【python数据挖掘】批量爬取站长之家的图片
概述:
站长之家的图片爬取
使用BeautifulSoup解析html
通过浏览器的形式来爬取,爬取成功后以二进制保存,保存的时候根据每一页按页存放每一页的图片
第一页:http://sc.chinaz.com/tupian/index.html
第二页:http://sc.chinaz.com/tupian/index_2.html
第三页:http://sc.chinaz.com/tupian/index_3.html
以此类推,遍历20页
源代码
# @Author: lomtom# @Date: 2020/2/27 14:22# @email: lomtom@qq.com# 站长之家的图片爬取# 使用BeautifulSoup解析html# 通过浏览器的形式来爬取,爬取成功后以二进制保存# 第一页:http://sc.chinaz.com/tupian/index.html# 第二页:http://sc.chinaz.com/tupian/index_2.html# 第三页:http://sc.chinaz.com/tupian/index_3.html# 遍历14页import osimport requestsfrom bs4 import BeautifulSoupdef getImage():url = ""for i in range(1,15):# 创建文件夹,每一页放进各自的文件夹download = "images/%d/"%iif not os.path.exists(download):os.mkdir(download)# urlif i ==1:url = "http://sc.chinaz.com/tupian/index.html"else:url = "http://sc.chinaz.com/tupian/index_%d.html"%i#发送请求获取响应,成功状态码为200response = requests.get(url)if response.status_code == 200:# 使用bs解析网页bs = BeautifulSoup(response.content,"html5lib")# 定位到图片的divwarp = bs.find("div",attrs={"id":"container"})# 获取imgimglist = warp.find_all_next("img")for img in imglist:# 获取图片名称和链接title = img["alt"]src = img["src2"]# 存入文件with open(download+title+".jpg","wb") as file:file.write(requests.get(src).content)print("第%d页打印完成"%i)if __name__ == '__main__':getImage()
效果图
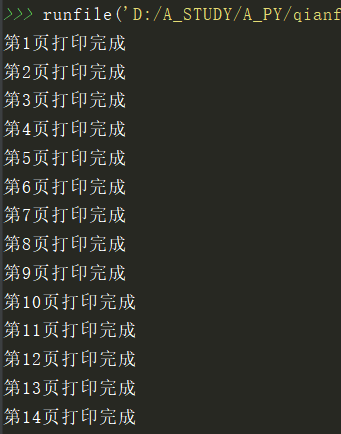
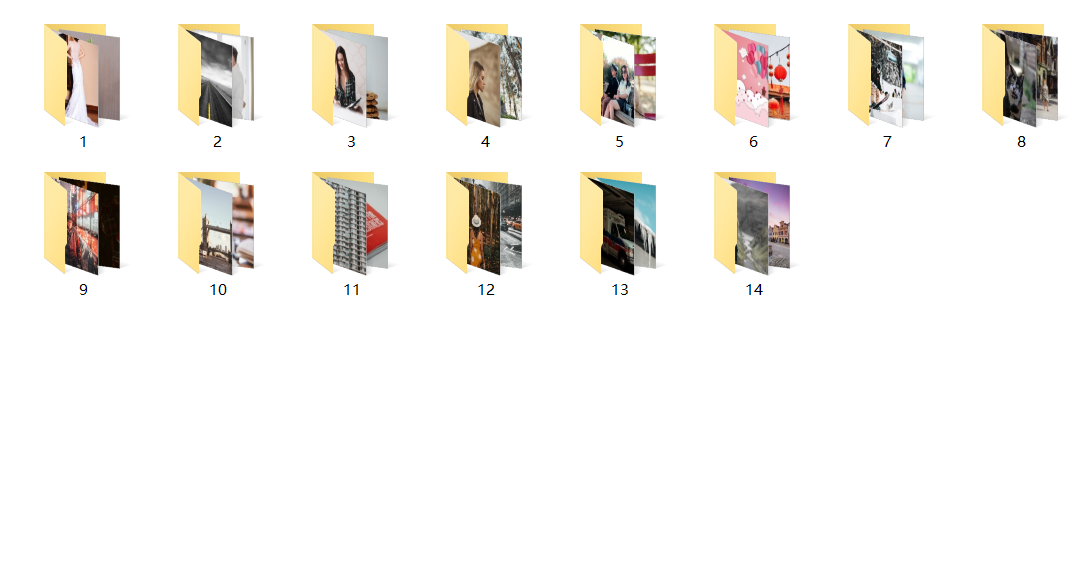
作者
【python数据挖掘】批量爬取站长之家的图片的更多相关文章
- python爬取站长之家植物图片
from lxml import etree from urllib import request import urllib.parse import time import os def hand ...
- from appium import webdriver 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium) - 北平吴彦祖 - 博客园 https://www.cnblogs.com/stevenshushu/p ...
- 【Python】批量查询-提取站长之家IP批量查询的结果v1.0
0 前言 写报告的时候为了细致性,要把IP地址对应的地区给整理出来.500多条IP地址找出对应地区复制粘贴到报告里整了一个上午. 为了下次更好的完成这项重复性很高的工作,所以写了这个小的脚本. 1 使 ...
- 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
抖音很火,楼主使用python随机爬取抖音视频,并且无水印下载,人家都说天下没有爬不到的数据,so,楼主决定试试水,纯属技术爱好,分享给大家.. 1.楼主首先使用Fiddler4来抓取手机抖音app这 ...
- 【Python】批量查询-提取站长之家IP批量查询的结果加强版本v3.0
1.工具说明 写报告的时候为了细致性,要把IP地址对应的地区给整理出来.500多条IP地址找出对应地区复制粘贴到报告里整了一个上午. 为了下次更好的完成这项重复性很高的工作,所以写了这个小的脚本. 某 ...
- 【python数据挖掘】爬取豆瓣影评数据
概述: 爬取豆瓣影评数据步骤: 1.获取网页请求 2.解析获取的网页 3.提速数据 4.保存文件 源代码: # 1.导入需要的库 import urllib.request from bs4 impo ...
- 【Python】批量爬取网站URL测试Struts2-045漏洞
1.概述都懒得写了.... 就是批量测试用的,什么工具里扣出来的POC,然后根据自己的理解写了个爬网站首页URL的代码... #!/usr/bin/env python # -*- coding: u ...
- Python爬虫项目--爬取链家热门城市新房
本次实战是利用爬虫爬取链家的新房(声明: 内容仅用于学习交流, 请勿用作商业用途) 环境 win8, python 3.7, pycharm 正文 1. 目标网站分析 通过分析, 找出相关url, 确 ...
- 从0实现python批量爬取p站插画
一.本文编写缘由 很久没有写过爬虫,已经忘得差不多了.以爬取p站图片为着手点,进行爬虫复习与实践. 欢迎学习Python的小伙伴可以加我扣群86七06七945,大家一起学习讨论 二.获取网页源码 爬取 ...
随机推荐
- 《HelloGitHub》第 46 期
兴趣是最好的老师,HelloGitHub 就是帮你找到兴趣! 简介 分享 GitHub 上有趣.入门级的开源项目. 这是一个面向编程新手.热爱编程.对开源社区感兴趣 人群的月刊,月刊的内容包括:各种编 ...
- Hbase与Maven工程的Spring配置笔记
1.HBase基本操作 hbase shell: 连接到正在运行的HBase实例 help: 显示一些基本的使用信息以及命令示例. 需要注意的是: 表名, 行, 列都必须使用引号括起来 create ...
- Integer梳理
Integer常量池 问题1 public class Main_1 { public static void main(String[] args) { Integer a = 1; Integer ...
- Exception:Request processing failed; nested exception is org.apache.ibatis.binding.BindingException
异常 在测试Spring MVC+Mybatis整合时,运行 Maven build -> tomcat7:Run 遇到如下异常 从异常信息上看,是找不到mapper对应的xml文件,于是我到t ...
- C++基类和派生类的析构函数
1.派生类也不能继承基类的析构函数. 2.与构造函数不同的是,在派生类的析构函数中不用显式地调用基类的析构函数,因为每个类只有一个析构函数,编译器知道如何选择,无需程序员干涉. 3.构造函数和虚构函数 ...
- mysql笔记(暂时)
2018-05-28 create table cms_user(id int key auto_increment,username varchar(20),password varchar(20) ...
- SDL初始化和创建窗口
//初始化SDL2和创建一个窗口,并且将屏幕绘制成大红色 #include <iostream> extern "C" { #include <SDL.h> ...
- 使用自环接口的UDP服务器和客户端
import argparse,socket from datetime import datetime MAX_BYTES = 65535 def server(port): sock = sock ...
- post 两种方式 application/x-www-form-urlencoded和multipart/form-data
本次主要涉及 application/x-www-form-urlencoded方式. postman访问方式如图: java代码实现: 首先使用maven作为第三方依赖管理: <depende ...
- onboard procossor and cross-compile
星载处理器 ERC32-TSC695F The European Space Agency’s ERC32 is a microprocessor implementing a SPARC V7 pr ...