PHP 爬虫——QueryList
前言:
来了个任务说要做个电影网站,要写个壳,数据直接从别人那扒。行吧!那就要学习下PHP爬虫了。占个博客,以后补充。http://study.querylist.cc/archives/6/
之前开发抓取网页上的东西,无非就是curl+正则。用curl去请求所要扒取的页面,然后通过正则匹配去提取你所需要的内容。
但是查了下现在PHP爬虫可以通过使用QueryList来实现。可以通过CSS的DOM选择器来实现。
特性:
- 拥有与jQuery完全相同的CSS3 DOM选择器
- 拥有与jQuery完全相同的DOM操作API
- 拥有通用的列表采集方案
- 拥有强大的HTTP请求套件,轻松实现如:模拟登陆、伪造浏览器、HTTP代理等意复杂的网络请求
- 拥有乱码解决方案
- 拥有强大的内容过滤功能,可使用jQuey选择器来过滤内容
- 拥有高度的模块化设计,扩展性强
- 拥有富有表现力的API
- 拥有高质量文档
- 拥有丰富的插件
- 拥有专业的问答社区和交流群
内容:
因为要做一个电影网站,所以这次利用QueryList来爬取电影网资源,这次爬取的是——玩的嗨TV, 网址:http://tv.wandhi.com/movielist/all/3.html。
首先,选取这网站主要是它是个解析站,去破解各大网站的电影资源供给观看,建站也比较简易,没有啥限制防盗链啥的。当然所能爬取到的资源也比较少,也主要是电影播放资源丰富吧。
主要爬取....(采集好像比较好听点)。本次主要采集了玩的嗨TV的电影列表页面和电影播放页面。
安装:
安装QueryList相当的简单,打开项目目录,运行compose命令进行安装
composer require jaeger/guerylist
(注意点 PHP版本需要在7.0以上)
在控制器中引入相应的类就可以开始使用了
use QL\QueryList;
使用:
先贴个小代码
/**
* 采集电影首页
*/
public function film_list($page = ){
$path = '/movielist/all/'.$page.'.html';
$rules = [
'link' => ['.lazy', 'href'],
'img' => ['.title>h5>a', 'src'],
'name' => ['.lazy', 'title'],
'score' => ['.score', 'html'],
'actor' => ['.subtitle', 'html'],
];
$data = QueryList::Query($this->url . $path, $rules)->data;
return $data;
}
从代码中可以很清楚的看出,使用QueryList的Query方法,参数为采集地址和采集规则。
采集地址就是你所要采集页面的网址。
采集规则是一个数组,结构“名字”=>[“css DOM选择器”,‘DOM属性’];
这样就可以采集到页面数据。
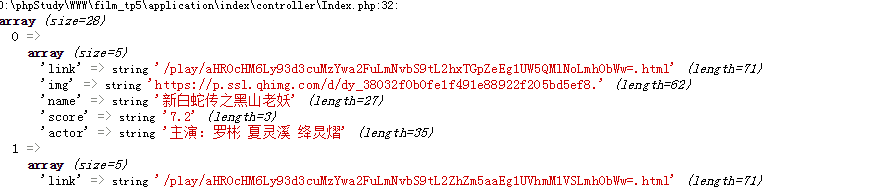
1、电影列表页面
页面结构如下:

爬取结果:
2、电影播放页面
页面结构:

主要采集这两个数据进行拼接就能获得视频的播放地址。
采集结果:

对数据进行拼接就可以获得视频播放地址。
总结:这次采集相对简单。QueryList还有提供了许多深层的方法,后面可以在进行测试使用。主要是进行了简易的采集,获取了所需的数据,电影网也足够了
结语:离职的最后一天,你会做些什么?
PHP 爬虫——QueryList的更多相关文章
- PHP爬虫之queryList
根据queryList 自己花了一个下午的时间写了一个爬星座数据的类,完全手写.附上代码 <?php require '../vendor/autoload.php'; use QL\Query ...
- PHP简单爬虫 基于QueryList采集库 和 ezsql数据库操作类
QueryList是一个基于phpQuery的PHP通用列表采集类,得益于phpQuery,让使用QueryList几乎没有任何学习成本,只要会CSS3选择器就可以轻松使用QueryList了,它让P ...
- Thinkphp5与QueryList,也可以实现采集(爬虫)页面功能
QueryList 是什么 QueryList是一套用于内容采集的PHP工具,它使用更加现代化的开发思想,语法简洁.优雅,可扩展性强.相比传统的使用晦涩的正则表达式来做采集,QueryList使用了更 ...
- php 爬虫框架
发现两款不错的爬虫框架,极力推荐下: phpspider 一款优秀的PHP开发蜘蛛爬虫 官方下载地址:https://github.com/owner888/phpspider 官方开发手册:http ...
- php爬虫学习笔记1 PHP Simple HTML DOM Parser
常用爬虫. 0. Snoopy是什么? (下载snoopy) Snoopy是一个php类,用来模仿web浏览器的功能,它能完成获取网页内容和发送表单的任务. Snoopy的一些特点: * ...
- 第一个get请求的爬虫程序
一:urllib库: urllib是Python自带的一个用于爬虫的库,器主要作用就是可以通过代码模拟浏览器发送请求.其被用到子模块在Python3中的urllib.request和urllib.pa ...
- python爬虫爬取get请求的页面数据代码样例
废话不多说,上代码 #!/usr/bin/env python # -*- coding:utf-8 -*- # 导包 import urllib.request import urllib.pars ...
- QueryList 来做采集
示例代码 先来感受一下使用 QueryList 来做采集是什么样子. 1 采集百度搜索结果列表的标题和链接.大理石平台价格 采集代码: $data = QueryList::get('https:// ...
- PHP网络爬虫实践:抓取百度搜索结果,并分析数据结构
百度的搜索引擎有反爬虫机制,我先直接用guzzle试试水.代码如下: <?php /** * Created by Benjiemin * Date: 2020/3/5 * Time: 14:5 ...
随机推荐
- Dig命令解析结果
dig -t RT NAME @NS -t RT 指定要查询的资源记录类型 NAME 需要解析的域(域名) @NS 指定那个域名服务器负责解析 [root@xss ~]# dig www.ihoney ...
- docker swarm英文文档学习-1-概述
参考https://docs.docker.com/engine/swarm/ Swarm mode overview群模式概述 Docker的当前版本包括集群模式,用于本地管理称为集群的Docker ...
- docker pull下载镜像时的报错及其解决方法
使用docker pull从镜像仓库拉取镜像时报错如下: [root@docker-registry ~]# docker pull centos Using default tag: latest ...
- Java使用PropertyDescriptor获取实体类中私有属性的值,并给私有属性赋值
大家都知道Java类中的私有的(private)属性是获取不到的(即使使用继承依然获取不到),那如果非要获取私有属性的值怎么办呢?一般的做法是将该java类封装称为一个JavaBean,即封装该私有属 ...
- STM32 中 BIT_BAND(位段/位带)和别名区使用入门(转载)
一. 什么是位段和别名区 是这样的,记得MCS51吗? MCS51就是有位操作,以一位(BIT)为数据对象的操作,MCS51可以简单的将P1口的第2位独立操作: P1.2=0;P1.2=1 :这样就把 ...
- jqgrid 行选中multiboxonly属性说明
multiboxonly属性值为布尔值. false:点击行时,同时选中改行的复选框,支持多行选中 true:点击行时,只将点击的行处理为选中状态,切换其他行时,原选中行的选中效果被取消 (永远只有一 ...
- 批量下载,多文件压缩打包zip下载
0.写在前面的话 图片批量下载,要求下载时集成为一个压缩包进行下载.从昨天下午折腾到现在,踩坑踩得莫名其妙,还是来唠唠,给自己留个印象的同时,也希望给需要用到这个方法的人带来一些帮助. 1.先叨叨IO ...
- CAN总线优势
CAN总线优势 RS-485基于R线构建的分布式控制系统而言, 基于CAN总线的分布式控制系统在以下方面具有明显的优越性: 首先,CAN控制器工作于多主方式,网络中 的各节点都可根据总线访问优先权(取 ...
- jQuery上传文件
1.引入资源 <script src="/yami/backend/backres/js/jquery.min.js"></script> <scri ...
- 带你看懂大数据采集引擎之Flume&采集目录中的日志
一.Flume的介绍: Flume由Cloudera公司开发,是一种提供高可用.高可靠.分布式海量日志采集.聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于采集数据:同时,flum ...