第五篇 scrapy安装及目录结构,启动spider项目
实际上安装scrapy框架时,需要安装很多依赖包,因此建议用pip安装,这里我就直接使用pycharm的安装功能直接搜索scrapy安装好了。
然后进入虚拟环境创建一个scrapy工程:
(third_project) bigni@bigni:~/python_file/python_project/pachong$ scr
scrapy screendump script scriptreplay
(third_project) bigni@bigni:~/python_file/python_project/pachong$ scrapy startproject ArticleSpider
New Scrapy project 'ArticleSpider', using template directory '/home/bigni/.virtualenvs/third_project/lib/python3.5/site-packages/scrapy/templates/project', created in:
/home/bigni/python_file/python_project/pachong/ArticleSpider You can start your first spider with:
cd ArticleSpider
scrapy genspider example example.com
(third_project) bigni@bigni:~/python_file/python_project/pachong$
我用pycharm进入创建好的scrapy项目,这个目录结构比较简单,而且有些地方很像Django

Spiders文件夹:我们可以在Spiders文件夹下编写我们的爬虫文件,里面主要是用于分析response并提取返回的item或者是下一个URL信息,每个Spider负责处理特定的网站或一些网站。__init__.py:项目的初始化文件。
items.py:通过文件的注释我们了解到这个文件的作用是定义我们所要爬取的信息的相关属性。Item对象是种容器,用来保存获取到的数据。
middlewares.py:Spider中间件,在这个文件里我们可以定义相关的方法,用以处理蜘蛛的响应输入和请求输出。
pipelines.py:在item被Spider收集之后,就会将数据放入到item pipelines中,在这个组件是一个独立的类,他们接收到item并通过它执行一些行为,同时也会决定item是否能留在pipeline,或者被丢弃。
settings.py:提供了scrapy组件的方法,通过在此文件中的设置可以控制包括核心、插件、pipeline以及Spider组件。
创建爬虫模板:
好比在Django中创建一个APP,在次创建一个爬虫
命令:
#注意:必须在该工程目录下
#创建一个名字为blogbole,爬取root地址为blog.jobbole.com 的爬虫;爬伯乐在线
scrapy genspider jobbole blog.jobbole.com
(third_project) bigni@bigni:~/python_file/python_project/pachong/ArticleSpider/ArticleSpider$ scrapy genspider jobbole blog.jobbole.com
Created spider 'jobbole' using template 'basic' in module:
ArticleSpider.spiders.jobbole
然后可以在spiders里看到新生成的文件jobbole.py

jobbole.py的内容如下:
# -*- coding: utf-8 -*-
import scrapy class JobboleSpider(scrapy.Spider):
# 爬虫名字
name = 'jobbole'
# 运行爬取的域名
allowed_domains = ['blog.jobbole.com']
# 开始爬取的URL
start_urls = ['http://blog.jobbole.com/'] # 爬取函数
def parse(self, response):
pass
在终端上执行 :scrapy crawl jobbole 测试下,其中jobbole是spidername
(third_project) bigni@bigni:~/python_file/python_project/pachong/ArticleSpider/ArticleSpider$ scrapy crawl jobbole
2017-08-27 22:24:21 [scrapy.utils.log] INFO: Scrapy 1.4.0 started (bot: ArticleSpider)
2017-08-27 22:24:21 [scrapy.utils.log] INFO: Overridden settings: {'BOT_NAME': 'ArticleSpider', 'NEWSPIDER_MODULE': 'ArticleSpider.spiders', 'ROBOTSTXT_OBEY': True, 'SPIDER_MODULES': ['ArticleSpider.spiders']}
2017-08-27 22:24:21 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.logstats.LogStats',
'scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.memusage.MemoryUsage',
'scrapy.extensions.telnet.TelnetConsole']
2017-08-27 22:24:21 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2017-08-27 22:24:21 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2017-08-27 22:24:21 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2017-08-27 22:24:21 [scrapy.core.engine] INFO: Spider opened
2017-08-27 22:24:21 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2017-08-27 22:24:21 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2017-08-27 22:24:21 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://blog.jobbole.com/robots.txt> (referer: None)
2017-08-27 22:24:26 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://blog.jobbole.com/> (referer: None)
2017-08-27 22:24:26 [scrapy.core.engine] INFO: Closing spider (finished)
2017-08-27 22:24:26 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 438,
'downloader/request_count': 2,
'downloader/request_method_count/GET': 2,
'downloader/response_bytes': 22537,
'downloader/response_count': 2,
'downloader/response_status_count/200': 2,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2017, 8, 27, 14, 24, 26, 588459),
'log_count/DEBUG': 3,
'log_count/INFO': 7,
'memusage/max': 50860032,
'memusage/startup': 50860032,
'response_received_count': 2,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2017, 8, 27, 14, 24, 21, 136475)}
2017-08-27 22:24:26 [scrapy.core.engine] INFO: Spider closed (finished)
(third_project) bigni@bigni:~/python_file/python_project/pachong/ArticleSpider/ArticleSpider$
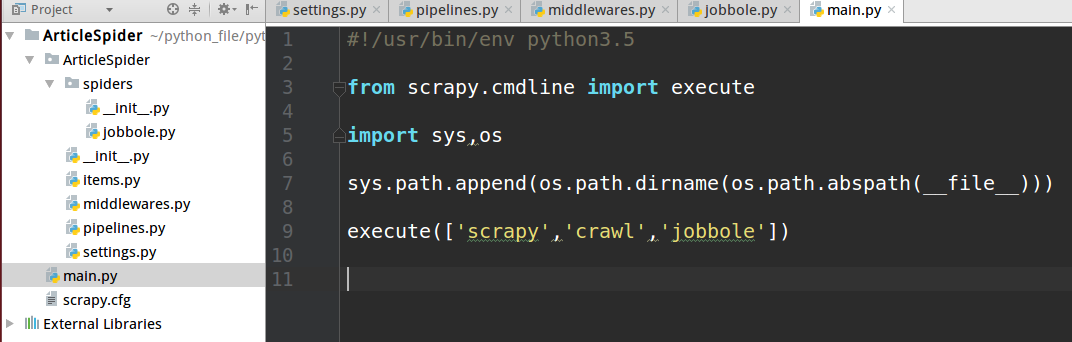
在pycharm 调试scrapy 执行流程,在项目里创建一个python文件,把项目路径写进sys.path,调用execute方法,传个数组,效果和上面在终端运行效果一样
PS:setting配置文件里建议把robotstxt协议停掉,否则scrapy会过滤某些url
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
第五篇 scrapy安装及目录结构,启动spider项目的更多相关文章
- 02、Scrapy 安装、目录结构及启动
1.从豆瓣源去快速安装Scrapy开发环境 C:\Users\licl11092>pip install -i https://pypi.douban.com/simple/ scrapy 2. ...
- vuejs目录结构启动项目安装nodejs命令,api配置信息思维导图版
vuejs目录结构启动项目安装nodejs命令,api配置信息思维导图版 vuejs技术交流QQ群:458915921 有兴趣的可以加入 vuejs 目录结构 build build.js check ...
- 02_Weblogic课程之安装篇:RedHat下JDK安装,RedHat下Weblogic安装,目录结构,环境变量设置
1 Weblogic的安装方式有三种: 一.GUI方式安装 (java –jar wls1035_generic.jar [-mode=gui])这是默认的 二.Console方式安装 ...
- Scrapy基础(二)————Scrapy的安装和目录结构
Scrapy安装: 1,首先进入虚拟环境 2,使用国内豆瓣源进行安装,快! pip install -i https://pypi.douban.com/simple/ scrapy 3,特殊情 ...
- ant design pro(一)安装、目录结构、项目加载启动【原始、以及idea开发】
一.概述 1.1.脚手架概念 编程领域中的“脚手架(Scaffolding)”指的是能够快速搭建项目“骨架”的一类工具.例如大多数的React项目都有src,public,webpack配置文件等等, ...
- 001-ant design pro安装、目录结构、项目加载启动【原始、以及idea开发】
一.概述 1.1.脚手架概念 编程领域中的“脚手架(Scaffolding)”指的是能够快速搭建项目“骨架”的一类工具.例如大多数的React项目都有src,public,webpack配置文件等等, ...
- Maven进价:Maven的安装和目录结构
一.在windows上安装Maven 1.下载 下载地址:http://maven.apache.org/download.html 下载最新版本 maven3.2.5 2.解压 解压地址:F:\Ja ...
- linux下mysql安装、目录结构、配置
1.准备安装程序(官方网站下载) 服务端:MySQL-server-community-5.1.44-1.rhel4.i386.rpm 客户端:MySQL-client-community-5.1.4 ...
- DedeCMS安装及目录结构
一.安装DedeCMS 1.下载DedeCMS安装包,我下载的版本是DedeCMS-V5.7-UTF8-SP1.tar.gz 官方下载地址 2.解压DedeCMS-V5.7-UTF8-SP1.tar. ...
随机推荐
- Java内部类成员
内部类可以访问其所有实例成员,实例字段和其封闭类的实例方法.参考如下实例 - 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 2 ...
- TP5截取部分字符串
TP5截取超出的字符串,使用...显示 在公共文件common.php中 视图模板中调用
- Android Studio3.3中Cannot resolve symbol ActivityTestRule
最近在看<Android编程权威指南>,在Windows10下安装了Android Studio3.3,边看编练习书中的例子程序,看到第21章""音频播放与单元测试&q ...
- mysql 5.7.20 从frm文件中得到建表语句 (使用 mysql-utilities)
系统环境 centos 7.2 mysql社区版 5.7.20 mysql-utilities 根据官网的说法,截止到2018年5月30日,实用工具的一些功能在Shell的路线图中,鼓励用户迁 ...
- mongo聚合命令
db.getCollection('chat').aggregate([ { "$match": { "last": 1, "type": ...
- centos7上的h5ai折腾记
过程: 安装php-fpm和nginx,且经验证二者在其他项目可以正常使用. 从debian8拷贝过来_h5ai的nginx配置如下: location ~ [^/]\.php(/|$) { fast ...
- 使用 Audacity 录制声卡声音
在Linux中使用 Audacity 录制电脑播放的声音非常简单,其实主要设置不在 Audacity 上,而是要设置好输入设备并选择对录音输入源. 首先确认输入设备中 内置音频的Monitor 没有被 ...
- Thunar 右键菜单等自定义
Thunar 右键菜单等自定义 可以使用图形界面或者直接编辑配置文件,二者是等价的. 图形界面: 以给"zip,rar,7z"等文件添加"在此位置使用unar解压缩&qu ...
- Ansible 和 Playbook 暂存
Ansible 和 Playbook 暂存 , 也是一个批量管理工具 自动化的批量管理工具 主机清单 HOST Inventory 模块插件 Playbooks 查看ansible的目录结构 ...
- shell egrep 引号
[jg73178@hdcgcgdbsla01dv ~]$ egrep \'SI\' tt.txt 'SI' [jg73178@hdcgcgdbsla01dv ~]$ egrep \"SI\& ...