Big Data(三)伪分布式和完全分布式的搭建
关于伪分布式的配置全程
伪分布式图示
1.安装VMWare WorkStation,直接下一步,输入激活码即可安装
2.安装Linux(需要100GB)
引导分区Boot200MB
交换分区Swap2048MB
其余分配到/
3.配置网络服务
vim /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0
TYPE=Ethernet
ONBOOT=yes
NM_CONTROLLED=yes
BOOTPROTO=static
IPADDR=192.168.118.11
NETMASK=255.255.255.0
GATEWAY=192.168.118.2
DNS1=114.114.114.114
DNS2=192.168.118.11
注意点:
1.关于IPADDR的前三个网关,要与虚拟网络编辑器的VMnet8的子网IP的前三个网关一样
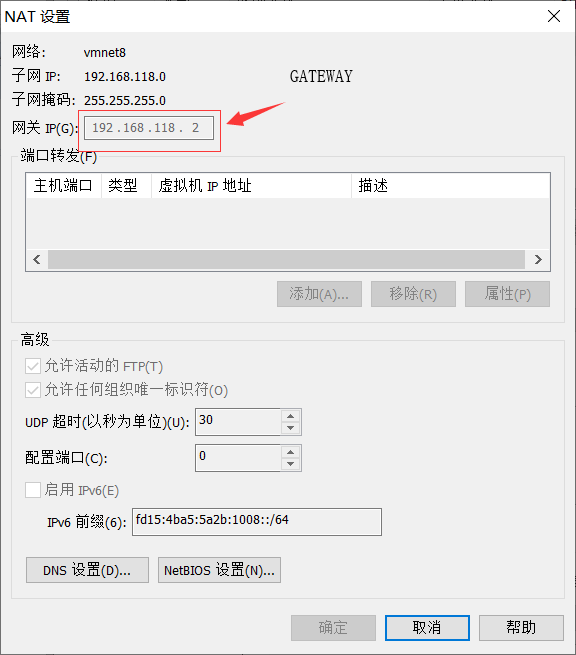
2.关于GATEWAY要与NAT下的GATEWAY一样,详情如下
虚拟网络编辑器:在VMWare编辑下打开
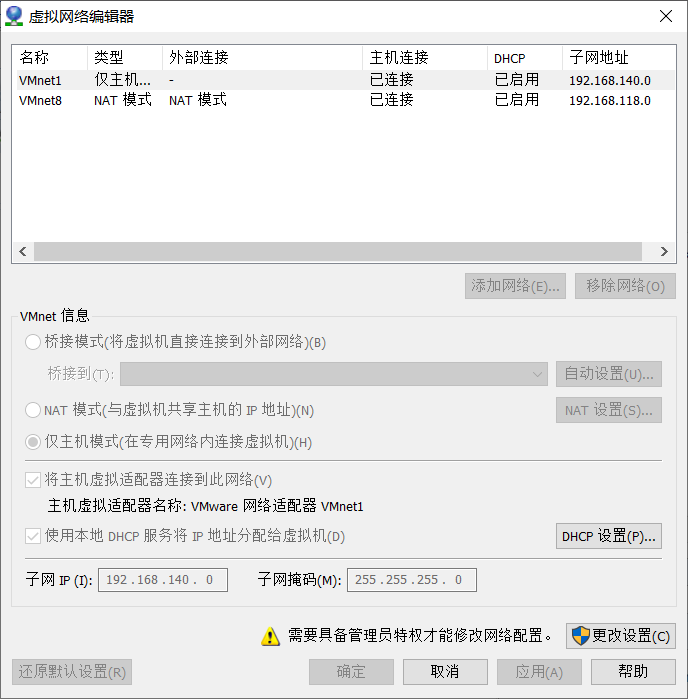
点击NAT设置,查看GATEWAY
4.修改主机名称
vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=node01
5.设置Host(关于Host,是指IP和主机名的映射关系)
vi /etc/hosts
192.168.150.11 node01
192.168.150.12 node02
6.关闭防火墙,开机不启动防火墙
service iptables stop
chkconfig iptables off
7.关闭selinux(selinux是Linux下一种安全模式,打开可能会连不上XShell)
vi /etc/selinux/config
SELINUX=disabled
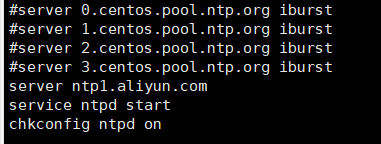
8.时间同步
使用yum安装ntp,并把原有的server注释,替换成
server ntp1.aliyun.com
service ntpd start
chkconfig ntpd on
9.安装jdk,使用xftp上传rpm文件
jdk-8u181-linux-x64.rpm
修改JAVA_HOME
vi /etc/profile
export JAVA_HOME=/usr/java/default
export PATH=$PATH:$JAVA_HOME/bin
source /etc/profile
10.安装ssh免密
(1)检验ssh是否可以登录
ssh localhost
需要输入密码,则不免密
(2)设置免密
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
ssh-keygen -t dsa表示使用dsa算法加密 -p ''表示密码为空 -f ~/ .ssh/id_dsa 将公钥放在/home/.ssh/id_dsa下
不能自己私自创建目录,关于ssh的目录权限,必须为755或者700,不能是777,否则不能使用免密
11.安装Hadoop
mkdir /opt/bigdata
tar xf hadoop-2.6..tar.gz
mv hadoop-2.6. /opt/bigdata/
pwd
/opt/bigdata/hadoop-2.6.
设置Hadoop的环境变量
vi /etc/profile
export JAVA_HOME=/usr/java/default
export HADOOP_HOME=/opt/bigdata/hadoop-2.6.
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
12.修改hadoop-env.sh,此文件为hadoop启动脚本,将JAVA_HOME改为具体的环境变量
cd $HADOOP_HOME/etc/hadoop
vi hadoop-env.sh
export JAVA_HOME=/usr/java/default
13.给出NN角色在哪里启动vi core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:9000</value>
</property>
14.配置一个hdfs副本
<!-- 副本数量为1 -->
<property>
<name>dfs.replication</name>
<value></value>
</property>
<!-- NameNode的路径-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/var/bigdata/hadoop/local/dfs/name</value>
</property>
<!-- DataNode的路径-->
<property>
<name>dfs.datanode.data.dir</name>
<value>/var/bigdata/hadoop/local/dfs/data</value>
</property>
<!-- SecondaryNameNode在哪个端口启动-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node01:</value>
</property>
<!-- SecondaryNameNode的路径-->
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>/var/bigdata/hadoop/local/dfs/secondary</value>
</property>
15.配置Slave
vi slaves
node01
16.初始化&启动
hdfs namenode -format
创建目录,并且初始化一个空的fsimage
VERSION CID
start-dfs.sh
17.修改windows: C:\Windows\System32\drivers\etc\hosts(注意这边IP要与端口一样)
192.168.150.11 node01
192.168.150.12 node02
192.168.150.13 node03
192.168.150.14 node04
18.简单创建目录
hdfs dfs -mkdir /bigdata
hdfs dfs -mkdir -p /user/root
19.HDFS的常见命令
hadoop fs == hdfs dfs 命令的执行要在bin目录下
例:./hadoop fs -ls /
hadoop fs -ls / 查看
hadoop fs -lsr
hadoop fs -mkdir /user/haodop 创建文件夹
hadoop fs -put a.txt /user/hadoop 上传到hdfs
hadoop fs -get /user/hadoop/a.txt 从hdfs下载
hadoop fs -cp src dst 复制
hadoop fs -mv src dst 移动
hadoop fs -cat /user/hadoop/a.txt 查看文件内容
hadoop fs -rm /user/hadoop/a.txt 删除文件
hadoop fs -rmr /user/hadoop 删除文件夹
hadoop fs -text /user/hadoop/a.txt 查看文件内容
hadoop fs -copyFromLocal localsrc dst 与hadoop fs -put功能类似
hadoop fs -moveFromLocal localsrc dst 将本地文件上传到hdfs,同时删除本地文件
、帮助命令查看 hadoop帮助命令查看,不需要输入help,只需要在bin目录下输入即可。
例:./hadoop
./hadoop fs
关于完全分布式的修改
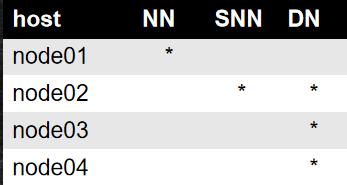
完全分布式图示
1.建立4台Linux主机
2.修改自己的主机名和网关
vim /etc/sysconfig/network-scripts/ifcfg-eth0
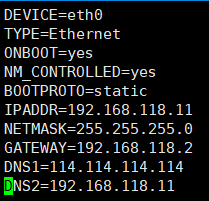
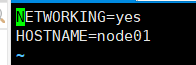
IPADDR分配4个不一样的IP

分配4个主机名
vim /etc/sysconfig/network
3.重启网卡
service network restart
4.重启网卡要记住删除文件
rm -f /etc/udev/rules.d/-persistent-net.rules
5.文件命令
scp xxx node:0x/xx scp是一种远程拷贝
6.`pwd`可以在另一台主机同样位置进行定位
Big Data(三)伪分布式和完全分布式的搭建的更多相关文章
- Hadoop三种安装模式:单机模式,伪分布式,真正分布式
Hadoop三种安装模式:单机模式,伪分布式,真正分布式 一 单机模式standalone单 机模式是Hadoop的默认模式.当首次解压Hadoop的源码包时,Hadoop无法了解硬件安装环境,便保守 ...
- 单机,伪分布式,完全分布式-----搭建Hadoop大数据平台
Hadoop大数据——随着计算机技术的发展,互联网的普及,信息的积累已经到了一个非常庞大的地步,信息的增长也在不断的加快.信息更是爆炸性增长,收集,检索,统计这些信息越发困难,必须使用新的技术来解决这 ...
- 使用Docker搭建Hadoop集群(伪分布式与完全分布式)
之前用虚拟机搭建Hadoop集群(包括伪分布式和完全分布式:Hadoop之伪分布式安装),但是这样太消耗资源了,自学了Docker也来操练一把,用Docker来构建Hadoop集群,这里搭建的Hado ...
- 三、Linux部署MinIO分布式集群
MinIO的官方网站非常详细,以下只是本人学习过程的整理 一.MinIO的基本概念 二.Windows安装与简单使用MinIO 三.Linux部署MinIO分布式集群 四.C#简单操作MinIO 一. ...
- 第三百四十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫数据保存
第三百四十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫数据保存 注意:数据保存的操作都是在pipelines.py文件里操作的 将数据保存为json文件 spider是一个信号检测 ...
- 第三百三十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—深度优先与广度优先原理
第三百三十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—深度优先与广度优先原理 网站树形结构 深度优先 是从左到右深度进行爬取的,以深度为准则从左到右的执行(递归方式实现)Scrapy默认 ...
- Ping CAP CTO、Codis作者谈redis分布式解决方案和分布式KV存储
此文根据[QCON高可用架构群]分享内容,由群内[编辑组]志愿整理,转发请注明出处. 苏东旭,Ping CAP CTO,Codis作者 开源项目Codis的co-author黄东旭,之前在豌豆荚从事i ...
- Elastic Stack之ElasticSearch分布式集群yum方式搭建
Elastic Stack之ElasticSearch分布式集群yum方式搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.搜索引擎及Lucene基本概念 1>.什么 ...
- 3.高并发教程-基础篇-之分布式全文搜索引擎elasticsearch的搭建
高并发教程-基础篇-之分布式全文搜索引擎elasticsearch的搭建 如果大家看了我的上一篇<2.高并发教程-基础篇-之nginx+mysql实现负载均衡和读写分离>文章,如果能很好的 ...
- 分布式文件系统FastDFS简介、搭建、与SpringBoot整合实现图片上传
之前大学时搭建过一个FastDFS的图片服务器,当时只是抱着好奇的态度搭着玩一下,当时搭建采用了一台虚拟机,tracker和storage服务在一台机器上放着,最近翻之前的博客突然想着在两台机器上搭建 ...
随机推荐
- 微信、QQ第三方登录授权时的问题总结
一.微信第一个问题:redirect_uri域名与后台配置不一致,错误码:10003 解决方案: 1,首先确定访问的第三方接口地址参数前后顺序是否正确,redirect_uri回调地址是否加了http ...
- CentOS 6.4 搭建 ntop 网络流量监控分析平台
[前言] Ntop是一种监控网络流量工具,用ntop显示网络的使用情况比其他一些网络管理软件更加直观.详细.Ntop甚至可以列出每个节点计算机的网络带宽利用率. 功能: 自动从网络中识别有用的信息: ...
- 浏览器端-3WSchool-JavaScript:JavaScript Boolean 对象
ylbtech-浏览器端-3WSchool-JavaScript:JavaScript Boolean 对象 1.返回顶部 1. Boolean 对象 Boolean 对象表示两个值:"tr ...
- 阶段3 3.SpringMVC·_02.参数绑定及自定义类型转换_2 请求参数绑定实体类型
参数封装到javaBean对象中 创建新的包domain.在下面新建Account 实现序列化 的接口,定义几个属性 生成get和set.还有toString的方法 表单 重新发布tomcat jav ...
- Pytorch笔记 (2) 初识Pytorch
一.人工神经网络库 Pytorch ———— 让计算机 确定神经网络的结构 + 实现人工神经元 + 搭建人工神经网络 + 选择合适的权重 (1)确定人工神经网络的 结构: 只需要告诉Pytorc ...
- unity中的常遇到的问题
1.使用unity的MovieTexture播放视频在物体上,对象只能在电脑上 2.移动端播放全屏视频 Handheld.PlayFullScreenMovie(),视频文件必须放置在Streamin ...
- Docker 镜像的操作
1. 从docker 镜像仓库获取镜像 docker pull [镜像名] 从 docker hub 中查看版本 获取 特定版本 docker pull centos 7.6.1801 2. ...
- [JS] 点击按钮触发后台事件前,弹出确认框
只需要在button中设置onclick属性触发事件即可 下面以ASP.NET代码为例, ASP.NET中按钮客户端触发js代码的属性是OnClientClick <asp:Button ID= ...
- python 并发编程 协程 协程介绍
协程:是单线程下的并发,又称微线程,纤程.英文名Coroutine.一句话说明什么是线程:协程是一种用户态的轻量级线程,即协程是由用户程序自己控制调度的 需要强调的是: 1. python的线程属于内 ...
- jquery ajax get 数组参数
对一些get请求,但方法参数要求是数组或集合的,如下 public virtual ActionResult Test(List<int> ids) { return Json(" ...