小白学 Python 爬虫(26):为啥上海二手房你都买不起

人生苦短,我用 Python
前文传送门:
小白学 Python 爬虫(2):前置准备(一)基本类库的安装
小白学 Python 爬虫(3):前置准备(二)Linux基础入门
小白学 Python 爬虫(4):前置准备(三)Docker基础入门
小白学 Python 爬虫(6):前置准备(五)爬虫框架的安装
小白学 Python 爬虫(10):Session 和 Cookies
小白学 Python 爬虫(11):urllib 基础使用(一)
小白学 Python 爬虫(12):urllib 基础使用(二)
小白学 Python 爬虫(13):urllib 基础使用(三)
小白学 Python 爬虫(14):urllib 基础使用(四)
小白学 Python 爬虫(15):urllib 基础使用(五)
小白学 Python 爬虫(16):urllib 实战之爬取妹子图
小白学 Python 爬虫(17):Requests 基础使用
小白学 Python 爬虫(18):Requests 进阶操作
小白学 Python 爬虫(21):解析库 Beautiful Soup(上)
小白学 Python 爬虫(22):解析库 Beautiful Soup(下)
小白学 Python 爬虫(23):解析库 pyquery 入门
引言
看到题目肯定有同学会问,为啥不包含新房,emmmmmmmmmmm
说出来都是血泪史啊。。。

小编已经哭晕在厕所,那位同学赶紧醒醒,太阳还没下山呢。
别看不起二手房,说的好像大家都买得起一样。

分析
淡不多扯,先进入正题,目标页面的链接小编已经找好了:https://sh.lianjia.com/ershoufang/pg1/ 。

房源数量还是蛮多的么,今年正题房产行业不景气,据说 房价都不高。
小编其实是有目的的,毕竟也来上海五年多了,万一真的爬出来的数据看到有合适,对吧,顺便也能帮大家探个路。

首先还是分析页面的链接信息,其实已经很明显了,在链接最后一栏有一个 pg1 ,小编猜应该是 page1 的意思,不信换成 pg2 试试看,很显然的么。
随便打开一个房屋页面进到内层页面,看下数据:
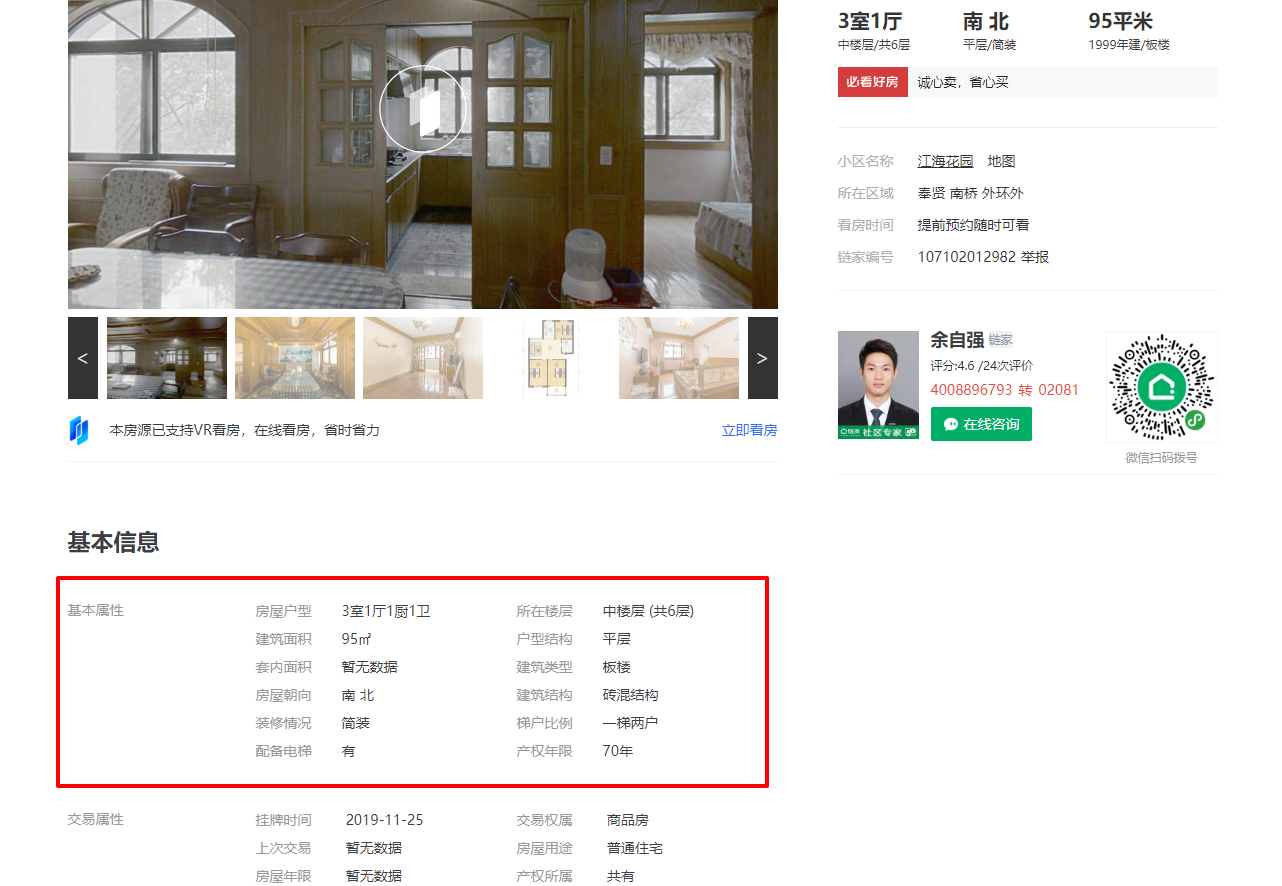
数据还是很全面的嘛,那详细数据就从这里取了。
顺便再看下详情页的链接:https://sh.lianjia.com/ershoufang/107102012982.html 。
这个编号从哪里来?
小编敢保证在外层列表页的 DOM 结构里肯定能找到。

这就叫老司机的直觉,秀不秀就完了。

撸代码
思想还是老思想,先将外层列表页的数据构建一个列表,然后通过循环那个列表爬取详情页,将获取到的数据写入 Mysql 中。
本篇所使用到的请求库和解析库还是 Requests 和 pyquery 。
别问为啥,问就是小编喜欢。
因为简单。

还是先定义一个爬取外层房源列表的方法:
def get_outer_list(maxNum):
list = []
for i in range(1, maxNum + 1):
url = 'https://sh.lianjia.com/ershoufang/pg' + str(i)
print('正在爬取的链接为: %s' %url)
response = requests.get(url, headers=headers)
print('正在获取第 %d 页房源' % i)
doc = PyQuery(response.text)
num = 0
for item in doc('.sellListContent li').items():
num += 1
list.append(item.attr('data-lj_action_housedel_id'))
print('当前页面房源共 %d 套' %num)
return list
这里先获取房源的那个 id 编号列表,方便我们下一步进行连接的拼接,这里的传入参数是最大页数,只要不超过实际页数即可,目前最大页数是 100 页,这里最大也只能传入 100 。
房源列表获取到以后,接着就是要获取房源的详细信息,这次的信息量有点大,解析起来稍有费劲儿:
def get_inner_info(list):
for i in list:
try:
response = requests.get('https://sh.lianjia.com/ershoufang/' + str(i) + '.html', headers=headers)
doc = PyQuery(response.text)
# 基本属性解析
base_li_item = doc('.base .content ul li').remove('.label').items()
base_li_list = []
for item in base_li_item:
base_li_list.append(item.text())
# 交易属性解析
transaction_li_item = doc('.transaction .content ul li').items()
transaction_li_list = []
for item in transaction_li_item:
transaction_li_list.append(item.children().not_('.label').text())
insert_data = {
"id": i,
"danjia": doc('.unitPriceValue').remove('i').text(),
"zongjia": doc('.price .total').text() + '万',
"quyu": doc('.areaName .info').text(),
"xiaoqu": doc('.communityName .info').text(),
"huxing": base_li_list[0],
"louceng": base_li_list[1],
"jianmian": base_li_list[2],
"jiegou": base_li_list[3],
"taoneimianji": base_li_list[4],
"jianzhuleixing": base_li_list[5],
"chaoxiang": base_li_list[6],
"jianzhujiegou": base_li_list[7],
"zhuangxiu": base_li_list[8],
"tihubili": base_li_list[9],
"dianti": base_li_list[10],
"chanquan": base_li_list[11],
"guapaishijian": transaction_li_list[0],
"jiaoyiquanshu": transaction_li_list[1],
"shangcijiaoyi": transaction_li_list[2],
"fangwuyongtu": transaction_li_list[3],
"fangwunianxian": transaction_li_list[4],
"chanquansuoshu": transaction_li_list[5],
"diyaxinxi": transaction_li_list[6]
}
cursor.execute(sql_insert, insert_data)
conn.commit()
print(i, ':写入完成')
except:
print(i, ':写入异常')
continue
两个最关键的方法已经写完了,接下来看下小编的成果:
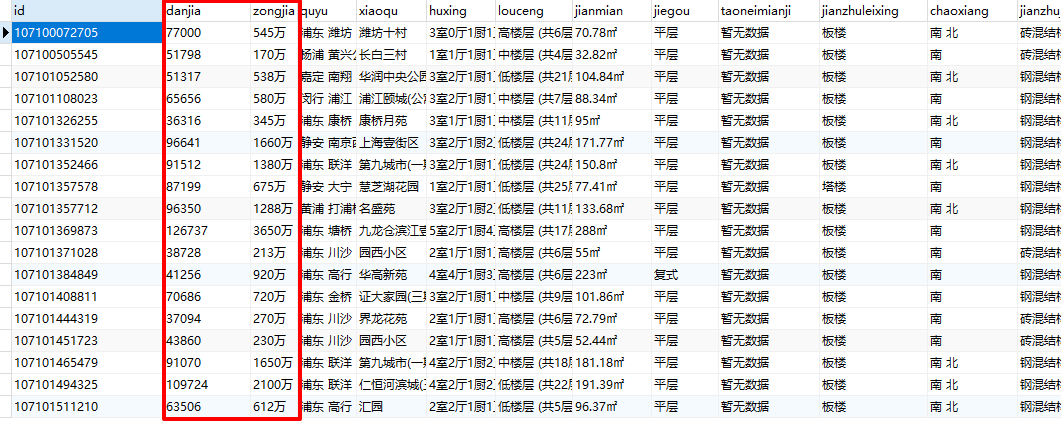
这个价格看的小编血压有点高。

果然还是我大魔都,不管几手房,价格看看就好。
小结
从结果可以看出来,链家虽然是说的有 6W 多套房子,实际上我们从页面上可以爬取到的拢共也就只有 3000 套,远没有达到我们想要的所有的数据。但是小编增加筛选条件,房源总数确实也是会变动的,应该是做了强限制,最多只能展示 100 页的数据,防止数据被完全爬走。
套路还是很深的,只要不把数据放出来,泥萌就不要想能爬到我的数据。对于一般用户而言,能看到前面的一些数据也足够了,估计也没几个人会翻到最后几页去看数据。

本篇的代码就到这里了,如果有需要获取全部代码的,可以访问代码仓库获取。
示例代码
本系列的所有代码小编都会放在代码管理仓库 Github 和 Gitee 上,方便大家取用。
小白学 Python 爬虫(26):为啥上海二手房你都买不起的更多相关文章
- 小白学 Python 爬虫(29):Selenium 获取某大型电商网站商品信息
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(30):代理基础
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(31):自己构建一个简单的代理池
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(32):异步请求库 AIOHTTP 基础入门
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(33):爬虫框架 Scrapy 入门基础(一)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(34):爬虫框架 Scrapy 入门基础(二)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(35):爬虫框架 Scrapy 入门基础(三) Selector 选择器
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(36):爬虫框架 Scrapy 入门基础(四) Downloader Middleware
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(37):爬虫框架 Scrapy 入门基础(五) Spider Middleware
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
随机推荐
- jQuery将字符串转换为数字
1:parseInt(string) parseInt("1234blue"); //returns 1234 parseInt("123"); //retu ...
- openssl使用
一. 加密方法 dsaffdfd fgggg 1.对称加密: 加密算法 + 口令 加密算法: DES(56bits),3DES(用des加密反复加密三次),AES(128bits),Blowfish ...
- 08 (h5*) js第9天--原型、继承
目录: 1:原型和原型链 2:构造函数的原型可以改变 3:原型的最终指向 4:先修改原型指向,在添加方法. 5:实例对象中的属性和原型属性重合, 6:一个神奇的原型链 7:继承 8:原型链 9:利用c ...
- JavaWeb学习——session总结
一.session简介 sesion也就是会话,Session对象存储特定用户会话所需的属性及配置信息.这样,当用户在应用程序的Web页之间跳转时,存储在Session对象中的变量将不会丢失,而是在整 ...
- forEach究竟能不能改变数组的值
forEach究竟能不能改变数组的值 :https://blog.csdn.net/ZhengKehang/article/details/81281563 初学者每次提到Array对象的时候有些烦人 ...
- 清除mac中自动记录的git用户名和密码
应用程序-实用工具-双击钥匙串-右上角搜索github-右击选项删除
- @RestController vs @Controller
package com.example.demo.controller; import java.util.HashMap; import java.util.Map; import org.spri ...
- 125-FMC125-两路125Msps AD,两路160Msps DA FMC子卡模块
FMC125-两路125Msps AD,两路160Msps DA FMC子卡模块 1.板卡概述 该板卡可实现2路14bit 250Msps AD 和2路16bit 160MspsDA功能,FMC连接 ...
- redis开发规范阿里云
一.键值设计 1.key名设计 1) 可读性和可管理性: 以业务名或数据库名为前缀,以防key冲突,用冒号分隔,比如业务名:表名:ID 2)简洁性: 保证语义的前提下,控制key的长度,当key较多 ...
- Java反射及注解学习- 反射的使用 - JDK动态代理
代理模式基本概念:1.代理模式的作用:为其他对象提供一种以控制对方的访问在某种情况下,一个客户不想或者不能直接引用另一个对象,代理可以在客户端和目标对象之间起到中介的作用代理的角色:(1)抽象角色:声 ...