TensorFlow——CNN卷积神经网络处理Mnist数据集
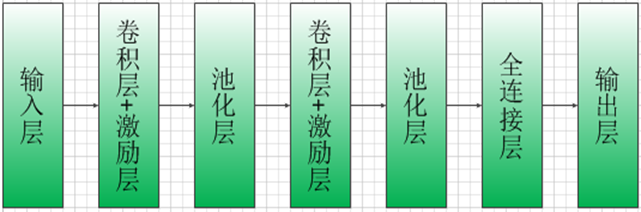
CNN模型结构:
import tensorflow as tf
#Tensorflow提供了一个类来处理MNIST数据
from tensorflow.examples.tutorials.mnist import input_data
import time #载入数据集
mnist=input_data.read_data_sets('MNIST_data',one_hot=True)
#设置批次的大小
batch_size=100
#计算一共有多少个批次
n_batch=mnist.train.num_examples//batch_size #定义初始化权值函数
def weight_variable(shape):
initial=tf.truncated_normal(shape,stddev=0.1)
return tf.Variable(initial)
#定义初始化偏置函数
def bias_variable(shape):
initial=tf.constant(0.1,shape=shape)
return tf.Variable(initial)
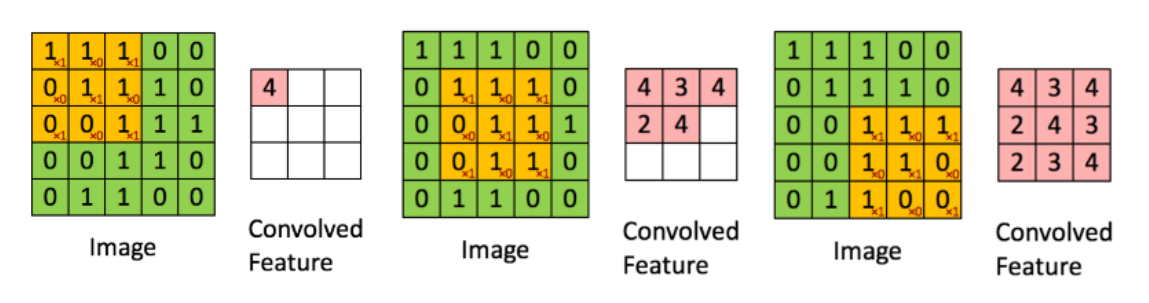
#卷积层
def conv2d(input,filter):
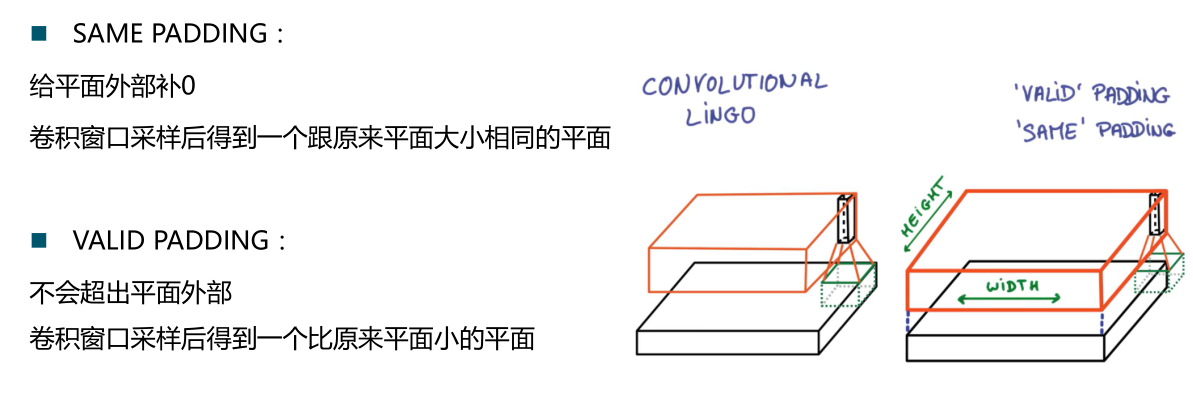
return tf.nn.conv2d(input,filter,strides=[1,1,1,1],padding='SAME')
#池化层
def max_pool_2x2(value):
return tf.nn.max_pool(value,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME') #输入层
#定义两个placeholder
x=tf.placeholder(tf.float32,[None,784]) #28*28
y=tf.placeholder(tf.float32,[None,10])
#改变x的格式转为4维的向量[batch,in_hight,in_width,in_channels]
x_image=tf.reshape(x,[-1,28,28,1]) #卷积、激励、池化操作
#初始化第一个卷积层的权值和偏置
W_conv1=weight_variable([5,5,1,32]) #5*5的采样窗口,32个卷积核从1个平面抽取特征
b_conv1=bias_variable([32]) #每一个卷积核一个偏置值
#把x_image和权值向量进行卷积,再加上偏置值,然后应用于relu激活函数
h_conv1=tf.nn.relu(conv2d(x_image,W_conv1)+b_conv1)
h_pool1=max_pool_2x2(h_conv1) #进行max_pooling 池化层 #初始化第二个卷积层的权值和偏置
W_conv2=weight_variable([5,5,32,64]) #5*5的采样窗口,64个卷积核从32个平面抽取特征
b_conv2=bias_variable([64])
#把第一个池化层结果和权值向量进行卷积,再加上偏置值,然后应用于relu激活函数
h_conv2=tf.nn.relu(conv2d(h_pool1,W_conv2)+b_conv2)
h_pool2=max_pool_2x2(h_conv2) #池化层 #28*28的图片第一次卷积后还是28*28,第一次池化后变为14*14
#第二次卷积后为14*14,第二次池化后变为了7*7
#经过上面操作后得到64张7*7的平面 #全连接层
#初始化第一个全连接层的权值
W_fc1=weight_variable([7*7*64,1024])#经过池化层后有7*7*64个神经元,全连接层有1024个神经元
b_fc1 = bias_variable([1024])#1024个节点
#把池化层2的输出扁平化为1维
h_pool2_flat = tf.reshape(h_pool2,[-1,7*7*64])
#求第一个全连接层的输出
h_fc1=tf.nn.relu(tf.matmul(h_pool2_flat,W_fc1)+b_fc1) #keep_prob用来表示神经元的输出概率
keep_prob=tf.placeholder(tf.float32)
h_fc1_drop=tf.nn.dropout(h_fc1,keep_prob) #初始化第二个全连接层
W_fc2=weight_variable([1024,10])
b_fc2=bias_variable([10]) #输出层
#计算输出
prediction=tf.nn.softmax(tf.matmul(h_fc1_drop,W_fc2)+b_fc2) #交叉熵代价函数
cross_entropy=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y,logits=prediction))
#使用AdamOptimizer进行优化
train_step=tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
#结果存放在一个布尔列表中(argmax函数返回一维张量中最大的值所在的位置)
correct_prediction=tf.equal(tf.argmax(prediction,1),tf.argmax(y,1))
#求准确率(tf.cast将布尔值转换为float型)
accuracy=tf.reduce_mean(tf.cast(correct_prediction,tf.float32)) #创建会话
with tf.Session() as sess:
start_time=time.clock()
sess.run(tf.global_variables_initializer()) #初始化变量
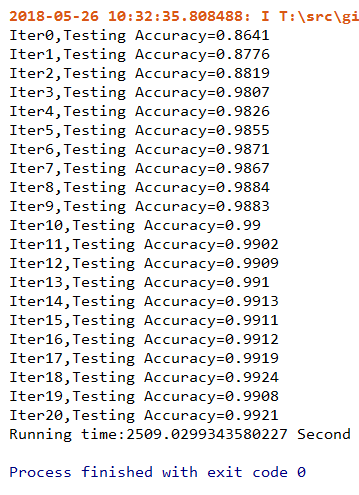
for epoch in range(21): #迭代21次(训练21次)
for batch in range(n_batch):
batch_xs,batch_ys=mnist.train.next_batch(batch_size)
sess.run(train_step,feed_dict={x:batch_xs,y:batch_ys,keep_prob:0.7}) #进行迭代训练
#测试数据计算出准确率
acc=sess.run(accuracy,feed_dict={x:mnist.test.images,y:mnist.test.labels,keep_prob:1.0})
print('Iter'+str(epoch)+',Testing Accuracy='+str(acc))
end_time=time.clock()
print('Running time:%s Second'%(end_time-start_time)) #输出运行时间
运行结果:
tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, data_format=None, name=None)
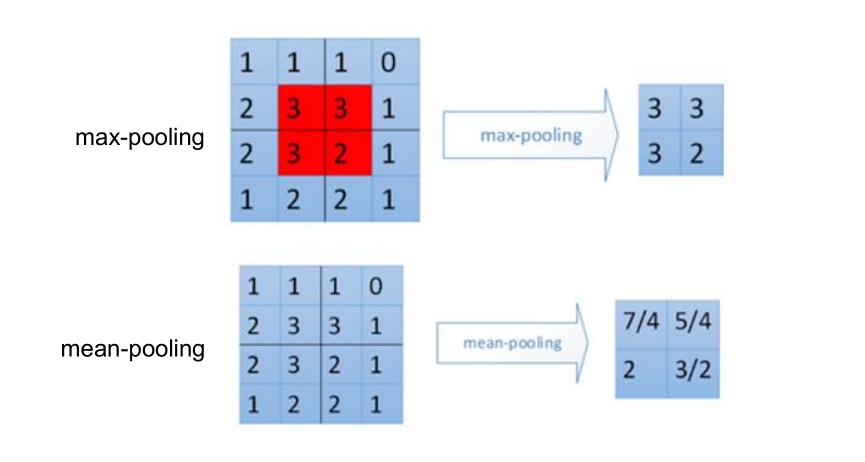
#池化层:
#Max pooling:取“池化视野”矩阵中的最大值
tf.nn.max_pool( value, ksize,strides,padding,data_format=’NHWC’,name=None)
#Average pooling:取“池化视野”矩阵中的平均值
tf.nn.avg_pool(value, ksize,strides,padding,data_format=’NHWC’,name=None)

TensorFlow——CNN卷积神经网络处理Mnist数据集的更多相关文章
- 3层-CNN卷积神经网络预测MNIST数字
3层-CNN卷积神经网络预测MNIST数字 本文创建一个简单的三层卷积网络来预测 MNIST 数字.这个深层网络由两个带有 ReLU 和 maxpool 的卷积层以及两个全连接层组成. MNIST 由 ...
- tensorflow CNN 卷积神经网络中的卷积层和池化层的代码和效果图
tensorflow CNN 卷积神经网络中的卷积层和池化层的代码和效果图 因为很多 demo 都比较复杂,专门抽出这两个函数,写的 demo. 更多教程:http://www.tensorflown ...
- Tensorflow学习教程------利用卷积神经网络对mnist数据集进行分类_利用训练好的模型进行分类
#coding:utf-8 import tensorflow as tf from PIL import Image,ImageFilter from tensorflow.examples.tut ...
- mxnet卷积神经网络训练MNIST数据集测试
mxnet框架下超全手写字体识别—从数据预处理到网络的训练—模型及日志的保存 import numpy as np import mxnet as mx import logging logging. ...
- TensorFlow——LSTM长短期记忆神经网络处理Mnist数据集
1.RNN(Recurrent Neural Network)循环神经网络模型 详见RNN循环神经网络:https://www.cnblogs.com/pinard/p/6509630.html 2. ...
- TensorFlow构建卷积神经网络/模型保存与加载/正则化
TensorFlow 官方文档:https://www.tensorflow.org/api_guides/python/math_ops # Arithmetic Operators import ...
- 使用TensorFlow的卷积神经网络识别自己的单个手写数字,填坑总结
折腾了几天,爬了大大小小若干的坑,特记录如下.代码在最后面. 环境: Python3.6.4 + TensorFlow 1.5.1 + Win7 64位 + I5 3570 CPU 方法: 先用MNI ...
- day-16 CNN卷积神经网络算法之Max pooling池化操作学习
利用CNN卷积神经网络进行训练时,进行完卷积运算,还需要接着进行Max pooling池化操作,目的是在尽量不丢失图像特征前期下,对图像进行downsampling. 首先看下max pooling的 ...
- TensorFlow实现卷积神经网络
1 卷积神经网络简介 在介绍卷积神经网络(CNN)之前,我们需要了解全连接神经网络与卷积神经网络的区别,下面先看一下两者的结构,如下所示: 图1 全连接神经网络与卷积神经网络结构 虽然上图中显示的全连 ...
随机推荐
- [HTML]时钟
<div class="clock" id="clock"> <!-- 原点 --> <div class="origi ...
- TYPORA的使用手册
Typora可以根据当前文档的标题层级,自动生成并显示大纲,窗口的右下角并有字数显示. 1.标题的使用标题的使用格式# 一阶标题 或者快捷键Ctrl+1 ##二阶标题 或者快捷键Ctrl+2 ###三 ...
- SpringMVC开发手册
title: SpringMvc -- 开发手册 date: 2018-11-15 22:14:22 tags: SpringMvc categories: SpringMvc #分类名 type: ...
- 【后台管理系统】—— Ant Design Pro页面相关(一)
一.List列表形式 import React, { PureComponent } from 'react'; import { findDOMNode } from 'react-dom'; im ...
- React Native商城项目实战12 - 首页头部内容
1.HomeTopView为首页头部内容,HomeTopListView为HomeTopView子视图. 2.HomeTopView.js /** * 首页头部内容 */ import React, ...
- dd备份命令使用
转载——dd 参数解释 1. if=文件名:输入文件名,缺省为标准输入.即指定源文件.< if=input file > 2. of=文件名:输出文件名,缺省为标准输出.即指定目的文件.& ...
- shell 操作字符串 变量 数组
#!/bin/bash name="jack" #使用双引号拼接 #greeting="hello,"$name"!" #greeting_ ...
- EF6中一个关于时间类型 datetime2 的坑
在一个访问下位机的程序中,返回的时间戳有时候因断线产生0001年01月01日的时间,而原先使用拼接SQL进行数据存储的操作时,这个问题是可以跳过的. 这次把拼接SQL的部分重新改为EF进行管理,这个坑 ...
- Map 接口有哪些类
Map接口 Map提供了一种映射关系,其中的元素是以键值对(key-value)的形式存储的,能够实现根据key快速查找value:Map中的键值对以Entry类型的对象实例形式存在:建(key值)不 ...
- tensorflow 关于 矩阵 运算 + 符号得含义。 2维 数组 + 1纬数组, 就是每一行都 加一边 1纬数组。 呵呵
小锋子Shawn(403568338) 13:51:23mnist.training.images?墨须(964489899) 13:51:27我的图片是100*100的,该怎么兼容. 小锋子S ...