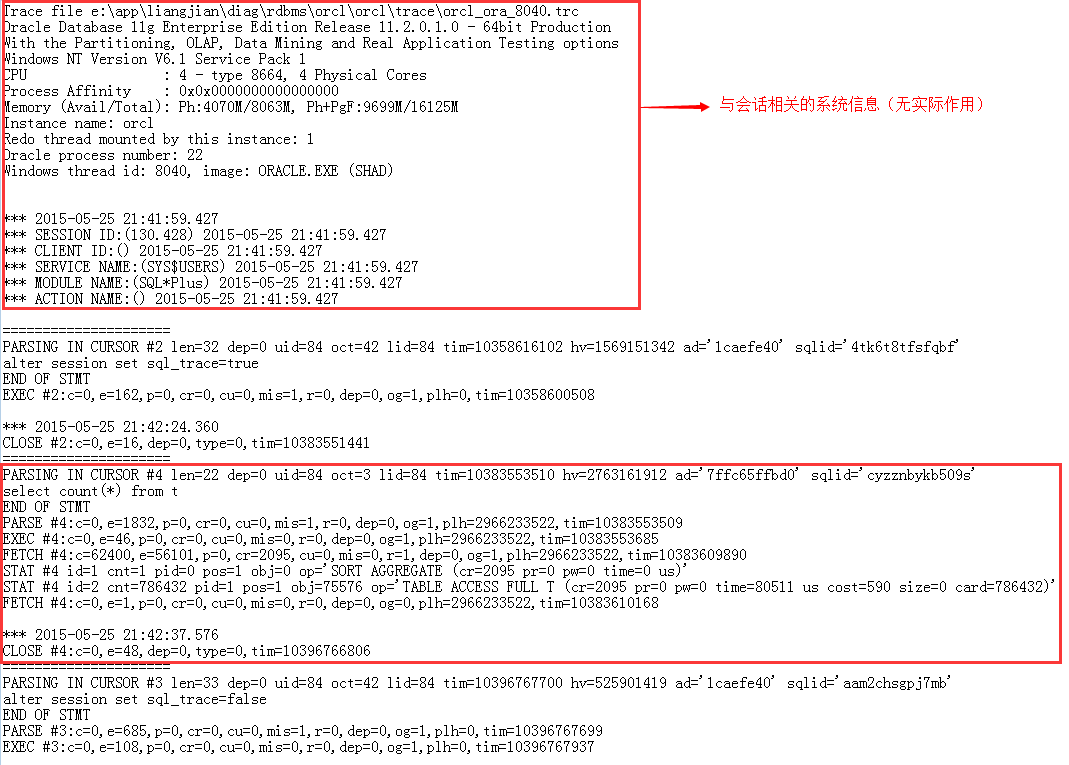
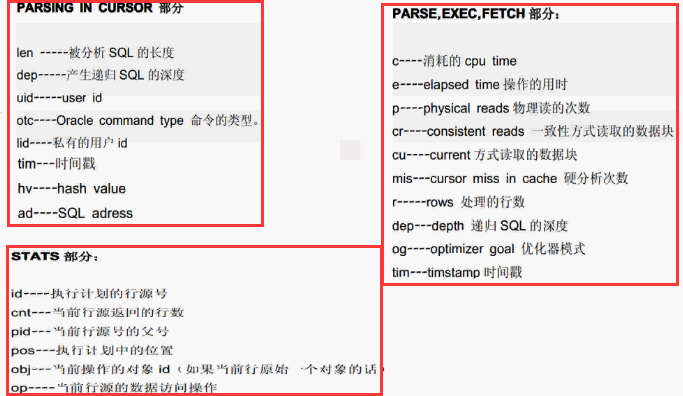
六,tkprof格式化工具

SQL执行计划之sql_trace的更多相关文章
- Oracle中SQL调优(SQL TUNING)之最权威获取SQL执行计划大全
该文档为根据相关资料整理.总结而成,主要讲解Oracle数据库中,获取SQL语句执行计划的最权威.最正确的方法.步骤,此外,还详细说明了每种方法中可选项的意义及使用方法,以方便大家和自己日常工作中查阅 ...
- Oracle查看SQL执行计划的方式
Oracle查看SQL执行计划的方式 获取Oracle sql执行计划并查看执行计划,是掌握和判断数据库性能的基本技巧.下面案例介绍了多种查看sql执行计划的方式: 基本有以下几种方式: ...
- Atitit sql执行计划
Atitit sql执行计划 1.1. 首先要搞明白什么叫执行计划? 执行计划是数据库根据SQL语句和相关表的统计信息作出的一个查询方案,这个方案是由查询优化器自动分析产生的 Oracle中的执行计划 ...
- 查看SQL执行计划
一用户进入某界面慢得要死,查看SQL执行计划如下(具体SQL语句就不完全公布了,截断的如下): call count cpu elapsed disk ...
- 查看Oracle SQL执行计划的常用方式
在查看SQL执行计划的时候有很多方式 我常用的方式有三种 SQL> explain plan for 2 select * from scott.emp where ename='KING'; ...
- sql执行计划解析案例(二)
sql执行计划解析案例(二) 今天是2013-10-09,本来以前自己在专注oracle sga中buffer cache 以及shared pool知识点的研究.但是在研究cache buffe ...
- Oracle之SQL优化专题01-查看SQL执行计划的方法
在我2014年总结的"SQL Tuning 基础概述"中,其实已经介绍了一些查看SQL执行计划的方法,但是不够系统和全面,所以本次SQL优化专题,就首先要系统的介绍一下查看SQL执 ...
- DB查询分析器7.01新增的周、月SQL执行计划功能
DB查询分析器7.01新增的周.月SQL执行计划功能 马根峰 (广东联合电子服务股份有限公司, 广州 510300) 1 引言 中国本土 ...
- SQL优化 MySQL版 -分析explain SQL执行计划与笛卡尔积
SQL优化 MySQL版 -分析explain SQL执行计划 作者 Stanley 罗昊 [转载请注明出处和署名,谢谢!] 首先我们先创建一个数据库,数据库中分别写三张表来存储数据; course: ...
随机推荐
- LCA模板 ( 最近公共祖先 )
LCA 有几种经典的求取方法.这里只给出模板,至于原理我完全不懂. 1.RMQ转LCA.复杂度O(n+nlog2n+m) 大致就是 DFS求出欧拉序 => 对欧拉序做ST表 => LCA( ...
- 【python 应用之四】提升 Python 运行性能的 7 个习惯
大家都知道艺赛旗的 RPA 依赖于 python 语言.因此我们可以掌握一些技巧,可尽量提高 Python 程序性能,也可以避免不必要的资源浪费.1.使用局部变量 尽量使用局部变量代替全局变量:便于维 ...
- wannafly 练习赛11 E 求最值(平面最近点对)
链接:https://www.nowcoder.com/acm/contest/59/E 时间限制:C/C++ 1秒,其他语言2秒 空间限制:C/C++ 32768K,其他语言65536K 64bit ...
- 一款基于jQuery Ajax的等待效果
特别提示:本人博客部分有参考网络其他博客,但均是本人亲手编写过并验证通过.如发现博客有错误,请及时提出以免误导其他人,谢谢!欢迎转载,但记得标明文章出处:http://www.cnblogs.com/ ...
- iOS自动化--Spaceship使用实践
Spaceship ### 脚本操作 证书,app,provision等一些列apple develop后台操作,快速高效. github地址 spaceship开发文档 文档有列出常用的api调用d ...
- LeetCode_1116.打印零与奇偶数(多线程)
LeetCode_1116 LeetCode-1116.打印零与奇偶数 假设有这么一个类: class ZeroEvenOdd { public ZeroEvenOdd(int n) { ... } ...
- Eigen中的矩阵及向量运算
Eigen中的矩阵及向量运算 ,[+,+=,-,-=] ,[\*,\*=] ,[.transpose()] ,[.dot(),.cross(),.adjoint()] ,针对矩阵元素进行的操作[.su ...
- WINDOWS API 大全(二)
9. API之设备场景函数 CombineRgn 将两个区域组合为一个新区域CombineTransform 驱动世界转换.它相当于依顺序进行两次转换CreateCompatibleDC 创建一个与特 ...
- kafka操作命令
kafka启动 bin/kafka-server-start.sh -daemon config/server.properties 创建topic bin/kafka-topics.sh -zook ...
- DNS 搜索 - dig 命令
dig 命令_互动百科 示例: # 全部 dig www.zjffun.com # 只显示 ANSWER SECTION dig www.zjffun.com +noall +answer