Prometheus基础应用
简介
Prometheus使用扫盲,包含基础的概念和操作说明,基于官网和个人测试。
versoin: 2.14
安装
prometheus安装运行非常方便,下载后解压,运行根目录下的可执行程序prometheus即可。
启动参数
常用启动参数说明
| 参数 | 说明 |
|---|---|
| --version | 打印版本信息 |
| --config.file="prometheus.yml" | 配置文件位置 |
| --web.listen-address="0.0.0.0:9090" | 访问prometheus的IP端口,0.0.0.0支持本地和远程访问,当指定固定IP时只能使用配置IP |
| --web.read-timeout=5m | 请求prometheus时超时时间 |
| --web.max-connections=512 | 最大并发连接 |
| --web.external-url=<URL> | 可用于设置prometheus访问的根路径,默认/,如:设置为“root”时,访问web、API变为http://IP:9090/root/ |
| --web.enable-lifecycle | 开启http的shutdown和reload操作。通过PUT(POST) /-/reload重新加载prometheus配置文件,通过PUT(POST) /-/quit远程关闭prometheus。 |
| --web.enable-admin-api | 开启管理员的api端点 |
| --web.cors.origin=".*" | 跨域支持 |
| --storage.tsdb.path="data/" | 数据存储目录,默认[prometheus_dir]/data/ |
| --storage.tsdb.retention =STORAGE.TSDB.RETENTION | 已过期,使用--storage.tsdb.retention.time |
| --storage.tsdb.retention.time =STORAGE.TSDB.RETENTION.TIME | 数据存储过期时间,如果未配置--storage.tsdb.retention或--storage.tsdb.retention.size,则默认15天 |
| --storage.tsdb.retention.size =STORAGE.TSDB.RETENTION.SIZE | 数据存储大小,Test版参数,后续版本可能改动 |
| --storage.tsdb.wal-compression | 预写入日志压缩 |
| --storage.remote.read-sample-limit=5e7 | 一次抓取样本的最大数量,0为不限制,默认5e7,流式响应忽略此配置 |
| --storage.remote.read-concurrent-limit=10 | 读取数据的并发数,默认10,0无限制 |
| --storage.remote.read-max-bytes-in-frame=1048576 | 一个frame最大读取数据的大小,默认1M,客户端也可以做限制 |
| --alertmanager.notification-queue-capacity=10000 | alertmanager通知队列大小 |
| --alertmanager.timeout=10s | 向alertmanager发送告警的超时时间 |
| --query.timeout=2m | 查询超时时间 |
| --query.max-concurrency=20 | 查询最大并发线程 |
| --query.max-samples=50000000 | 查询可载入内容的最大数据, |
| --log.level=info | 日志等级:debug, info, warn, error |
| --log.format=logfmt | 日志格式:logfmt, json |
管理API
| API | 描述 |
|---|---|
| GET /-/healthy | 健康检查,status 200判定健康 |
| GET /-/ready | 服务可用检查,status 200判定可提供查询服务 |
| PUT /-/reload POST /-/reload |
重新加载配置,包括yaml和rule,需开启 --web.enable-lifecycle |
| PUT /-/quit POST /-/quit |
关闭程序,需开启 --web.enable-lifecycle |
本地存储
(1)存储方式
样本被分组存储,每组存储两个小时的样本和元数据、索引,样本以一个或多个chunk文件存储,执行数据删除时首先执行的是逻辑删除,而非物理删除。
.
├── 01DWGZHP8QP5WC7XJF3ECEEYH1 //分组
│ ├── chunks //样本
│ │ └── 000001
│ ├── index //索引
│ ├── meta.json //元数据
│ └── tombstones
├── 01DWH1PBH94RF9E5H9JV1JV040
│ ├── chunks
│ │ └── 000001
│ ├── index
│ ├── meta.json
│ └── tombstones
├── lock
├── queries.active
└── wal //预写入日志
├── 00000004
├── 00000005
├── 00000006
├── 00000007
├── 00000008
└── checkpoint.000003
└── 00000000
(2)预写入日志(WAL)
chunk中写入的数据首先保存在内存里,未直接持久化。通过write-ahead-log (WAL) 预写入日志可以确保在prometheus崩溃后重新启动时回放日志,恢复数据。默认128MB的segments,支持压缩(需手动开启),最大支持10%时间的block增长,或者21天,先到为准。
注:压缩功能是2.12版本开始引入,因wal格式内容发生变化,如果回退至2.11或以下的版本,需删除wal。
可通过--storage.tsdb.wal-segment-size设置wal的segments大小。
配置
Prometheus配置
具体配置项内容较多,主要描述整体配置模块及主要作用,参数明细参见官方描述。
# 配置全局指标采集周期、超时、告警采集频率等
global:
# 全局告警规则文件文件列表
rule_files:
# 指标数据采集,包含多个job_name,配置对应的地址、采集接口等
scrape_configs:
# 关联告警模块Alertmanager的相关配置
alerting:
# 使用三方模块存储数据时的远程写配置
remote_write:
# 使用三方模块存储数据时的远程读配置
remote_read:
规则配置
prometheus规则配置包括两种规则:
recording rules:记录规则,用于对指定计算的预处理,通过服务端定时执行,客户端在查询时就不需要根据PromQL表达式实时计算,可以直接返回结果。alerting rules:告警规则,配置满足某一特定规则后触发告警。
规则文件在服务启动时会自动校验配置文件的语法、格式,同时提供离线工具校验promtool(prometheus安装根目录下):
./promtool check rules /path/to/example.rules.yml
groups:
# [ - <rule_group> ],一组规则
# 执行频率,可选,默认global.evaluation_interval
interval: 15s
# 当前配置文件中唯一名称
- name: example
# 规则
rules:
# recording rules
# record指标名称
- record: job:http_inprogress_requests:sum
# PromQL表达式
expr: sum(http_inprogress_requests) by (job)
# 记录规则结果中标签,新增/覆盖原始
labels:
type: recording
# alerting rules
# alert指标名称
- alert: HighRequestLatency
# PromQL表达式
expr: job:request_latency_seconds:mean5m{job="myjob"} > 0.5
# 满足告警条件持续多久后,触发告警
for: 10m
# 告警标签,新增/覆盖原始
labels:
severity: page
# 告警注释
annotations:
summary: High request latency
PromQL
概述
返回类型
Prometheus通过自身提供的PromQL语法查询或统计,查询的结果包含四种数据类型:
- Instant vector :瞬时向量,一组时序数据,每个时序数据包含唯一的样本,如*_tatal{}、*_count{}
- Range vector:范围向量,一组时序数据,每个时序数据包含范围内的样本,如*{}[1m]
- Scalar :标量,浮点数字,如sum()、count()
- String:字符串,未使用
参见Expression language data types
时序选择器
(1)瞬时向量
http_requests_total{job="prometheus",group="canary"}
针对瞬时向量http_requests_total,通过{}描述一组选择器,等同SQL中where条件,支持四种操作符:
=等于、!=不等于、=~正则匹配、!~正则不匹配
支持的正则表达式语法RE2
(2)范围向量
http_requests_total{job="prometheus"}[5m]
范围向量通过[]描述查询的范围,等同SQL的between,支持以下六种时间单位:
s秒、m分、h时、d天、w周、y年
(3)偏移量
sum(http_requests_total{method="GET"} offset 5m)
rate(http_requests_total[5m] offset 1w)
通过offset查询指定偏移范围的数据,必须紧跟在选择器之后,不合法使用:
sum(http_requests_total{method="GET"}) offset 5m // INVALID.
子查询
针对给定的范围和颗粒度进行瞬时向量查询,结果为范围向量:
rate(http_requests_total[5m])[20m:2m]
解析:
- 范围:20m
- 颗粒度:2m
- 瞬时向量:http_requests_total[5m]
- 范围向量:20m内,每隔2m的5m增长率
操作符
二元运算符
(1)算数运算符:
+加、-减、*乘、/除、%取余、^乘方
可用在以下操作:
- 两个scalar
- instant vector和scalar,instant vector中每个样本的值都会与scalar进行运算
- 两个instant vector,取两个vector的样本交集进行运算,结果存放在新的vector中,结果的指标名称将被删除。
(2)比较运算符:
==等于、!=不等于、> 大于、<小于、>=大于等于、<=小于等于
默认情况下,比较的运算结果,是返回两个向量中满足比较的样本,可通过运算符后加关键字bool来改变比较的结果,0表示false,1表示true,支持以下几种类型的比较:
- 两个scalar,必须在运算符后添加
bool,返回0/1 - instant vector和scalar,scalar与instant vector中每个样本进行比较。当使用
bool时,返回instant vector中全量样本的比较结果;未使用bool时,仅返回满足比较的样本。 - 两个instant vector,取两个vector的样本交集进行比较。当使用
bool时,返回所有交集样本的比较结果(0或1);未使用bool时,仅返回满足比较的样本内容(交集但不匹配也不会返回)。
(3)逻辑运算符
and与、or或、unless补
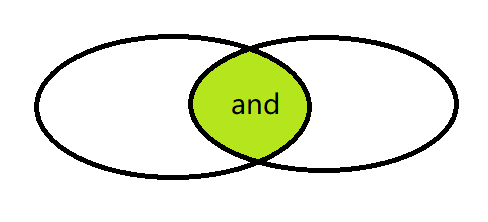
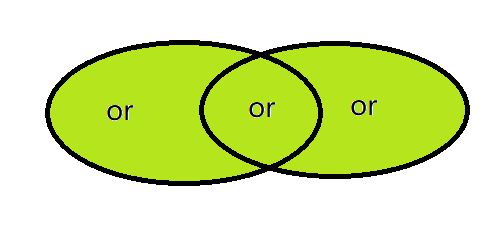
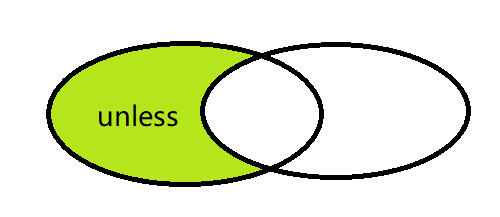
说明:v1 unless v2所获取的结果是v1中有,v2中没有的,返回内容是v1中的样本。
(4)优先级
^*,/,%+,-==,!=,<=,<,>=,>and,unlessor
优先级自上至下,运算顺序从左到右,^除外,从右到左。
向量匹配
(1)one-to-one
两个向量在操作时vector1 <operator> vector2,默认匹配是按照标签和标签值全部匹配时才可以进行运算,使用ignoring关键字忽略一组匹配的标签,使用on关键字仅匹配指定的一组标签。
# 忽略le标签,匹配handler标签
prometheus_http_response_size_bytes_bucket{handler="/",le="100"} / ignoring (le) prometheus_http_response_size_bytes_count
# 使用handler匹配
prometheus_http_response_size_bytes_bucket{handler="/",le="100"} / on (handler) prometheus_http_response_size_bytes_count
(2)many-to-one / one-to-many
比较复杂,多数情况使用ignoring就可以处理,不做描述。
聚合运算
sum(v instant-vector)和min(v instant-vector)最小值max(v instant-vector)最大值avg(v instant-vector)平均值stddev(v instant-vector)标准差stdvar(v instant-vector)标准方差count(v instant-vector)样本数量count_values(lable_name string, v instant-vector)计算向量样本中各个value出现的次数bottomk(k scalar, v instant-vector)取最小k个valuetopk(k scalar, v instant-vector)取最大的k个valuequantile(φ scalar, v instant-vector)计算分位数
使用without排除结果中的标签,by根据指定标签分组统计,仅适用输入向量的处理,语法:
<aggr-op> [without|by (<label list>)] ([parameter,] <vector expression>)
或者
<aggr-op>([parameter,] <vector expression>) [without|by (<label list>)]
例:
# 指标prometheus_http_response_size_bytes_bucket根据handler标签分组求和
sum by (handler) (prometheus_http_response_size_bytes_bucket)
# 指标prometheus_http_response_size_bytes_bucket排除handler标签后,分组求和
sum(prometheus_http_response_size_bytes_bucket) without (handler)
函数
abs(v instant-vector):返回给定瞬时向量的所有样本的绝对值absent(v instant-vector):如果给定瞬时向量包含样本,则返回空;如果给定向量为空,则返回不包含指标名的样本,value为1ceil(v instant-vector):瞬时向量值向上取整changes(v range-vector):返回给定范围向量的值变化次数,即value的枚举数clamp_max(v instant-vector, max scalar):设定给定瞬时向量的上限值:低于给定max保持原值,高于max则为maxclamp_min(v instant-vector, min scalar):设定给定瞬时向量的下限值:高于给定min保持原值,低于min则为minday_of_month(v=vector(time()) instant-vector):返回给定的UTC时间是当月的第几天,取值1-31day_of_week(v=vector(time()) instant-vector):返回给定的UTC时间是本周的第几天,取值0-6,0为周日days_in_month(v=vector(time()) instant-vector):返回给定的UTC时间的月份有多少天,取值28-31delta(v range-vector):计算范围向量中第一个值和最后一个值的差值,用于gaugederiv(v range-vector):使用简单线性回归计算范围向量中时间序列的二阶导数,用于gaugeexp(v instant-vector):返回给定瞬时向量值的指数函数值,即e^value,value很大时返回+Inf。特殊情况:Exp(+Inf) = +Inf、Exp(NaN) = NaNfloor(v instant-vector):瞬时向量向下取整histogram_quantile(φ float, b instant-vector):计算给定瞬时向量的百分位数(0<=φ<=1),用于直方图(histogram)的bucket百分位数计算。如果直方图buckets少于2,返回NaN,如果给定的百分位数φ<0,返回-Inf;φ>1,返回+Infholt_winters(v range-vector, sf scalar, tf scalar):生成给定向量的平滑值,平滑因子sf越低老数据越重要,趋势因子tf越高趋势数据越重要,用于gaugehour(v=vector(time()) instant-vector):返回给定的UTC时间的小时,取值0-23idelta(v range-vector):计算范围向量最后两个值的差,用于gaugeincrease(v range-vector):计算范围向量最后一个值减去第一个值的差,仅应用于counter,打破单调性时(如由于目标重启导致的计数器重置)会自动调整。irate(v range-vector):计算范围向量的瞬时增长率,样本最后两个值的增长率,仅适用于计算快速变化的值,趋势分析使用rate(),打破单调性时(如由于目标重启导致的计数器重置)会自动调整label_join(v instant-vector, dst_label string, separator string, src_label_1 string, src_label_2 string, ...):对瞬时向量中每一个样本,将src_lable(范围向量中指标的标签)的value使用separator拼接,结果存放在新标签dst_label中,相当于给原始样本新增了一个dst_labellabel_replace(v instant-vector, dst_label string, replacement string, src_label string, regex string):对瞬时向量的每个样本,满足正则regex匹配的标签src_label,将指定的正则子组replacement(用$1、$2...表示)放入目标标签dst_labelln(v instant-vector):瞬时向量样本自然对数(e),特殊情况:ln(+Inf) = +Inf、ln(0) = -Inf、ln(x < 0) = NaN、ln(NaN) = NaNlog2(v instant-vector):瞬时向量2的对数log10(v instant-vector):瞬时向量10的对数minute(v=vector(time()) instant-vector):给定的UTC时间是当前小时的多少分钟,取值0-59month(v=vector(time()) instant-vector):给定的UTC时间是当前年份第几个月,取值1-12predict_linear(v range-vector, t scalar):基于范围向量使用简单线性回归,预测从当前开始t秒后的值rate(v range-vector):计算范围向量的平均增长率,打破单调性时(如由于目标重启导致的计数器重置)会自动调整,适用趋势分析和告警,用于counter类型。与聚合操作符或聚合函数一起使用时,需先执行rate再执行聚合,否则rate无法检测到重置。resets(v range-vector):返回范围向量中计时器的重置次数,以瞬时向量返回,两个连续样本数值发生减少则认为重置,用于counterround(v instant-vector, to_nearest=1 scalar):使用瞬时向量样本进行计算,返回值是to_nearest的整数倍,该值与样本值偏差最小。如样本值为sample_value,存在(n-1)*to_nearest < sample_value < n*to_nearest,则与sample_value差值小的一侧值为计算结果,如果差值相等,选较大值。scalar(v instant-vector):给定瞬时向量的样本值转为标量,样本数量=0或>1时,返回NaNsort(v instant-vector):瞬时向量样本值升序排列sort_desc(v instant-vector):瞬时向量样本值降序排列sqrt(v instant-vector):瞬时向量的样本值开方time():返回表达式计算的时间。timestamp(v instant-vector):返回瞬时向量中每个样本的时间戳。vector(s scalar):scalar转为vector,不含标签year(v=vector(time()) instant-vector):返回给定时间的年<aggregation>_over_time():范围向量聚合统计类函数avg_over_time(range-vector): 平均值min_over_time(range-vector): 最小值max_over_time(range-vector): 最大值sum_over_time(range-vector): 求和count_over_time(range-vector): 数量quantile_over_time(scalar, range-vector): scalar在vector中的分位数stddev_over_time(range-vector): 标准差stdvar_over_time(range-vector): 标准方差
详细描述,见FUNCATIONS。
HTTP API
API接口请求返回2xx状态码,响应数据是json格式。
异常请求返回:
400 Bad Request参数错误422 Unprocessable Entity表达式无法执行503 Service Unavailable请求超时或被丢弃
响应数据如下:
{
"status": "success" | "error", // 请求状态
"data": <data>, // 响应数据
// 请求异常时返回,status为error
"errorType": "<string>",
"error": "<string>",
// 请求存在警告时返回
"warnings": ["<string>"]
}
表达式查询
当查询返回结果超过server端字符限制时,可将参数使用URL编码,并指定请求方式为POST,请求头Content-Type: application/x-www-form-urlencoded。
查询返回格式:
{
"resultType": "matrix" | "vector" | "scalar" | "string", // 响应格式
"result": <value> // 响应值
}
上述返回为[HTTP API](#HTTP API)中<data>标签内容,返回具体格式见响应格式。
查询主要包含以下两种:
(1)瞬时查询
API:
GET /api/v1/query
POST /api/v1/query
Params:
query=: PromQL表达式time=: 时间,默认当前服务器时间,可选timeout=: 超时时间,默认使用-query.timeout,可选
(2)范围查询
API:
GET /api/v1/query_range
POST /api/v1/query_range
Params:
query=: PromQL表达式start=: 开始时间end=: 结束时间step=: 查询周期间隔timeout=: 超时时间,默认使用-query.timeout,可选
响应格式
API表达式查询的返回格式,包括matrix, vector, scalar, string四种,对应PromQL定义的四种返回类型,以下描述的返回格式,均为表达式查询中result标签内容。
**(1)Range vectors **
范围向量返回格式定义为matrix:
[
{
"metric": { "标签名": "标签值", ... },
"values": [ [ 时间戳, "样本值" ], ... ]
},
...
]
(2)Instant vectors
瞬时向量格式定义为vector:
[
{
"metric": { "标签名": "标签值", ... },
"value": [ 时间戳, "样本值" ]
},
...
]
**(3)scalar **
标量格式定义为scalar:
[ 时间戳, "数值" ]
**(4)string **
字符串定义为string:
[ 时间戳, "字符串值" ]
元数据查询
(1)根据标签查找指标
当查询返回结果超过server端字符限制时,可将参数使用URL编码,并指定请求方式为POST,请求头Content-Type: application/x-www-form-urlencoded。
API:
GET /api/v1/series
POST /api/v1/series
Params:
match[]=: 一个或多个匹配选择器,至少一个start=: 开始时间end=: 结束时间
(2)查询标签名
API:
GET /api/v1/labels
POST /api/v1/labels
(3)查询标签值
API:
GET /api/v1/label/<label_name>/values
目标查询
查询prometheus监控的目标对象的状态信息。
API:
GET /api/v1/targets
规则查询
返回当前已加载的预警规则信息,和由实例触发的告警规则,该新增API稳定性暂时不能保证。
API:
GET /api/v1/rules
告警查询
返回当前激活的告警列表,该新增API稳定性暂时不能保证。
GET /api/v1/rules
目标元数据查询
试验性接口,可能变动,建议不应用。
API:
GET /api/v1/targets/metadata
Params:
match_target=: 标签选择器,为空匹配所有目标metric=: 指标名称,为空匹配所有指标limit=: 最大匹配数
AlertManager状态查询
告警组件AlertManager状态查询。
API:
GET /api/v1/alertmanagers
状态查询
查询当前prometheus相关配置信息。
API:
GET /api/v1/status/config // 返回当前已加载的配置yaml文件内容,不含注释
GET /api/v1/status/flags // 返回prometheus启动配置项信息
GET /api/v1/status/runtimeinfo // 返回运行信息,如启动时间、chunk数、安装目录等
GET /api/v1/status/buildinfo // 返回prometheus版本构建信息
数据库管理API
所有数据库管理API需要开启--web.enable-admin-api。
(1)快照
接口用于保存实时数据的快照,数据存放在<data-dir>/snapshots/<datetime>-<rand>,接口返回生成的数据目录名称<datetime>-<rand>。
API:
POST /api/v1/admin/tsdb/snapshot
PUT /api/v1/admin/tsdb/snapshot
Params:
skip_head=: 跳过头块中未压缩的数据,可选。
(2)删除
用于删除时间段内指定的指标数据,数据不会被立即删除,会在后续清理或调用清理的接口。操作成功会返回204.
API:
POST /api/v1/admin/tsdb/delete_series
PUT /api/v1/admin/tsdb/delete_series
Params:
match[]=: 一个或多个匹配选择器,至少一个start=: 开始时间,可选,默认最小时间。end=: 结束时间,可选,默认最大时间
(3)清理
用于清理 已删除的数据,会立即释放磁盘空间,操作成功返回204
API:
POST /api/v1/admin/tsdb/clean_tombstones
PUT /api/v1/admin/tsdb/clean_tombstones
Prometheus基础应用的更多相关文章
- Prometheus基础(二)
1.什么是Prometheus? Prometheus是由SoundCloud开发的开源监控报警系统和时序列数据库(TSDB).Prometheus使用Go语言开发,是Google BorgMon监控 ...
- Prometheus基础
监控系统作用 监控系统主要用于保证所有业务系统正常运行, 和业务的瓶颈监控. 需要周期性采集和探测. 采集的详情 采集: 采集器, 被监控端, 监控代理, 应用程序自带仪表盘, 黑盒监控, SNMP. ...
- Prometheus监控学习记录
官方文档 Prometheus基础文档 从零开始:Prometheus 进阶之路:Prometheus —— 技巧篇 进阶之路:Prometheus —— 理解篇 prometheus的数据类型介绍 ...
- 360 基于 Prometheus的在线服务监控实践
转自:https://mp.weixin.qq.com/s/lcjZzjptxrUBN1999k_rXw 主题简介: Prometheus基础介绍 Prometheus打点及查询技巧 Promethe ...
- 《为什么说 Prometheus 是足以取代 Zabbix 的监控神器?》
为什么说 Prometheus 是足以取代 Zabbix 的监控神器? Kuberneteschina 致力于提供最权威的 Kubernetes 技术.案例与Meetup! 关注他 12 人赞同 ...
- prometheus学习系列一: Prometheus简介
Prometheus简介 prometheus受启发于Google的Brogmon监控系统(相似kubernetes是从Brog系统演变而来), 从2012年开始由google工程师Soundclou ...
- Prometheus 学习目录
Prometheus 介绍 Prometheus 安装 https://www.bookstack.cn/read/prometheus-book/quickstart-why-monitor.md ...
- 01 . Prometheus简介及安装配置Grafana
Promethus简介 Prometheus受启发于Google的Brogmon监控系统(相似的Kubernetes是从Google的Brog系统演变而来),从2012年开始由前Google工程师在S ...
- Python调用Prometheus监控数据并计算
Prometheus是什么 Prometheus是一套开源监控系统和告警为一体,由go语言(golang)开发,是监控+报警+时间序列数 据库的组合.适合监控docker容器.因为kubernetes ...
随机推荐
- pytorch学习笔记(九):PyTorch结构介绍
PyTorch结构介绍对PyTorch架构的粗浅理解,不能保证完全正确,但是希望可以从更高层次上对PyTorch上有个整体把握.水平有限,如有错误,欢迎指错,谢谢! 几个重要的类型和数值相关的Tens ...
- Android Studio(九):引用jar及so文件
Android Studio相关博客: Android Studio(一):介绍.安装.配置 Android Studio(二):快捷键设置.插件安装 Android Studio(三):设置Andr ...
- C#的类
一.String类 1.Length 字符的长度 string x = Console.ReadLine();int i = x.Length;// Length 是获取字符串的长度(从1开始数)Co ...
- Codeforces Round #170 (Div. 1 + Div. 2)
A. Circle Line 考虑环上的最短距离. B. New Problem \(n\) 个串建后缀自动机. 找的时候bfs一下即可. C. Learning Languages 并查集维护可以沟 ...
- 前端开发工具之jQuery
jQuery jQuery是一个轻量级的JavaScript第三方库,能够简单方便的进行JavaScript编程. jQuery选择器 1,id选择器: $("#id") 2,标签 ...
- Python--day61--Django ORM单表操作之展示用户列表
user_list.html views.py 项目的urls.py文件
- JAVA配置系统变量
CLASSPATH= .;%JAVA_HOME%/lib/dt.jar;%JAVA_HOME%/lib/tools.jar JAVA_HOME = C:/Program Files/Java/jdk1 ...
- tomcat access日志
每次看access log都会记不住pattern里的各个标识代表的什么意思,记录下,备忘! tomcat的access log是由实现了org.apache.catalina.AccessLog接口 ...
- C# 强转会不会抛出异常
最近遇到一个小伙伴问我,从一个很大的数强转,会不会抛出异常.实际上不会出现异常 最简单的代码是使用一个比 maxvalue 大的数,然后用它强转 long tathkDucmmsc = int.Max ...
- webpack学习(二)初识打包配置
前言:webpack打包工具让整个项目的不同文件夹相互关联,遵循我们想要的规则.想 .vue文件, .scss文件浏览器并不认识,因此webpage暗中做了很多转译,编译等工作. 事实上,如果我们在没 ...